AWS Cloud Operations Blog
How McAfee used Amazon CloudWatch to monitor a multi-PB data migration to Databricks on AWS
This blog post was contributed by Kanishk Mahajan@AWS; Hashem Raslan, Manager, Engineering@McAfee; Anastasia Zamyshlyaeva, Vice President, Data Engineering@McAfee
McAfee, a global leader in online protection security enables home users and businesses to stay ahead of fileless attacks, viruses, malware, and other online threats. McAfee wanted to create a centralized data platform as a single source of truth to power customer insights. This involved migrating approximately 2 petabytes (PB) of data from more than 60 sources including Azure Databricks into Databricks on AWS. In this post, we describe how McAfee used Amazon CloudWatch and related AWS services to provide visibility and monitoring for a cost-effective data migration into Databricks on AWS.
Migrating a petabyte scale datalake using Databricks deep clones
Databricks clones are replicas of a source table at a given point in time. They have the same metadata (schema, partitions, constraints etc) as the source table and while a shallow clone only duplicates the metadata of the table being cloned, a deep clone makes a full copy of the metadata as well as data files of the table being cloned. Similar to copying with a CTAS command (CREATE TABLE… AS… SELECT…) but without the need to re-specify partitioning options, constraints and other information, deep clones are fast, robust and also work in an incremental manner. This incremental copy feature was critical for us in our large scale multi petabyte migration since deep clones provided us with an efficient solution to replicate only the data that is required to protect against failures, instead of all of the data. Deep clones enabled us to copy both our streaming application transactions as well as our COPY INTO transactions. This provided us with the ability to continue our ETL (extract, load and transform) applications from exactly where we left off after the migration.
Monitoring data transfer using Amazon CloudWatch
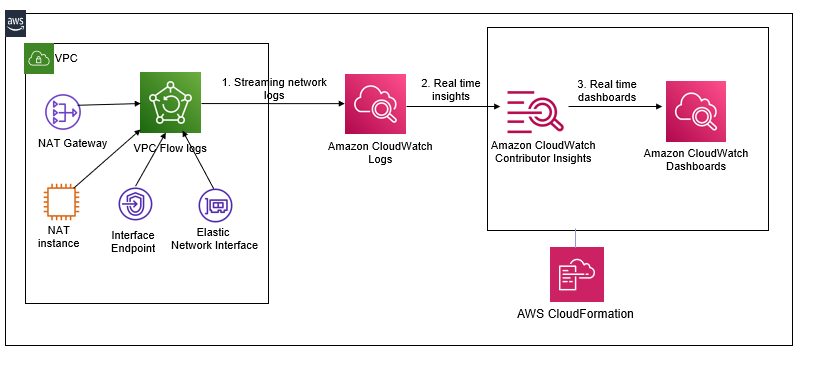
We configured Amazon VPC Flow Logs to publish flow log data directly to Amazon CloudWatch Logs. The flow logs were configured to monitor Databricks data transfer flow traffic entering and leaving the Amazon Virtual Private Cloud (VPC) where the Databricks compute was deployed. The flow log data published to CloudWatch Logs contained information such as the source and destination IP addresses, port, protocol, connection requests and bytes transferred for requests to the NAT gateway, NAT instance and the Amazon VPC endpoint for Amazon S3 for the data transfer to Databricks on AWS.
We built a solution to automate the provisioning of Amazon CloudWatch Contributor Insights rules that were then applied to these CloudWatch Logs. These Contributor Insights rules filtered log data based on log streams corresponding to individual Amazon Elastic network interfaces of the NAT instance, NAT Gateway and VPC endpoints in the deployed subnets. We automated the provisioning of CloudWatch metrics from these rules based on the INSIGHT_RULE_METRIC metric math function and our solution used those metrics to create Amazon CloudWatch alarms based on thresholds applied to these metrics.
Based on Amazon CloudWatch metrics monitoring for bytes transferred, we discovered that the data processing charge for the PBs of data that went through the NAT Gateway made it more cost effective to replace it with an appropriately sized NAT instance configured for instance recovery to automatically recover from failures. To benefit from AWS Migration Acceleration Program (MAP) discounts for the migration, we implemented custom cluster tagging in Databricks. The cluster tag with a ”map-migrated” key was then automatically propagated to all the Databricks Amazon Elastic Compute Cloud (EC2) data plane nodes that were spun up or down for data processing on AWS by the Databricks control plane and we used CloudWatch metrics to monitor resource utilization and health of these tagged instances.
You can download our solution for aggregation and streaming of network logs into Contributor Insights in the databricks transfer flow as shown in the diagram below.
Next steps
The current application on AWS is currently being tested in a proof of concept (POC) deployment to receive a peak of approximately 1B API requests/day from McAfee’s consumer endpoints that are installed on the devices of an estimated 17M subscribers. These requests are streamed to an Amazon Kinesis Data Stream and they’re consumed by a Databricks ETL job that leverages the out-of-the-box, optimized Kinesis source from the Databricks runtime.
To benefit from enhanced security and simpler network administration, we have configured the Databricks ETL job to use a Kinesis VPC endpoint for communication with the Kinesis data stream in our POC. In the future, we also plan to use AWS PrivateLink for secure cluster connectivity between the Databricks data plane and the Databricks control plane for tasks related to cluster initiation or starting Spark worker jobs. Based on this PrivateLink CloudWatch monitoring solution, we can then extend our current CloudWatch automation and provide time-series monitoring and visualization for both Kinesis VPC Endpoints and PrivateLink connections in this same deployment.

Conclusion
Databricks cloning provides simple, efficient, and cost-effective data migration for large datasets. It supports several sources and destinations for data transfer – including HDFS, Azure and AWS storage while providing advanced features such as support for incremental data capture, data synchronization, transaction logs, buffers and retries. In this post, we described how McAfee leveraged CloudWatch automation with Contributor Insights, metrics and alarms to monitor and optimize a petabyte scale data transfer into AWS. We also shared our CloudWatch automation solution that you can download and use to monitor and visualize your own data migration.