AWS Storage Blog
Using AWS Snowball to migrate data to Amazon S3 Glacier for long-term storage
Customers often choose to move large amounts of on-premises data to Amazon S3 Glacier. These customers choose to use S3 Glacier for its ability to reliably and securely store any amount of data at a cost-effective price, while being designed for 11 9’s of data durability. This makes S3 Glacier a popular choice for long-term storage and backup. However, network connectivity and bandwidth can be a challenge when moving large amounts of data out of your on-premises data store to Amazon S3. Slow connectivity leads to long transfer times. To overcome challenges in bandwidth-constrained environments, customers can use AWS Snow Family to migrate their data. Snowball Family devices can migrate a few terabytes of data up to hundreds of petabytes of data with devices such as AWS Snowcone and AWS Snowball Edge.
In this blog post, we explore how customers can move large amounts of on-premises data to S3 Glacier using a Snowball Edge. We also review data migration best practices and address frequently asked questions. Both the Snowball Edge and S3 Glacier have a few unique features and capabilities to consider when migrating your data.
Preparing your migration
The process of ordering a Snowball Edge through the AWS Snow Family console is simple. Start by choosing the Import into Amazon S3 job type, enter your shipping address, select the Snow Family device you’d like to order, and set your security preferences to create a job. You have the option to use an existing S3 bucket as a target for the Snowball import. Be mindful that any existing objects with the same name as the newly imported objects will be overwritten. Once you receive the Snowball Edge, follow this documentation to upload your data, and ship the Snowball Edge back. While following these steps allow you to migrate your data to AWS, we recommend you consider several details such as file sizes and future access patterns, before you order a Snowball Edge. For the scope of this blog, we assume you have explored the various Amazon S3 storage classes and have decided that S3 Glacier is the right choice for your data migration.
Before you order your Snowball Edge, consider the following three items as part of your planning and preparation phase.
- How will I migrate and store data while being cost-conscious?
- How will I comply with future data retrieval requirements?
- How will I validate data integrity?
How will I migrate and store data while being cost-conscious?
When migrating data to S3 Glacier using a Snowball Edge, the two important factors that impact cost are the number of files and the size of the files. There is material impact of having a large number of smaller files or a small number of larger files. In both cases, it is important to understand how these combinations impact your costs and migration timeline before you begin your data migration. The following table presents a simplified version of the pros and cons of each approach.
| Large number of small files (over 500,000 files) | Small number of large files | |||
| Snowball Edge | Pros | No preprocessing is needed for data transfer. | Pros | Total copy operation overhead is minimized, decreasing data transfer time. |
| Cons | Copy operation overhead for each file increases data transfer time due to decreased throughput. | Cons | Preprocessing is required, which allow faster data transfer time due to higher throughput. | |
| S3 Glacier | Pros | Retrieve individual files at lower retrieval costs. | Pros | Lower costs to transition data to S3 Glacier. |
| Cons | Total lifecycle costs to transition data into S3 Glacier increase. Metadata overhead increases storage per file, increasing storage costs. | Cons | Retrieving individual files requires large batched file retrieval, which increases retrieval costs. | |
Migration costs
Having a large number of files is detrimental to the upload/download speeds as each file adds to the processing time overhead. When transferring data to your Snowball Edge, we recommend limiting yourself to 500,000 files or folders within each directory. We also recommend that all files transferred are no smaller than 1 MB in size so that you optimize your migration performance. If you have a large number of files smaller than 1 MB in size, we recommend following our best practice documentation of batching files into larger archives before transferring them onto a Snowball device. For this process, you can use the Snowball uploader script that is designed to do exactly this – help batch and move many small files efficiently with a single script. However, if your ultimate goal is to store data in S3 Glacier as individual files, you can first batch your files to reduce the data transfer time to the Snowball Edge. You can then have your files auto extract when data is imported into S3 as described in this documentation. Choosing this method of auto extracting files from your Snowball Edge to S3 will incur both PUT and lifecycle transition request costs for every file.
Batching your files also has direct monetary impact as well. Both PUT requests from your Snowball Edge to S3 and lifecycle transition policy from S3 to S3 Glacier are charged per request, and not by file size. The cost scales linearly with the increased number of files. Batching files will not only speed up the transfer, but will also minimize request costs that you incur during the migration process.
