AWS Public Sector Blog
Building self-recovering systems against technology and business risk with Amazon Bedrock production resilience

Your generative AI production workloads can route around failures automatically. As foundation models (FMs) converge in quality, Amazon Bedrock gives you access to multiple leading models through a single API, so you can build systems that recover from throttling and capacity limits without human intervention. They’re self-healing by design.
The reliability patterns behind this are well understood. But guidance documents don’t prevent outages. Code does. Amazon Web Services (AWS) supports model choice so you can evaluate, switch and adopt new models without rewriting applications or changing infrastructure. For AWS GovCloud (US) customers, where downtime disrupts operations, that model flexibility is an operational necessity.
The question is where in your stack you encode these patterns so they’re enforced automatically on every Amazon Bedrock call. In this post, we explore the answer: proving which models qualify through evaluation, then encoding that knowledge into your application so every call inherits it.
Models have converged—that’s your resilience opportunity
Routing across multiple models only works if those models are good enough. A year ago, falling back from your primary model to a secondary meant accepting a meaningful quality drop. That’s no longer the case.
Standford’s human-centered Artificial Intelligence Index Report 2025 tracks this directly. In 2023, the Elo score difference between the top two models on the Chatbot Arena Leaderboard was 4.9%. By 2024, it had shrunk to 0.7%. As the report puts it: “The AI landscape is becoming increasingly competitive, with high-quality models now available from a growing number of developers.”
When your fallback models score within a percentage point of your primary, routing across them adds resilience without sacrificing quality.
This convergence changes how you should think about model selection. Amazon Bedrock provides secure, simple, and cost-effective access to a variety of models through a single integration path to your workloads, which means you don’t need separate integrations for each provider. For most production workloads, such as summarization, classification, extraction, and question answering, multiple models will meet your quality bar. The strategic advantage isn’t picking the best model. It’s proving that several models are good enough, then routing across them automatically. This matters especially in environments such as AWS GovCloud (US), where AWS is committed to expanding access to leading frontier models and large language models (LLMs) needed for critical workloads. Multi-model routing within Amazon Bedrock lets you take full advantage of that growing model choice as your primary resilience lever.
Model selection should not be a one-time architectural decision. It should be a continuous, evidence-based process—and the evidence says you have more qualified models than you think. The hard part isn’t finding a second model that works. It’s building the systems that prove it works and route to it automatically.
Prove which models qualify before you need them
Benchmark convergence is the macro trend. But your application isn’t a benchmark. You need to prove it for your workload.
Amazon Bedrock Evaluations gives you the framework to do exactly that. You can run automatic evaluation jobs against your own prompt dataset—inputs representative of your actual workload, not generic benchmarks—and score candidate models on metrics such as accuracy, robustness, and semantic correctness. For deeper quality assessment, LLM-as-a-judge jobs use a second model as an evaluator that scores each prompt-response pair and explains its reasoning, using either the built-in metrics of Amazon Bedrock or custom metrics you define for your domain. You set the bar. Any model that passes is production eligible. Any model that fails is not, regardless of its benchmark headlines.
When a new model version drops, you run it through the same process. Think of it the way you think about continuous integration and continuous delivery (CI/CD) for application code. You don’t deploy a new service without running your test suite, and you shouldn’t promote a new model without running your evaluation suite. You can’t benchmark during an outage. The evaluation work has to happen before you need the fallback.
The output of this process informs your routing configuration. Models that pass your quality bar get added to the multiplexer with assigned weights, then you update the model list and weights based on your evaluation results. Models that fail stay out. New versions enter through the same gate.
The following diagram shows how evaluation results inform the multiplexer’s routing configuration.
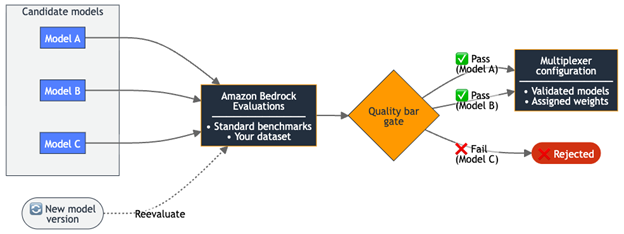
Figure 1: Evaluation-to-routing pipeline— models that pass your quality bar are promoted to the multiplexer configuration directly as a configuration change
Encode best practices where they’ll actually run
When you know which models qualify, you next need to identify where in your stack to enforce the routing, retries, and fallbacks. Each operational best practice maps to a concern that a client facade addresses when it wraps the standard BedrockRuntimeClient:
| Concern | Amazon Bedrock | AWS SDK | Client facade |
| Timeouts | Enforces per-model limits | Bounds individual calls | Moves to a different model when one is slow |
| Retry | – | Retries the same model | Tries a different model |
| Failover | Routes one model across Regions | – | Routes across multiple models |
| Fault isolation | Separates model capacity | Reports errors to caller | Removes unhealthy models from traffic |
| Observability | Amazon Bedrock model invocation logging | Per-call metrics | Per-model health across the full pool |
You integrate the multiplexer one time per application entry point. After that initial integration, model changes, routing adjustments, and new fallback additions are configuration changes, with no code modifications required. When your team adds a new Amazon Bedrock integration such as a summarization endpoint, classification service, or extraction pipeline, the same operational guardrails apply without the new team needing to reimplement them.
The following diagram shows how these concerns compose within the facade around every Amazon Bedrock API call. A request passes inward through each layer to reach Amazon Bedrock, and the response returns outward through the same layers in reverse.
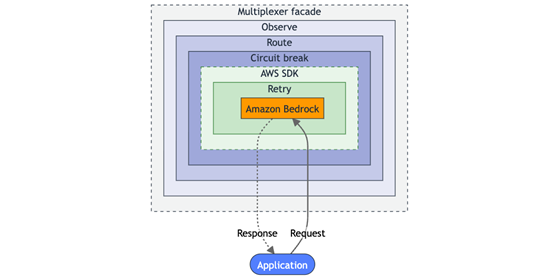
Figure 2: Client facade layers, where each operational best practice becomes a responsibility the facade handles.
Some teams reach for a third-party proxy such as LiteLLM or Portkey to get these capabilities. Proxies add a network hop, introduce a dependency that needs its own availability story, and often abstract away built-in Amazon Bedrock features such as prompt caching and streaming. The AI gateway architecture pattern gives you a unified interface with full SDK capabilities when you need a centralized control plane. For AWS GovCloud (US) customers whose organizational policies require additional approval for third-party proxies, an SDK-based client facade removes that dependency.
What this looks like in practice
Here’s what this pattern looks like as running code. The open source Amazon Bedrock Model Multiplexer is a reference implementation of this client facade pattern, wrapping the BedrockRuntimeClient. It demonstrates weighted multi-model routing, automatic fallback, circuit-breaker logic, and structured observability, which are driven by external configuration.
Here’s how you instantiate the multiplexer with two validated primary models and one fallback:
The MODEL_CONFIG environment variable holds the model list and weights as JSON:
The routing, retry, and circuit-breaking logic is driven by that configuration. When you promote a new model through your evaluation pipeline, you update the environment variable, with no code deploy required. The AWS Lambda function picks up the new configuration on its next cold start, and the application code stays the same.
A request flows through the multiplexer like this:
- The facade starts tracing the full request lifecycle.
- The facade manages failover attempts. On each attempt, it selects a model based on configured weights.
- The circuit breaker checks whether the selected model is healthy enough to receive traffic. If it is, the facade wraps the AWS SDK call with a client-side timeout and sends it to Amazon Bedrock.
- The facade records latency and model health on every call. If the call succeeds, it returns the response to the caller.
- If the call throws a ThrottlingException, the facade skips that model and selects the next weighted model. If a model accumulates repeated failures across requests, the circuit breaker marks that model as temporarily unavailable and the routing layer excludes it from selection until it recovers. When all primary models are exhausted, the routing layer promotes fallback models you already validated through your evaluation pipeline into the selection pool.
The entire sequence, from primary to fallback to success, happens within a single application call. Your application code calls multiplexer.processRequest() one time and gets a response. It never needs to know whether the response came from the primary model, a weighted secondary, or a fallback. The configuration is environment-specific, whether it’s development, production, or AWS GovCloud (US), each with its own model availability and capacity profile. Swap the configuration, and the same application code adapts to a different set of validated models.
Conclusion
LLM operations today look like database operations did 15 years ago: teams know the best practices, but every application implements them differently, or not at all. The facade pattern changes this equation. Instead of six teams writing six different retry implementations, you encode the operational knowledge one time in a shared client facade built on the AWS SDK, and every Amazon Bedrock call in your organization inherits it.
The argument is straightforward. Evaluation data proves which models qualify for your workload. The facade enforces routing, resilience, and observability on every call. Together, they transform LLM operations from reactive incident response into proactive, evidence-based engineering.
The models have converged. The AWS SDK client libraries exist. The evaluation tools are available. The gap is the code between them, and it’s smaller than you think. To get started, explore the open source Amazon Bedrock Model Multiplexer on GitHub and review the Amazon Bedrock documentation.
- Amazon Bedrock Model Multiplexer on AWS Samples
- Get started with the Amazon Bedrock Converse API
- Set up Amazon Bedrock Evaluations for your workload
- Learn about AWS SDK for JavaScript v3 BedrockRuntimeClient
- Learn about AWS SDK for Python (Boto3) BedrockRuntime