AWS Storage Blog
Building an open warehouse architecture: Supabase’s integration with Amazon S3 Tables
As applications scale, developers face a persistent challenge: analytical queries that slow down transactional databases, force them to copy data across multiple proprietary tools, and create disconnected data silos. For the 5 million developers building on Supabase, an open source Postgres development platform, this tension between operational and analytical workloads has become increasingly critical.
The open warehouse architecture addresses this challenge by combining the strengths of two complementary systems: Postgres for fast, reliable transactional operations, and Apache Iceberg format storage on Amazon S3 Tables for analytical workloads. This architecture eliminates the need to choose between operational performance and analytical capability, while maintaining an open standard that prevents vendor lock-in.
This post explores how Supabase implements this architecture using three key components: Supabase Analytics Buckets for analytical storage management, Supabase ETL for near real-time data replication, and a Postgres Foreign Data Wrapper for Iceberg that enables SQL queries access to both operational and historical data.
The challenges with scaling analytics
Companies often start with a single Postgres database for user registration, orders, and core features. As applications scale, data volume grows, which creates three common challenges:
- Performance degradation: At first, you can run reports right on your transactional database. But as data grows, things slow down. PostgreSQL is designed for transactional workloads with fast reads and writes on individual rows, not for scanning and aggregating large volumes of data. Some teams add read-only copies to help, but these are still slow for big questions.
- Redundant cost: When read-only copies aren’t enough, teams add special tools such as data warehouses for historical data or a search tool for logs. This helps with speed, but because these tools often use proprietary storage formats, you must copy your data to use them. This leads to waste. Therefore, companies end up paying to store the same historical records across multiple tools, doubling storage costs for the exact same data.