Storage costs
We recommend batching smaller files to have a smaller number of large files for minimizing storage costs as well. When storing files in S3 Glacier, S3 adds 40 KB of chargeable overhead for metadata, with 8 KB charged at S3 Standard rates and 32 KB charged at S3 Glacier rates. Visit the S3 pricing page for more detail. You will be charged for this data per file stored in S3 Glacier. While the storage charge for 40 KB metadata is minimal, it does scale linearly with the number of files, just like the previously mentioned request costs. Therefore, a smaller number of files help save on storage costs.
Lifecycle rules
Currently, there is no way of uploading objects directly to S3 Glacier using a Snowball Edge. Thus, you first have to upload your objects into S3 Standard, and then use S3 lifecycle policies to transition the files to S3 Glacier. In this scenario, you will want to minimize the time spent in S3 Standard for all files to avoid unintended S3 Standard storage charges. To do this, we recommend using a zero-day lifecycle policy. From a cost perspective, when using a zero-day lifecycle policy, you are only charged S3 Glacier rates. When billed, the lifecycle policy is accounted for first, and if the destination is S3 Glacier, you are charged S3 Glacier rates for the transferred files. Therefore, it is important to set up zero-day lifecycle policies on your bucket before sending the Snowball Edge back to AWS.
Here are the steps for setting up lifecycles rules on your S3 bucket.
1. Sign in to the AWS Management Console and access the Amazon S3 console. Choose the name of the bucket that you want to create a lifecycle rule for.
2. Select the Management tab, and choose Create lifecycle rule.

Figure 1: Management tab of the Amazon S3 Management Console for creating a lifecycle rule
3. In Lifecycle rule name, enter a name for your rule.
4. Choose the scope of the lifecycle rule. In this example, we apply the lifecycle rule to all objects in the bucket.

Figure 2: Creating a zero-day lifecycle rule
5. Under Lifecycle rule actions, choose the actions that you want your lifecycle rule to perform. We will be transitioning current versions of objects between storage classes, i.e. any newly uploaded objects will be transitioned to S3 Glacier.
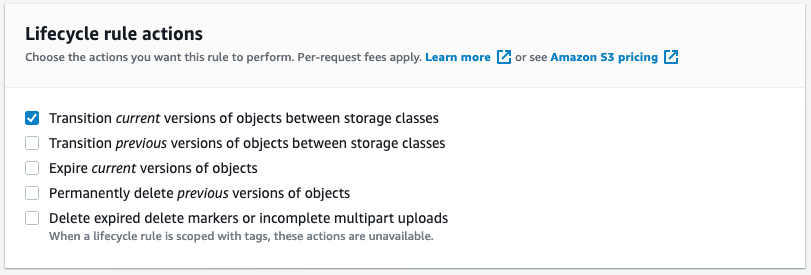
Figure 3: Configuring lifecycle rule action
6. Select which storage class you will transition the objects to. In this instance, we select S3 Glacier. To achieve the zero-day lifecycle policy, we type 0 in the Days after object creation. Be aware that there is a lifecycle transition request charge. For example, in the Ohio (US-EAST-2) Region, it is $0.05 to transition 1,000 objects. This is why it is recommended to batch many small files together, in order to reduce the transition costs.
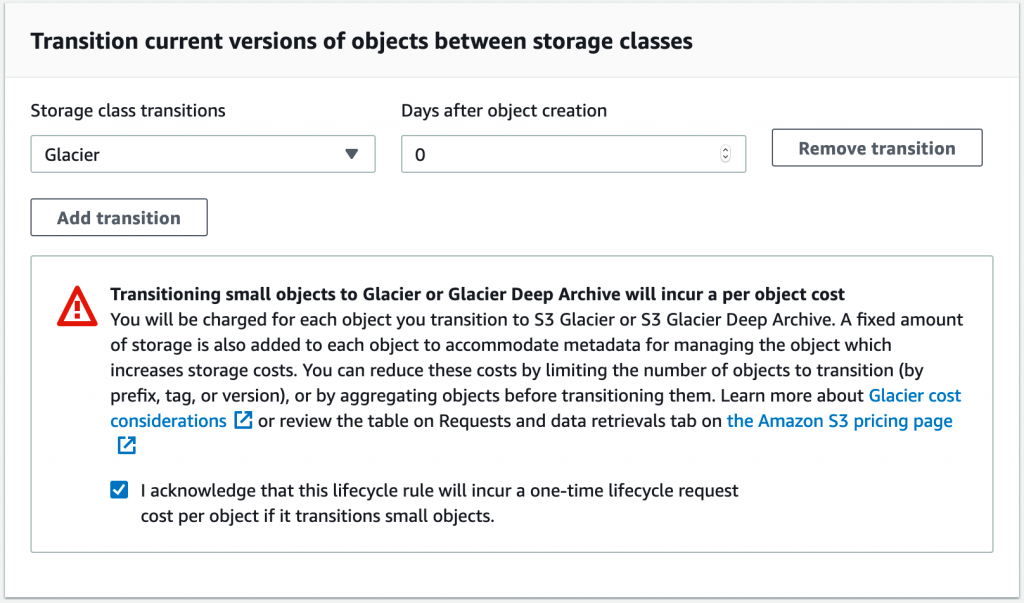
Figure 4: Confirming the creation of zero-day lifecycle rule
7. Choose the Create rule button to enable the lifecycle policy. If the lifecycle policy has been successfully created, you will see the new policy in the Management tab under Lifecycle rules.

Figure 5: Verifying the creation of zero-day lifecycle rule
How will I comply with future data retrieval requirements?
If you expect to access data infrequently and with advanced notice, batch your files to reduce the total number of files and reduce both cost and processing time. However, this is not always the best option. You can occasionally encounter situations where you must access usage logs on a short notice such as responding to an audit or responding to a client request to retrieve archived files. Depending on the urgency, the data retrieval costs for S3 Glacier are priced as follows.
| Retrieval time | Data retrieval requests (per 1,000 requests) | Data retrievals (per GB) | |
| Expedited | 1–5 minutes | $10.00 | $0.03 |
| Standard | 3–5 hours | $0.05 | $0.01 |
| Bulk | 5–12 hours | $0.025 | $0.0025 |
As you may have noticed by looking at the preceding chart, it is not economical to retrieve large amounts of data with expedited retrieval time. Given the pricing structure, it is advantageous to retrieve a single file rather than many smaller files that add up to the same size. However, if you are looking for a single file, it is better to retrieve only that file instead of needing to retrieve the entire batch, only to access a single file within the batch. In the preceding section, we discussed how it is better to batch files for migration and storage.
To retrieve data, there are clear tradeoffs between larger files and smaller files. If you foresee yourself needing to retrieve individual files on a short notice, you may want to consider storing the data individually and avoid batching. If you do not need to retrieve individual files, you should prioritize optimizing storage and migration costs over access costs by batching smaller files together.
How will I validate data integrity?
We often receive requests from customers for guidance on how to validate the integrity of the file and confirm that their data has been migrated securely and safely to S3 Glacier. AWS has multiple checks in place to validate the integrity of the file before your files reach S3 Glacier. When your files are being transferred to the Snowball Edge, checksums are created for each file copied. Batched files will receive one checksum for each batch. These checksums are used for validating the integrity of the files as they are imported into S3. If the checksum does not match for a file, the file is not imported into S3 at all. If you would like to validate the integrity of the files at each step, you have the option of keeping inventory of the files and the MD5 hash prior to the transfer. You can then use this hash for validation. You can read more about this process in the support documentation. After you have successfully imported data into S3 with a Snowball Edge, you will have access to a job report, which includes the failure logs. This allows you to see if any files failed the validation checks during the transfer.
Conclusion
In this blog post, we covered best practices when migrating data from your environment to S3 using a Snowball Edge, and highlights additional details that should be considered during the data migration process. While S3 and Snowball greatly simplify the process of transferring and storing TBs to PBs of data in AWS, optimizations can be made based on each use case. We discussed migrating and storing data in a cost-effective manner, optimizing storage for data retrieval requirements, and verifying data integrity. Considering these details will allow you to transfer your files with confidence and minimize unintended expenses for your long-term storage.
Thanks for reading this blog post! If you have any comments or questions, don’t hesitate to leave them in the comments section.