亚马逊AWS官方博客
基于 Amazon ECS Fargate 和 Graviton 构建企业级多租户 AI Agent 平台:OpenClaw + Hermes 双 Agent 实践
摘要:随着 AI Agent 从实验走向生产,企业面临一个现实问题:如何让不同团队各自拥有独立的 Agent 实例,同时保障数据隔离、控制成本、降低运维门槛?本文介绍一种基于 Amazon ECS Fargate + ARM64 (AWS Graviton) 的轻量级多租户方案,同时部署 OpenClaw(多功能 Web Agent)和 Hermes(自进化 AI 助手)两个开源 Agent,通过四层隔离机制实现企业级安全,适合小型团队快速落地。同时覆盖从 Agent 应用部署到 Agent 驱动数据分析的完整工作流——利用 Hermes Agent 管理 Spark on Amazon EKS 集群、分析 NYC 出租车公开数据集。
一、引言
一个典型的企业 AI Agent 部署场景:IT 部门搭建了一套 Agent 平台,HR、法务、工程、运营各团队都想接入。每个团队需要独立的 Agent 实例——独立的对话历史、独立的文件空间、独立的模型权限、互不可见的数据。
这带来一个核心矛盾:隔离性要求每个租户独占资源,但运维效率要求统一管理。
传统做法是用 Kubernetes 搭建多租户平台(Namespace 隔离 + Operator 管理生命周期),但这对团队的 K8s 能力有较高要求。对于租户规模在几到几十人、没有专职平台工程团队的企业,需要一种更轻量的方案——既能保障租户隔离,又不引入 K8s 的运维复杂度。
本文介绍如何基于 Amazon ECS Fargate + Graviton 构建这样一套平台:每个租户拥有独立的 ECS Service 和 Amazon EFS 存储空间,通过 ALB 路径路由精准分发请求,同时部署 OpenClaw 和 Hermes 两个互补的开源 Agent。整个平台通过 Terraform 一键部署,从零到可用通常在 30 分钟以内。
二、方案选型
2.1 方案定位
本方案面向企业内部 AI 助手场景,核心设计目标:
- 租户规模:几到几十人(Slot 数量可调)
- 团队规模:2-5 人可快速上手
- 核心诉求:快速部署、低运维、成本可控
- 首选方案:Amazon ECS Fargate + ARM Graviton
2.2 双 Agent 选型
本方案同时集成两个互补的开源 AI Agent,每个用户的 Slot 同时包含两个 Agent 实例。
2.2.1 Hermes — 自我进化的 AI Agent
Hermes Agent 是由 Nous Research 开发的开源 AI Agent(MIT 协议),是目前增长最快的开源 Agent 框架之一。与大多数 Agent 框架不同,Hermes 的核心差异化在于自我进化能力——它不是每次从零开始,而是从经验中持续学习。
Hermes 的记忆系统分为三层:
- Layer 1 — 冻结系统提示记忆:MEMORY.md(2,200 字符)和 USER.md(1,375 字符)在每次会话开始时冻结注入 system prompt。Agent 通过 add/replace/remove 操作主动维护记忆,容量刻意有限以逼迫高质量策展。
- Layer 2 — 程序性技能记忆:Agent 完成复杂任务后自动提炼为可复用的 Skill 文件(遵循 agentskills.io 开放标准),后续遇到类似任务时语义匹配召回。这是 Do → Learn → Improve 闭环的核心。
- Layer 3 — 会话搜索:SQLite FTS5 全文索引所有历史会话,查询时 FTS5 匹配 + LLM 摘要化注入当前上下文。选择 FTS5 而非向量数据库是务实的工程选择——零运维、精确匹配出色、本地部署友好。
此外,Hermes 还支持 8 种可选的外部记忆提供者(如 Honcho 辩证用户建模),以及 40+ 内置工具、子 Agent 委派、cron 定时任务、多平台 IM 接入(微信、飞书、企微、钉钉、QQ、WhatsApp、Discord、Slack)等能力。
在本方案中,Hermes 容器还预装了 kubectl 和 aws cli,使其能够直接操作 Amazon EKS 集群和 AWS 资源——这是后续”Agent 驱动数据分析”场景的基础。
2.2.2 OpenClaw — 多功能 Web Agent 平台
OpenClaw 是一个功能丰富的开源 AI Agent 平台,核心优势在于开箱即用和渠道覆盖广。它提供 Web Control UI(浏览器打开即对话)、50+ 通信渠道接入(通过对话指令自动配置)、内置代码执行沙箱、MCP 工具调用,以及 Gateway 鉴权和 Workspace 隔离等多租户友好特性。
2.2.3 对比与选型建议
| 维度 | Hermes | OpenClaw |
| 核心定位 | 越用越聪明,持久记忆+自学习 | 开箱即用,Web 交互+多渠道覆盖 |
| 持久记忆 | 三层记忆跨 Session 持久化 | Session 级,重启后丢失 |
| 自学习 | Skills 自动沉淀+自我改进 | 无 |
| IM 渠道 | 微信/飞书/企微/钉钉/QQ 等 | 50+ 渠道,覆盖更广 |
| Token 效率 | 上下文更紧凑,消耗低约 30% | 标准消耗 |
选型建议:需要跨会话持久记忆和自学习 → Hermes;需要快速对话和多渠道覆盖 → OpenClaw;两者都需要 → 本方案支持并行部署。
确定了 Agent 选型后,接下来选择承载平台。
2.3 平台选型:ECS Fargate + Graviton
2.3.1 EKS vs ECS Fargate 选型
| 维度 | Amazon EKS | Amazon ECS Fargate |
