亚马逊AWS官方博客
使用 Amazon Redshift 和 Amazon Managed Grafana 构建近实时物流仪表板提升运营智能
Amazon Redshift 是一项完全托管式数据仓库服务,目前正在帮助成千上万的客户管理大规模的分析。该服务继续引领性价比基准,并将计算和存储分开,这样每个组件都可以独立扩展,您只为所需资源付费。它还消除了数据孤岛,使用统一的安全和治理策略,简化对操作数据库、数据仓库和数据湖的访问。
借助 Amazon Redshift Streaming Ingestion 功能,访问和分析从实时数据来源传入的数据比以往任何时候都更简单。该功能在 Amazon Redshift 与 AWS 中的流引擎之间提供原生集成,简化了流架构,这些引擎包括 Amazon Kinesis Data Streams 和 Amazon Managed Streaming for Apache Kafka(Amazon MSK)。系统日志、社交媒体源和 IoT 流等流式数据来源可以连续将事件推送到流引擎,而 Amazon Redshift 仅简单地作为另一个使用器。在 Amazon Redshift 流功能上线之前,我们必须先将流数据暂存到 Amazon Simple Storage Service(Amazon S3)中,然后运行复制命令将数据加载到 Amazon Redshift。消除在 Amazon S3 中暂存数据的需求可以提高性能并缩短延迟。有了这个功能,我们可以每秒摄取数百 MB 的数据,延迟短至几秒钟。
我们的客户面临的另一个常见挑战是使用流数据时需要掌握其他技能。在 Amazon Redshift Streaming Ingestion 中,客户只需要熟悉 SQL。我们使用 SQL 来执行以下操作:
- 通过创建外部架构来定义 Amazon Redshift 与我们流引擎之间的集成
- 创建不同的流数据库对象,这些对象实际上是实体化视图
- 查询和分析流数据
- 生成使用机器学习(ML)来预测延迟的新功能
- 使用 Amazon Redshift ML 在本地进行推理
在这篇文章中,我们使用 Amazon Redshift 和 Amazon Managed Grafana 构建近实时物流控制面板。我们的示例针对一家物流公司的运营智能控制面板,用于为运营团队提供态势感知和增强智能。在该控制面板上,团队可以根据短短几秒钟前发生的事件,查看货物和物流车队的当前状态。它还显示了 Amazon Redshift ML 模型的发货延迟预测,该模型可帮助他们主动应对中断,甚至是在中断发生之前。

解决方案概览
此解决方案包括以下组件,使用 AWS Cloud Development Kit(AWS CDK)实现自动化的资源预置:
- 使用 Python 代码模拟多个流数据来源,这些代码在我们的无服务器计算服务 AWS Lambda 中运行
- 流事件由 Amazon Kinesis Data Streams 捕获,这是一种高度可扩展的无服务器流数据服务
- 我们使用 Amazon Redshift Streaming Ingestion 功能来处理和存储流数据,使用 Amazon Redshift ML 来预测发货延迟的可能性
- 我们使用 AWS Step Functions 进行无服务器工作流编排
- 该解决方案包括一个在 Amazon Managed Grafana 上构建的使用层,我们可以在其中将洞察可视化,甚至通过 Amazon Simple Notification Service(Amazon SNS)为运营团队生成警报
下图展示了我们解决方案的架构。
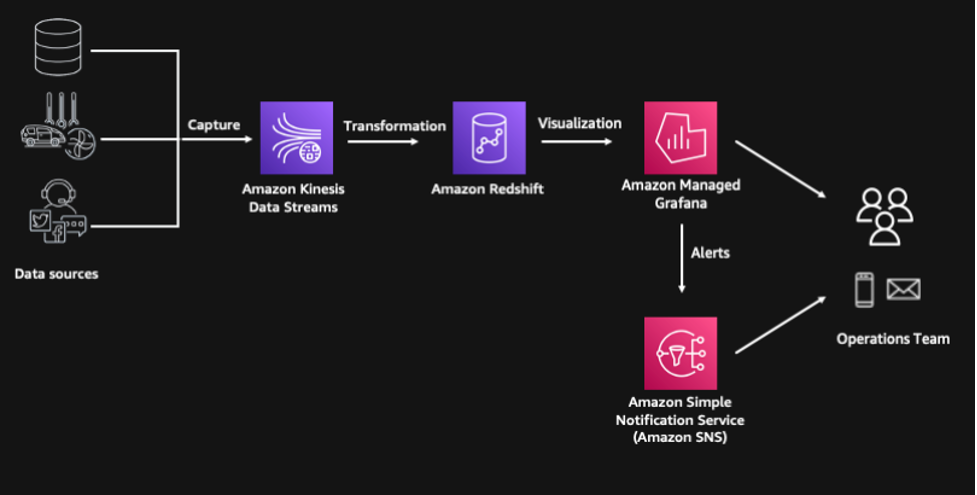
先决条件
该项目需要满足以下先决条件:
