Artificial Intelligence
Streamline code migration using Amazon Nova Premier with an agentic workflow
Many enterprises are burdened with mission-critical systems built on outdated technologies that have become increasingly difficult to maintain and extend.
This post demonstrates how you can use the Amazon Bedrock Converse API with Amazon Nova Premier within an agentic workflow to systematically migrate legacy C code to modern Java/Spring framework applications. By breaking down the migration process into specialized agent roles and implementing robust feedback loops, organizations can accomplish the following:
- Reduce migration time and cost – Automation handles repetitive conversion tasks while human engineers focus on high-value work.
- Improve code quality – Specialized validation agents make sure the migrated code follows modern best practices.
- Minimize risk – The systematic approach prevents critical business logic loss during migration.
- Enable cloud integration – The resulting Java/Spring code can seamlessly integrate with AWS services.
Challenges
Code migration from legacy systems to modern frameworks presents several significant challenges that require a balanced approach combining AI capabilities with human expertise:
- Language paradigm differences – Converting C code to Java involves navigating fundamental differences in memory management, error handling, and programming paradigms. C’s procedural nature and direct memory manipulation contrast sharply with Java’s object-oriented approach and automatic memory management. Although AI can handle many syntactic transformations automatically, developers must review and validate the semantic correctness of these conversions.
- Architectural complexity – Legacy systems often feature complex interdependencies between components that require human analysis and planning. In our case, the C code base contained intricate relationships between modules, with some TPs (Transaction Programs) connected to as many as 12 other modules. Human developers must create dependency mappings and determine migration order, typically starting from leaf nodes with minimal dependencies. AI can assist in identifying these relationships, but the strategic decisions about migration sequencing require human judgment.
- Maintaining business logic – Making sure critical business logic is accurately preserved during translation requires continuous human oversight. Our analysis showed that although automatic migration is highly successful for simple, well-structured code, complex business logic embedded in larger files (over 700 lines) requires careful human review and often manual refinement to prevent errors or omissions.
- Inconsistent naming and structures – Legacy code often contains inconsistent naming conventions and structures that must be standardized during migration. AI can handle many routine transformations—converting alphanumeric IDs in function names, transforming C-style error codes to Java exceptions, and converting C structs into Java classes—but human developers must establish naming standards and review edge cases where automated conversion may be ambiguous.
- Integration complexity – After converting individual files, human-guided integration is essential for creating a cohesive application. Variable names that were consistent across the original C files often become inconsistent during individual file conversion, requiring developers to perform reconciliation work and facilitate proper inter-module communication.
- Quality assurance – Validating that converted code maintains functional equivalence with the original requires a combination of automated testing and human verification. This is particularly critical for complex business logic, where subtle differences can lead to significant issues. Developers must design comprehensive test suites and perform thorough code reviews to ensure migration accuracy.
These challenges necessitate a systematic approach that combines the pattern recognition capabilities of large language models (LLMs) with structured workflows and essential human oversight to produce successful migration outcomes. The key is using AI to handle routine transformations while keeping humans in the loop for strategic decisions, complex logic validation, and quality assurance.
Solution overview
The solution employs the Amazon Bedrock Converse API with Amazon Nova Premier to convert legacy C code to modern Java/Spring framework code through a systematic agentic workflow. This approach breaks down the complex migration process into manageable steps, allowing for iterative refinement and handling of token limitations. The solution architecture consists of several key components:
- Code analysis agent – Analyzes C code structure and dependencies
- Conversion agent – Transforms C code to Java/Spring code
- Security assessment agent – Identifies vulnerabilities in legacy and migrated code
- Validation agent – Verifies conversion completeness and accuracy
- Refine agent – Rewrites the code based on the feedback from the validation agent
- Integration agent – Combines individually converted files
Our agentic workflow is implemented using a Strands Agents framework combined with the Amazon Bedrock Converse API for robust agent orchestration and LLM inference. The architecture (as shown in the following diagram) uses a hybrid approach that combines Strands’s session management capabilities with custom BedrockInference handling for token continuation.