| 方案定位 | Agent as Product(大规模对外部署) | Agent as Worker(企业内部部署) |
| 架构复杂性 | 高(Kata + MicroVM + Agent Sandbox) | 低(Fargate 托管,开箱即用) |
| 运维复杂性 | 高(Self-built Stack,需 K8s 专家) | 低(Managed Stack,无节点管理) |
| 学习曲线 | 陡峭(K8s 生态) | 平缓(AWS 原生) |
| 适合团队规模 | 平台工程团队 | 2-5 人应用团队 |
| 多租户隔离 | Namespace + NetPolicy + Kata Sandbox | Service 级隔离(独立 Task + Security Group + EFS Access Point) |
| ARM / Graviton | 支持 | 支持(比 x86 便宜约 20%) |
2.3.2 ECS Fargate + Graviton 的关键优势
| 维度 | Graviton (ARM64) | x86 同配置实例 |
| 性价比 | 提升 20%-40% | 基准 |
| 单核性能 | 优秀(最新系列9g基于Arm Neoverse V3) | 良好 |
| 能效比 | 高(功耗更低) | 标准 |
| 生态兼容 | 主流软件均已支持 | 完全兼容 |
选择 ECS Fargate + Graviton 的关键理由:
- Fargate 提供完全托管的 Serverless 计算,每个 Task 运行在独立的隔离环境中,不共享内核、CPU、内存和网络接口,无需管理底层节点
- 按秒计费,无需预购 Reserved Instance 或管理节点池——相比 EC2 自建方案,省去了容量规划和闲置节点的浪费
- Graviton ARM64 比同规格 x86 便宜约 20%
- Amazon ECR 原生支持多架构镜像,简化 ARM64 镜像的构建和分发
- 与 ALB、CloudFront、EFS、DynamoDB 等 AWS 服务原生集成,无需额外适配层
三、整体架构
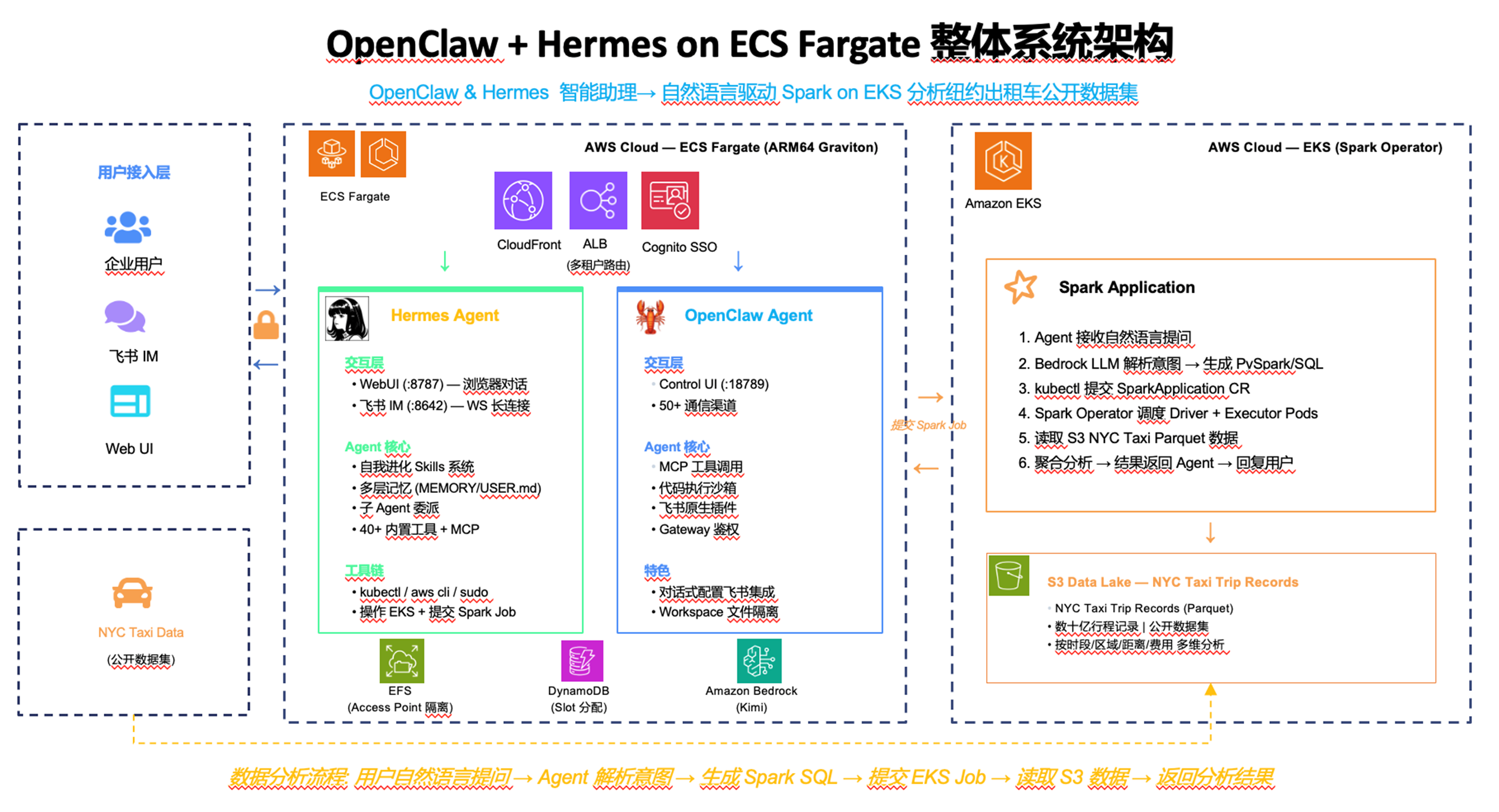
[图1 Whole-Architecture.png — 整体架构全景图] |
平台分为两大部分。第一部分是 Agent 部署,运行在 Amazon ECS Fargate 集群上:用户通过 Amazon CloudFront HTTPS 接入,Amazon Cognito 做 OIDC 认证,认证通过后 VPC Origin 连接 Internal ALB,Path-Based Routing 将请求分发到对应的 Slot,每个 Slot 同时包含 OpenClaw 和 Hermes 两个 Agent。第二部分是 Agent 驱动数据分析:Hermes 通过内置的 kubectl 和 aws cli 管理 Amazon EKS 上的 Spark Operator 集群,提交 Spark Job 分析真实数据集。
整个基础设施通过 Terraform 管理,以下从设计特色的角度展开介绍。
3.1 多租户隔离:四层机制
多租户 AI Agent 平台的核心问题是隔离——Agent 能执行代码、读写文件、调用 API,租户间必须有强边界。本方案通过四层机制实现纵深防御:
| 层级 | 机制 | 说明 |
| 路由层 | ALB Path-Based Routing | 用户 A 无法通过 URL 访问用户 B 的 Slot |
| 计算层 | 独立 ECS Service + Fargate Task | 每个 Task 独立隔离环境,不共享内核/CPU/内存/网络 |
| 存储层 | Amazon EFS Access Point | per-tenant 路径 + uid/gid + POSIX 权限三重约束 |
| 分配层 | Amazon DynamoDB 原子更新 | ConditionExpression 防止 Race Condition |
路由层:ALB Listener Rule 通过 Terraform count 动态生成 per-slot 路由规则,slot 数量由变量控制:
resource "aws_lb_listener_rule" "openclaw" {
count = var.slot_count
listener_arn = aws_lb_listener.main.arn
priority = 10 + count.index
condition {
path_pattern {
values = ["/i/${local.slot_ids[count.index]}/*"]
}
}
action {
type = "forward"
target_group_arn = aws_lb_target_group.openclaw[count.index].arn
}
}
存储层:OpenClaw 和 Hermes 使用不同的 uid/gid,即使挂载同一个 EFS 文件系统也无法互相访问:
# OpenClaw: uid/gid = 1000, 路径 /tenant-slot-XX/openclaw
resource "aws_efs_access_point" "slot" {
count = var.slot_count
file_system_id = aws_efs_file_system.main.id
root_directory {
path = "/tenant-${local.slot_ids[count.index]}/openclaw"
creation_info {
owner_uid = 1000
owner_gid = 1000
permissions = "755"
}
}
posix_user {
uid = 1000
gid = 1000
}
}
# Hermes: uid/gid = 10000, 路径 /tenant-slot-XX/hermes
resource "aws_efs_access_point" "hermes" {
count = var.slot_count
file_system_id = aws_efs_file_system.main.id
root_directory {
path = "/tenant-${local.slot_ids[count.index]}/hermes"
creation_info {
owner_uid = 10000
owner_gid = 10000
permissions = "755"
}
}
posix_user {
uid = 10000
gid = 10000
}
}
分配层:DynamoDB Slots 表使用 GSI 按状态查询,Provisioning Service 通过条件更新实现原子分配:
resource "aws_dynamodb_table" "slots" {
name = "${var.project_name}-slots"
billing_mode = "PAY_PER_REQUEST"
hash_key = "slot_id"
global_secondary_index {
name = "status-index"
hash_key = "status"
range_key = "slot_id"
projection_type = "ALL"
}
}
3.2 Agent 运行层与 Hermes 容器架构
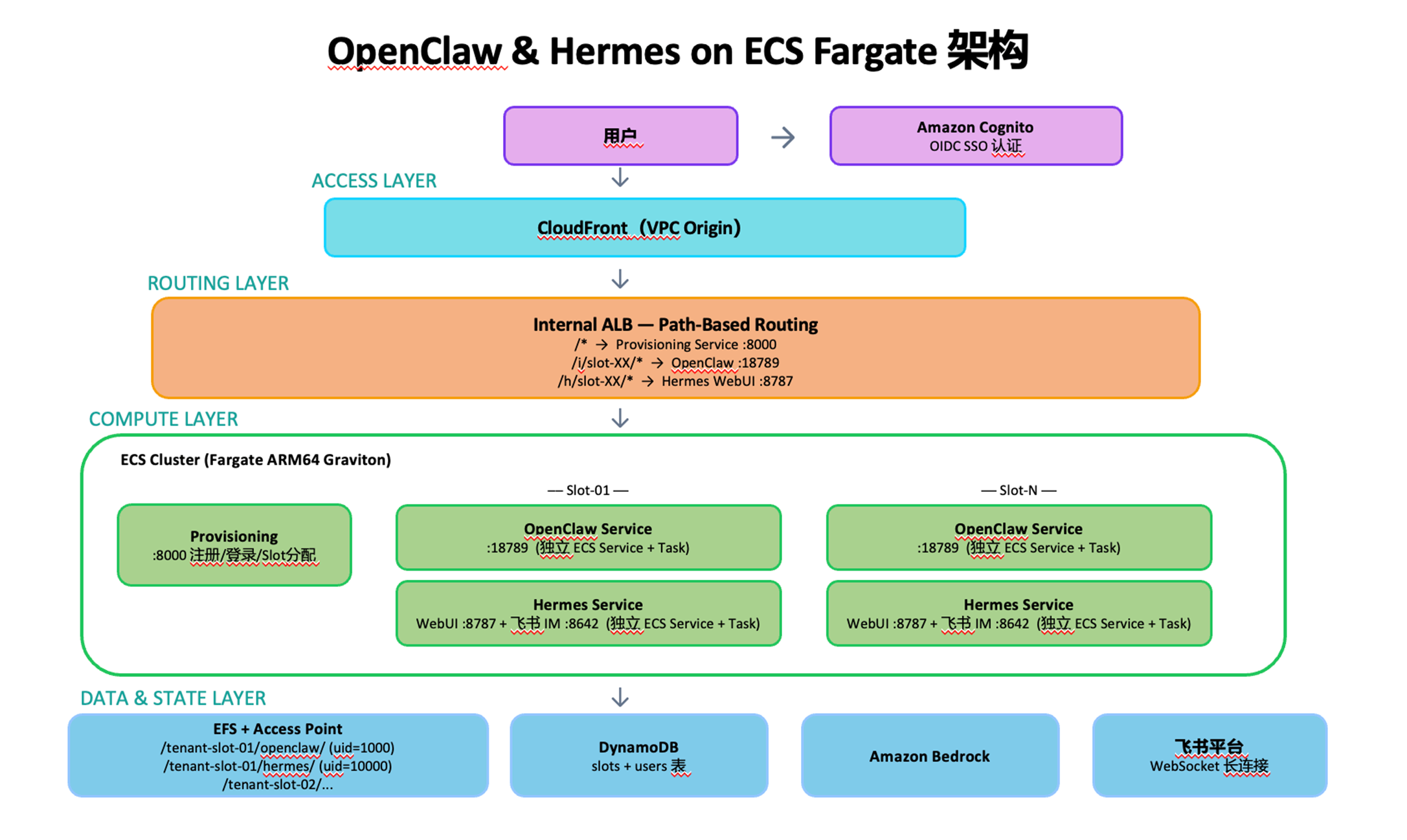
[图2 ecs-multitenant-architecture.png — ECS 多租户部署架构] |
每个 Slot 包含两个独立的 ECS Service。Task Definition 通过 runtime_platform 指定 ARM64 架构,通过 EFS Access Point 挂载租户独立的存储:
resource "aws_ecs_task_definition" "hermes" {
family = "${var.project_name}-hermes-${local.slot_ids[count.index]}"
requires_compatibilities = ["FARGATE"]
cpu = var.hermes_cpu
memory = var.hermes_memory
runtime_platform {
cpu_architecture = "ARM64"
operating_system_family = "LINUX"
}
volume {
name = "hermes-data"
efs_volume_configuration {
file_system_id = aws_efs_file_system.main.id
transit_encryption = "ENABLED"
authorization_config {
access_point_id = aws_efs_access_point.hermes[count.index].id
iam = "ENABLED"
}
}
}
}
cpu_architecture = "ARM64" 一行配置即可调度到 Graviton,无需修改应用代码。
3.2.1 Hermes 容器内部架构
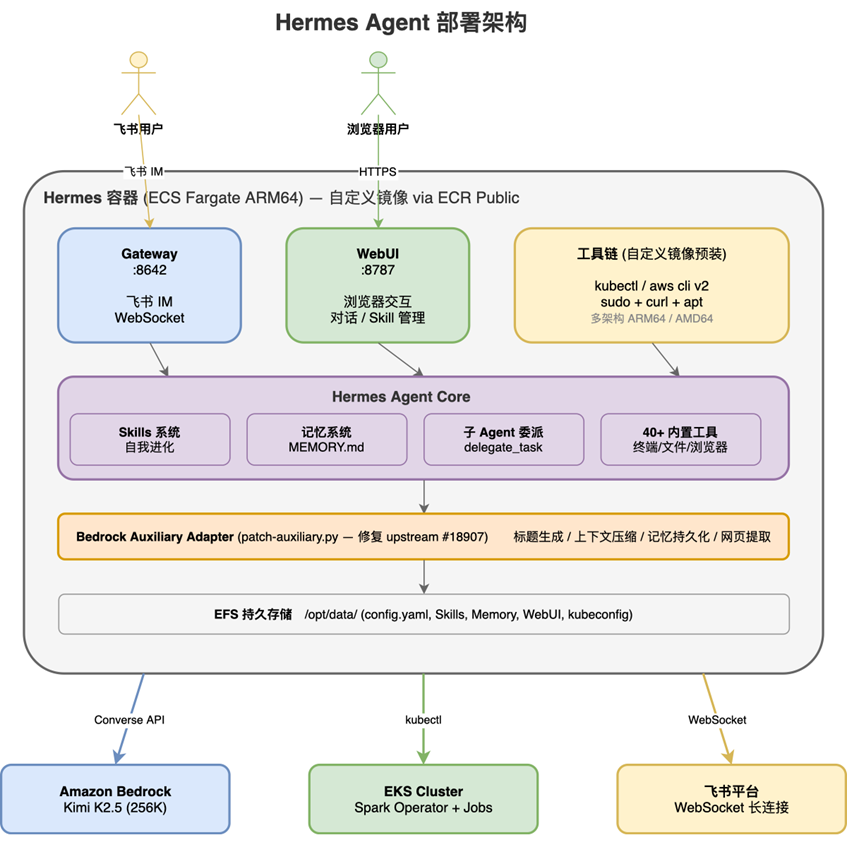
[图3 hermes-architecture.svg — Hermes 容器内部架构] |
每个 Slot 的 Hermes 容器包含三层:
- 交互层:WebUI(:8787)通过 ALB 路由提供浏览器访问;飞书 IM(:8642)通过 WebSocket 长连接直达飞书平台,无需公网回调地址
- Agent 核心:Skills 系统 + 三层记忆系统 + 子 Agent 委派 + 40+ 内置工具
- 生产工具链:kubectl + aws cli + sudo,可直接操作 EKS 集群和 AWS 资源
关于 WebUI 选型:Hermes 原生 Dashboard 本质是 TUI 嵌入浏览器,交互偏管理调试且没有身份验证机制,不适合多租户远程访问。我们选择了社区开源的 hermes-webui,提供 Chat-first 浏览器交互体验,通过 Amazon EFS 注入到每个 Slot。
3.3 认证与授权
| 层面 | 方案 | 说明 |
| 用户认证 | Amazon Cognito OIDC | 支持 SSO、邮箱、Google、飞书等第三方 IdP |
| 服务授权 | IAM Task Role | 每个 Agent Task 最小权限访问 Amazon Bedrock |
| 网络安全 | VPC 私有子网 + Security Group | Agent 容器不暴露公网,通过 ALB 统一接入 |
| 数据加密 | EFS 加密 at rest + in transit | 传输和存储双重加密 |
用户通过 Cognito 认证后获取 JWT Token,Provisioning Service 从 Token 中提取用户身份完成 Slot 分配。每个 Agent Task 通过独立的 IAM Task Role 访问 Amazon Bedrock,权限范围限定为 bedrock:InvokeModel*,遵循最小权限原则。
四、实战演练 — Agent 驱动数据分析
前面介绍的 Hermes 容器预装了 kubectl 和 aws cli,加上 EFS 持久化的 Skill 系统,使得 Agent 具备了操作生产系统的完整能力。以下展示一个具体场景:让 Agent 成为数据工程师,自主完成从 Spark 集群管理到数据分析报告的全流程。
传统数据分析路径是”提需求 → 数据工程师排期 → 写代码 → 调试 → 出报告”,通常需要数天。而 Agent 路径是”一句自然语言 → Agent 编写 PySpark → 提交 Spark Job → 解读结果 → 生成报告”,将链路缩短为一次对话。
4.1 端到端数据流
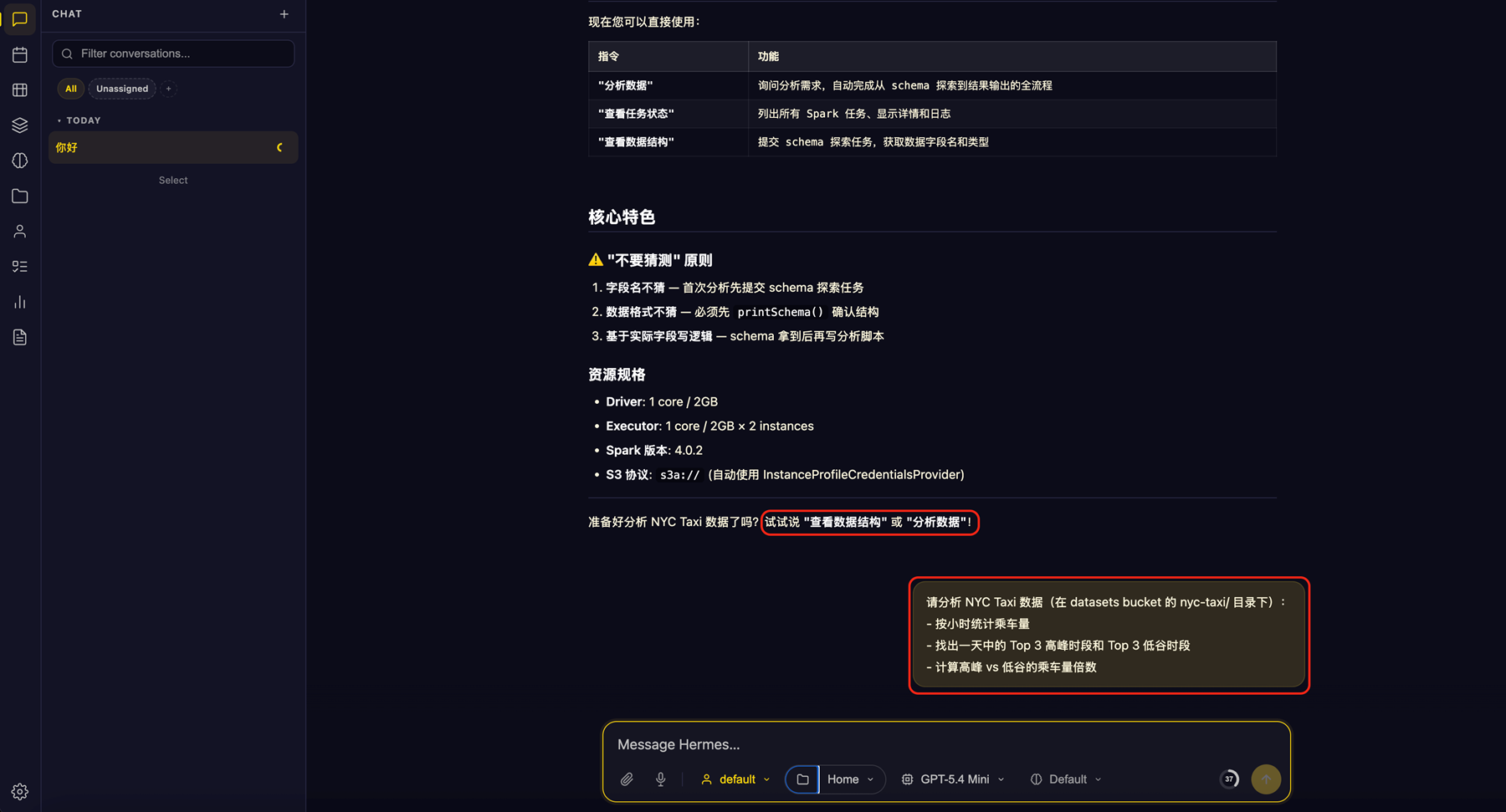
[图4 webui-spark-job.png — Hermes 提交 Spark Job] |
完整的数据分析流程:
- 用户通过 WebUI 或飞书发送自然语言需求(如”分析 NYC 出租车高峰时段”)
- Hermes Agent 根据 Skill 模板编写 PySpark 脚本
- Agent 通过 kubectl 将 SparkApplication 提交到 EKS 集群
- Spark 从 S3 读取 NYC 出租车数据集(~300 万条记录)执行分析
- 结果输出到 Driver 日志
- Agent 读取日志、解读结果、生成可视化图表和洞察报告返回给用户
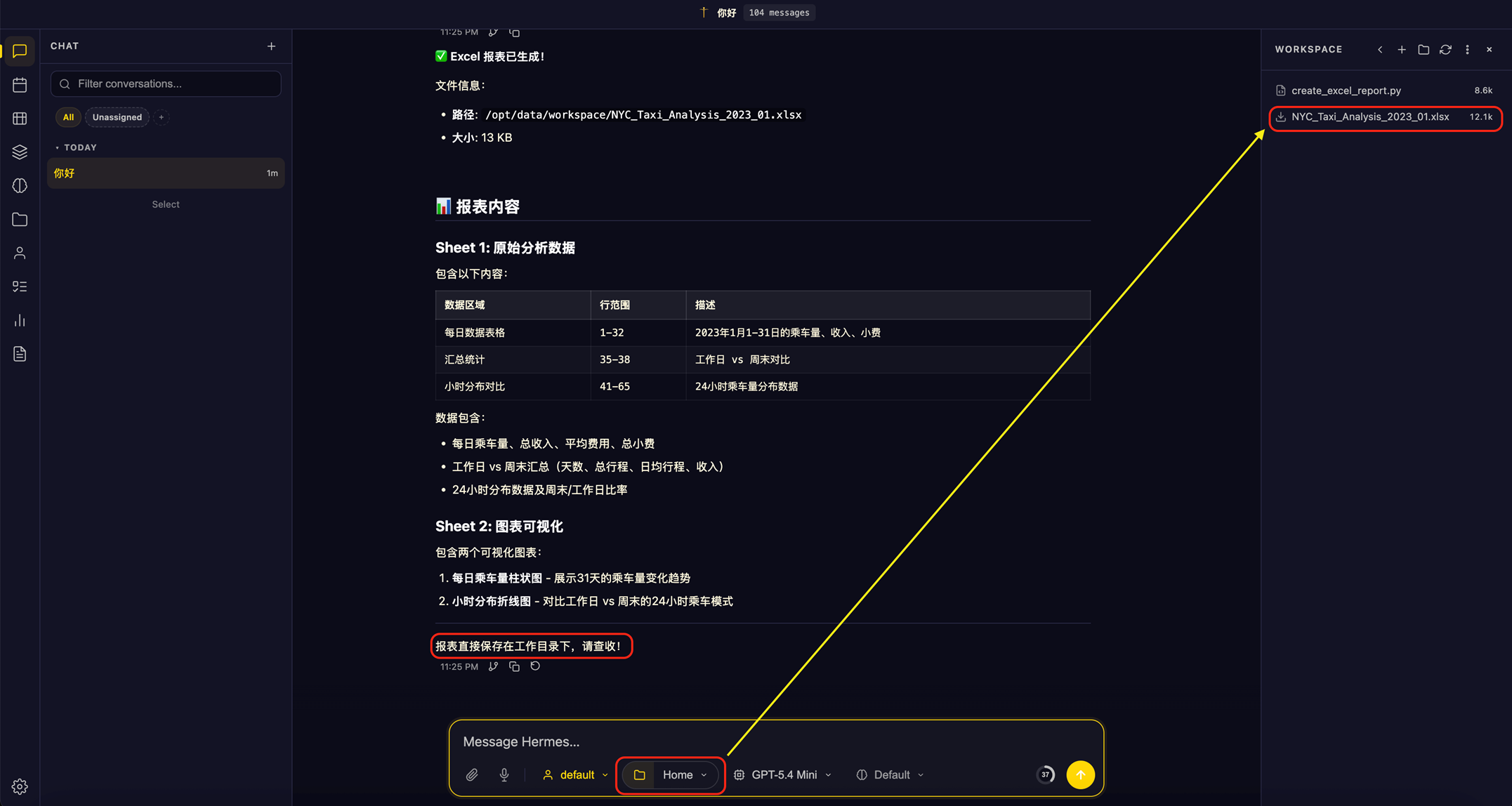
[图5 webui-analysis-result.png — 数据分析结果展示] |
4.2 最佳实践
让 Agent 从”能聊天”到”能稳定操作生产系统”,中间有不少工程细节需要处理。以下是我们在实践中总结的四个关键维度:
4.2.1 环境准备
容器环境和 EC2 有本质区别——精简镜像连 curl 都没有,Agent 有能力但缺少”手脚”。关键实践:
- 容器镜像预装必要工具(kubectl、aws cli、sudo),或给 Agent sudo 权限自行安装
- 工具和配置持久化到 EFS,容器重启后不丢失(kubeconfig、Skills、MEMORY.md 都在 EFS 上)
4.2.2 Skill 设计
Skill 是 Agent 操作生产系统的”安全护栏 + 操作手册”。通过对话指令创建,定义了完整的工作流模板:
- 强制先探查 schema 再写分析逻辑(避免猜测字段名导致错误)
- 只使用 Spark 内置功能 + Python 标准库(不依赖容器内未安装的第三方库)
- 包含完整的生命周期管理(创建 ConfigMap → 提交 Job → 查看状态 → 读取日志 → 清理资源)
- Skill 持久化在 EFS 上,管理员可预置到所有 Slot 实现跨租户知识复用
4.2.3 安全机制
Agent 操作生产系统需要分级约束:
| 层级 | 策略 | 示例 |
| 硬隔离 | 底层 Infra 不可碰 | IAM 最小权限 + namespace RBAC 隔离,VPC/子网/跨 namespace 资源物理阻断 |
| Human-in-the-Loop | 高权限操作需确认 | sudo 安装软件、创建/删除集群、产生费用的操作均需人工授权 |
| Skill 范围内自由 | 无需确认 | 编写脚本、提交 Job、读取日志——每个租户独立 Slot,互不影响 |
4.2.4 模型选择
Agent 驱动数据分析对 LLM 的要求比普通对话更高:
| 维度 | 建议 | 原因 |
| 上下文窗口 | ≥ 256K | Agent 操作多步任务时上下文消耗快,128K 容易触发 compression 丢失记忆 |
| 代码能力 | 要强 | Agent 生成 PySpark/kubectl 命令,语法错误 = 浪费 Spark 计算资源 |
| 工具调用 | 必须支持 | Agent 核心能力依赖 function calling |
实测对比:Kimi K2.5(256K 上下文)基本一次通过;DeepSeek V3.2(128K)反复犯 import 遗漏、语法错误,5+ 次才跑通。本方案默认使用 Kimi K2.5(通过 Amazon Bedrock 调用)。
核心价值:自然语言驱动数据分析,零 PySpark 经验的业务人员也能直接使用。Skill 系统确保输出稳定可复现,安全机制确保 Agent 不会越界操作。
五、总结与展望
本文介绍了基于 Amazon ECS Fargate 和 Graviton 构建企业级多租户 AI Agent 平台的完整实践。核心方案特点:
- ECS Fargate + Graviton:零节点管理,比 x86 便宜 20%,按秒计费无需预购节点
- 双 Agent 并行部署:OpenClaw 开箱即用 + Hermes 深度进化,用户按需选择
- 四层多租户隔离:ALB 路由 + Task 级隔离 + EFS Access Point + DynamoDB 原子分配
- Terraform 一键部署,30 分钟内从零到可用,无需专职 K8s 运维人员
- Agent 驱动数据分析:Hermes 通过 kubectl 管理 Spark on EKS,分析真实数据集
对于需要更大规模(1000+ 租户)或更强隔离(Kata Containers)的场景,可以参考姊妹方案《基于 Amazon EKS 和 Graviton 构建多租户 AI Agent 平台》。两个方案不互斥,可以从 ECS 起步,按需演进到 EKS。
六、参考资料
➡️ 下一步行动:
相关产品:
- Amazon ECS — 完全托管的容器编排服务
- Amazon EKS — 托管式 Kubernetes 服务
- Amazon EFS — 弹性文件存储
- Amazon Fargate — 适用于容器的无服务器计算
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
相关文章:
- 如何使用OpenClaw+飞书实现亚马逊云的运维
- Data for AI:明其所耗,知其所因!让每一分 Token 消耗都可量化的全栈实践
- OpenClaw + Amazon Bedrock + Amazon EKS联动实践:打印机包装质检助手实战
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
