Networking & Content Delivery
Tracking pixel driven web analytics with Amazon CloudFront: Part 2
This post is a continuation of Tracking Pixel driven web analytics with AWS Edge Services. In Part 1 of this series, we discussed the usage of pixel tracking to provide insights into user behavior. A tracking pixel consists of using a 1×1 transparent pixel with a HTML element to leverage the loading call to send tracking information to a backend server. By using Amazon CloudFront real-time logs, we presented an edge service solution for pixel tracking. Real-time logs are a feature of Amazon CloudFront that log detailed information of nearly every request that CloudFront receives. This solution can be used by advertising tech or e-commerce customers and even for personal blogs to collect data on user behavior, track conversions, build attribution modeling, or personalize content.
This post demonstrates how to implement the pixel tracking solution and leverages cloud Infrastructure-as-Code (IaC) AWS Cloud Development Kit (AWS CDK) to deploy the solution. AWS CDK is an open-source software development framework to define cloud application resources using familiar programming languages. The referenced architecture with sample code can be used to build your own edge pixel tracking.
This solution is available on GitHub. Note that this sample code is for demonstration purposes and must be altered for production use.
Overview
There are four main components in this example:
- A CloudFront distribution: CloudFront is a content delivery network (CDN) service that securely delivers data, videos, applications, and APIs and at high speeds with low latency. The static assets (for example, HTML, and the tracking pixel) are stored in Amazon Simple Storage Service (Amazon S3) and exposed and cached by CloudFront. Real-time logs are enabled for request calls made to fetch the tracking pixel.
- Kinesis to collect, process, and load the data stream into a data lake: Amazon Kinesis cost-effectively processes and analyzes streaming data at any scale as a fully managed service. Real-time logs are integrated with Kinesis, and it delivers to Amazon S3 as a data lake. Using Amazon S3 as the data lake provides integration to other AWS analytic services, at low cost, to quickly extract data insights.
- Glue crawler to populate AWS Glue Data Catalog: Glue crawlers connect to a source or target data store, use classifiers to determine the schema of the data, and then create metadata in Glue Data Catalog. This is used as the extract, transform, and log (ETL) process and groups the data into tables and partitions from the Amazon S3 data lake.
- Analyze the data with Athena: Amazon Athena provides a simplified and flexible way to analyze petabytes of data where it lives. Athena works directly with data stored in Amazon S3, allowing you to analyze the pixel tracking data.
This is the example architecture:
Figure 1: Pixel tracking solution architecture
The request flow is as follows:
- The user requests static content and tracking pixel embedded in a web page.
- CloudFront retrieves static assets from Amazon S3 or its cache and returns it to the client. Requests for the pixel image are recorded with real-time logs.
- CloudFront real-time logs are delivered to Amazon Kinesis Data Streams.
- Kinesis Data Streams are delivered to Amazon Kinesis Data Firehose.
- Kinesis Data Firehose loads streaming data into an S3 bucket.
- A scheduled crawler runs every 40 minutes and automatically groups data into tables and writes metadata to the Data Catalog.
- Pixel tracking data analyst uses Athena to query and analyze the cataloged tracking data.
Implementation
CloudFront distribution and S3 bucket
For this post, a simple HTML page was constructed to mimic a webpage hosted on Amazon S3. The HTML page and the 1×1 pixel asset are uploaded to the S3 bucket through the BucketDeployment construct.
const bucket = new s3.Bucket(this, 'pixel-tracking-webpage-bucket', {
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
encryption: s3.BucketEncryption.S3_MANAGED,
versioned: true,
enforceSSL: true,
serverAccessLogsBucket: loggingBucket,
serverAccessLogsPrefix: 's3-web-page-access-logs',
});
...
new s3deploy.BucketDeployment(this, 'pixel-tracking-deploy-webpage', {
sources: [s3deploy.Source.asset('./webpage')],
destinationBucket: bucket,
distribution: distribution,
distributionPaths: ['/*'],
});The CloudFront distribution has a default behavior with an Amazon S3 origin for the static assets of the webpage. The distribution’s cache behavior will default the caching policy to the managed cache policy Cache Optimized and not set an origin request policy when none are specified. An additional behavior is used for the tracking pixel so that only requests to the pixel image receive real-time logs.
