AWS Big Data Blog
Bringing your stored procedures to Amazon Redshift
Amazon always works backwards from the customer’s needs. Customers have made strong requests that they want stored procedures in Amazon Redshift, to make it easier to migrate their existing workloads from legacy, on-premises data warehouses.
With that primary goal in mind, AWS chose to implement PL/pqSQL stored procedure to maximize compatibility with existing procedures and simplify migrations. In this post, we discuss how and where to use stored procedures to improve operational efficiency and security. We also explain how to use stored procedures with AWS Schema Conversion Tool.
What is a stored procedure?
A stored procedure is a user-created object to perform a set of SQL queries and logical operations. The procedure is stored in the database and is available to users who have sufficient privileges to run it.
Unlike a user-defined function (UDF), a stored procedure can incorporate data definition language (DDL) and data manipulation language (DML) in addition to SELECT queries. A stored procedure doesn’t have to return a value. You can use the PL/pgSQL procedural language, including looping and conditional expressions, to control logical flow.
Stored procedures are commonly used to encapsulate logic for data transformation, data validation, and business-specific operations. By combining multiple SQL steps into a stored procedure, you can reduce round trips between your applications and the database.
You can also use stored procedures for delegated access control. For example, you can create stored procedures to perform functions without giving a user access to the underlying tables.
Why would you use stored procedures?
Many customers migrating to Amazon Redshift have complex data warehouse processing pipelines built with stored procedures on their legacy data warehouse platform. Complex transformations and important aggregations are defined with stored procedures and reused in many parts of their processing. Re-creating the logic of these processes using an external programming language or a new ETL platform could be a large project. Using Amazon Redshift stored procedures allows you to migrate to Amazon Redshift more quickly.
Other customers would like to tighten security and limit the permissions of their database users. Stored procedures offer new options to allow DBAs to perform necessary actions without having to give permissions too widely. With the security definer concepts in stored procedures, it is now possible to allow users to perform actions they otherwise would not have permissions to run.
Additionally, using stored procedures in this way helps reduce the operations burden. An experienced DBA is able to define a well-tested process for some administrative or maintenance action. They can then allow other, less experienced operators to execute the process without entrusting them with full superuser permissions on the cluster.
Finally, some customers prefer using stored procedures to manage their ETL/ELT operations as an alternative to shell scripting or complex orchestration tools. It can be difficult to ensure that shell scripts correctly retrieve and interpret the state of each operation in an ETL/ELT process. It can also be challenging to take on the operation and maintenance of an orchestration tool with a small data warehouse team.
Stored procedures allow the ETL/ELT logical steps to be fully enclosed in a master procedure that is written so that it either succeeds completely or fails cleanly with no side effects. The stored procedure can be called with confidence from a simple scheduler like cron.
Create a stored procedure
To create a stored procedure in Amazon Redshift, use the following the syntax:
When you design stored procedures, think about the encapsulated functionality, input and output parameters, and security level. As an example, here’s how you can write a stored procedure to check primary key violations, given names of the schema, table, and primary key column, using dynamic SQL:
For details about the kinds of SQL queries and control flow logic that can be used inside a stored procedure, see Creating Stored Procedures in Amazon Redshift.
Invoke a stored procedure
Stored procedures must be invoked by the CALL command, which takes the procedure name and the input argument values. CALL can’t be part of any regular queries. As an example, here’s how to invoke the stored procedure created earlier:
Amazon Redshift stored procedure calls can return results through output parameters or a result set. Nested and recursive calls are also supported. For details, see CALL command.
How to use security definer procedures
Now that you know how to create and invoke a stored procedure, here’s more about the security aspects. When you create a procedure, only you as the owner (creator) have the privilege to call or execute it. You can grant EXECUTE privilege to other users or groups, which enables them to execute the procedure. EXECUTE privileges do not automatically imply that the caller can access all database objects (tables, views, and so on) that are referenced in the stored procedure.
Take the example of a procedure, sp_insert_customers, created by user Mary. It has an INSERT statement that writes to table customers that is owned by Mary. If Mary grants EXECUTE privileges to user John, John still can’t INSERT into the table customers unless he has explicitly been granted INSERT privileges on customers.
However, it might make sense to allow John to call the stored procedure without giving him INSERT privileges on customers. To do this, Mary has to set the SECURITY attribute of the procedure to DEFINER when creating the procedure and then grant EXECUTE privileges to John. With this set, when John calls sp_insert_customers, it executes with the privileges of Mary and can insert into customers without him having been granted INSERT privileges on that table.
When the security attribute is not specified during procedure creation, its value is set to INVOKER by default. This means that the procedure executes with the privileges of the user that calls it. When the security attribute is explicitly set to DEFINER, the procedure executes with the privileges of the procedure owner.
Best practices with stored procedures in Amazon Redshift
Here are some best practices for using stored procedures.
Ensure that stored procedures are captured in your source control tool.
If you plan to use stored procedures as a key element of your data processing, you should also establish a practice of committing all stored procedure changes to a source control system.
You could also consider defining a specific user who is the owner of important stored procedures and automating the process of creating and modifying procedures.
You can retrieve the source for existing stored procedures using the following command:
SHOW procedure_name;
Consider the security scope of each procedure and who calls it
By default, stored procedures run with the permission of the user that calls them. Use the SECURITY DEFINER attribute to enable stored procedures to run with different permissions. For instance, explicitly revoke access to DELETE from an important table and define a stored procedure that executes the delete after checking a safe list.
When using SECURITY DEFINER, take care to:
- Grant
EXECUTEon the procedure to specific users, not toPUBLIC. This ensures that the procedure can’t be misused by general users. - Qualify all database objects that the procedure accesses with the schema names if possible. For example, use
myschema.mytableinstead of justmytable. - Set the
search_pathwhen creating the procedure by using the SET option. This prevents objects in other schemas with the same name from being affected by an important stored procedure.
Use set-based logic and avoid manually looping over large datasets
When manipulating data within your stored procedures, continue to use normal, set-based SQL as much as possible, for example, INSERT, UPDATE, DELETE.
Stored procedures provide new control structures such as FOR and WHILE loops. These are useful for iterating over a small number of items, such as a list of tables. However, you should avoid using the loop structures to replace a set-based SQL operation. For example, iterating over millions of values to update them one-by-one is inefficient and slow.
Be aware of REFCURSOR limits and use temp tables for larger result sets
Result sets may be returned from a stored procedure either as a REFCURSOR or using temp tables. REFCURSOR is an in-memory data structure and is the simplest option in many cases.
However, there is a limit of one REFCURSOR per stored procedure. You may want to return multiple result sets, interact with results from multiple sub-procedures, or return millions of result rows (or more). In those cases, we recommend directing results to a temp table and returning a reference to the temp table as the output of your stored procedure.
Keep procedures simple and nest procedures for complex processes
Try to keep the logic of each stored procedure as simple possible. You maximize your flexibility and make your stored procedures more understandable by keeping them simple.
The code of your stored procedures can become complex as you refine and enhance them. When you encounter a long and complex stored procedure, you can often simplify by moving sub-elements into a separate procedure that is called from the original procedure.
Migrating a stored procedure with the AWS Schema Conversion Tool
With Amazon Redshift announcing the support for stored procedures, AWS also enhanced AWS Schema Conversion Tool to convert stored procedures from legacy data warehouses to Amazon Redshift.
AWS SCT already supports the conversion of Microsoft SQL Server data warehouse stored procedures to Amazon Redshift.
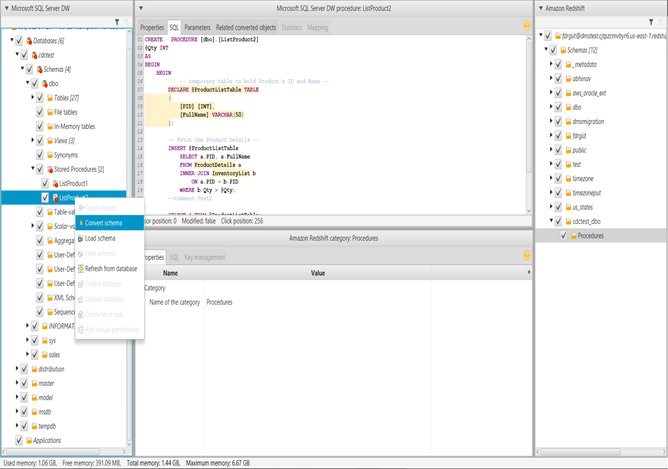
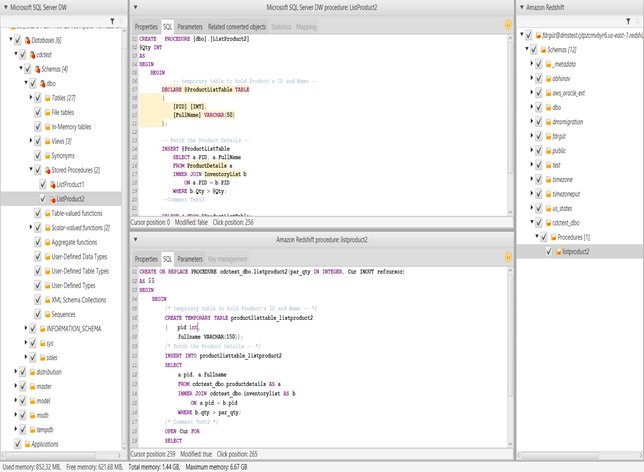
With build 627, AWS SCT can now convert Microsoft SQL Server data warehouse stored procedures to Amazon Redshift. Here are the steps in AWS SCT:
- Create a new OLAP project for a SQL Server data warehouse (DW) to Amazon Redshift conversion.
- Connect to the SQL Server DW and Amazon Redshift endpoints.
- Uncheck all nodes in the source tree.
- Open the context (right-click) menu for Schemas.
- Open the context (right-click) menu for the Stored Procedures node and choose Convert Script (just like when you convert database objects).
- (Optional) You can also choose to review the assessment report and apply the conversion.
Here is an example of a SQL Server DW stored procedure conversion:
Conclusion
Stored procedure support in Amazon Redshift is now generally available in every AWS Region. We hope you are as excited about running stored procedures in Amazon Redshift as we are.
With stored procedure support in Amazon Redshift and AWS Schema Conversion Tool, you can now migrate your stored procedures to Amazon Redshift without having to encode them in another language or framework. This feature reduces migration efforts. We hope more on-premises customers can take advantage of Amazon Redshift and migrate to the cloud for database freedom.
About the Authors
 Joe Harris is a senior Redshift database engineer at AWS, focusing on Redshift performance. He has been analyzing data and building data warehouses on a wide variety of platforms for two decades. Before joining AWS he was a Redshift customer from launch day in 2013 and was the top contributor to the Redshift forum.
Joe Harris is a senior Redshift database engineer at AWS, focusing on Redshift performance. He has been analyzing data and building data warehouses on a wide variety of platforms for two decades. Before joining AWS he was a Redshift customer from launch day in 2013 and was the top contributor to the Redshift forum.
 Abhinav Singh is a database engineer at AWS. He works on design and development of database migration projects as well as customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.
Abhinav Singh is a database engineer at AWS. He works on design and development of database migration projects as well as customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.
 Entong Shen is a senior software engineer on the Amazon Redshift query processing team. He has been working on MPP databases for over 7 years and has focused on query optimization, statistics and SQL language features. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
Entong Shen is a senior software engineer on the Amazon Redshift query processing team. He has been working on MPP databases for over 7 years and has focused on query optimization, statistics and SQL language features. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
 Vinay is a principal product manager at Amazon Web Services for Amazon Redshift. Previously, he was a senior director of product at Teradata and a director of product at Hortonworks. At Hortonworks, he launched products in Data Science, Spark, Zeppelin, and Security. Outside of work, Vinay loves to be on a yoga mat or on a hiking trail.
Vinay is a principal product manager at Amazon Web Services for Amazon Redshift. Previously, he was a senior director of product at Teradata and a director of product at Hortonworks. At Hortonworks, he launched products in Data Science, Spark, Zeppelin, and Security. Outside of work, Vinay loves to be on a yoga mat or on a hiking trail.
![]() Sushim Mitra is a software development engineer on the Amazon Redshift query processing team. He focuses on query optimization problems, SQL Language features and Database security. When not at work, he enjoys reading fiction from all over the world.
Sushim Mitra is a software development engineer on the Amazon Redshift query processing team. He focuses on query optimization problems, SQL Language features and Database security. When not at work, he enjoys reading fiction from all over the world.