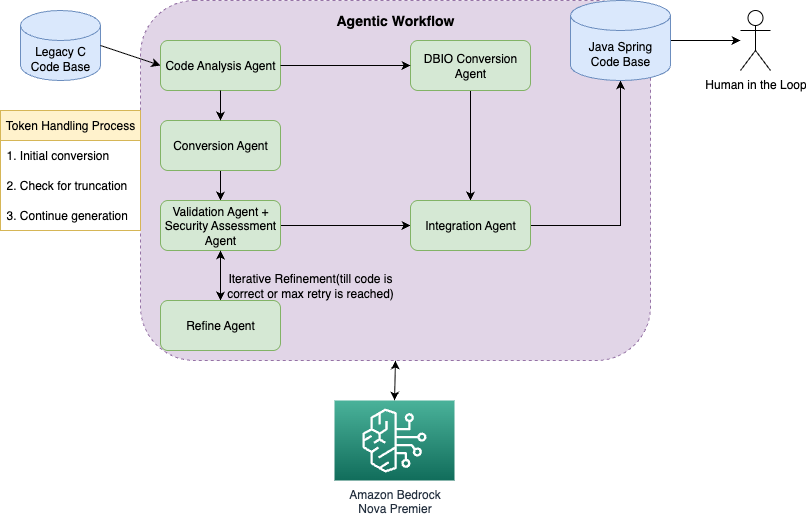
The solution uses the following core technologies:
- Strands Agents framework (v1.1.0+) – Provides agent lifecycle management, session handling, and structured agent communication
- Amazon Bedrock Converse API – Powers the LLM inference with Amazon Nova Premier model
- Custom BedrockInference class – Handles token limitations through text prefilling and response continuation
- Asyncio-based orchestration – Enables concurrent processing and non-blocking agent execution
The workflow consists of the following steps:
1. Code analysis:
- Code analysis agent – Performs input code analysis to understand the conversion requirements. Examines C code base structure, identifies dependencies, and assesses complexity.
- Framework integration – Uses Strands for session management while using
BedrockInferencefor analysis. - Output – JSON-structured analysis with dependency mapping and conversion recommendations.
2. File categorization and metadata creation:
- Implementation –
FileMetadatadata class with complexity assessment. - Categories – Simple (0–300 lines), Medium (300–700 lines), Complex (over 700 lines).
- File types – Standard C files, header files, and database I/O (DBIO) files.
3. Individual file conversion:
- Conversion agent – Performs code migration on individual files based on the information from the code analysis agent.
- Token handling – Uses the
stitch_output()method for handling large files that exceed token limits.
4. Security assessment phase:
- Security assessment agent – Performs comprehensive vulnerability analysis on both legacy C code and converted Java code.
- Risk categorization – Classifies security issues by severity (Critical, High, Medium, Low).
- Mitigation recommendations – Provides specific code fixes and security best practices.
- Output – Detailed security report with actionable remediation steps.
5. Validation and feedback loop:
- Validation agent – Analyzes conversion completeness and accuracy.
- Refine agent – Applies iterative improvements based on validation results.
- Iteration control – Maximum five feedback iterations with early termination on satisfactory results.
- Session persistence – Strands framework maintains conversation context across iterations.
6. Integration and finalization:
- Integration agent – Attempts to combine individually converted files.
- Consistency resolution – Standardizes variable naming and provides proper dependencies.
- Output generation – Creates cohesive Java/Spring application structure.
7. DBIO conversion (specialized)
- Purpose – Converts SQL DBIO C source code to MyBatis XML mapper files.
- Framework – Uses the same Strands and
BedrockInferencehybrid approach for consistency.
The solution consists of the following key orchestration features:
- Session persistence – Each conversion maintains session state across agent interactions.
- Error recovery – Comprehensive error handling with graceful degradation.
- Performance tracking – Built-in metrics for processing time, iteration counts, and success rates.
- Token continuation – Seamless handling of large files through response stitching.
This framework-specific implementation facilitates reliable, scalable code conversion while maintaining the flexibility to handle diverse C code base structures and complexities.
Prerequisites
Before implementing this code conversion solution, make sure you have the following components configured:
- AWS environment:
- AWS account with appropriate permissions for Amazon Bedrock with Amazon Nova Premier model access
- Amazon Elastic Compute Cloud (Amazon EC2) instance (t3.medium or larger) for development and testing or development environment in local machine
- Development setup:
- Python 3.10+ installed with Boto3 SDK and Strands Agents
- AWS Command Line Interface (AWS CLI) configured with appropriate credentials and AWS Region
- Git for version control of legacy code base and converted code
- Text editor or integrated development environment (IDE) capable of handling both C and Java code bases
- Source and target code base requirements:
- C source code organized in a structured directory format
- Java 11+ and Maven/Gradle build tools
- Spring Framework 5.x or Spring Boot 2.x+ dependencies
The source code and prompts used in the post can be found in the GitHub repo.