const distribution = new cloudfront.Distribution(this,
'pixel-tracking-distribution', {
comment: 'Pixel Tracking Distribution',
defaultRootObject: 'index.html',
defaultBehavior: {
origin: new origins.S3Origin(bucket),
allowedMethods: cloudfront.AllowedMethods.ALLOW_ALL,
viewerProtocolPolicy: cloudfront.ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
additionalBehaviors: {
'1x1.png': {
origin: new origins.S3Origin(bucket),
viewerProtocolPolicy: cloudfront.ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
},
},
},
logBucket: loggingBucket,
logFilePrefix: 'cloudfront-access-logs',
}
);
Enabling CloudFront real-time logs
Real-time logs are configured to write logs to a Kinesis Data Stream, where the sample rate determines the percentage of viewer requests sent to Kinesis Data Streams. Setting to 100 includes every viewer request. The list of the fields specified in the real-time log configuration determine what fields from each request is recorded in the log. This example logs timestamp, c-ip, cs-user-agent, and cs-uri-query. However, each log can contain up to 40 fields.
const dataStream = new kinesis.Stream(this,
'pixel-tracking-data-stream', {
encryption: kinesis.StreamEncryption.MANAGED,
streamMode: kinesis.StreamMode.ON_DEMAND,
}
);
...
const cfnRealtimeLogConfig = new cloudfront.CfnRealtimeLogConfig(this,
'pixel-tracking-real-time-log-config', {
endPoints: [{
kinesisStreamConfig: {
roleArn: pixelProcessingCloudFrontRole.roleArn,
streamArn: dataStream.streamArn,
},
streamType: 'Kinesis',
}],
fields: [
'timestamp',
'c-ip',
'cs-user-agent',
'cs-uri-query',
],
name: `cloudfront-real-time-log-config-${this.stackName}`,
samplingRate: 100,
}
);At this time, AWS CDK doesn’t have direct support to set real-time logs. Therefore, we must use an unescape hatch. An unescaped hatch allows the IaC to go up an abstraction level to Layer 1 (L1), which directly represents AWS CloudFormation resources. Raw overrides are used to add the real-time log config Amazon Resource Name (ARN) to the cache behavior for the pixel image.
const cfnDistribution = distribution.node.defaultChild as cloudfront.CfnDistribution;
cfnDistribution.addPropertyOverride(
'DistributionConfig.CacheBehaviors.0.RealtimeLogConfigArn', cfnRealtimeLogConfig.attrArn
);Data delivery to data lake
Kinesis Data Firehose can read directly from the Kinesis Data Stream and delivers streaming data to data lake. Using the delivery stream saves us from having to write our own Kinesis consumer to write the records to Amazon S3. This data lake can be further enhanced by aggregating log files to reduce object count or use Amazon S3 Intelligent Tiering.
const dataLake = new s3.Bucket(this, 'pixel-tracking-data-lake', {
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
encryption: s3.BucketEncryption.S3_MANAGED,
versioned: true,
enforceSSL: true,
serverAccessLogsBucket: loggingBucket,
serverAccessLogsPrefix: 's3-data-stream-access-logs',
});
const s3Destination = new firehose_destinations.S3Bucket(dataLake, {
dataOutputPrefix: 'year=!{timestamp:YYYY}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/',
errorOutputPrefix: 'fherroroutputbase/!{firehose:random-string}/!{firehose:error-output-type}/!{timestamp:yyyy/MM/dd}/',
});
...
new firehose.DeliveryStream(this,
'pixel-tracking-delivery-stream', {
sourceStream: dataStream,
destinations: [s3Destination],
}
);Cataloging the data with AWS Glue
AWS Glue provides built-in classifiers. However, we use a custom one to help classify the data. This also lets us specify headers, since real-time logs don’t contain headers. The crawler is scheduled to run every 40 minutes on the hour and scans the data lake to automatically infer schemas, partition structure, and populate the Data Catalog.
const classifer = new glue.CfnClassifier(this, 'pixel-tracking-glue-classifer', {
csvClassifier: {
name: 'pixel-tracking-classifier-csv',
delimiter: '\t',
quoteSymbol: '\"',
containsHeader: 'ABSENT',
header: ['timestamp', 'request_ip', 'user_agent', 'uri_query' ],
containsCustomDatatype: ['double', 'string', 'string', 'string'],
customDatatypeConfigured: true,
disableValueTrimming: false,
allowSingleColumn: false,
},
});
// Use Glue crawler to automatically create schema tables
new glue.CfnCrawler(this, ‘pixel-tracking-glue-crawler’, {
role: glueRole.roleName,
targets: {
s3Targets: [{
path: `S3://${dataLake.bucketName}`,
}],
},
databaseName: glueDatabase.databaseName,
description: ‘Glue crawler for pixel tracking data’,
classifiers: [ classifer.ref ],
crawlerSecurityConfiguration: glueSecurityOptions.securityConfigurationName,
recrawlPolicy: {
recrawlBehavior: ‘CRAWL_EVERYTHING’,
},
schedule: {
scheduleExpression: ‘cron(40 * * * ? *)’,
},
tablePrefix: ‘pt_’,
});Walkthrough
The following steps walk you through this implementation.
