亚马逊AWS官方博客
在 AWS 上以高可用性模式实现 Microsoft SQL 数据库服务现代化的注意事项
许多企业都有需要 Microsoft SQL Server 来运行关系数据库工作负载的应用程序:一些应用程序可能是专有软件,供应商可使用它强制 Microsoft SQL Server 运行数据库服务;其他应用程序可能是长期存在的、自主开发的应用程序,它们在最初开发时便已包含 Microsoft SQL Server。当企业将应用程序迁移到 AWS 时,他们通常会先直接迁移,然后在 Amazon Elastic Compute Cloud(Amazon EC2)上运行 Microsoft SQL 数据库服务。之所以会这样,可能是因为他们最熟悉这种方式。
在 Amazon EC2 上以高可用性模式运行 Microsoft SQL 数据库服务
此选项对现有运维模式的影响最小。它使您能够利用 AWS Cloud 管理物理设施等服务,快速开始实现 Microsoft SQL 数据库服务的现代化。底层基础设施操作任务(例如,服务器机架、堆栈和维护)由 AWS 管理。您具有对数据库和操作系统级别访问的完全控制权,因此,可以选择多种工具来管理操作系统、数据库软件、修补程序、数据复制、备份和恢复。
您可以将任何 Microsoft SQL Server 支持的复制方法与 Amazon EC2 上的 Microsoft SQL Server 数据库结合使用,实现高可用性、数据保护和灾难恢复。常见的解决方案包括日志传送、数据库镜像、Always On 可用性组和 Always On 失效转移集群实例。
在单个区域内实现高可用性
图 1 说明了如何在跨单个区域内的多个可用区(AZ,Availability Zone)的 Amazon EC2 上使用 Microsoft SQL Server。AZ 之间的互连与数据中心互通类似,并由 AWS 管理。主数据库是读写数据库,而辅助数据库配置了日志传送、数据库镜像或 Always On 可用性组以实现高可用性。来自主数据库的所有事务性数据都将传输,并且会异步应用于辅助数据库以进行日志传送;对于 Always On 可用性组和镜像,可以异步或同步应用该数据。

图 1.通过 Amazon EC2 上的 Microsoft SQL 数据库服务在单个区域内实现高可用性
跨多个区域实现高可用性
图 2 说明了如何在跨多个区域的 Amazon EC2 上为 Microsoft SQL Server 配置高可用性。来自主数据库的其他区域中的辅助 Microsoft SQL Server 配置了日志传送、数据库镜像或 Always On 可用性组以实现高可用性。来自主数据库的事务性数据通过完全托管的 AWS 主干网络跨区域传输。

图 2.通过 Amazon EC2 上的 Microsoft SQL 数据库服务跨多个区域实现高可用性
在 Amazon RDS 上以高可用性模式更换 Microsoft SQL 数据库服务的平台
Amazon RDS 是一项托管式数据库服务,负责大多数管理任务。它目前支持使用 SQL Server 数据库镜像(DBM,Database Mirroring)或 Always On 可用性组(AG,Availability Group)作为高度可用的失效转移解决方案,对 SQL Server 进行多可用区部署。
在单个区域内实现高可用性
图 3 演示了在 Amazon RDS 上运行的 Microsoft SQL 数据库服务在单个区域中配置了多可用区部署模型。多可用区部署为数据库实例提供了更高的可用性、数据持久性和容错能力。如果发生计划内数据库维护或计划外服务中断,Amazon RDS 会自动失效转移到最新的辅助数据库实例。此功能可让数据库操作快速恢复,而无需人工干预。主实例和备用实例使用相同的端点,作为失效转移过程的一部分,其物理网络地址将转换为辅助副本。发生失效转移时,您无需重新配置应用程序。Amazon RDS 通过使用 SQL Server 数据库镜像或 Always On 可用性组来支持 Microsoft SQL Server 的多可用区部署。

图 3.通过 Amazon RDS 上的 Microsoft SQL 数据库服务在单个区域内实现高可用性
跨多个区域实现高可用性
图 4 描述了如何使用 AWS Database Migration Service(AWS DMS)在 Amazon RDS 上跨多个区域配置 Microsoft SQL 数据库服务之间的跨连续复制。AWS DMS 需要在 Amazon RDS 上为 Microsoft SQL Server 实例启用 Microsoft Change Data Capture。如果出现问题,您可以通过在其他区域内提升 Amazon RDS 只读副本,来启动手动失效转移并恢复数据库服务。

图 4.通过 Amazon RDS 上的 Microsoft SQL 数据库服务跨多个区域实现高可用性
在 Amazon Aurora 上以高可用性模式重构 Microsoft SQL 数据库服务
此选项可帮助您消除 SQL 数据库服务许可证成本。您可以在真正的云原生现代数据库架构上运行数据库服务。您可以使用 AWS Schema Conversion Tool 来协助评估并转换数据库代码和存储对象。将明确标记任何无法自动转换的对象,以便手动转换这些对象来完成迁移。
Aurora 架构涉及存储和计算的分离。Aurora 包含一些适用于数据库集群中的数据的高度可用的功能。即使集群中的部分或全部数据库实例变得不可用,数据也是安全的。其他高度可用的功能适用于数据库实例。这些功能有助于确保一个或多个数据库实例准备好处理来自应用程序的数据库请求。
在单个区域内实现高可用性
图 5 说明了 Aurora 将数据副本存储在跨单个区域内的多个可用区的数据库集群中。当数据写入主数据库实例时,Aurora 会跨可用区将数据同步复制到与集群卷关联的六个存储节点。这样做可以实现数据冗余,消除 I/O 冻结,并最大限度地减小系统备份期间的延迟峰值。以高可用性模式运行数据库实例,可以在计划内系统维护(例如数据库引擎更新)期间提高可用性,并有助于保护数据库,使其免受故障和可用区中断的影响。

图 5.通过 Amazon Aurora 在单个区域内实现高可用性
跨多个区域实现高可用性
图 6 描述了如何设置 Aurora 全局数据库以实现跨多个区域的高可用性。Aurora 全局数据库由一个将数据写入到的主区域和最多五个只读辅助区域构成。您可以直接向主区域中的主数据库集群发出写入操作。Aurora 自动使用专用基础设施将数据复制到辅助区域,这通常会有不到一秒的延迟。
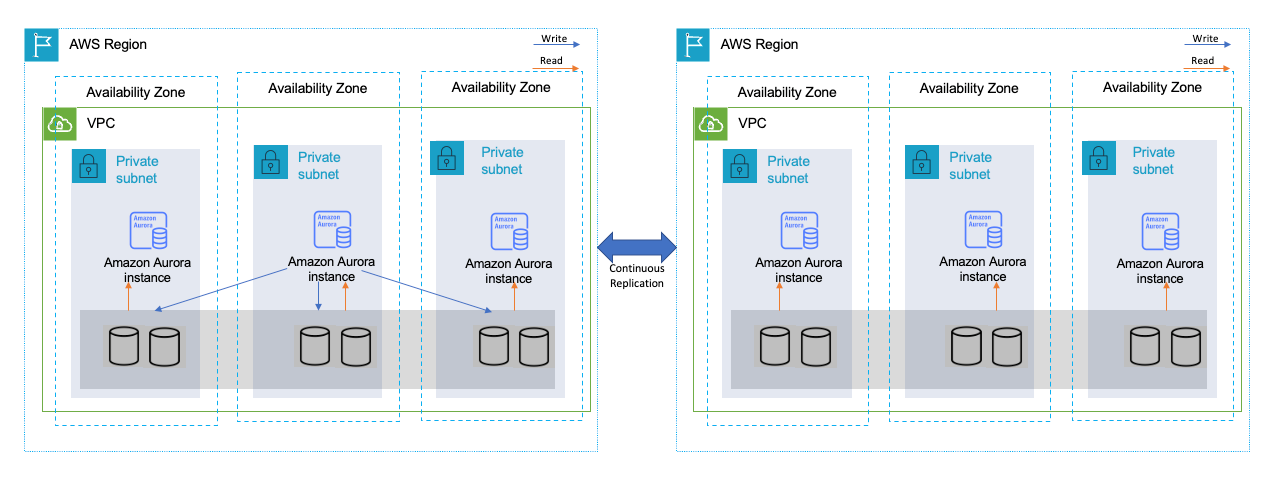
图 6.通过 Amazon Aurora 全球数据库跨多个区域实现高可用性
总结
在 AWS 上实现 SQL 数据库服务的现代化时,您可以选择 Amazon EC2、Amazon RDS 或 Amazon Aurora 选项。了解业务所需的特性和服务管理责任的范围是一个好的开始。当提供了多个满足业务需求的选项时,请选择一个能够让您更多地关注您的应用程序和业务增值功能,并帮助您降低服务的“总拥有成本”的选项。