Agent-based conversion process
The solution uses a sophisticated multi-agent system implemented using the Strands framework, where each agent specializes in a specific aspect of the code conversion process. This distributed approach provides thorough analysis, accurate conversion, and comprehensive validation while maintaining the flexibility to handle diverse code structures and complexities.
Strands framework integration
Each agent extends the BaseStrandsConversionAgent class, which provides a hybrid architecture combining Strands session management with custom BedrockInference capabilities:
Code analysis agent
The code analysis agent examines the structure of the C code base, identifying dependencies between files and determining the optimal conversion strategy. This agent helps prioritize which files to convert first and identifies potential challenges. The following is the prompt template for the code analysis agent:
Conversion agent
The conversion agent handles the actual transformation of C code to Java/Spring code. This agent is assigned the role of a senior software developer with expertise in both C and Java/Spring frameworks. The prompt template for the conversion agent is as follows:
Security assessment agent
The security assessment agent performs comprehensive vulnerability analysis on the original C code and the converted Java code, identifying potential security risks and providing specific mitigation strategies. This agent is crucial for making sure security vulnerabilities are not carried forward during migration and new code follows security best practices. The following is the prompt template for the security assessment agent:
Validation agent
The validation agent reviews the converted code to identify missing or incorrectly converted components. This agent provides detailed feedback that is used in subsequent conversion iterations. The prompt template for the validation agent is as follows:
Feedback loop implementation with refine agent
The feedback loop is a critical component that enables iterative refinement of the converted code. This process involves the following steps:
- Initial conversion by the conversion agent.
- Security assessment by the security assessment agent.
- Validation by the validation agent.
- Feedback incorporation by the refine agent (incorporating both validation and security feedback).
- Repeat until satisfactory results are achieved.
The refine agent incorporates security vulnerability fixes alongside functional improvements, and security assessment results are provided to development teams for final review and approval before production deployment. The following code is the prompt template for code refinement:
Integration agent
The integration agent combines individually converted Java files into a cohesive application, resolving inconsistencies in variable naming and providing proper dependencies. The prompt template for the integration agent is as follows:
DBIO conversion agent
This specialized agent handles the conversion of SQL DBIO C source code to XML files compatible with persistence framework in the Java Spring framework. The following is the prompt template for the DBIO conversion agent:
Handling token limitations
To address token limitations in the Amazon Bedrock Converse API, we implemented a text prefilling technique that allows the model to continue generating code where it left off. This approach is particularly crucial for large files that exceed the model’s context window and represents a key technical innovation in our Strands-based implementation.
Technical implementation
The following code implements the BedrockInference class with continuation support:
Continuation strategy details
The continuation strategy consists of the following steps:
- Response monitoring:
- The system monitors the
stopReasonfield in Amazon Bedrock responses. - When
stopReasonequalsmax_tokens, continuation is triggered automatically. This makes sure no code generation is lost due to token limitations.
- The system monitors the
- Context preservation:
- The system extracts the last few lines of generated code as continuation context.
- It uses text prefilling to maintain code structure and formatting. It preserves variable names, function signatures, and code patterns across continuations.
- Response stitching:
Optimizing conversion quality
Through our experiments, we identified several factors that significantly impact conversion quality:
- File size management – Files with more than 300 lines of code benefit from being broken into smaller logical units before conversion.
- Focused conversion – Converting different file types (C, header, DBIO) separately yields better results as each file type has distinct conversion patterns. During conversion, C functions are transformed into Java methods within classes, and C structs become Java classes. However, because files are converted individually without cross-file context, achieving optimal object-oriented design might require human intervention to consolidate related functionality, establish proper class hierarchies, and facilitate appropriate encapsulation across the converted code base.
- Iterative refinement – Multiple feedback loops (4–5 iterations) produce more comprehensive conversions.
- Role assignment – Assigning the model a specific role (senior software developer) improves output quality.
- Detailed instructions – Providing specific transformation rules for common patterns improves consistency.
Assumptions
This migration strategy makes the following key assumptions:
- Code quality – Legacy C code follows reasonable coding practices with discernible structure. Obfuscated or poorly structured code might require preprocessing before automated conversion.
- Scope limitations – This approach targets business logic conversion rather than low-level system code. C code with hardware interactions or platform-specific features might require manual intervention.
- Test coverage – Comprehensive test cases exist for the legacy application to validate functional equivalence after migration. Without adequate tests, additional validation steps are necessary.
- Domain knowledge – Although the agentic workflow reduces the need for expertise in both C and Java, access to subject matter experts who understand the business domain is required to validate preservation of critical business logic.
- Phased migration – The approach assumes an incremental migration strategy is acceptable, where components can be converted and validated individually rather than a full project level migration.
Results and performance
To evaluate the effectiveness of our migration approach powered by Amazon Nova Premier, we measured performance across enterprise-grade code bases representing typical customer scenarios. Our assessment focused on two success factors: structural completeness (preservation of all business logic and functions) and framework compliance (adherence to Spring Boot best practices and conventions).
Migration accuracy by code base complexity
The agentic workflow demonstrated varying effectiveness based on file complexity, with all results validated by subject matter experts. The following table summarizes the results.
| File Size Category | Structural Completeness | Framework Compliance | Average Processing Time |
| Small (0–300 lines) | 93% | 100% | 30 –40 seconds |
| Medium (300–700 lines) | 81%* | 91%* | 7 minutes |
| Large (more than 700 lines) | 62%* | 84%* | 21 minutes |
*After multiple feedback cycles
Key insights for enterprise adoption
These results reveal an important pattern: the agentic approach excels at handling the bulk of migration work (small to medium files) while still providing significant value for complex files that require human oversight. This creates a hybrid approach where AI handles routine conversions and security assessments, and developers focus on integration and architectural decisions.
Conclusion
Our solution demonstrates that the Amazon Bedrock Converse API with Amazon Nova Premier, when implemented within an agentic workflow, can effectively convert legacy C code to modern Java/Spring framework code. The approach handles complex code structures, manages token limitations, and produces high-quality conversions with minimal human intervention. The solution breaks down the conversion process into specialized agent roles, implements robust feedback loops, and handles token limitations through continuation techniques. This approach accelerates the migration process, improves code quality, and reduces the potential for errors. Try out the solution for your own use case, and share your feedback and questions in the comments.
About the authors
 Aditya Prakash is a Senior Data Scientist at the Amazon Generative AI Innovation Center. He helps customers leverage AWS AI/ML services to solve business challenges through generative AI solutions. Specializing in code transformation, RAG systems, and multimodal applications, Aditya enables organizations to implement practical AI solutions across diverse industries.
Aditya Prakash is a Senior Data Scientist at the Amazon Generative AI Innovation Center. He helps customers leverage AWS AI/ML services to solve business challenges through generative AI solutions. Specializing in code transformation, RAG systems, and multimodal applications, Aditya enables organizations to implement practical AI solutions across diverse industries.
 Jihye Seo is a Senior Deep Learning Architect who specializes in designing and implementing generative AI solutions. Her expertise spans model optimization, distributed training, RAG systems, AI agent development, and real-time data pipeline construction across manufacturing, healthcare, gaming, and e-commerce sectors. As an AI/ML consultant, Jihye has delivered production-ready solutions for clients, including smart factory control systems, predictive maintenance platforms, demand forecasting models, recommendation engines, and MLOps frameworks
Jihye Seo is a Senior Deep Learning Architect who specializes in designing and implementing generative AI solutions. Her expertise spans model optimization, distributed training, RAG systems, AI agent development, and real-time data pipeline construction across manufacturing, healthcare, gaming, and e-commerce sectors. As an AI/ML consultant, Jihye has delivered production-ready solutions for clients, including smart factory control systems, predictive maintenance platforms, demand forecasting models, recommendation engines, and MLOps frameworks
 Yash Shah is a Science Manager in the AWS Generative AI Innovation Center. He and his team of applied scientists, architects and engineers work on a range of machine learning use cases from healthcare, sports, automotive and manufacturing, helping customers realize art of the possible with GenAI. Yash is a graduate of Purdue University, specializing in human factors and statistics. Outside of work, Yash enjoys photography, hiking and cooking.
Yash Shah is a Science Manager in the AWS Generative AI Innovation Center. He and his team of applied scientists, architects and engineers work on a range of machine learning use cases from healthcare, sports, automotive and manufacturing, helping customers realize art of the possible with GenAI. Yash is a graduate of Purdue University, specializing in human factors and statistics. Outside of work, Yash enjoys photography, hiking and cooking.