亚马逊AWS官方博客
使用 AWS SCT 将大型数据仓库从 Greenplum 迁移到 Amazon Redshift – 第 2 部分
在这个由多部分组成的系列的第二篇文章中,我们将分享选择最佳 Amazon Redshift 集群、数据架构、转换存储过程、广泛用于 SQL 转换的兼容函数和查询方面的最佳实践,以及优化表列数据类型长度的建议。您可以参阅本系列的第一篇文章,了解有关规划、运行和验证使用 AWS Schema Conversion Tool (AWS SCT) 将大规模数据仓库从 Greenplum 迁移到 Amazon Redshift 的指南。
选择您的最佳 Amazon Redshift 集群
Amazon Redshift 有两种类型的集群:预置和无服务器。对于预置集群,您需要使用所需的计算资源进行同样的设置。Amazon Redshift 无服务器可以在云中运行任何规模的高性能分析。有关更多信息,请参阅推出 Amazon Redshift 无服务器 – 能以任何规模运行分析,而无需管理数据仓库基础设施。
Amazon Redshift 集群由节点组成。每个集群都有一个领导节点和一个或多个计算节点。领导节点接收来自客户端应用程序的查询,解析查询,并制定查询运行计划。然后,领导节点协调这些计划与计算节点的并行运行,并聚合这些节点的中间结果。随后,它将结果返回到客户端应用程序。
在确定集群类型时,请考虑以下几点:
- 估计压缩的输入数据大小、vCPU 和性能。在撰写本文时,我们建议使用具有托管存储的 Amazon Redshift RA3 实例,以独立扩展计算和存储,从而实现快速查询性能。
- Amazon Redshift 根据您的数据大小提供自动化“帮我选择”集群。
- 云 Amazon Redshift 数据仓库的一项主要优势在于,您不再受制于硬件和传统数据仓库之类的商品。为了加速创新,您可以选择尝试不同的集群选项,并根据性能和成本选择优化的集群选项。
- 在开发或试运行时,通常可以从较少数量的节点开始。在进入生产环境时,您可以根据自己的使用模式调整节点数量。在调整集群规模时,我们建议您选择预留实例类型,以进一步降低成本。面向公众的实用程序 Simple Replay 可通过重放客户工作负载,帮助您确定不同集群类型和大小的性能。对于预置集群,如果您打算使用推荐的 RA3 实例,可以比较不同的节点类型,以确定正确的实例类型。
- 根据工作负载模式,Amazon Redshift 支持集群的大小调整、暂停和停止及并发扩展。Amazon Redshift 工作负载管理 (WLM) 可实现有效而灵活的内存与查询并发管理。
使用 AWS SCT 创建数据提取任务
借助 AWS SCT 提取代理,您可以并行迁移源表。这些提取代理使用数据源上的有效用户进行身份验证,以允许在提取期间调整该用户可用的资源。AWS SCT 代理在本地处理数据,并将其上传到 Amazon Simple Storage Service (Amazon S3)(通过网络)(通过 AWS Direct Connect)。我们建议您在安装了 AWS SCT 代理的 Greenplum 计算机与您的 AWS 区域之间保持一致的网络带宽。
如果您有大约 2000 万行或 1 TB 大小的表,可以使用 AWS SCT 上的虚拟分区功能从这些表中提取数据。这将创建几个子任务,并使该表的数据提取过程并行化。因此,我们建议为迁移的每个架构创建两组任务:一个用于小型表,另一个用于使用虚拟分区的大型表。
有关更多信息,请参阅创建、运行和监控 AWS SCT 数据提取任务。
数据架构
要简化数据架构并使其现代化,请考虑以下几点:
- 建立问责制和权力,以强制执行企业数据标准和政策。
- 规范企业与业务部门和职能部门之间的数据和分析运营模式。
- 通过数据资产和工具或技术的合理化和现代化来简化数据技术生态系统。
- 开发组织结构以促进业务和交付团队之间更稳健的整合,并构建面向数据的产品和解决方案,以解决整个生命周期中的业务问题和利用机会。
- 定期备份数据,以便在出现问题时能够重播。
- 在规划、设计、执行及整个实施和维护过程中,确保添加数据质量管理以实现预期的成效。
- 轻松是简单、快速、直观、低成本解决方案的关键。简单比复杂要好得多。简单让大胆思考成为可能(Invent and Simplify 是 Amazon 的另一项领导原则)。通过仅迁移表和架构中使用的必要数据,简化旧版流程。例如,如果您要对增量数据执行截断和加载,请标识水印并仅处理增量数据。
- 您的使用案例可能需要记录级插入、更新和删除,以满足隐私法规和简化管道需求;简化文件管理和近实时数据访问;或简化更改数据捕获 (CDC) 数据管道开发。我们建议根据您的使用案例,使用有针对性的工具。AWS 提供了一些选项,用于将 Apache HUDI 与 Amazon EMR 和 AWS Glue 结合使用。
迁移存储过程
在本部分中,我们将分享存储过程从 Greenplum 迁移到 Amazon Redshift 的最佳实践。具有复杂业务逻辑的数据处理管道通常使用存储过程来执行数据转换。我们建议您使用 AWS Glue 或 Amazon EMR 等大数据处理来实现提取、转换和加载 (ETL) 作业的现代化。相关详情,请参阅使用 Amazon Redshift 进行高性能 ETL 处理的八大最佳实践。对于时间敏感的迁移到云原生数据仓库(如 Amazon Redshift),在云原生 ETL 工具中重新设计和开发整个管道可能非常耗时。因此,将存储过程从 Greenplum 迁移到 Amazon Redshift 存储过程可能是正确的选择。
