- AWS Solutions Library
- Generative AI Application Builder on AWS
Generative AI Application Builder on AWS
Rapidly develop and deploy production-ready Agentic AI applications
Overview
Building and managing agentic AI applications can be challenging for teams without deep AI infrastructure or orchestration expertise. Generative AI Application Builder (GAAB) on AWS eliminates that complexity by unifying all the key components of modern agentic systems into one integrated solution. GAAB brings together the Model Context Protocol (MCP), agents, and multi-agent orchestration with built-in authentication, permissioning, networking, and application management—so teams can focus on iterating and improving their applications instead of managing infrastructure.
With GAAB, you can deploy local MCP servers as remote endpoints using AWS Lambda, container images, or OpenAPI and Smithy API specifications. The platform enables developers to create agents, assign MCP tools, and orchestrate complex behaviors through the Agent-as-a-Tool framework. Once an agentic application is ready, teams can collaborate instantly by accessing the application out of the box or integrating it with their own client through a single WebSocket connection.
GAAB accelerates the path from prototype to production by simplifying the deployment, management, and scaling of secure, extensible agentic applications built on AWS.
Benefits
You can experiment with different model, system prompt, and memory configurations for the same use case to compare outputs and performance directly from the GAAB management dashboard. Once you have completed your testing iterations, you can easily deploy the GAAB created applications with the default user interface or integrate the agentic application with your existing system.
Centralize the deployment and management of Model Context Protocol (MCP) servers, AI Agents, and Multi-agent workflows while governing and decentralizing access to the deployed agentic applications across your teams.
-
Built with AWS Well-Architected design principles, this solution offers enterprise-grade security and scalability with high availability and low latency, ensuring seamless integration into your applications with high performance standards.
Extend this solution’s functionality by integrating your existing projects or natively connecting additional AWS services. GAAB is an open-source application, enabling you to use the included Strands and LangChain orchestration layers and Lambda functions to connect with the services of your choice.
How it works
Build and Deploy Agents
The Agent Builder use case enables you to quickly configure, deploy, and manage AI Agents from the Management Dashboard. Configure the Agent's model, tools, memory, system prompt, and integration pattern before deploying the AI Agent stack.
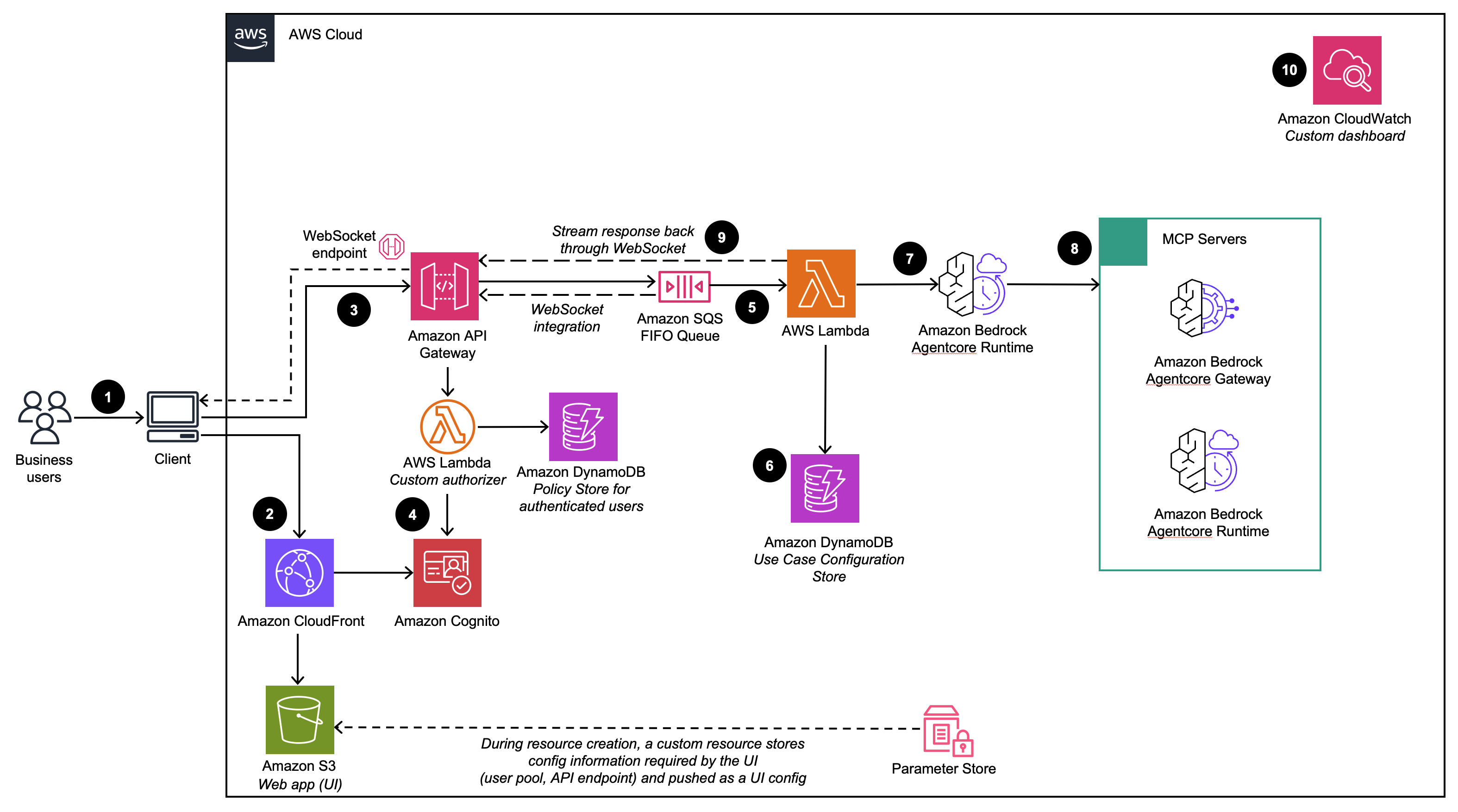
Multi-Agent Applications
The Multi-Agent use case enables you to quickly orchestrate multiple Agents to address complex tasks from the Management Dashboard. Configure the orchestration Agent's model, the AI Agents to use as tools, the orchestration prompt, and integration pattern before deploying the Multi-Agent stack.
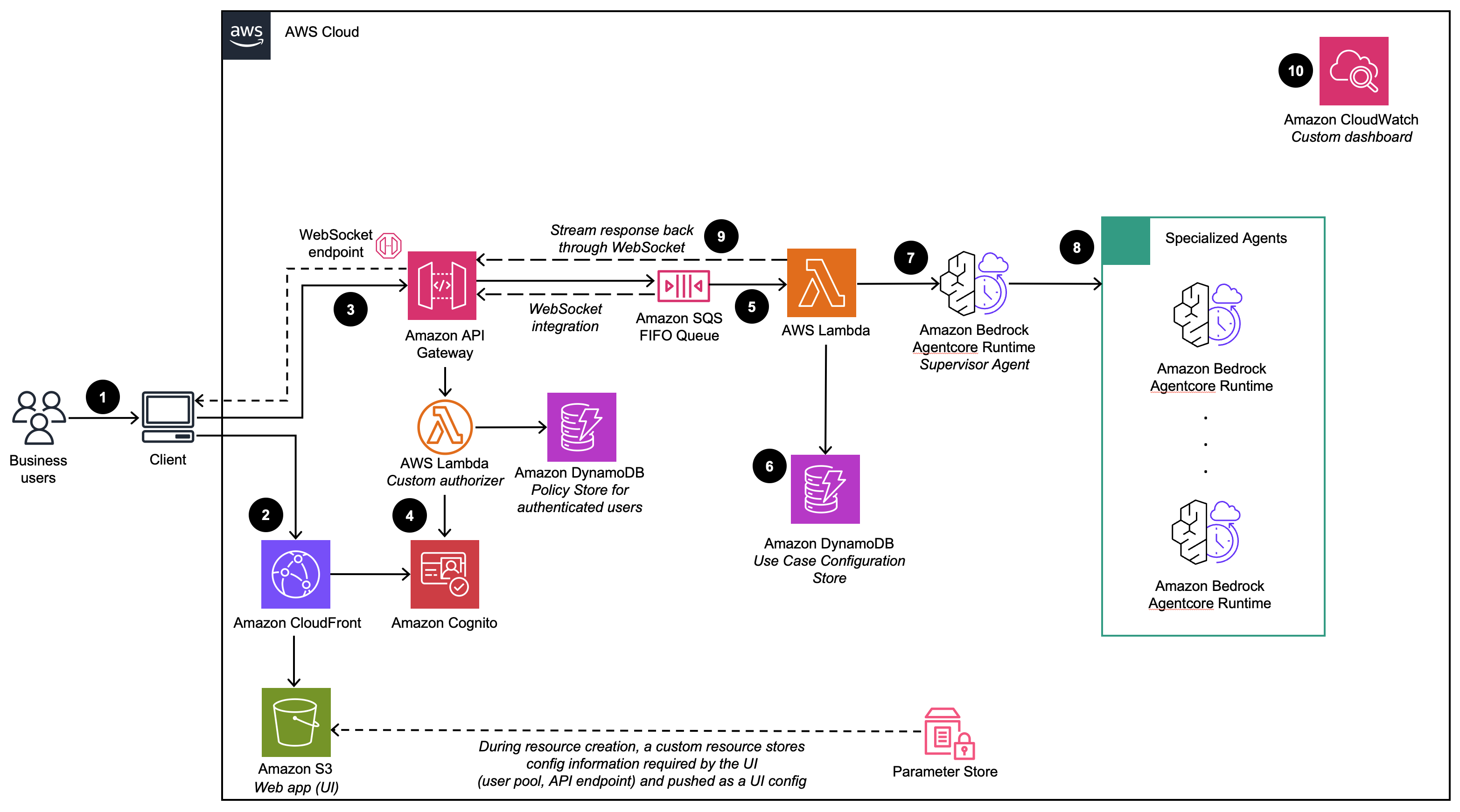
Deploy Remote MCP Servers
The MCP Server use case enables you to quickly deploy and manage MCP Servers from the Management Dashboard. You can connect to any existing MCP Server by providing its endpoint URL, or deploy and host your own MCP Server via an image, Lambda function, OpenAPI spec, or Smithy file, providing the flexibility to integrate external third-party services or self-hosted MCP Servers for use in Agent Builder and Multi-Agent Use cases.
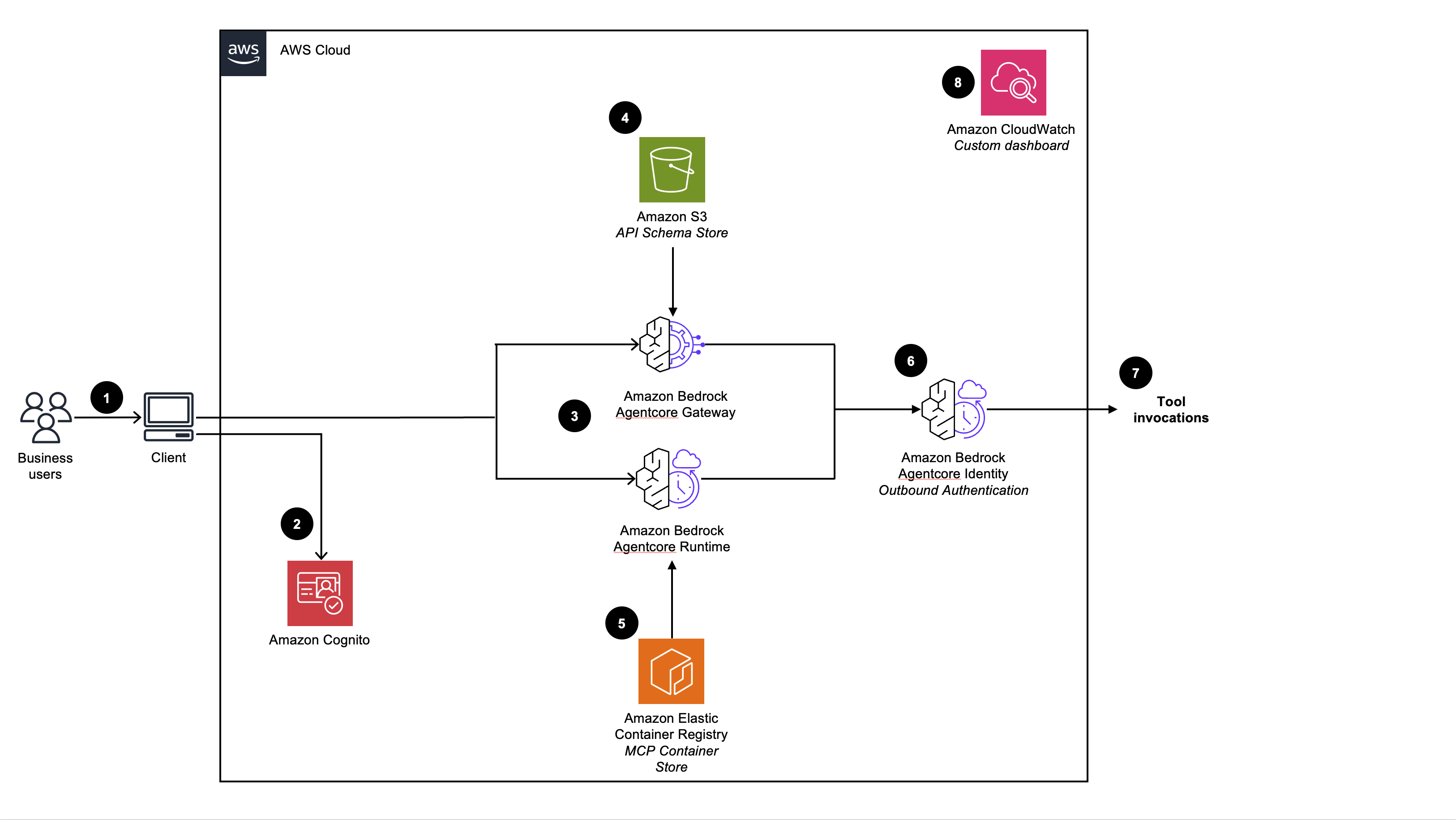
Retrieval Augmented Generation (RAG) Chatbots
The RAG Chatbot use case enables you to quickly deploy and manage a Retrieval Augmented Generation (RAG) enabled chatbot. Configure the chatbot’s model, RAG knowledgebase, and guardrails to implement safeguards and reduce hallucinations before deploying the chatbot stack.
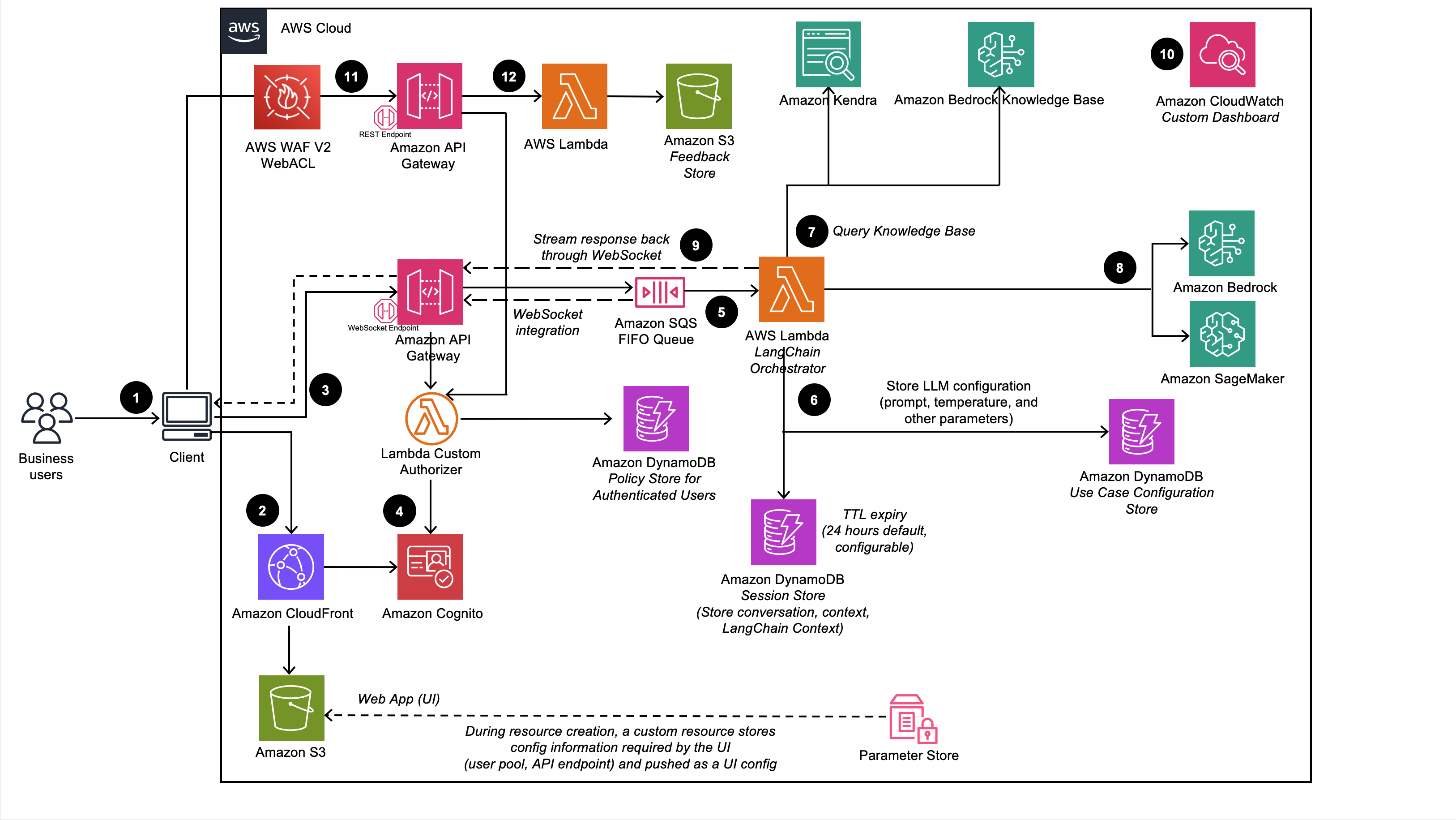
Management Dashboard
The Management Dashboard is a web UI management console for admin users to create and manage remote MCP Servers, Agents, Multi-Agent workflows, and RAG chatbot deployments. This dashboard enables customers to rapidly experiment with configurations across models, tools, and memory before deploying governed and production-ready Agentic applications.
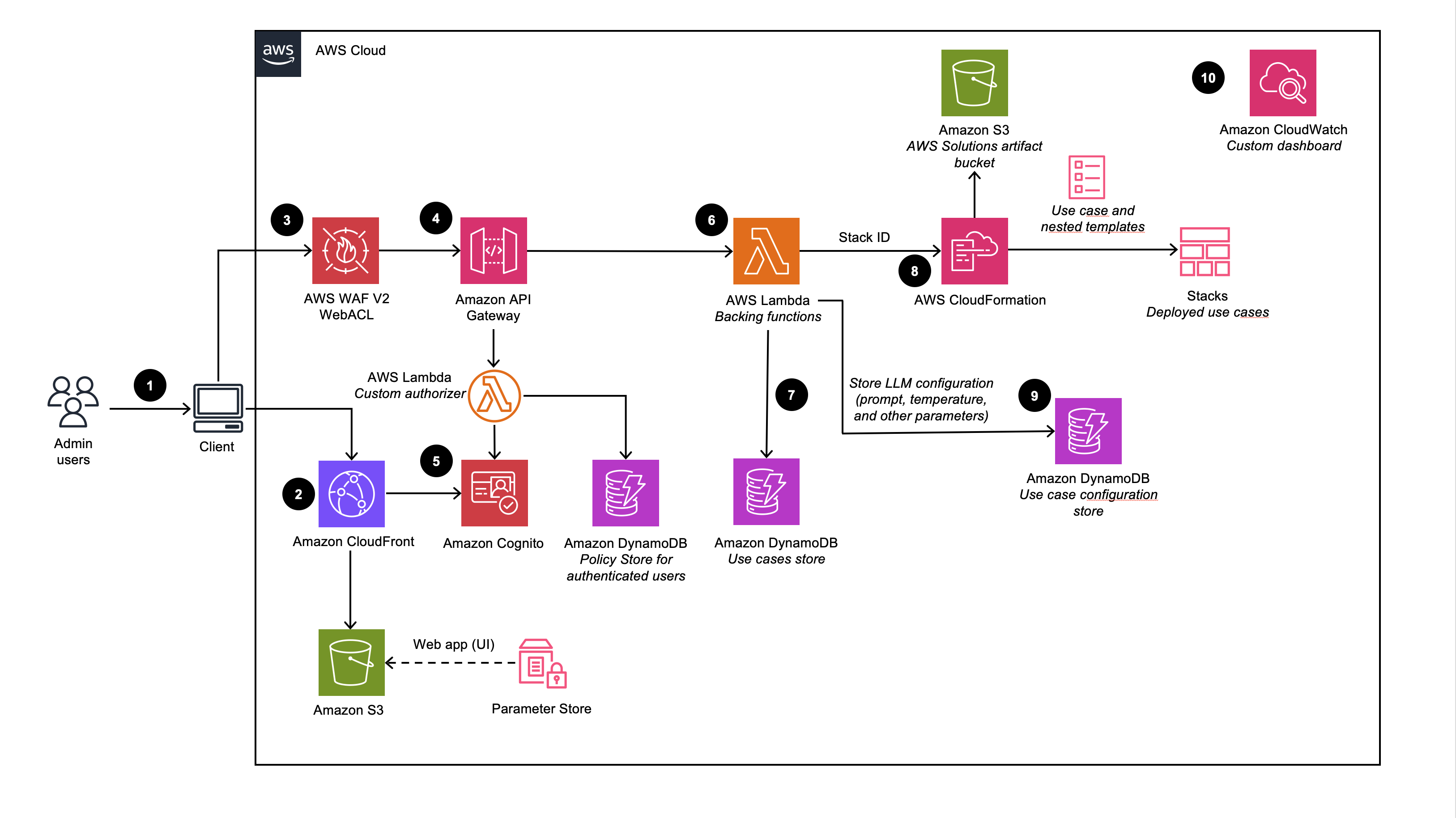
About this deployment
-
Version: 4.1.8
-
Released: 3/2026
-
Author: AWS
-
Est. deployment time: 10 mins
-
Estimated cost: See details
Deploy with confidence
Everything you need to launch this AWS Solution in your account is right here
We'll walk you through it
Get started fast. Read the implementation guide for deployment steps, architecture details, cost information, and customization options.
Let's make it happen
Ready to deploy? Open the CloudFormation template in the AWS Console to begin setting up the infrastructure you need. You'll be prompted to access your AWS account if you haven't yet logged in.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages