AWS Open Source Blog
Enhancing Spinnaker deployment experience of AWS Lambda functions with the Lambda plugin
This post was written by Jason Coffman, Gaurav Dhamija, Vikrant Kahlir, Nima Kaviani, Brandon Leach, Shyam Maniyedath, and Shrirang Moghe.
Spinnaker is an open source continuous delivery platform that allows for fast-paced, reliable, and repeatable deployment of software to the cloud. For many AWS customers, including Airbnb, Pinterest, Snap, Autodesk, and Salesforce, Spinnaker is a critical piece of technology that allows their developers to deploy their applications safely and reliably across different AWS managed services.
In a recent collaboration, Autodesk (an AWS customer heavily utilizing Spinnaker), Armory.io (an AWS strategic partner), and several teams across AWS worked together to provide feature parity for primitives in the AWS Lambda provider relative to other existing providers in Spinnaker. This includes the support for inclusion in native pipelines, blue/green deployments, integration with AWS messaging services (Amazon Simple Queue Service [Amazon SQS] and Amazon Simple Notification Service [Amazon SNS]), Lambda@Edge, and rollbacks.
In the rest of this blog post, we discuss the design choices made in building the Lambda plugin and we walk through a sample scenario of deploying a Lambda function using the plugin. This article assumes that readers have experience in using Spinnaker. For additional information, please refer to the Spinnaker documentation.
Design choices
Three critical design decisions were made as part of designing the plugin:
- Keeping functions as separate first-class citizens in Spinnaker rather than morphing them into the existing Spinnaker primitives (Servers in particular).
- Choosing between declarative deployment of Lambda functions via AWS Serverless Application Model (AWS SAM) definitions and Spinnaker’s AWS CloudFormation provider versus imperative expansion of the deployment process into several custom Spinnaker stages.
- Implementing the new functionality into core Spinnaker microservices rather than pulling it into a custom Spinnaker plugin.
As for choosing between a new Functions primitive and the existing Servers and Server Groups, the message-driven and idempotent nature of Lambda functions prove unique enough capabilities to justify keeping functions as separate primitives in Spinnaker. In particular, the notion of a healthy server versus a healthy function can vary widely as a healthy server assumes reserved compute resources readily available and responsive, whereas a healthy function implies a custom packaged block of code that has been instantiated, invoked, and verified for results at least once.
Between utilizing AWS SAM and the CloudFormation provider and defining custom stages, the choice is slightly harder to make. While declarative deployment has gained significant momentum with the introduction of GitOps and dominance of Kubernetes, legacy Spinnaker pipelines may have hard constraints around the process of defining and composing different stages in Spinnaker imperatively and by relying on the composability features of existing pipelines.
The plugin implements imperative composable stages that enable CRUD (create, read, update, and delete). Imperative deployment of Lambda functions is consistent with how Spinnaker pipelines are used to deploy other resources as well. If you are already using Spinnaker for continuous delivery, the plugin implementation will not be surprising and should blend well with the rest of your pipelines. That said, utilizing AWS SAM to deploy Lambda functions remains a viable feature and can be used where a more declarative approach to deploying Lambda is desired.
Finally, starting from Spinnaker 1.20.6, plugins can be added to most Spinnaker microservices (frontend and backend) to enhance and extend Spinnaker with custom functionality. Benefits of developing features into plugins are multifold, including:
- Plugins decouple the development of the required features from the core components of Spinnaker. As a result, engineering teams can move faster and with less interference to the design of the core components.
- This approach simplifies the design and implementation of core Spinnaker components as feature-specific adjustments to Spinnaker microservices are encapsulated in the respective plugins.
- It reduces complexity in configuration by minimizing what needs to be deployed to the bare minimum required by a Spinnaker user.
The new plugin introduces the following new stages to Orca (the microservice responsible for orchestration of execution flows in the delivery process) as well as to Deck (the UI microservice in Spinnaker):
- Lambda Deployment enables creation of and updates to the Lambda functions.
- Lambda Invoke is used to invoke Lambda functions as part of an automated validation process.
- Lambda Route decides on the routing strategy across various versions of your Lambda deployment.
- Lambda Delete deletes a subset of the deployed versions of a given Lambda function.
The plugin is available in the GitHub organization for Spinnaker Plugins as the AWS Lambda Deployment Plugin where you can find details on configuration and installation of the plugin. Next, we will look at a sample scenario of using the plugin to deploy Lambda functions.
Deploying Lambda functions using Spinnaker
We have modeled a hypothetical Spinnaker pipeline (picture below) for deploying a new Lambda function by stitching together the new stages available via the Lambda plugin. The pipeline will help us achieve the following objectives:
- Deploy a new Lambda function version.
- Route 10% of traffic to this new Lambda function version for canary analysis.
- Validate deployment via canary analysis.
- Route 100% of traffic either to the new Lambda function version or roll back to previous version based on the result of canary analysis.
- Clean up the version that is not needed depending on the results of the canary analysis.

In the following steps, we will dive deep into each stage illustrated in the diagram above and discuss various configuration options available.
Step 1: Add Lambda Deployment stage
The first stage in the pipeline is the Lambda Deployment stage. This stage enables deployment of a new Lambda function version. If the function exists, a new version is added and if it does not exist then a new Lambda function will be created.

This stage includes several fields that allow for configuration of various attributes for an Lambda function. The attributes that can be configured as part of this stage are:
- Required attributes, which include function name, alias name, runtime, Simple Storage Service (Amazon S3) location for function artifact, publish flag, and execution role ARN.
- Optional attributes, which include information about environment variables, tags, resource configuration, network configuration, event-triggers, and error handling configuration.
A few of the key aspects related to this stage includes:
- The name of the deployed function is derived from values for the application name, stack name, and function name.
- Execution role ARN refers to an existing AWS Identity and Access Management (IAM) role, which should have the necessary permissions for services that need to be accessed via the deployed Lambda function.
- If the publish flag is set to true, then a new Lambda function version will be created.
Step 2: Add Lambda Route stage and configure canary testing
The second stage in the pipeline is the Lambda Route stage. This stage allows routing of traffic between different Lambda function versions for canary testing of the new versions deployed as part of the Lambda deployment stage.

This stage supports following strategies for routing of traffic between various versions of Lambda function:
- Simple deployment strategy, which routes 100% of traffic from an existing version to the newly deployed version. It also supports targeting specific versions of a Lambda function based on built-in macros or by explicitly specifying the version to be used.

- Weighted deployment strategy, which routes a specific percentage of traffic to the new version of the Lambda function. We can combine several of these stages to incrementally route traffic to the new version of a Lambda function. Similar to simple deployment strategy, this stage supports routing traffic to various versions based on either built-in macros or by explicitly specifying version numbers. This stage is ideal for canary rollout of updates to your Lambda function.

- Blue/green deployment strategy, which includes health check configuration to test whether the newly deployed Lambda function is working as expected before routing 100% of traffic to the new version. The health check type supported as of this blog writing is Lambda Invocation. This allows for execution of newly deployed versions using a sample payload and checks the response by comparing it with expected output. In case of mismatch, this stage can also optionally delete the new version based the value of On Fail flag.

Step 3: Add Manual Judgement stage for canary analysis
The third stage in the pipeline is a Manual Judgement stage, which allows users to check the result of routing traffic to the new version of the Lambda function as part of canary rollout in the previous stage. In advanced scenarios, this stage could be replaced by an Automated Canary Analysis stage provided by Spinnaker. For the sake of simplicity, we have utilized manual judgement for this blog post.
Based on the outcome of manual or automated canary analysis, the next stage in the pipeline will be invoked.

Step 4: Add Lambda Route stage to configure traffic routing to the new version of the Lambda function on canary analysis success
If the result of the canary analysis is positive, the next stage is where we again use the Lambda Route stage to route 100% of traffic to the newly deployed version. We utilize the simple deployment strategy as part of this stage to shift traffic to the new version.

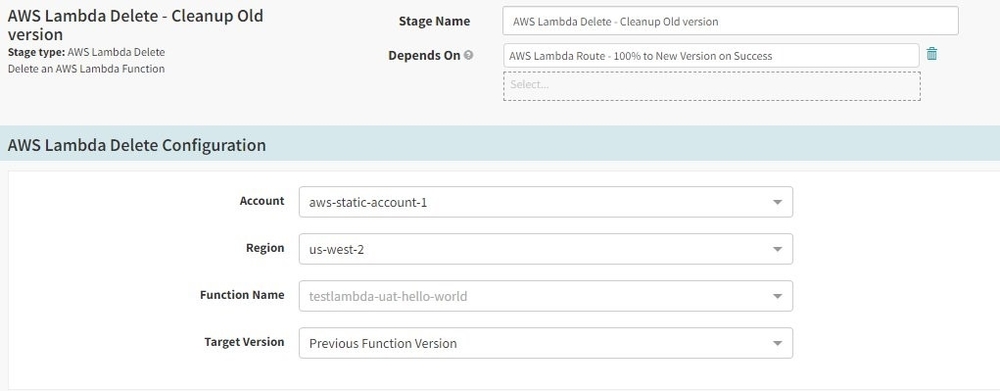
Step 5: Add Lambda Delete stage to clean up previous function version upon canary analysis success
Once traffic has been routed to new version of Lambda function, the final stage is to clean up the previous Lambda function version. This is done by including Lambda Delete stage in our pipeline. Similar to other stages mentioned previously, this stage supports built-in macros as well as ability to specify specific version of Lambda function to be deleted. In our scenario, we have used the Previous Function Version macro to delete the previous version of the Lambda function after the new version has been successfully deployed and all traffic is shifted.
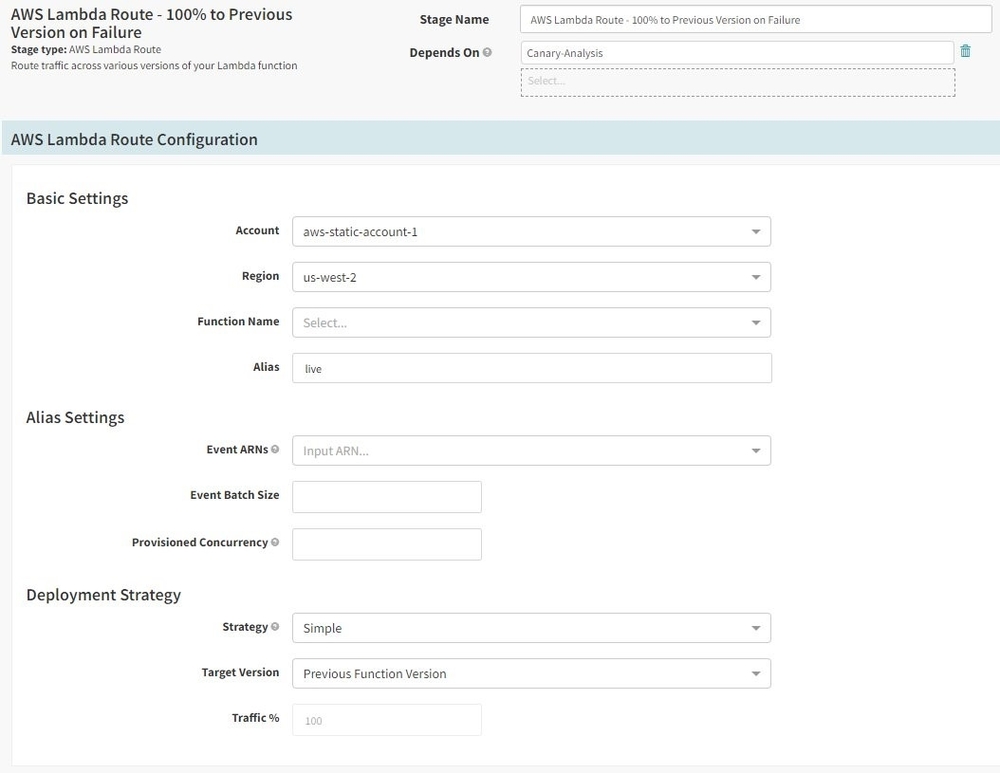
Step 6: Add Lambda Route stage to configure traffic routing to the previous version of Lambda function on canary analysis failure
In case the result of canary analysis is negative, the next stage is where we again use the Lambda Route stage to roll back 100% of traffic to the previous version Lambda function. We utilize the simple deployment strategy as part of this stage to shift traffic back to the previous version.
Step 7: Add Lambda Delete stage to clean up new function version on canary analysis failure
In case of canary analysis failure and after shifting of traffic back to a previous version, this stage will delete the new version that was deployed as part of this pipeline execution. This is done by adding the Lambda Delete stage in the pipeline and by setting the Target Version to the Newest Function Version.

Step 8: Save and execute pipeline and validate rollout of Lambda function in AWS Console
Once we have added all of the stages mentioned in the previous steps, the final step is to execute the pipeline and validate the deployment and rollout of changes in Lambda function in AWS Management Console.
Step 8a. First execution of the pipeline
When the pipeline is executed for the first time, it will create a new version of the Lambda function. The screenshot below shows the execution flow for the successful execution of the pipeline.

Thereafter, we can find the newly created Lambda function in our AWS console.

Step 8b. Subsequent executions of pipeline
On a subsequent execution of the pipeline, we can observe traffic shifting between new and previous versions of the Lambda function in our AWS console. Once the pipeline reaches the canary analysis stage, we can log in to the console and navigate to the Lambda function created by this pipeline.

In the qualifiers drop-down, we see a new version of the Lambda function, and we can observe a 10% to 90% traffic split between the two versions of the Lambda function.

Once we resume the pipeline by marking the canary analysis step as successful, all traffic is routed to the new version and the previous version is deleted, as shown in screenshot below.

This completes our demo for how various stages related to the CRUD and traffic routing operations using the Lambda plugin can be chained together in a Spinnaker pipeline.
Conclusion and future scope
In this blog post, we discussed the collaborative efforts between Autodesk, various AWS teams, and Armory.io to drive the implementation and release of the Lambda plugin for Spinnaker. Development of this plugin follows our mission at AWS to bring AWS best practices into Spinnaker (and other CI/CD) software, while contributing and collaborating with the open source communities, our customers, and partners. As discussed earlier, the AWS plugin has already been donated to the Spinnaker community and is available under the Spinnaker Plugin repository.
Like any other open source project, we greatly appreciate receiving feedback and contributions to further improve this plugin and the general user experience of using Lambda with Spinnaker.
If you have any additional questions or feedback on AWS contributions to Spinnaker, please let us know in the comments.

Shrirang Moghe
Shrirang Moghe spends most of his time in the Autodesk Cloud, making every effort to make Autodesk Cloud Products as available, reliable, and delightful to their customers, and even better than their desktop ancestors. He has spent more than 17 years designing CAD systems and workflows. Talk to him about regionalization, FedRamp, collaboration, cloud security, or your CAD/construction automation needs.

Brandon Leach
Brandon Leach is a software architect at Autodesk and a long time member of the Spinnaker community. His background includes building software delivery automation, data and identity platforms, and large-scale distributed systems engineering. His current focus areas are service quality, engineering efficiency, and enabling Autodesk’s transformation to a platform company.