要成功迁移,请务必遵循以下 Amazon Redshift 存储过程最佳实践:
- 在创建存储过程时指定架构名称。这有助于提高架构级别安全性,您可以强制执行授权或撤销访问控制。
- 为防止命名冲突,我们建议使用前缀 sp_ 命名过程。Amazon Redshift 专门为存储过程保留 sp_ 前缀。通过在过程名称前面加上前缀 sp_,可以确保过程名称不会与任何现有或将来的 Amazon Redshift 过程名称冲突。
- 使用存储过程中的模式名称限定数据库对象。
- 遵循所需的最低访问规则并撤销不需要的访问权限。对于类似实施,确保存储过程运行权限未向 ALL 开放。
- SECURITY 属性控制过程访问数据库对象的权限。创建存储过程时,可以将 SECURITY 属性设置为 DEFINER 或 INVOKER。如果指定 SECURITY INVOKER,则该过程将使用调用该过程的用户的权限。如果指定 SECURITY DEFINER,则该过程将使用过程所有者的权限。INVOKER 是默认设置。有关更多信息,请参阅存储过程的安全性和权限。
- 在涉及存储过程时管理事务非常重要。有关更多信息,请参阅管理事务。
- TRUNCATE 在存储过程中隐式发出提交。它通过提交当前事务并创建新事务来干扰事务块。使用 TRUNCATE 时要谨慎行事,以确保它永远不会破坏事务的原子性。这也适用于 COMMIT 和 ROLLBACK。
- 遵守游标约束并理解使用游标时的性能注意事项。处理大型数据集时,应使用基于集的 SQL 逻辑和临时表。
- 避免在存储过程中进行硬编码。使用动态 SQL 在运行时动态构建 SQL 查询。确保对动态 SQL 进行适当的日志记录和错误处理。
- 对于异常处理,可以将 RAISE 语句作为存储过程代码的一部分编写。例如,您可以使用自定义消息引发异常,或者在日志记录表中插入一条记录。对于像 WHEN OTHERS 这样的未处理异常,使用 SQLERRM 或 SQLSTATE 等内置函数,将其传递给调用应用程序或程序。在撰写本文时,Amazon Redshift 限制从异常块调用存储过程。
序列
您可以使用 IDENTITY 列、系统时间戳或纪元时间作为确保唯一性的选项。IDENTITY 列或基于时间戳的解决方案可能具有稀疏值,因此,如果您需要连续的数字序列,则需要使用专用数字表。您还可以对整个集使用 RANK() 或 ROW_NUMBER() 窗口函数。或者,从表的现有 ID 列中获取高水印线,并在插入记录时递增值。
字符数据类型长度
Greenplum char 和 varchar 数据类型长度根据字符长度指定,包括多字节字符长度。Amazon Redshift 字符类型根据字节定义。对于在 Greenplum 中使用多字节字符集的表列,Amazon Redshift 中转换后的表列应为源数据的实际字节大小分配足够的存储空间。
一种简单的解决方法是将 Amazon Redshift 字符列长度设置为比相应 Greenplum 列长度大四倍。
最佳实践是使用尽可能小的列大小。Amazon Redshift 不会根据属性的长度分配存储空间,而是根据存储字符串的实际长度分配存储空间。但是,在运行时,在处理查询时,Amazon Redshift 会根据属性的长度分配内存。因此,从性能角度来看,不将默认大小设置为大四倍会有所帮助。
一种有效的解决方案是分析生产数据集并确定 Greenplum 字符列的最大字节大小长度。添加 20% 的缓冲区以支持表的未来增量增长。
要得出现有列的实际字节大小长度,请运行 AWS Samples GitHub 存储库中的 Greenplum 数据结构字符实用程序。
数字精度和小数位数
Amazon Redshift 数字数据类型的最大存储精度限制为 38,而在 Greenplum 数据库中,您可以定义没有任何定义长度的数值列。
使用 AWS Samples GitHub 存储库中的 Greenplum 数据结构数值实用程序,分析您的生产数据集并确定数字溢出候选对象。对于数字数据,您可以根据自己的使用案例选择解决此问题。对于包含小数部分的数字,您可以选择根据数据类型对数据进行四舍五入,而整数部分不会丢失任何数据。为了日后参考,您可以在 VARCHAR 中保留该列的副本或存储在 S3 数据湖中。如果您发现溢出数据异常值的比例极小,请清理源数据以进行高质量数据迁移。
SQL 查询和函数
将 SQL 脚本或存储过程转换为 Amazon Redshift 时,如果您遇到不支持的函数、数据库对象或代码块,并可能需要针对其重写查询,请创建用户定义的函数 (UDFs) 或者重新设计。您可以使用 SQL SELECT 子句或 Python 程序创建自定义标量 UDF。新函数存储在数据库中,可供任何具有足够运行权限的用户使用。运行自定义标量 UDF 的方式与运行现有 Amazon Redshift 函数的方式大致相同,以匹配旧版数据库的任何功能。以下是一些替代查询语句的示例,以及实现代码重写期间可能需要的特定聚合的方法。
AGE
Greenplum 函数 AGE () 返回从当前日期减去的间隔。您可以根据您的使用案例,使用 MONTHS_BETWEEN()、ADD_MONTH()、DATEDIFF() 和 TRUNC() 函数子集来完成相同操作。
以下示例 Amazon Redshift 查询按年、月和日计算日期 2001-04-10 和 1957-06-13 之间的间隔。您可以将其应用于表中的任何日期列。

COUNT
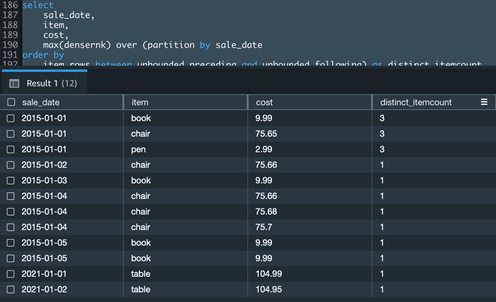
如果您的使用案例在 Count() 窗口函数中获得不同的聚合,则您可以使用 Dense_Rank () 和 Max() 窗口函数的组合来实现相同的功能。
以下示例 Amazon Redshift 查询计算给定销售日期的不同商品数量:
ORDER BY
带有 ORDER BY 子句的 Amazon Redshift 聚合窗口函数需要强制框架。
以下示例 Amazon Redshift 查询按销售日期创建成本的累计总和,并按分区内的商品对结果进行排序:

STRING_AGG
在 Greenplum 中,STRING_AGG() 是一个聚合函数,用于连接字符串列表。在 Amazon Redshift 中,使用 LISTAGG() 函数。
以下示例 Amazon Redshift 查询返回每个部门的电子邮件地址列表(以分号分隔):

ARRAY_AGG
在 Greenplum 中,ARRAY_AGG() 是一个聚合函数,它接受一组值作为输入并返回一个数组。在 Amazon Redshift 中,使用 LISTAGG() 和 SPLIT_TO_ARRAY() 函数的组合。SPLIT_TO_ARRAY() 函数返回 SUPER 数据类型。
以下示例 Amazon Redshift 查询返回每个部门的电子邮件地址数组:

要从 SUPER 表达式中检索数组元素,可以使用 SUBARRAY() 函数:

UNNEST
在 Greenplum 中,您可以使用 UNNEST 函数拆分数组并将数组元素转换为一组行。在 Amazon Redshift 中,您可以使用 PartiQL 语法对 SUPER 数组进行迭代。有关更多信息,请参阅查询半结构化数据。

WHERE
在 Amazon Redshift 中,您无法在查询的 WHERE 子句中使用窗口函数。但可以使用 WITH 子句构建查询,然后引用 WHERE 子句中的计算列。
以下示例 Amazon Redshift 查询返回总销售时间超过 100 的销售日期的表中的销售日期、商品和成本:

请参阅下表,了解其他 Greenplum 日期/时间函数以及 Amazon Redshift 等效函数,以加快代码迁移。
| . | 描述 | Greenplum | Amazon Redshift |
| 1 | now() 函数返回当前事务的开始时间 | now () | sysdate |
| 2 | clock_timestamp() 返回事务块中当前语句的开始时间戳 | clock_timestamp () | to_date(getdate(),’yyyy-mm-dd’) + substring(timeofday(),12,15)::timetz |
| 3 | transaction_timestamp () 返回当前事务的开始时间戳 | transaction_timestamp () | to_date(getdate(),’yyyy-mm-dd’) + substring(timeofday(),12,15)::timetz |
| 4 | Interval – 该函数将 x 年和 y 个月添加到 date_time_column 并返回时间戳类型 | date_time_column + interval ‘ x years y months’ | add_months(date_time_column, x*12 + y) |
| 5 | 获取两个时间戳字段之间的总秒数 | date_part(‘day’, end_ts – start_ts) * 24 * 60 * 60+ date_part(‘hours’, end_ts – start_ts) * 60 * 60+ date_part(‘minutes’, end_ts – start_ts) * 60+ date_part(‘seconds’, end_ts – start_ts) | datediff(‘seconds’, start_ts, end_ts) |
| 6 | 获取两个时间戳字段之间的总分钟数 | date_part(‘day’, end_ts – start_ts) * 24 * 60 + date_part(‘hours’, end_ts – start_ts) * 60 + date_part(‘minutes’, end_ts – start_ts) | datediff(‘minutes’, start_ts, end_ts) |
| 7 | 从两个时间戳字段的差异中提取日期部分文字 | date_part(‘hour’, end_ts – start_ts) | extract(hour from (date_time_column_2 – date_time_column_1)) |
| 8 | 用于返回一周中 ISO 这一天的函数 | date_part(‘isodow’, date_time_column) | TO_CHAR(date_time_column, ‘ID’) |
| 9 | 用于返回日期时间字段中 ISO 年份的函数 | extract (isoyear from date_time_column) | TO_CHAR(date_time_column, ‘IYYY’) |
| 10 | 将纪元秒转换为等效日期时间 | to_timestamp(epoch seconds) | TIMESTAMP ‘epoch’ + Number_of_seconds * interval ‘1 second’ |
用于集群故障排除或运行诊断的 Amazon Redshift 实用程序
Amazon Redshift Utilities GitHub 存储库包含一组实用程序,用于加快 Amazon Redshift 的故障排除或分析。此类实用程序由查询、视图和脚本组成。默认情况下,它们不会部署到 Amazon Redshift 集群上。最佳实践是将所需的视图部署到管理架构中。
结论
在本文中,我们介绍了有关数据类型、函数和存储过程的规范性指导,以加快从 Greenplum 到 Amazon Redshift 的迁移过程。尽管本文描述了云仓库现代化及向其迁移,但您应该将这个转型过程扩展到成熟的现代数据架构。AWS 云支持多个使用案例,使您能够更加以数据为导向。对于现代数据架构,您应该使用有针对性的数据存储,例如 Amazon S3、Amazon Redshift、Amazon Timestream,以及其他基于您使用案例的数据存储。
关于作者
 Suresh Patnam 是 AWS 的首席解决方案架构师。他热衷于帮助各种规模的企业转型为快速发展的数字组织,专注于大数据、数据湖和 AI/ML。Suresh 拥有杜克大学福库商学院工商管理硕士学位和密苏里州立大学 CIS 硕士学位。闲暇时,Suresh 喜欢打网球,陪伴家人。
Suresh Patnam 是 AWS 的首席解决方案架构师。他热衷于帮助各种规模的企业转型为快速发展的数字组织,专注于大数据、数据湖和 AI/ML。Suresh 拥有杜克大学福库商学院工商管理硕士学位和密苏里州立大学 CIS 硕士学位。闲暇时,Suresh 喜欢打网球,陪伴家人。
 Arunabha Datta 是AWS Professional Services 的高级数据架构师。他与客户和合作伙伴合作,使用 AWS Analytics 服务架构和实施现代数据架构。闲暇时间,Arunabha 喜欢摄影,陪伴家人。
Arunabha Datta 是AWS Professional Services 的高级数据架构师。他与客户和合作伙伴合作,使用 AWS Analytics 服务架构和实施现代数据架构。闲暇时间,Arunabha 喜欢摄影,陪伴家人。