Prerequisites and deployment
Refer to the project in the GitHub repository for instructions to deploy the solution using AWS CDK. Multiple resources are provisioned for you as part of the deployment, and it takes several minutes to complete. AWS CDK will output the CloudFront distribution’s URL when the deployment is done.
Generating tracking data
To start collecting metrics you must edit the index.html by updating the tracking pixel HTML with your distribution URL. Redeploy the html changes to Amazon S3 and invalidate the file from CloudFront to remove it from the cache. Once redeployed, CloudFront collects data when someone visits the webpage through the embedded HTML image. You can also simulate this by using a curl command. Furthermore, you can go to the AWS Glue page in the AWS Management Console and manually trigger the crawler to run to not wait for the data to propogate through.
curl -G -d 'userid=aws_user' -d 'thirdpartyname=example.hightrafficwebsite.com' https://<your template output domain>Querying the tracking pixel information with Athena
If this is the first-time using Athena in your AWS account, then you must setup an Amazon S3 output bucket for query results. There is a banner to walk you through the setup, but more information can be found on the Getting Started page.
Using the database configured by the solution, the table is populated based on the crawler results.
const glueDatabase = new glue_alpha.Database(this,
'pixel-tracking-database', {
databaseName: 'pixel_tracking_db',
}
);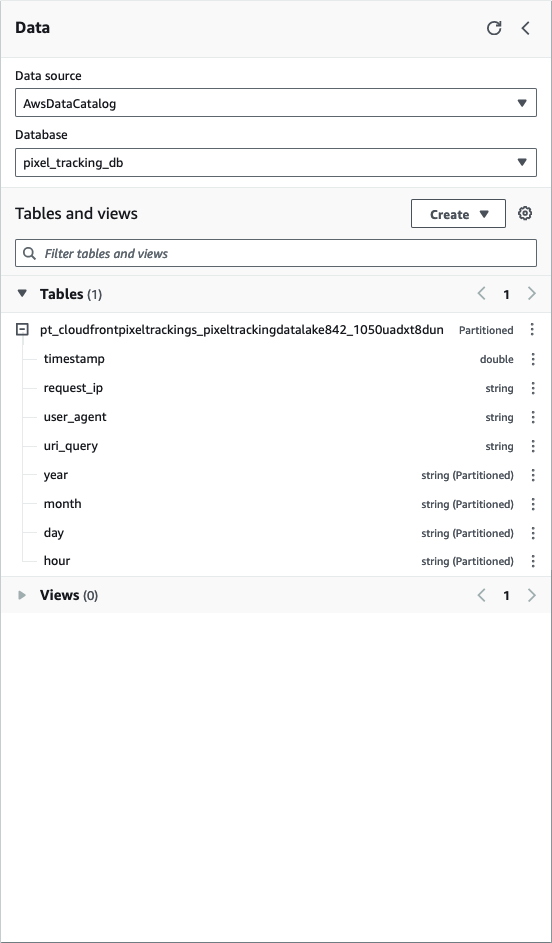
Figure 2: Example of database schema in Athena query editor
The following is an example of the query results from the table showing data collected by the real-time logs.
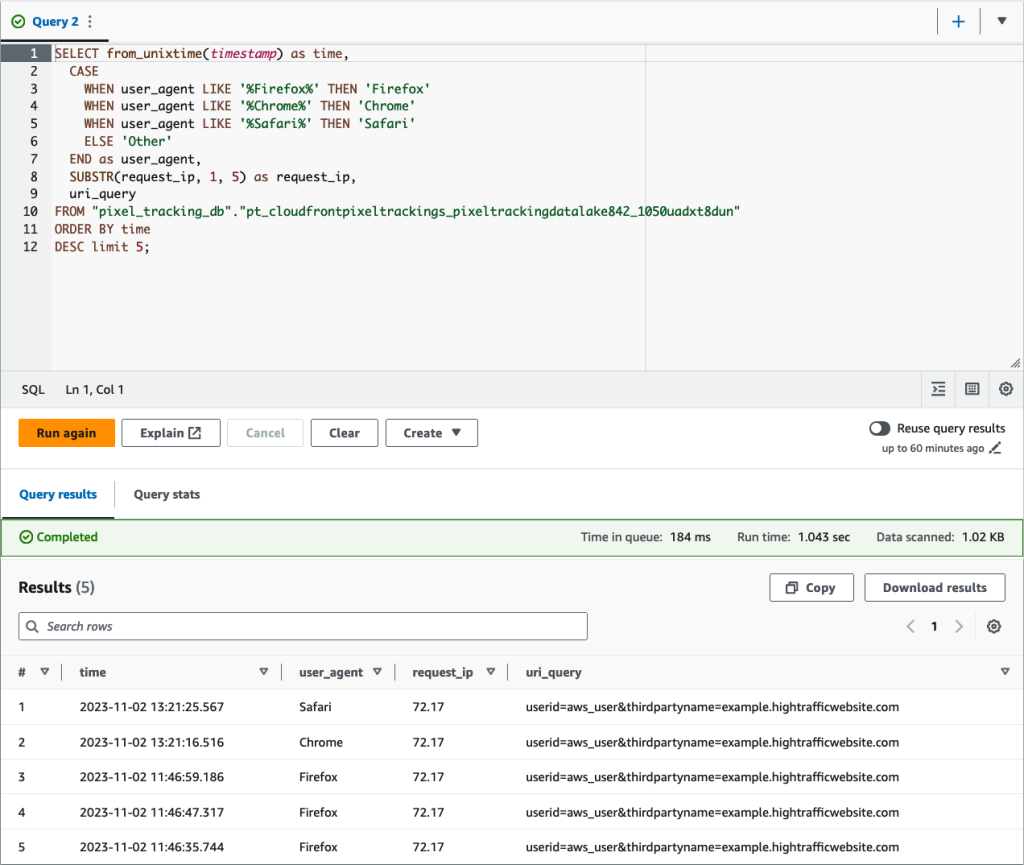
Figure 3: Example of query results for database
Solution considerations
There are a number of considerations to keep in mind when building this type of solution.
Real-time logs are delivered on a best-effort basis
Real-time logs are not intended to be used as a complete accounting of all requests. The log entry for a particular request might be delivered long after the request was processed and, in rare cases, a log entry might not be delivered. A common practice in data analysis is working with a sampling of the data and not the complete set. You must confirm your use-case falls under this common practice and having an incomplete set of data won’t have an impact on your analysis.
General Data Protection Regulation (GDPR) and data sovereignty
Each of the stand alone services used in this solution are configurable to be compliant with GDPR. However, in it’s current configuration, data from users all over the world would be aggregated to a single AWS Region, which may not be in line with your compliance needs. For information on GDPR with AWS, visit GDPR compliance when using AWS services. If you are looking to adopt this solution and have questions regarding GDPR, then we recommend contacting your AWS account manager.
Metrics and use-cases
The provided example only pulls a small set of metrics and can be customized to include additional metrics. The exact metrics to use depend on what use-cases are important to your business and future product iterations. For example, you can use the browser’s user agent to understand what browsers and devices are used to visit your website. This could show that you have a large amount of your traffic coming from mobile, and thus it would be a reason to adopt a mobile-first approach when designing new features. Tracking browser language could be used to determine when your website should support new languages. Supporting additional languages and locales has the potential to increase your customer base, but also engineering complexity. By tracking which pages are visited and what actions are taken, such as add to cart, checkout, and sign up, these metrics provide insight into how customers use your website. By analyzing the data, you can make data-driven decisions and measure how changes and new features impact your customers.
Conclusion
In this post, we demonstrated how to implement the pixel tracking solution with CloudFront real-time logs. Then, CloudFront leverages AWS analytical services Kinesis Data Streams, Kinesis Data Firehose, Amazon S3, Glue Data Catalog, and Athena to enable insights into website activity. This solution’s usage of managed and serverless services makes it advantageous over a traditional beacon server by adopting AWS at scale and operate more efficiently and securely. If you are interested in learning other ways to customize at the edge, then checkout our documentation on customizing with edge functions.

Matthew de Anda
Matthew is a Senior Solutions Architect at AWS, working primarily with startups and customers looking to build and scale serverless applications. Prior to AWS, Matthew worked as an engineering leader in the startup space for 10 years. He lives in Austin, Texas with his family and enjoys cooking and introducing his kids into movies and TV shows he watched at their age.

Nick McCord
Nick is a Solutions Architect at AWS, primarily focusing on startup customers across a diverse set of industries. He regularly engages with founders and executives to provide technical guidance on best practices to fuel efficient long-term growth. Prior to AWS, he’s was a DevOps Engineer and Data Engineering consultant, primarily in the financial services industry. He lives in Virginia with his three dogs and is passionate about early career development.

Rahul Nammireddy
Rahul is a Senior Solutions Architect at AWS, focuses on guiding digital native customers through their cloud native transformation. With a passion for AI/ML technologies, he works with customers in industries such as retail and telecom. Throughout his 23+ years career, Rahul has held key technical leadership roles in a diverse range of companies, from startups to publicly listed organizations, showcasing his expertise as a builder and driving innovation.