- Data silo: The cost isn’t just storage—this redundancy leads to disconnected silos. Data locked in incompatible formats makes it hard to see the whole picture. Each tool becomes an isolated “island,” forcing engineers to maintain fragile pipelines just to keep them in sync, and to spend valuable cycles debugging pipeline issues instead of building features.
The solution: Open warehouse architecture
To solve these challenges, companies are adopting an open warehouse architecture, as shown in the following figure.
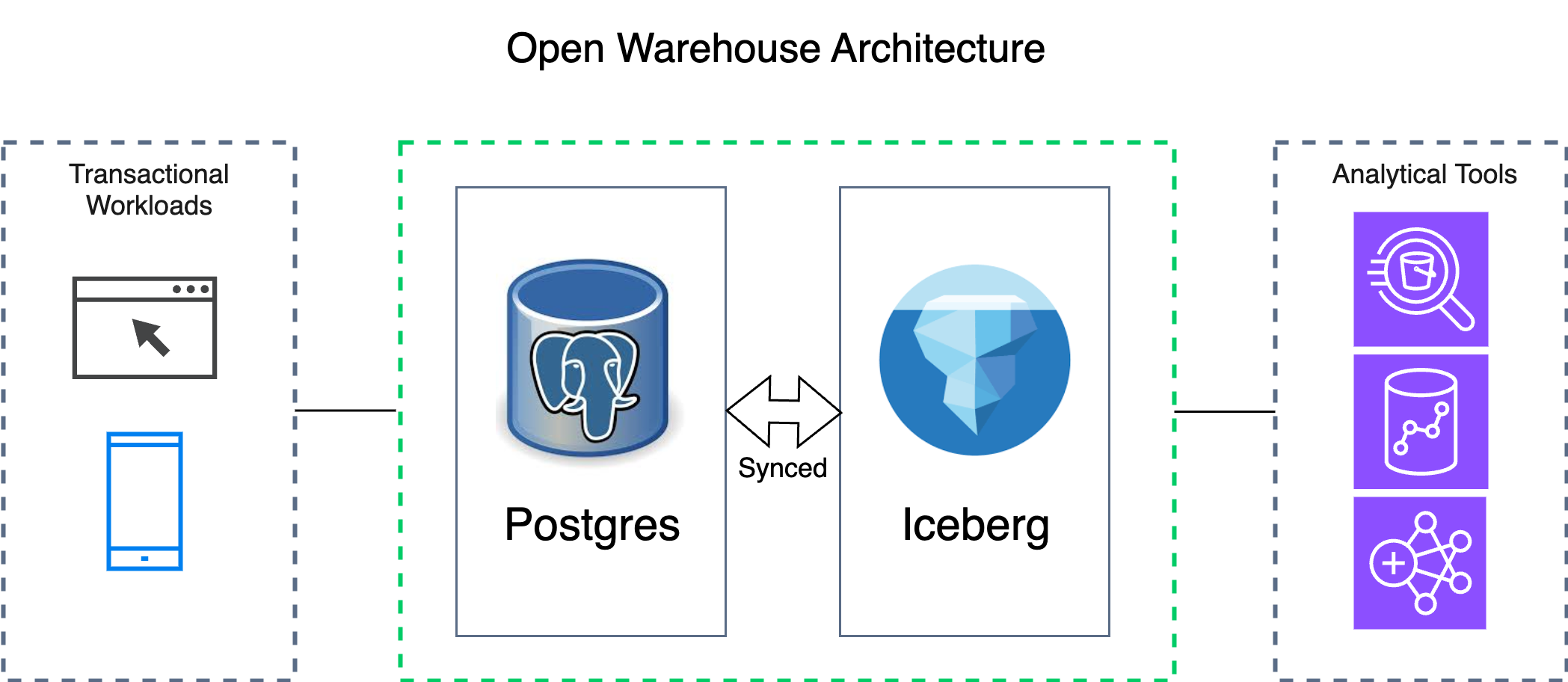
This architecture relies on two open technologies to handle distinct workloads:
- Postgres as the transactional database: Applications continue running on Postgres, benefiting from its speed and reliability for critical transactional workloads.
- Apache Iceberg as the analytical storage: Iceberg provides a scalable, high-performance format for analytical data. It provides reliability and consistency for large datasets while maintaining universal accessibility. It is an open standard, thus your data remains portable for any supported tool to access it.
Applications write to Postgres, while data is continuously mirrored to Apache Iceberg tables. Then, teams can query the analytical data using their preferred tools, such as Amazon Athena, Amazon Redshift, Spark, or Trino.
This architecture resolves the scaling challenges described in the previous section:
- It addresses the performance degradation by isolating heavy analytical queries from the transactional database.
- It reduces redundant cost by storing data in cost-effective object storage instead of copying data to proprietary warehouses.
- It resolves the data silo by introducing the open standard analytical data storage layer. This provides teams with the flexibility to choose any analytical tool so that every query accesses the same “single source of truth.”
Implementation: Automating with Supabase and S3 Tables
Implementing this architecture manually requires managing Iceberg file maintenance and building reliable replication pipelines. Supabase automates the architecture with three components, shown in the following figure.
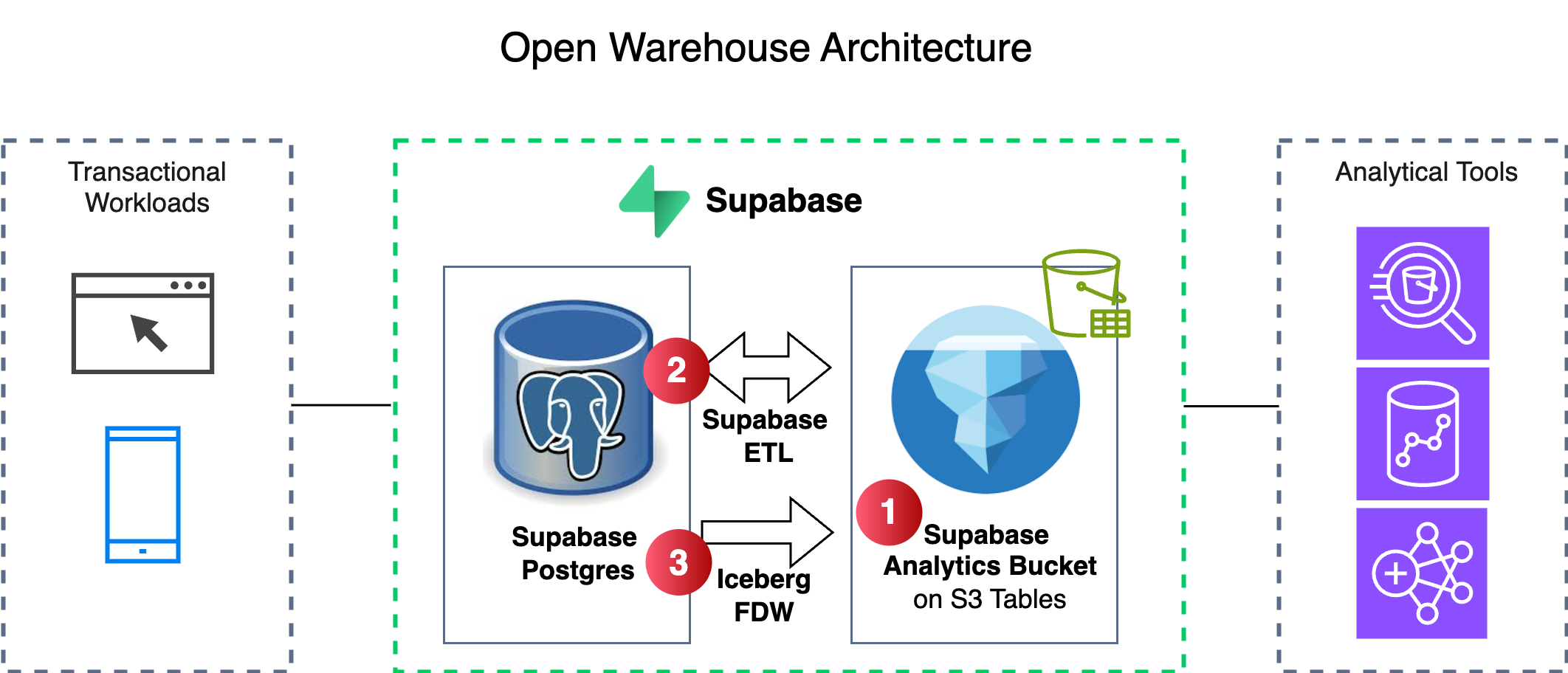
1. Supabase Analytics Buckets (through S3 Tables)
