¿Qué son las MLOps?
¿Qué son las MLOps?
Las operaciones de machine learning (MLOps) son un conjunto de prácticas que automatizan y simplifican los flujos de trabajo y los despliegues de machine learning (ML). El machine learning y la inteligencia artificial (IA) son capacidades fundamentales que puede desplegar para resolver problemas complejos del mundo real y ofrecerle valor a sus clientes. MLOps es una cultura y una práctica de ML que une el desarrollo de aplicaciones de ML (Dev) a la implementación y las operaciones (Ops) de sistemas de ML. Su organización puede usar las MLOps para automatizar y estandarizar los procesos a lo largo del ciclo de vida del ML. Estos procesos incluyen el desarrollo de modelos, las pruebas, la integración, el lanzamiento y la administración de la infraestructura.
¿Por qué se necesitan las MLOps?
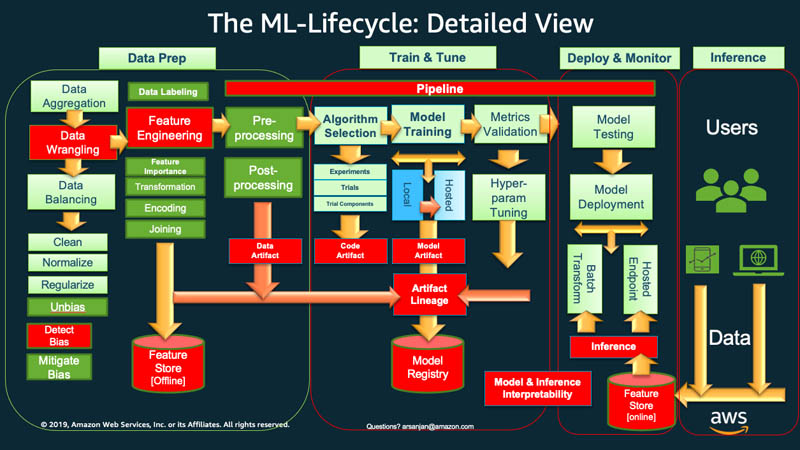
En un nivel alto, para comenzar el ciclo de vida del machine learning, su organización normalmente tiene que empezar con la preparación de los datos. Obtiene datos de diferentes tipos y de diversos orígenes, y realiza varias actividades, como la agrupación, la limpieza de duplicados y la ingeniería de características.
Después de eso, utiliza los datos para entrenar y validar el modelo de ML. A continuación, puede implementar el modelo entrenado y validado como un servicio de predicción al que pueden acceder otras aplicaciones a través de las API.
El análisis exploratorio de datos a menudo requiere que experimente con diferentes modelos hasta que la mejor versión del modelo esté lista para su implementación. Esto conduce a implementaciones frecuentes de versiones de modelos y control de versiones de los datos. El seguimiento de los experimentos y la administración de la canalización de entrenamiento de ML son tareas esenciales antes de que las aplicaciones puedan integrar el modelo a su código o consumirlo.
MLOps es fundamental para administrar de forma sistemática y simultánea el lanzamiento de nuevos modelos de ML con cambios en el código de la aplicación y los datos. Una implementación óptima de MLOps trata los activos de ML de manera similar a otros activos de software de entornos de integración y entrega continuas (CI/CD). Los modelos de ML se implementan junto con las aplicaciones y los servicios que utilizan y aquellos que los consumen como parte de un proceso de lanzamiento unificado.
¿Cuáles son los principios de las MLOps?
A continuación, explicamos cuatro principios clave de las MLOps.
Control de versiones
Este proceso implica el seguimiento de los cambios en los activos de machine learning para que pueda reproducir los resultados y volver a usar versiones anteriores si es necesario. Todas las especificaciones de modelos o código de entrenamiento de ML pasan por una fase de revisión del código. Cada una con su número de versión para que el entrenamiento de los modelos de ML se pueda reproducir y auditar.
La capacidad de replicación en un flujo de trabajo de ML es importante en todas las fases, desde el procesamiento de datos hasta la implementación del modelo de ML. Implica que cada fase debería producir resultados idénticos con la misma entrada.
Automatización
Automatice diversas etapas de la canalización de machine learning para garantizar la repetibilidad, la coherencia y la escalabilidad. Esto incluye etapas que van desde la ingesta de datos, el preprocesamiento, el entrenamiento y la validación del modelo hasta la implementación.
Estos son algunos factores que pueden desencadenar el entrenamiento y la implementación automatizados de modelos:
- Mensajería
- Monitoreo de los eventos en el calendario
- Cambios en los datos
- Cambios en el código de entrenamiento del modelo
- Cambios en el código de la aplicación
Las pruebas automatizadas le permiten descubrir los problemas de forma temprana para corregir errores y aprender rápidamente. La automatización es más eficiente con la infraestructura como código (IaC). Puede usar herramientas para definir y administrar la infraestructura. De esta manera, se asegura de que puede repetir los procesos e implementar los recursos de manera uniforme en varios entornos.
Actividades continuas
A través de la automatización, puede ejecutar pruebas e implementar código de forma continua en toda su canalización de ML.
En las MLOps, el término continuo se refiere a cuatro actividades que ocurren constantemente si se realiza algún cambio en alguna parte del sistema:
- La integración continua extiende la validación y las pruebas del código a los datos y los modelos en la canalización.
- La entrega continua implementa automáticamente el modelo recién entrenado o el servicio de predicción con modelo.
- El entrenamiento continuo vuelve a entrenar automáticamente los modelos de ML para volver a implementarlos.
- El monitoreo continuo se refiere al monitoreo de datos y al monitoreo de modelos utilizando métricas relacionadas con la empresa.
Gobernanza de los modelos
La gobernanza implica administrar todos los aspectos relacionados con los sistemas de ML para lograr una mayor eficiencia. Debe realizar muchas actividades para encargarse de la gobernanza:
- Fomente una estrecha colaboración entre los científicos de datos, los ingenieros y las partes interesadas de la empresa
- Utilice documentación clara y canales de comunicación efectivos para asegurarse de que todos estén al tanto y de acuerdo con los planes
- Establezca mecanismos para recopilar comentarios sobre las predicciones de los modelos y entrenarlos aún más
- Asegúrese de que los datos confidenciales estén protegidos, que el acceso a los modelos y la infraestructura sea seguro, y que se cumplan los requisitos de conformidad
También es esencial contar con un proceso estructurado para revisar, validar y aprobar los modelos antes de que se empiecen a utilizar. Esto puede implicar comprobar la imparcialidad, los prejuicios y las consideraciones éticas.
¿Qué beneficios aportan las MLOps?
El machine learning ayuda a las organizaciones a analizar los datos y obtener información para tomar decisiones. Sin embargo, es un campo innovador y experimental que presenta sus propios desafíos. La protección de datos confidenciales, los presupuestos reducidos, la escasez de personal calificado y la tecnología en constante evolución limitan el éxito de un proyecto. Sin control ni orientación, los costos pueden dispararse, y los equipos de ciencia de datos tal vez no logren los resultados deseados.
Las MLOps aportan un mapa para guiar los proyectos de machine learning hacia el éxito, sin importar las limitaciones. Estos son algunos de los beneficios clave de las MLOps.
Reducción del plazo de comercialización
Con las MLOps, su organización consigue un marco para alcanzar sus objetivos de ciencia de datos de manera más rápida y eficiente. Sus desarrolladores y gerentes pueden adoptar enfoques más estratégicos y ágiles en la administración de modelos. Los ingenieros de machine learning pueden aprovisionar la infraestructura a través de archivos de configuración declarativos para que los proyectos arranquen sin problemas.
La automatización a la hora de crear e implementar modelos se traduce en una comercialización más rápida con costos operativos más bajos. Los científicos de datos pueden explorar rápidamente los datos de una organización para ofrecer más valor empresarial a todos.
Productividad mejorada
Las prácticas de MLOps aumentan la productividad y aceleran el desarrollo de modelos de ML. Por ejemplo, puede estandarizar el entorno de desarrollo o experimentación. De esa forma, sus ingenieros de ML pueden lanzar proyectos nuevos, alternar entre proyectos y reutilizar modelos de ML en todas las aplicaciones. Pueden crear procesos repetibles para que la experimentación y el entrenamiento de modelos sean tareas rápidas. Los equipos de ingeniería de software pueden colaborar entre sí y coordinar su trabajo a lo largo del desarrollo de software de ML para lograr una mayor eficiencia.
Eficiencia en la implementación de modelos
Las MLOps mejoran la resolución de problemas y la administración de modelos en producción. Por ejemplo, los ingenieros de software pueden monitorear el desempeño del modelo y reproducir el comportamiento para solucionar problemas. Pueden rastrear y administrar de forma centralizada las versiones de los modelos y elegir la más adecuada para diferentes casos de uso empresariales.
Al integrar los flujos de trabajo del modelo a canalizaciones de integración y entrega continuas (CI/CD), se limita la degradación del rendimiento y se mantiene la calidad del modelo. Esto es cierto incluso después de las actualizaciones y el ajuste del modelo.
¿Cómo se implementan las MLOps en la organización?
Hay tres niveles de implementación de MLOps, según la madurez de la automatización en su organización.
Nivel 0 de MLOps
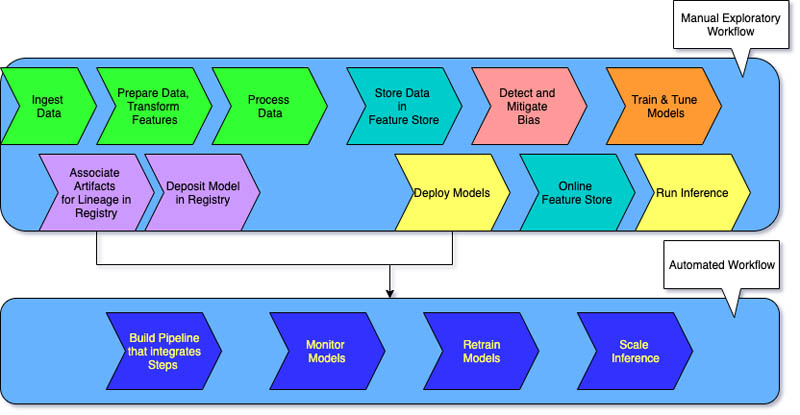
El nivel 0 para las organizaciones que recién comienzan a usar sistemas de machine learning se caracteriza por incluir flujos de trabajo de ML manuales y un proceso dirigido por científicos de datos.
Cada paso es manual, incluidos la preparación de los datos, el entrenamiento de ML y el desempeño y la validación del modelo. Requiere una transición manual entre los pasos, y cada paso se ejecuta y administra de forma interactiva. Los científicos de datos suelen entregar modelos entrenados como artefactos que el equipo de ingeniería implementa en la infraestructura de API.
El proceso separa a los científicos de datos que crean el modelo de los ingenieros que lo implementan. Los lanzamientos poco frecuentes implican que los equipos de ciencia de datos pueden volver a entrenar los modelos solo unas pocas veces al año. No hay consideraciones de CI/CD para los modelos de ML con el resto del código de la aplicación. Del mismo modo, no se monitorea activamente el rendimiento.
Nivel 1 de MLOps
Las organizaciones que desean entrenar los mismos modelos con datos nuevos con frecuencia requieren una implementación de nivel 1. El nivel 1 de MLOps tiene como objetivo entrenar el modelo de forma continua mediante la automatización de la canalización de ML.
En el nivel 0, se implementa un modelo entrenado en la etapa de producción. Por otro lado, en el nivel 1, se implementa una canalización de entrenamiento que se ejecuta de forma recurrente para ofrecer el modelo entrenado a las demás aplicaciones. Como mínimo, se logra una entrega continua del servicio de predicción con modelo.
El nivel 1 tiene las siguientes características:
- Pasos para experimentar rápidamente con ML que implican bastante automatización
- Entrenamiento continuo del modelo en producción con datos nuevos que activan la canalización en funcionamiento
- Implementación de la misma canalización en todos los entornos de desarrollo, preproducción y producción
Sus equipos de ingeniería trabajan con los científicos de datos para crear componentes de código en módulos que se puedan reutilizar, que puedan definirse de acuerdo con la componibilidad y que potencialmente se compartan con todas las canalizaciones de ML. También crea un almacén de características centralizado que estandariza el almacenamiento, el acceso y la definición de las características para el entrenamiento y el servicio de ML. Además, puede administrar los metadatos, como la información sobre cada ejecución de la canalización y los datos sobre la capacidad de replicación.
Nivel 2 de MLOps
El nivel 2 de MLOps es para las organizaciones que desean experimentar más y crear con frecuencia modelos nuevos que requieran entrenamiento continuo. Es adecuado para empresas impulsadas por la tecnología que actualizan sus modelos en cuestión de minutos, los entrenan cada una hora o todos los días y, al mismo tiempo, los vuelven a implementar en miles de servidores.
Como hay varias canalizaciones de ML en juego, una configuración de MLOps de nivel 2 requiere la configuración completa de MLOps de nivel 1. También requiere lo siguiente:
- Un orquestador de canalizaciones de ML
- Un registro de modelos para controlar varios modelos
Las tres etapas siguientes se repiten a escala para varias canalizaciones de ML para garantizar la entrega continua del modelo.
Creación de la canalización
Pruebe de forma iterativa nuevos modelos y nuevos algoritmos de ML y, al mismo tiempo, se asegura de que se hayan organizado los pasos de experimentación. Esta etapa genera el código fuente de sus canalizaciones de ML. El código se almacena en un repositorio de código fuente.
Implementación de la canalización
A continuación, crea el código fuente y ejecuta las pruebas para obtener los componentes de la canalización para su implementación. El resultado es una canalización desplegada con la implementación del nuevo modelo.
Empleo de la canalización
Por último, utilice la canalización como un servicio de predicción para sus aplicaciones. Recopile estadísticas sobre el servicio implementado de predicción con modelo a partir de datos que se obtienen en tiempo real. Con el resultado de esta etapa, se activa la ejecución de la canalización o un nuevo ciclo de experimentación.
¿En qué se diferencian las MLOps de las DevOps?
Tanto las MLOps como las DevOps son prácticas que tienen como objetivo mejorar los procesos en los que se desarrollan, implementan y monitorean las aplicaciones de software.
Las DevOps tienen como objetivo cerrar la brecha entre los equipos de desarrollo y operaciones. Permiten garantizar que los cambios en el código se prueben, integren e implementen automáticamente en la producción de manera eficiente y confiable. Promueven una cultura de colaboración para acelerar los ciclos de lanzamiento, mejorar la calidad de las aplicaciones y usar de forma más eficiente los recursos.
Las MLOps, por otro lado, son un conjunto de prácticas recomendadas que se establecieron específicamente para proyectos de machine learning. Si bien implementar e integrar el software tradicional pueden ser tareas relativamente sencillas, los modelos de ML presentan desafíos particulares. Implican la recopilación de datos, el entrenamiento de modelos, la validación, la implementación y el monitoreo y reentrenamiento continuos.
Las MLOps se centran en automatizar el ciclo de vida del machine learning. Ayudan a garantizar que los modelos no solo se desarrollen, sino que también se implementen, monitoreen y vuelvan a entrenar de manera sistemática y repetida. Incorpora los principios de DevOps al ML. Las MLOps dan como resultado una implementación más rápida de los modelos de ML, mayor precisión a lo largo del tiempo y mayor seguridad de que aportan valor real a la empresa.
¿Con qué puede ayudarlo AWS para que cumpla sus requisitos de MLOps?
Amazon SageMaker es un servicio totalmente administrado que puede usar para preparar datos y crear, entrenar e implementar modelos de aprendizaje automático. Es adecuado para cualquier caso de uso con infraestructura, herramientas y flujos de trabajo totalmente administrados.
SageMaker proporciona herramientas diseñadas específicamente para que las MLOps automaticen los procesos a lo largo del ciclo de vida del ML. Al usar las herramientas de Sagemaker para MLOps, puede alcanzar rápidamente la madurez de nivel 2 de mLOps a escala.
Estas son las principales características de SageMaker que puede utilizar:
- Utilice Experimentos de SageMaker para controlar los artefactos relacionados con sus trabajos de entrenamiento de modelos, como parámetros, métricas y conjuntos de datos.
- Configure Canalizaciones de SageMaker para que se ejecuten automáticamente a intervalos regulares o cuando se produzcan ciertos eventos.
- Utilice Registro de modelos de SageMaker para controlar las versiones de los modelos. También puede monitorear sus metadatos, como la agrupación de casos de uso, y los valores de referencia de las métricas de rendimiento de los modelos en un repositorio central. Puede utilizar esta información para elegir el mejor modelo en función de los requisitos de su empresa.
Comience a usar mLOps en Amazon Web Services (AWS) creando una cuenta hoy mismo.