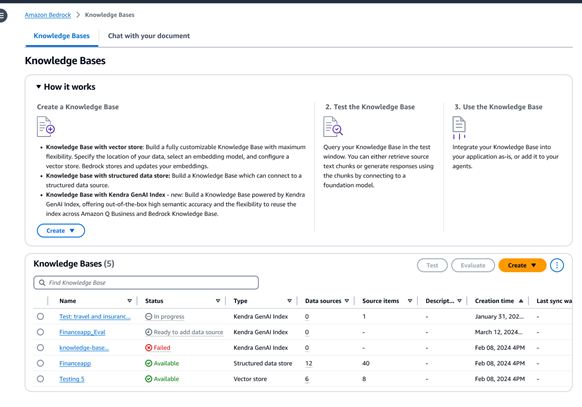
Bases de connaissances Amazon Bedrock
Grâce aux bases de connaissances Amazon Bedrock, vous pouvez fournir aux modèles fondamentaux et aux agents des informations contextuelles issues des sources de données privées de votre entreprise afin de donner des réponses plus pertinentes, plus précises et plus personnalisées.
Support entièrement géré pour un flux de travail RAG de bout en bout
Pour fournir aux modèles de fondation (FM) des informations exclusives et à jour, les organisations utilisent la génération à enrichissement contextuel (RAG), une technique qui permet d’extraire les données des sources de données de l’entreprise et d’enrichir les invites afin de générer des réponses plus pertinentes et plus précises. Les bases de connaissances Amazon Bedrock sont une capacité entièrement gérée comprenant une gestion intégrée du contexte de la session et de l’attribution de la source, qui vous aide à mettre en œuvre l’intégralité du flux de travail RAG, de l’ingestion à la récupération et à l’augmentation des invites, sans avoir à développer d’intégrations personnalisées aux sources de données ni à gérer les flux de données. Vous pouvez également poser des questions et résumer les données d’un seul document, sans configurer de base de données vectorielles. Si vos données contiennent des sources structurées, les bases de connaissances Amazon Bedrock propose un langage naturel géré intégré au langage de requête structuré pour générer une commande de requête afin de récupérer les données, sans avoir à les déplacer vers un autre entrepôt.
Connectez en toute sécurité les FM et les agents aux sources de données
Si vous disposez de sources de données non structurées, les bases de connaissances Amazon Bedrock récupèrent automatiquement les données de sources telles qu’Amazon Simple Storage Service (Amazon S3), Confluence, Salesforce, SharePoint ou Web Crawler. En outre, vous recevez également l’ingestion de documents par programmation pour permettre aux clients d’ingérer des données en streaming ou des données provenant de sources non prises en charge. Une fois le contenu ingéré, les bases de connaissances Amazon Bedrock le convertissent en blocs de texte, convertissent le texte en intégrations et stockent les intégrations dans votre base de données vectorielles. Vous pouvez choisir parmi plusieurs boutiques vectorielles prises en charge, notamment Amazon Aurora, Amazon OpenSearch sans serveur, l’analytique Amazon Neptune, MongoDB, Pinecone et Redis Enterprise Cloud. Vous pouvez également choisir de vous connecter à un index de recherche hybride Amazon Kendra pour une extraction gérée.
À l’aide des bases de connaissances Amazon Bedrock, vous pouvez également vous connecter à vos banques de données structurées pour générer des réponses fondées. Cela peut être particulièrement utile lorsque vous disposez de documents sources tels que des informations transactionnelles stockées dans des entrepôts de données et des lacs de données. Les bases de connaissances Amazon Bedrock utilisent le langage naturel vers SQL pour convertir les requêtes en commandes SQL et exécuter les commandes pour récupérer les données, sans avoir à les déplacer depuis votre source.
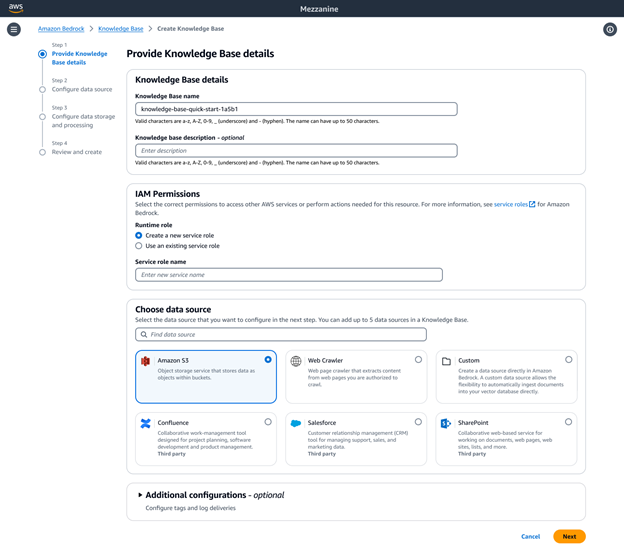
Personnalisez les bases de connaissances Amazon Bedrock pour fournir des réponses précises au moment de l’exécution
Avec les bases de connaissances Amazon Bedrock comme solution RAG entièrement gérée, vous avez la possibilité de personnaliser et d’améliorer la précision de la récupération. Pour les sources de données non structurées contenant des données multimodales telles que des images et des documents visuellement riches avec des mises en page complexes (par exemple, des documents contenant des tableaux, des figures, des graphiques et des diagrammes), vous pouvez configurer les bases de connaissances pour analyser, examiner et extraire des informations pertinentes. Vous pouvez choisir Bedrock Data Automation ou des modèles de fondation comme analyseur. Cela permet un traitement fluide de données multimodales complexes, et donc de créer des applications GenAI de haute précision.
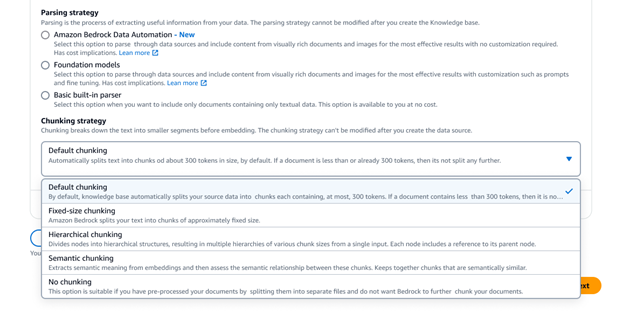
Les bases de connaissances Amazon Bedrock proposent diverses options avancées de découpage des données, notamment des découpages sémantiques, hiérarchiques et à taille fixe. Pour un contrôle total, vous pouvez également écrire votre propre code de découpage sous forme de fonction Lambda et même utiliser des composants prêts à l’emploi provenant de frameworks comme LangChain et LlamaIndex. Si vous choisissez l’analytique Amazon Neptune comme boutique vectorielle, les bases de connaissances Amazon Bedrock crée automatiquement des vectorisations et des graphiques qui lient le contenu associé entre vos sources de données. Bedrock Knowledge Bases exploite ces relations de contenu avec GraphRAG pour améliorer la précision de la récupération, ce qui permet d’adresser des réponses plus complètes, pertinentes et explicables aux utilisateurs finaux.
Récupérer des données et améliorer les invites
À l’aide de l’API Retrieve, vous pouvez récupérer des résultats pertinents pour une requête utilisateur à partir de bases de connaissances, y compris des éléments visuels tels que des images, des diagrammes, des graphiques, des tableaux, du contenu audio et vidéo, ou des données structurées provenant de bases de données, le cas échéant. L’API RetrieveAndGenerate va encore plus loin en utilisant directement les résultats multimodaux récupérés pour augmenter l’invite FM et renvoyer la réponse. Vous pouvez également choisir de fournir des filtres ou d’utiliser un FM pour générer des filtres implicites afin de limiter les résultats renvoyés au contenu pertinent uniquement. Les bases de connaissances Amazon Bedrock proposent des modèles de reclassement pour améliorer la pertinence des segments de documents récupérés dans le contenu textuel, visuel et multimédia.
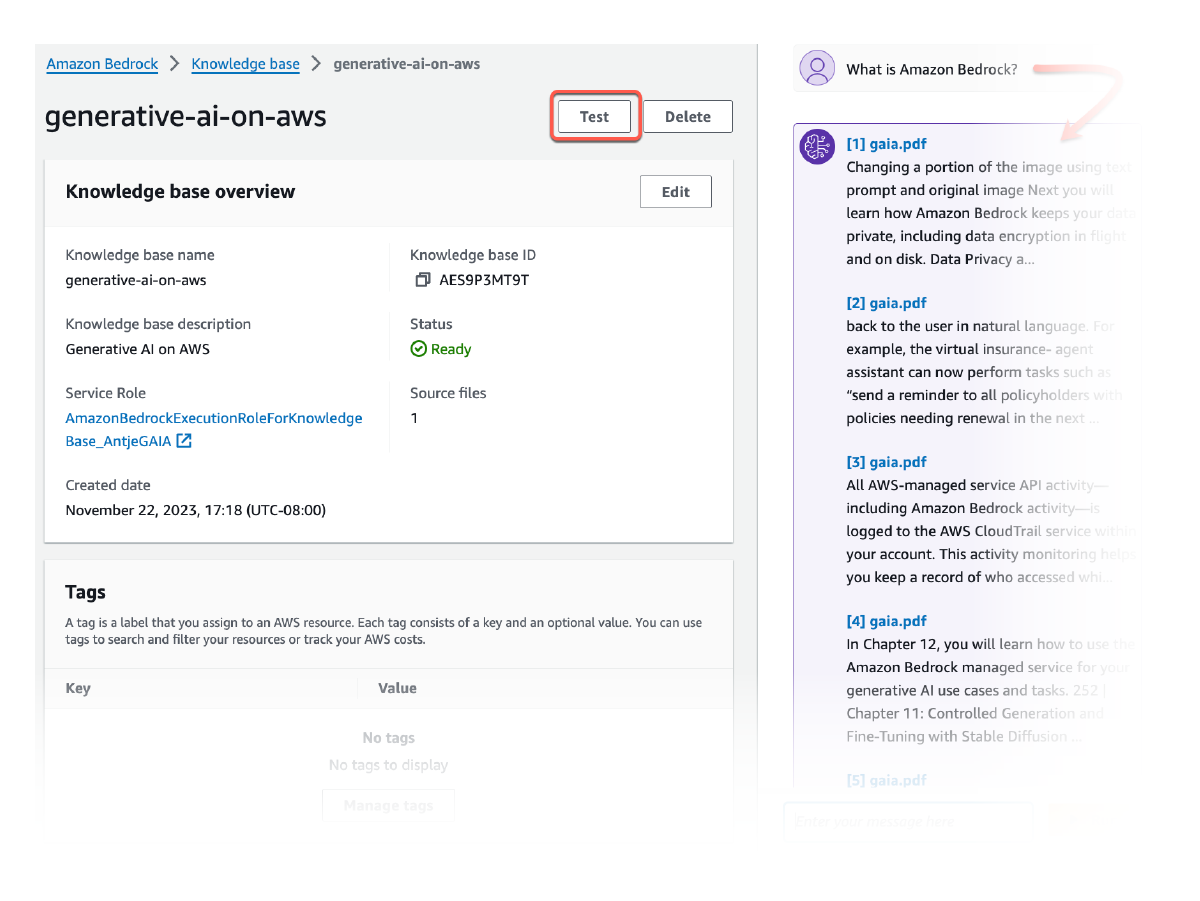
Fournir l’attribution de la source
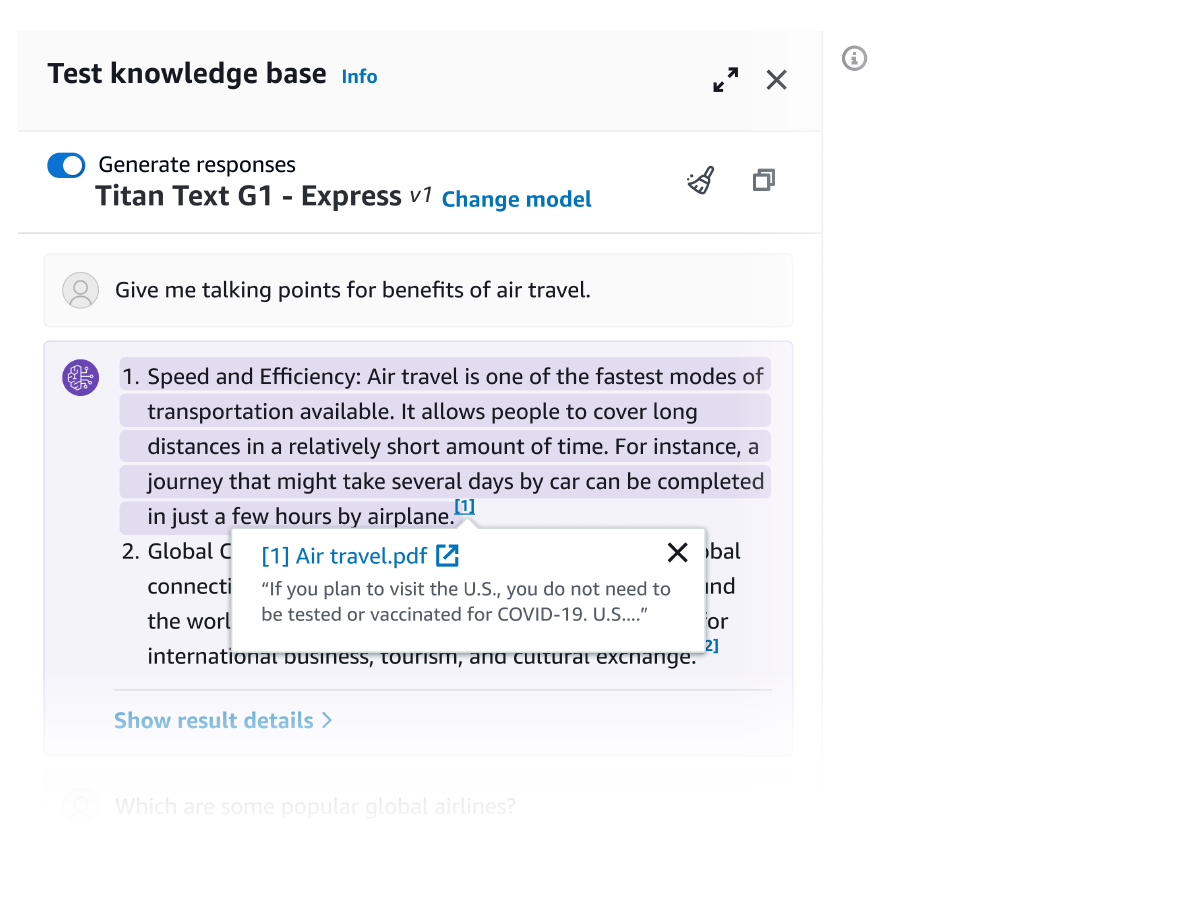
Toutes les informations extraites des bases de connaissances Amazon Bedrock sont accompagnées de citations (comprenant des visuels) afin d’améliorer la transparence et de minimiser les hallucinations.
Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages
Comment démarrer
Les nouvelles capacités de New Amazon Bedrock améliorent le traitement et la récupération des données.
Découvrez les cas d’utilisation courants de l’IA générative avec Amazon Bedrock Workshop
Utilisez RAG pour améliorer les réponses des applications d’IA générative