Query performance on Iceberg tables depends heavily on file layout. Without maintenance, data becomes fragmented into thousands of small files, which slows down reads. Supabase Analytics Buckets use S3 Tables, a purpose-built bucket type that solves this through automated maintenance, while providing robust security.
Automated maintenance:
- Automatic compaction: S3 Tables continuously runs background jobs to merge small data files into larger, optimized files. This maintenance process means that queries remain fast without needing you to manage maintenance servers.
- Snapshot management: S3 Tables handles the expiration of old data snapshots to manage storage costs effectively.
Security:
- Encryption: S3 Tables always protects data in transit using Transport Layer Security (1.2 and above) through HTTPS. For protecting data at rest, it supports server-side encryption with Amazon S3 managed keys (SSE-S3) and server-side encryption with AWS Key Management Service (AWS KMS) keys (SSE-KMS).
- Access control: It enables granular access control, so that you can grant permissions down to the specific table or namespace level.
2. Supabase ETL
Moving data from a transactional database to an analytical store often necessitates building and maintaining fragile “glue code.” Supabase ETL eliminates this engineering burden by providing a dedicated ETL pipeline between Supabase Postgres and Supabase Analytics Buckets that hooks directly into Postgres internals:
- Near real-time replication: Instead of relying on slow batch jobs or polling, Supabase ETL reads the Postgres Write Ahead Log (WAL). It streams changes (inserts, updates, deletes) to Iceberg tables, so that analytics are available in near real-time.
- Seamless developer experience: Traditional pipelines take months to build and test. You can use Supabase ETL to enable this replication with a single click in the dashboard. It abstracts away the complexity of managing replication slots and stream processing, so that teams can focus immediately on generating insights.
3. Postgres Foreign Data Wrapper for Iceberg
This extension uses the Postgres Foreign Data Wrapper (FDW) mechanism to map Iceberg tables as if they were local tables. This occurs whether they’re stored in Supabase Analytics Buckets, or any other iceberg format storage.
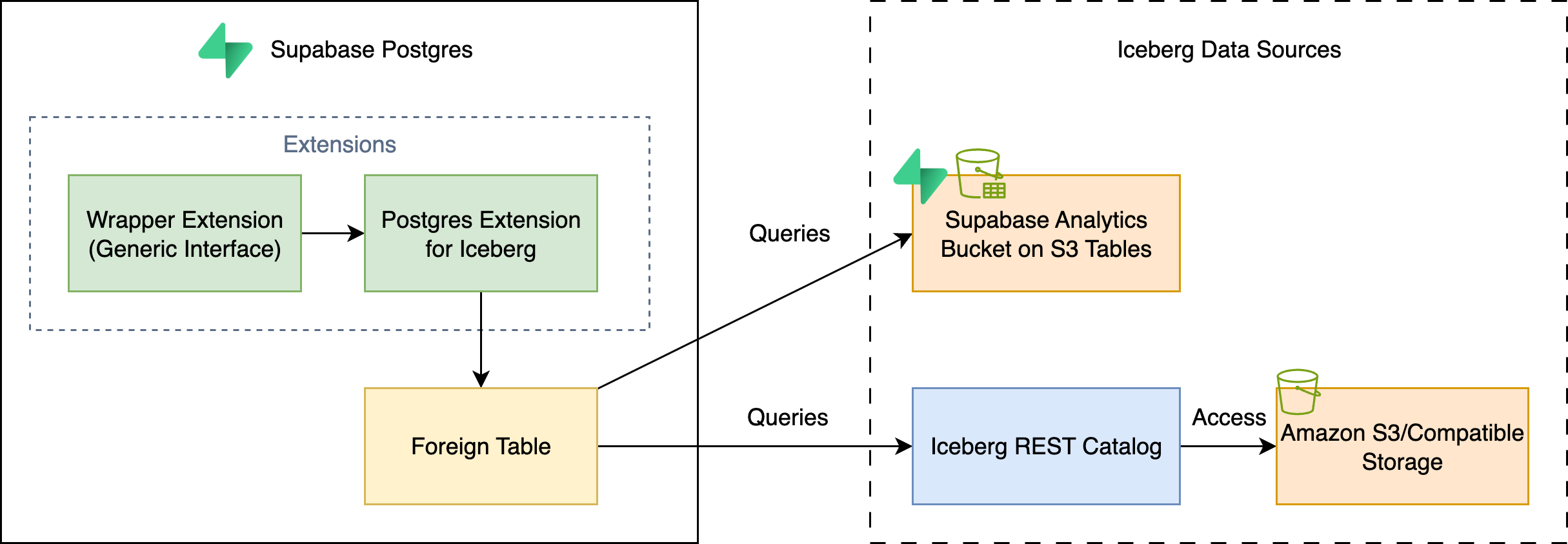
- Unified SQL interface: You can write standard SQL queries that access both your local operational data and your historical data.
Architecture in action: Scaling e-commerce
Consider a high-growth e-commerce platform facing performance degradation. As the business grows, internal teams—Data Science, BI, and Operations—start running complex analytical queries directly on the Postgres database to track trends and behavior. These heavy queries compete for CPU and memory with active customer transactions, slowing down the checkout experience for users.
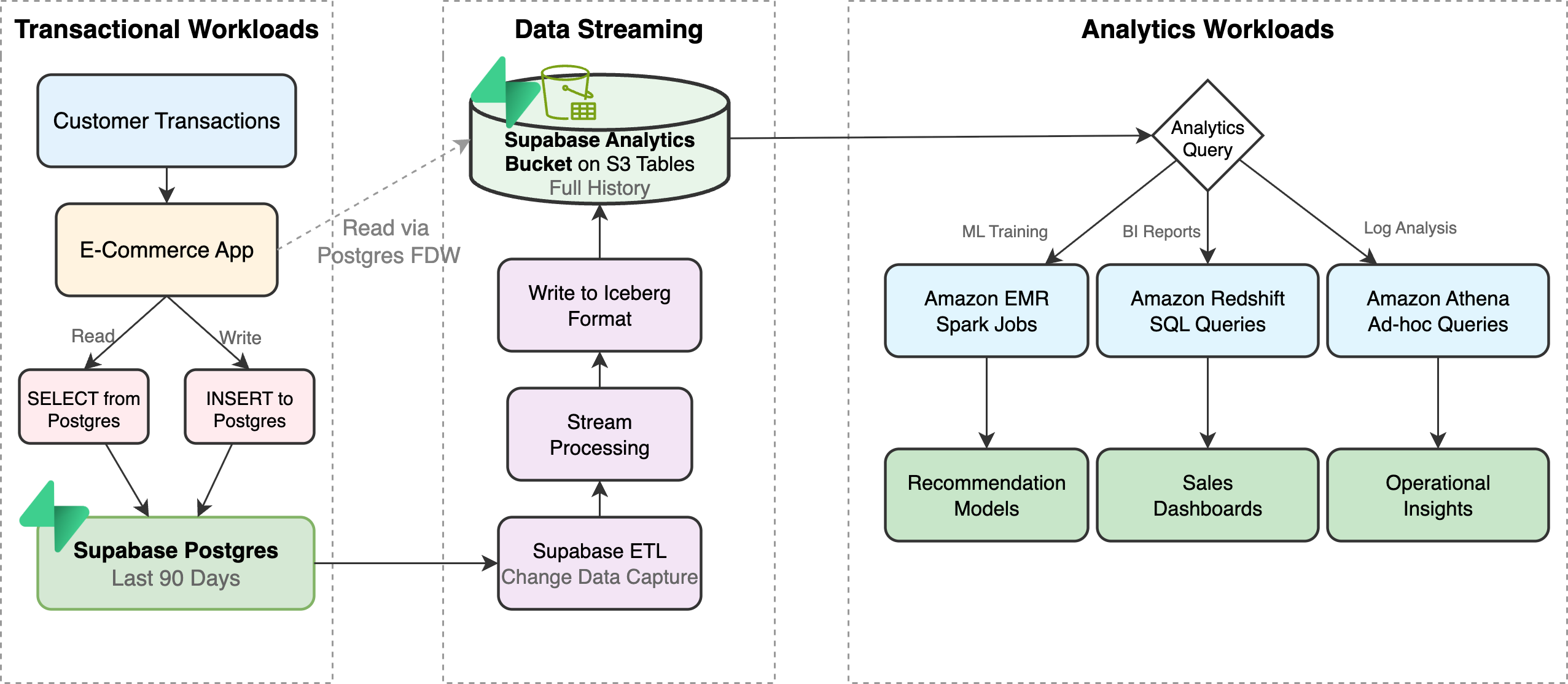
To restore performance without losing data access, the engineering team adopts a tiered storage strategy, also shown in the preceding figure:
- Supabase ETL streams new transactions to a Supabase Analytics Bucket (Iceberg format) in near real time, creating a record of the platform’s history.
- The team configures the primary Postgres database to automatically delete records older than a specific timeframe (for example 90 days). This keeps active tables lean.
Teams connect analytical tools to the Supabase Analytics Bucket:
- Data Science teams use Amazon EMR (Spark) to train recommendation models on the full history.
- BI teams use Redshift to generate sales trend reports.
- Operations teams use Athena to analyze logs.
Application uses the Postgres FDW for Iceberg for the following:
- Pre-calculated metrics: Instead of calculating expensive metrics such as “Year-over-Year Spending” inside Postgres, analytical tools can pre-calculate them in Iceberg. Then, the app queries these results directly through the FDW.
- Cold data lookup: If a user needs to view a specific invoice from five years ago, then the application fetches the raw record directly from the Supabase Analytics Bucket. The user gets seamless access to their full history, while the transactional database remains lean and fast.
Conclusion
The open warehouse architecture solves a fundamental challenge in modern data systems: maintaining operational performance while enabling analytics at scale. This approach separates transactional and analytical workloads through open standards, which removes the traditional trade-offs between speed, cost, and flexibility.
Supabase’s implementation using Amazon S3 Tables demonstrates how this works in practice. Postgres handles transactional operations, while Apache Iceberg tables on S3 Tables provide the analytical scale—all without managing complex pipelines or duplicating data. Data teams can run sophisticated analytics using their preferred tools (for example Spark, Amazon Athena, and Amazon Redshift), while application developers continue building with familiar Postgres workflows, all accessing the synced underlying data through open standards.
Want to dive deeper? Check out these resources: