Amazon Web Services ブログ
データサイエンス100本ノックが SageMaker Studio Lab からすぐに学べるようになりました
2022 年夏の甲子園は、決勝で満塁ホームランが出る記録的な試合となりました。球児が野球のノックを受けるのなら、エンジニアが受けるノックは何でしょう ? 本記事では「データサイエンス 100 本ノック(構造化データ加工編)」を Amazon SageMaker Studio Lab で簡単に学ぶ方法をご紹介します。データサイエンス 100 本ノックは、データベースのテーブルや CSV ファイルといった表形式のデータから欲しいデータを取り出す方法を学べる教材です。 GitHub で公開されており、 2022 年 8 月時点で 1,800 を超える Star がつけられています。

データサイエンス 100 本ノック(構造化データ加工編)トップページより
普段データベースに触れる機会があるエンジニアの方はもちろん、表計算ソフトから一歩進んで Python によるデータ処理にチャンレンジしたい方にもおすすめの教材です。高校球児たちが熱戦を繰り広げるまさに 8 月、著者の森谷さんらのご協力で Studio Lab で学びやすくなったので Studio Lab でノックを開始する方法をご紹介します。
データサイエンス 100 本ノック 構造化データ加工編とは
「データサイエンス 100 本ノック(構造化データ加工編)」は、 データサイエンティスト検定を行うデータサイエンティスト協会が無料で公開している教材です。データサイエンティスト協会ではデータサイエンティストに必要なスキルとしてビジネス力、データサイエンス力、データエンジニアリング力の 3 つを定義していますが、本教材はデータエンジニアリング力を学べる教材になります。

学び方のガイドは協会のロゴが含まれるためクレジットの表記・改変禁止での利用( CC-BY-ND)となりますが、そのほかの教材は MIT ライセンスで利用が可能です。大学や企業でも「データサイエンティスト協会スキル定義委員」の「データサイエンス 100 本ノック(構造化データ加工編)」を利用していることを明示すれば自由に利用ができます。
全 100 本の構成は下表のとおりになっています。テーブルの列/行に対する操作、表形式データの結合、外れ値・異常値・欠損値を処理する方法、日付型や座標データの処理などを一通り学ぶことができます。

「データサイエンス100本ノック(構造化データ加工編)」のガイドより引用
データサイエンス 100 本ノック 構造化データ加工編の特徴
データエンジニアリングが無料で学べる教材はなかなかなく、希少性という点でまずデータサイエンス 100 本ノックには価値があります。さらに、100 本ノックには 3 つの学びやすい特徴があります。
- SQL 、 Python 、 R 、3つの言語がサポートされている
- 実践的なデータをもとに学ぶことができる
- 書籍によるガイドが提供されている
100 本ノックは SQL 、 Python 、 R の3つの言語いずれでも実施ができます。特に Python や R の経験はないが SQL はよく知っている方は 100 本ノックを通じて Python や R 、データサイエンスに触れることができます。逆に Python や R でのデータ分析には慣れているがアプリケーション開発経験があまりない方は、 Docker を使った環境構築や pre-commit によるコミット前の自動チェックを経験することでアプリケーション開発の作法に触れることができます。どのような経験がある方でも新しいことが学べるよう配慮された、素晴らしい教材です。
100 本ノックでは実践的な小売の POS データが題材になっています。テーブルの構造はマスタとトランザクションに分けられており、顧客名や住所が日本語などデータの内容も現実的です。以下はテーブルの構成図ですが、データ項目から実践的なデータであることを感じていただけると思います。

データサイエンス100本ノック(構造化データ加工編)の100knocks_ER.pdfより引用
100 本ノックを完遂するために「データサイエンス 100 本ノック構造化データ加工編ガイドブック」が発売されています。回答は GitHub リポジトリに用意されていますが、解説が欲しい方は書籍から回答に至るまでの理由を学ぶことができます。
データサイエンス 100 本ノック 構造化データ加工編をAmazon SageMaker Studio Labで学ぶ
Amazon SageMaker Studio Lab はメールアドレスのみ、無料でデータサイエンスを学ぶための環境が利用できるサービスです。利用にあたってAWSアカウントはいらないため、クレジットカードを登録する必要がありません。「データサイエンスの学びを支援する Amazon SageMaker Studio Lab をグラレコで解説」ではイラスト付きで Studio Lab の特徴を解説しています。
データサイエンス 100 本ノック 構造化データ加工編が Studio Lab で学びやすい理由は 3 点です。
- 「 Open Studio Lab 」のボタンをクリックするだけで Studio Lab での学習を開始できる。
- 学習用の環境、学習の途中経過を静的ストレージに保存できる。
- Python と R いずれでも学ぶことができる。
100 本ノックの GitHub 上にある「 Open Studio Lab 」のボタンをクリックするだけで Studio Lab での学習を開始できます。
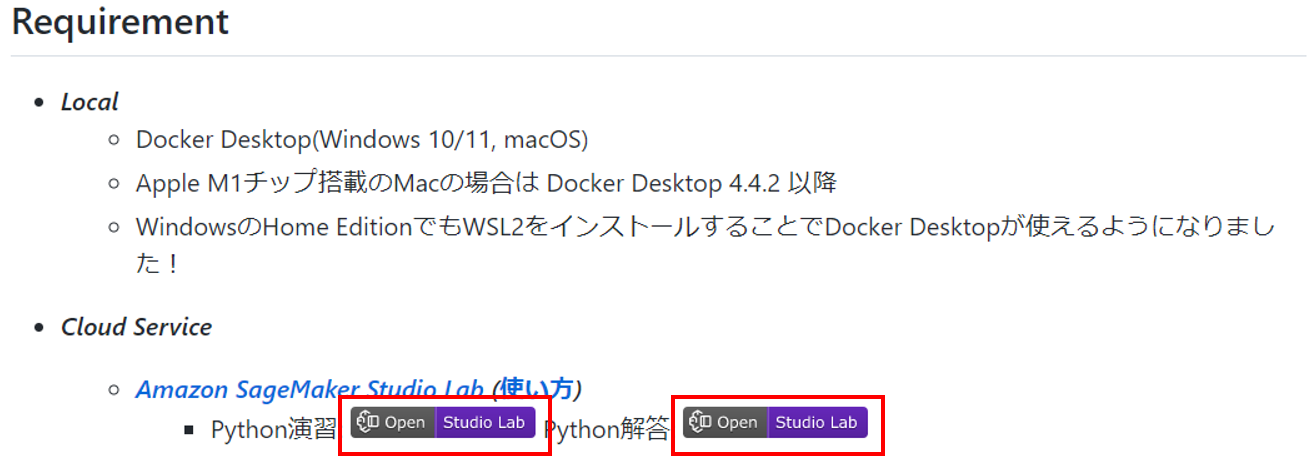
「データサイエンス 100 本ノック(構造化データ加工編)」 README.md より
通常は Docker を使用し環境を構築しますが、データエンジニアリングを学びたい方の中には Docker になじみがない方もいらっしゃると思います。そうした方は、 Studio Lab を利用することで環境構築の手間をスキップして学習をはじめることができます(将来的にデータサイエンスを開発に活かしたい場合は前述のとおり Docker に慣れておくことはおすすめです)。
Studio Lab は永続ストレージを持っているのが大きな特徴です。100 本ノックを動作させるための環境は永続ストレージに格納されます。そのため、セッションが切れるたび pip install で最初からセットアップをする必要がありません。もちろん、100 本ノックの途中経過も保存されます。いつでも中断し、中断したところから再開することができます。
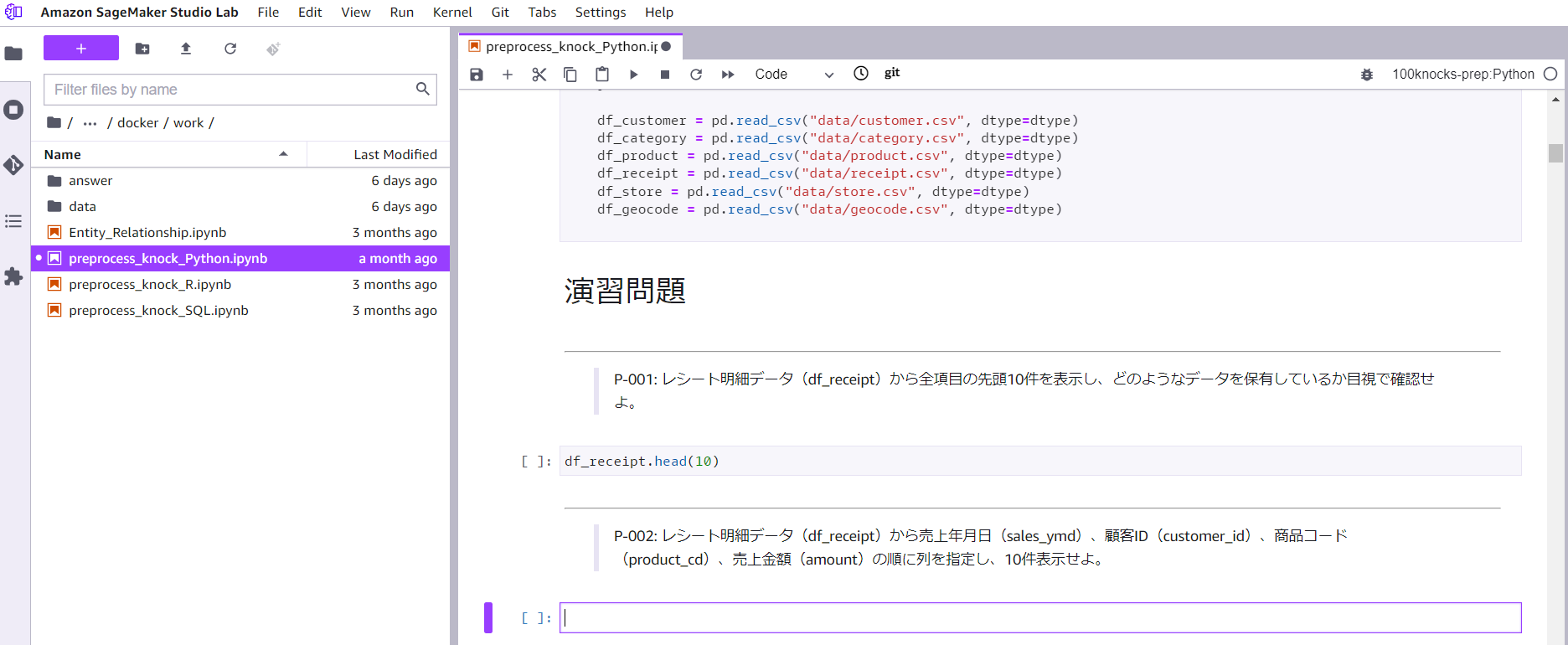
100 本ノックを Studio Lab で解いている様子
Studio Lab は R のカーネルを動かすことができるため、 R の問題も解くことができます。Jupyter Lab をベースにしているため、 R をはじめとし様々な言語のカーネルを追加できるのも Studio Lab の魅力です。 2022 年 8 月の時点ではワンクリックで R の問題が実行できるボタンはまだつけられていませんが、今後 Pull Request で実装することを検討しています。もちろん、100 本ノックはオープンソースなので R の環境構築に長けた方にぜひ Pull Request の作成を検討いただければうれしいです!
では、 Studio Lab で 100 本ノックを開始してみましょう!
1.Studio Labにログインする
ログインページから、 Studio Lab にログインします。Studio Lab のアカウントは Request Account から作成できます。

2.ランタイムを実行する
Start runtime ボタンをクリックし、実行環境を立ち上げましょう。CPU と GPU 両方つかえますが、100 本ノックは CPU で十分です。 CPU の方が 12 時間とセッション時間が長いので、集中力を失わずに済みます。

3. データサイエンス 100 本ノック 構造化データ加工編にアクセスする
Studio Lab とは別のブラウザのタブから、「データサイエンス 100 本ノック 構造化データ加工編」を開いてください。紫色の Open Studio Lab ボタンをクリックします。現在は Python 版を解くことができます。クリックするのは演習、解答どちらのボタンでも構いません。演習、解答、両方の Jupyter Notebook を取り込む手順を解説します。

「データサイエンス 100 本ノック(構造化データ加工編)」 README.mdより
4. データサイエンス 100 本ノック 構造化データ加工編を Studio Lab にコピーする
Copy to project ボタンをクリックし、教材ファイルを Studio Lab にコピーします。
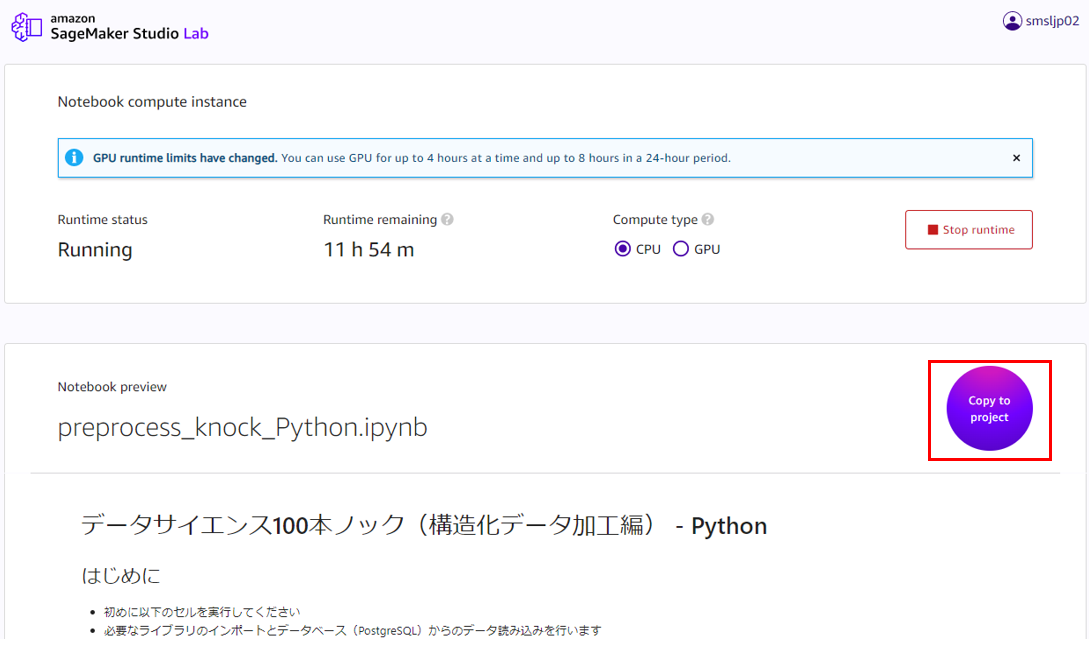
今回は演習、解答を含むすべてのファイルをコピーします。
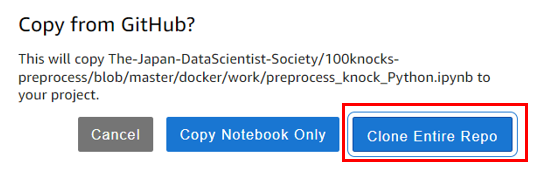
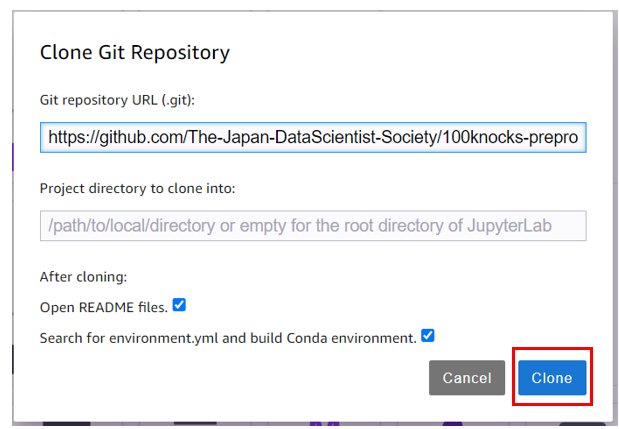
100 本ノックのリポジトリには環境の定義ファイル ( environment.yml ) が含まれるので、これを利用して環境をつくるか確認が行われます。OKをクリックします。
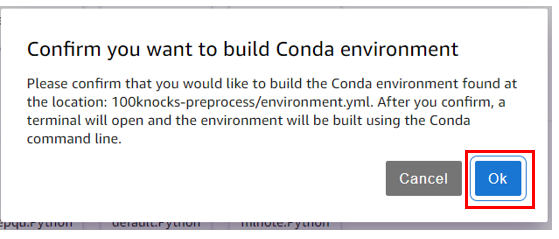
自動的にターミナルが立ち上がり、コマンドが実行されます。100knocks-prep という 100 本ノックを動かすための環境が作成されます。下図のようにコマンドが終了したら完了です。

5. 学習をはじめる
ファイルのコピー、環境の構築が終了したので学習がはじめられます。Python 版の場合、演習用と解答の Jupyter Notebook は次のパスになります。問題を解くときは演習用、解答を見るときは解答の Jupyter Notebookを開いてください。
- 演習用: docker/work/preprocess_knock_Python.ipynb
- 解答: docker/work/answer/ans_preprocess_knock_Python.ipynb
Jupyter Notebook を実行する時は、実行環境として作成した 100knocks-prep を選択するのを忘れないようにしましょう。( 100knocks-prep の環境を作成してから Jupyter Notebook で選択できるようになるまで少し時間がかかります)。
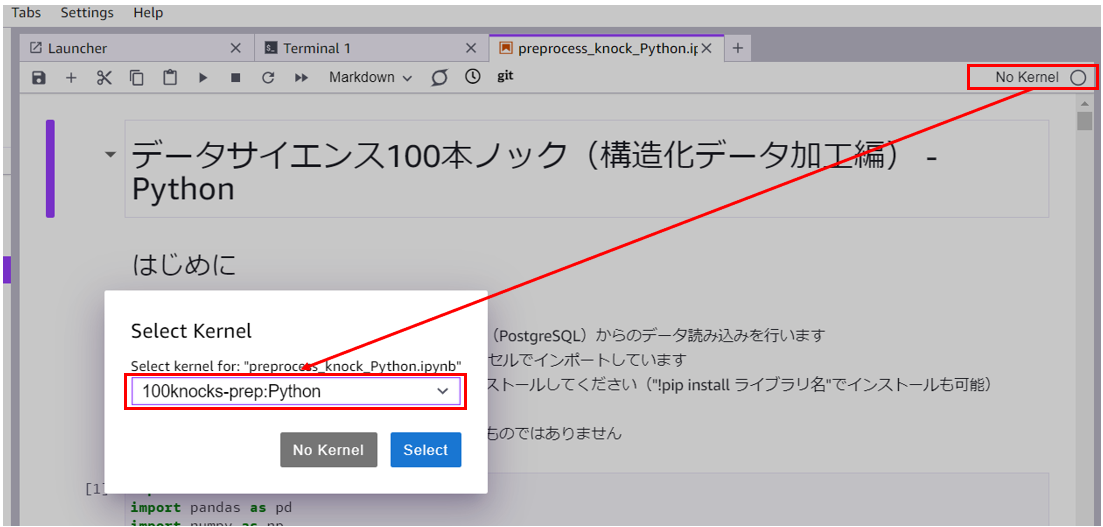
一度開いた Jupyter Notebook は、次に起動したときも開いたままになっています。ちょっと休憩する時などでも安心ですね。高校球児でも 100 本ノックを受けるときは休憩をはさむと思うので、みなさんも休憩を入れながらチャレンジしていただければと思います!
おわりに
AWSでは機械学習の学びから活用までを支援しています。学びの支援の一例として、「データサイエンス 100 本ノック 構造化データ加工編」をStudio Labで学ぶ方法をご紹介しました。 Studio Lab で学べる教材に興味がある方は、Studio Lab Community のページをご参照ください。Studio Lab Community のページでは、データサイエンティスト協会が定義する 3 つのスキル、ビジネス力、データサイエンス力、データエンジニアリング力のカテゴリにそってそれぞれが身に着けられる教材を紹介しています。ビジネス力を磨ける教材として「 ML Enablement Workshop 」、データサイエンス力が磨ける教材として「機械学習帳」を掲載しています。今後もデータサイエンスを学び、活用するのに役立つ教材を紹介していきます。
学びから活用へのステップアップを支援をするため「 AWS Black Belt ML Enablement Series 」をYouTubeで公開しています。この動画ではプロダクトで機械学習を活用するためのプロジェクトの進め方を解説しています。「機械学習モデル開発プロジェクトの進め方」や「機械学習の価値を計算する」は特に重要なプロセスを解説しており、シリーズの中でも特に再生、Goodボタンを頂いています。本番環境に機械学習モデルを配置する時は本格的な機械学習モデルの開発環境である SageMaker が適しています。 Studio Lab は SageMaker への移行手順を用意しており、 SageMaker のドキュメントで手順を解説しています。 SageMaker の使い方がわからない際は、ML Enablement SeriesのDark Partの動画シリーズでわかりやすく(かつ面白く!?)解説しているのでぜひご覧いただければと思います。 AWS に直接ご相談されたい方は AWS 技術相談窓口も活用頂ければと思います。
本記事がデータサイエンスを学び、活用したい方のお役に立てば幸いです!
著者について
久保 隆宏 ( Takahiro Kubo ) : 機械学習領域の Developer Relations Engineer です。機械学習を学び活用する際に AWS が最適なプラットフォームとなるよう、研究者や開発者の方からフィードバックを収集し、サービスの改善に活かす活動をしています。個人的には金融領域での機械学習の活用、特に非財務情報を自然言語処理で解析する方法に関心があります。過去に、データセットの公開やプロダクトの開発に携わった経験があります。