- 一个 AWS 账户。
- Amazon Linux 2,且安装了 AWS CDK、Docker CLI 和 Python3。或者,设置 AWS Cloud9 环境也可满足此要求。
- 要运行此代码,您需要对所用 AWS 账户提升权限。
使用 AWS CDK 的示例部署
AWS CDK 是一个开源项目,让您可以使用熟悉的编程语言定义云基础设施。它使用高级结构来表示 AWS 组件,从而简化构建流程。在这篇文章中,我们使用 Python 来定义云基础设施,因为许多数据和分析专业人员都熟悉它。
克隆 GitHub 存储库并安装 Python 依赖项:
接下来,引导 AWS CDK。这会设置 AWS CDK 部署到 AWS 账户时所需的资源。仅当您尚未在部署账户和区域中使用 AWS CDK 时,才需要执行此步骤。
部署所有堆栈:
整个部署时间需要 10 到 15 分钟。
使用 Amazon Redshift Streaming Ingestion 访问流数据
AWS CDK 部署使用相应的默认 IAM 角色预置 Amazon Redshift 集群,用于访问 Kinesis 数据流。我们可以创建一个外部架构,用于在 Amazon Redshift 集群与 Kinesis 数据流之间建立连接:
有关如何连接到集群的说明,请参阅连接到 Redshift 集群。
我们使用实体化视图来解析 Kinesis 数据流中的数据。在这种情况下,整个负载按原样采集,并使用 Amazon Redshift 中的 SUPER 数据类型存储。存储在流引擎中的数据通常采用半结构化格式,而 SUPER 数据类型为分析 Amazon Redshift 中的半结构化数据提供了一种快速高效的方法。

请参阅以下代码:
刷新实体化视图会调用 Amazon Redshift,以直接从 Kinesis 数据流读取数据并加载到实体化视图中。此刷新操作可以通过在实体化视图定义中添加 AUTO REFRESH 子句来自动完成。但是,在此示例中,我们使用 AWS Step Functions 来编排端到端数据管道。
现在,我们可以开始对流数据进行查询,并将该流数据与物流车队数据等其他数据集整合在一起。如果想知道货物在不同州的分布情况,我们可以使用 PartiQL 语法,轻松解包 JSON 负载的内容。
使用 Amazon Redshift SQL 函数生成特征
下一步是使用 Amazon Redshift SQL 转换和扩充流数据,用于生成供 Amazon Redshift ML 进行预测的其他特征。我们使用日期和时间函数来标识周中日期,以及计算订购日期与目标配送日期之间的天数。
我们还使用地理空间函数,具体而言是 ST_DistanceSphere 来计算起点位置与目的地位置之间的距离。Amazon Redshift 中的 GEOMETRY 数据类型提供了一种经济实惠的方法,用于大规模分析经度和纬度等地理空间数据。在此示例中,地址已经转换为经度和纬度。不过,如果您需要执行地理编码,则可以使用用户定义函数(UDF,User-Defined Function)将 Amazon Location Service 与 Amazon Redshift 集成。除了地理编码之外,利用 Amazon Location Service 还可以更准确地计算起点和目的地之间的路线距离,甚至可以指定沿途的路径点。
我们使用另一个实体化视图来保存这些转换。实体化视图提供了一种简单而高效的方法,使用其增量刷新功能来创建数据管道。Amazon Redshift 会识别自上次刷新以来的增量更改,并仅基于这些更改来更新目标实体化视图。在此实体化视图中,我们所有的转换都是确定性的,因此我们希望在进行全面刷新或增量刷新时数据能够保持一致。

请参阅以下代码:
使用 Amazon Redshift ML 预测延迟
我们可以利用这些扩充后的数据来预测货物的延迟概率。Amazon Redshift ML 是 Amazon Redshift 的一项功能,供您利用 Amazon Redshift 的强大功能直接在数据仓库中构建、训练和部署机器学习模型。
新 Amazon Redshift 机器学习模型的训练,已经在 AWS CDK 部署中使用 CREATE MODEL 语句启动。训练数据集在 FROM 子句中定义,TARGET 定义模型要预测的列。FUNCTION 子句定义进行预测所用函数的名称。
这个简化的模型使用历史观测结果进行训练,完成训练过程大约需要 30 分钟时间。您可以通过运行 SHOW MODEL 语句来检查训练作业的状态。
模型准备就绪后,我们可以开始对流式传入 Amazon Redshift 的新数据进行预测。使用训练过程中定义的 Amazon Redshift ML 函数生成预测。我们将计算得到的特征从转换后的实体化视图传递到此函数,然后将预测结果填充 delay_probability 列。
最终输出将保存在 consignment_predictions 表中,Step Functions 协调将持续的增量数据加载到此目标表中。我们为最终输出使用表格而不是实体化视图,因为机器学习预测涉及随机性,它可能会提供不确定的结果。使用表可以让我们更好地控制如何加载数据。

请参阅以下代码:
创建 Amazon Managed Grafana 控制面板
我们使用 Amazon Managed Grafana 创建一个近实时物流控制面板。Amazon Managed Grafana 是一项完全托管式服务,可轻松创建、配置和共享交互式控制面板和图表,用于监控数据。我们还可以使用 Grafana,根据特定条件或阈值设置警报和通知,使您能够快速识别和响应问题。
设置控制面板的概要步骤如下:
- 创建 Grafana 工作区。
- 使用 AWS IAM Identity Center(AWS Single Sign-On 的后继产品)或者使用直接 SAML 集成,设置 Grafana 身份验证。
- 将 Amazon Redshift 配置为 Grafana 数据来源。
- 为近实时物流控制面板导入 JSON 文件。
GitHub 存储库中提供了更详细的说明,供您参考。
清理
为避免持续产生费用,请删除已部署的资源。访问 Amazon Linux 2 环境并运行 AWS CDK destroy 命令。删除与此部署相关的 Grafana 对象。
小结
在这篇文章中,我们使用 Amazon Redshift 和 Amazon Managed Grafana 构建近实时物流控制面板,展示了这一过程有多简单。我们仅使用 SQL 便创建了端到端的现代化数据管道。这展示了 Amazon Redshift 如何成为实现数据大众化的强大平台,通过该平台,包括业务分析师、数据科学家和其他人在内的广泛用户无需专业技术技能或专业知识即可处理和分析数据。
我们欢迎您探索使用 Amazon Redshift 和 Amazon Managed Grafana 还能实现的功能。同时,我们建议您查看 AWS 大数据博客,了解有关 Amazon Redshift 的其他有用的博客文章。
关于作者
 Paul Villena 是 AWS 的分析解决方案架构师,专长于构建现代化数据和分析解决方案来推动实现商业价值。他与客户合作,帮助他们利用云的强大功能。他感兴趣的领域包括基础设施即代码、无服务器技术和 Python 编码。
Paul Villena 是 AWS 的分析解决方案架构师,专长于构建现代化数据和分析解决方案来推动实现商业价值。他与客户合作,帮助他们利用云的强大功能。他感兴趣的领域包括基础设施即代码、无服务器技术和 Python 编码。