Amazon Web Services ブログ
AWS Glue Data Catalog で Apache Iceberg 統計情報を収集してクエリパフォーマンスを高速化する
本記事は 2024 年 7 月 9 日 に公開された「Accelerate query performance with Apache Iceberg statistics on the AWS Glue Data Catalog」を翻訳したものです。
2024 年 8 月: この記事は Amazon Athena のサポートについて更新されました。
本日、AWS Glue Data Catalog の新機能として、Apache Iceberg テーブルのカラムレベル集計統計情報を生成してクエリを高速化する機能を発表いたします。これらの統計情報は Amazon Redshift Spectrum と Amazon Athena のコストベースオプティマイザ (CBO) で活用され、クエリパフォーマンスの向上とコスト削減につながります。
Apache Iceberg は、データレイク上で ACID トランザクションを実現するオープンテーブルフォーマットです。大規模な分析データセットの処理に適しており、小さな行レベルの操作でも効率的に動作します。また、タイムトラベル、スキーマエボリューション、隠しパーティショニングなどの便利な機能も提供しています。
AWS はお客様のフィードバックに基づき、Iceberg ワークロードを実現するためのサービス統合に投資してきました。その一例が AWS Glue Data Catalog です。Data Catalog は組織のデータセットに関するメタデータを保存する一元的なリポジトリであり、ユーザーがデータを可視化、検索、クエリできるようにします。Data Catalog は Iceberg テーブルをサポートしており、テーブルの現在のメタデータを追跡します。また、トランザクション書き込みごとに生成される個々の小さなファイルを、読み取りとスキャン操作を高速化するために少数の大きなファイルに自動コンパクションすることもできます。
2023 年、Data Catalog は非 Iceberg テーブルのカラムレベル統計情報のサポートを発表しました。この機能はクエリエンジンの CBO で使用されるテーブル統計情報を収集します。今回、Data Catalog はこのサポートを Iceberg テーブルにも拡張しました。Data Catalog が生成する Iceberg テーブルのカラム統計情報は Puffin Spec に基づいており、他のテーブルデータとともに Amazon Simple Storage Service (Amazon S3) に保存されます。これにより、Iceberg をサポートするさまざまなエンジンがこれらを活用し、更新できます。
この記事では、Iceberg テーブルのカラムレベル統計情報が Redshift Spectrum と Amazon Athena でどのように機能するかを説明します。さらに、TPC-DS データセットを使用して Iceberg カラム統計情報のパフォーマンス上のメリットを紹介します。
Iceberg テーブルのカラム統計情報の仕組み
AWS Glue Data Catalog は、Apache DataSketches の Theta Sketch アルゴリズムを使用してテーブルカラム統計情報を生成し、個別値の数 (NDV) を推定して Puffin ファイルに保存します。
SQL プランナーにとって、NDV はクエリプランニングを最適化するための重要な統計情報です。NDV 統計情報がクエリパフォーマンスを最適化できるシナリオがいくつかあります。例えば、2 つのテーブルをカラムで結合する場合、オプティマイザは NDV を使用して結合の選択性を推定できます。一方のテーブルの結合カラムの NDV が他方のテーブルと比較して低い場合、オプティマイザはシャッフル結合の代わりにブロードキャスト結合を選択し、データ移動を削減してクエリパフォーマンスを向上させることができます。さらに、3 つ以上のテーブルを結合する場合、オプティマイザは各結合の出力サイズを推定し、効率的な結合順序を計画できます。また、NDV は group by、distinct、count クエリなどのさまざまな最適化にも使用できます。
ただし、100% の精度で NDV を継続的に計算するには O(N) の空間計算量が必要です。代わりに、Theta Sketch はすべての個別値をメモリやストレージに保存することなく、データセット内の NDV を推定できる効率的なアルゴリズムです。Theta Sketch の主なアイデアは、データを 0〜1 の範囲にハッシュし、しきい値 (θ で表される) に基づいてハッシュ値の一部のみを選択することです。この小さなデータのサブセットを分析することで、Theta Sketch アルゴリズムは元のデータセットの NDV の正確な推定値を提供できます。
Iceberg の Puffin ファイルは、インデックスや統計情報などの情報を blob タイプとして保存するように設計されています。保存できる代表的な blob タイプの 1 つは apache-datasketches-theta-v1 で、これは Theta Sketch アルゴリズムを使用して NDV を推定するためのシリアライズされた値です。Puffin ファイルは Iceberg のメタデータの snapshot-id にリンクされており、クエリエンジンの CBO がクエリプランを最適化するために使用します。
Amazon Redshift を通じて Iceberg カラム統計情報を活用する
この機能のパフォーマンス上のメリットを実証するために、業界標準の TPC-DS 3 TB データセットを使用します。Redshift Spectrum と Amazon Athena でクエリを実行し、Iceberg カラム統計情報の有無によるクエリパフォーマンスを比較します。この記事で使用するクエリを含めていますので、ワークフローに従って独自のクエリを試すことをお勧めします。
全体的な手順は以下のとおりです:
- パブリック Amazon S3 バケットから TPS-DS データセットを抽出し、S3 バケットに Iceberg テーブルとして保存する AWS Glue ジョブを実行します。AWS Glue Data Catalog はこれらのテーブルのメタデータの場所を保存します。Amazon Redshift Spectrum と Amazon Athena を使用してこれらのテーブルをクエリします。
- カラム統計情報を生成: AWS Glue Data Catalog の拡張機能を使用して、各テーブルのカラム統計情報を生成します。Theta Sketch を保存する Puffin ファイルが生成されます。
- Amazon Redshift Spectrum と Amazon Athena でクエリ: Amazon Redshift Spectrum と Amazon Athena を使用してデータセットに対してクエリを実行し、カラム統計情報がクエリパフォーマンスに与えるメリットを評価します。
以下の図はアーキテクチャを示しています。
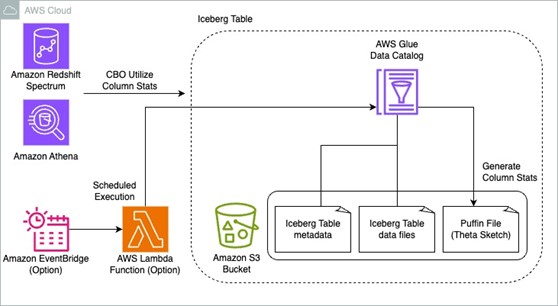
この新機能を試すには、以下の手順を完了します:
- AWS CloudFormation でリソースをセットアップします。
- AWS Glue ジョブを実行して、S3 バケットに 3TB TPC-DS データセットの Iceberg テーブルを作成します。Data Catalog はこれらのテーブルのメタデータの場所を保存します。
- Redshift Spectrum と Amazon Athena でクエリを実行し、クエリ時間を記録します。
- Data Catalog テーブルの Iceberg カラム統計情報を生成します。
- Redshift Spectrum と Amazon Athena でクエリを実行し、前回の実行とクエリ時間を比較します。
- オプションで、AWS Lambda と Amazon EventBridge を使用して AWS Glue カラム統計情報ジョブをスケジュールします。
AWS CloudFormation でリソースをセットアップする
この記事には、クイックセットアップ用の CloudFormation テンプレートが含まれています。必要に応じてレビューしてカスタマイズできます。注意: この CloudFormation テンプレートには、少なくとも 3 つのアベイラビリティーゾーンを持つリージョンが必要です。テンプレートは以下のリソースを生成します:
- 仮想プライベートクラウド (VPC)、パブリックサブネット、プライベートサブネット、ルートテーブル
- Amazon Redshift Serverless ワークグループと名前空間
- TPC-DS データセット、カラム統計情報、ジョブスクリプトなどを保存する S3 バケット
- Data Catalog データベース
- パブリック S3 バケットから TPS-DS データセットを抽出し、S3 バケットに Iceberg テーブルとしてデータを保存する AWS Glue ジョブ
- AWS Identity and Access Management (IAM) ロールとポリシー
- AWS Glue カラム統計情報をスケジュールで実行するための Lambda 関数と EventBridge スケジュール
CloudFormation スタックを起動するには、以下の手順を完了します:
- AWS CloudFormation コンソールにサインインします。
- Launch Stack を選択します。

- Next を選択します。
- パラメータをデフォルトのままにするか、要件に基づいて適切に変更し、Next を選択します。
- 最終ページで詳細を確認し、I acknowledge that AWS CloudFormation might create IAM resources を選択します。
- Create を選択します。
このスタックの完了には約 10 分かかります。完了後、AWS CloudFormation コンソールでデプロイされたスタックを確認できます。
AWS Glue ジョブを実行して 3TB TPC-DS データセットの Iceberg テーブルを作成する
CloudFormation スタックの作成が完了したら、AWS Glue ジョブを実行して TPC-DS データセットの Iceberg テーブルを作成します。この AWS Glue ジョブは、パブリック S3 バケットから TPC-DS データセットを抽出し、データを Iceberg テーブルに変換します。これらのテーブルは S3 バケットにロードされ、Data Catalog に登録されます。
AWS Glue ジョブを実行するには、以下の手順を完了します:
- AWS Glue コンソールで、ナビゲーションペインの ETL jobs を選択します。
InitialDataLoadJob-<your-stack-name>を選択します。- Run を選択します。
この AWS Glue ジョブの完了には約 30 分かかります。ジョブ処理ステータスが Succeeded と表示されたら、プロセスは完了です。

AWS Glue ジョブは、TPC-DS データセットを保存するテーブルを 2 つの同一のデータベース (tpcdsdbnostats と tpcdsdbwithstats) に作成します。tpcdsdbnostats のテーブルには統計情報が生成されず、参照として使用します。tpcdsdbwithstats のテーブルに統計情報を生成します。AWS Glue コンソールでこれら 2 つのデータベースと基盤となるテーブルの作成を確認します。この時点では、これらのデータベースは同じデータを保持しており、テーブルに統計情報は生成されていません。
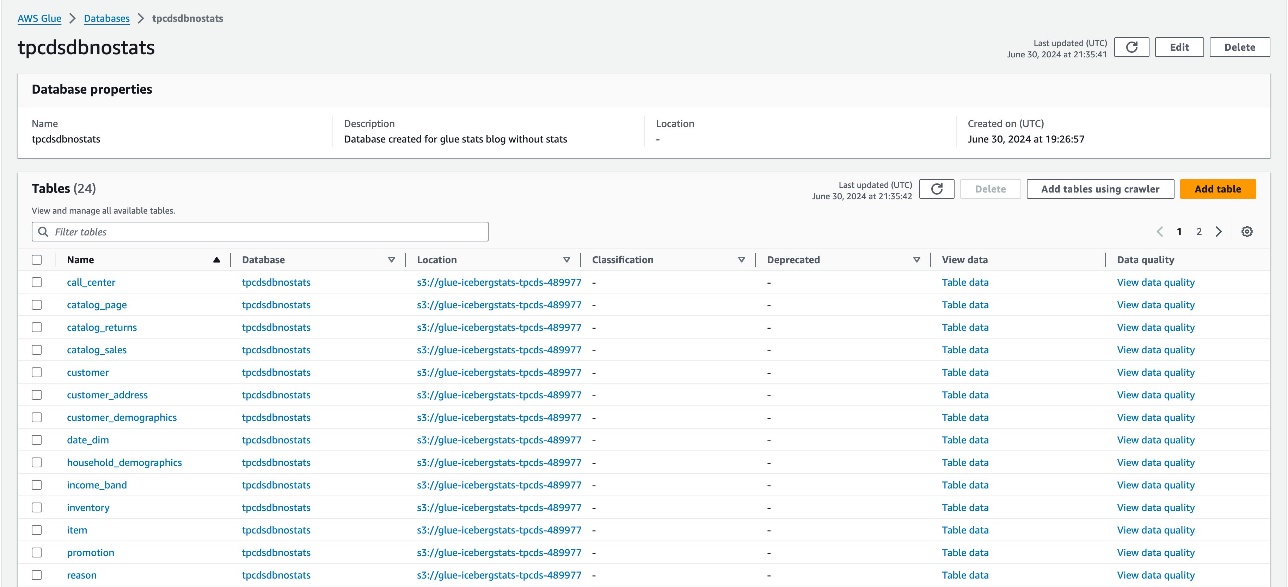
統計情報なしで Redshift Spectrum でクエリを実行する
前の手順で、指定された RPU (デフォルトは 128) で Redshift Serverless ワークグループをセットアップし、S3 バケットに TPC-DS 3TB データセットを準備し、Iceberg テーブル (現時点では統計情報なし) を作成しました。
Amazon Redshift でクエリを実行するには、以下の手順を完了します:
- Amazon Redshift クエリをダウンロードします。
- Redshift クエリエディタ v2 で、ダウンロードしたファイル
redshift-tpcds-sample.sqlの Redshift Query for tables without column statistics セクションに記載されているクエリを実行します。 - 各クエリの実行時間を記録します。
統計情報なしで Amazon Athena でクエリを実行する
Amazon Athena からも TPC-DS テーブル (現時点では統計情報なし) をクエリしてみましょう。Amazon Athena でクエリを実行するには、以下の手順を完了します:
- Amazon Athena クエリをダウンロードします。
- Athena クエリエディタで、ダウンロードしたファイル
athena-tpcds-sample.sqlの Athena Query for tables without column statistics セクションに記載されているクエリを実行します。 - 各クエリの実行時間を記録します。

Iceberg カラム統計情報を生成する
Data Catalog テーブルの統計情報を生成するには、以下の手順を完了します:
- AWS Glue コンソールで、ナビゲーションペインの Data Catalog の下にある Databases を選択します。
tpcdsdbwithstatsデータベースを選択して、利用可能なすべてのテーブルを表示します。- これらのテーブルのいずれか (例:
call_center) を選択します。 - Column statistics – new に移動し、Generate statistics を選択します。
- デフォルトオプションを維持します:
- Choose columns で、Table (All columns) を選択します。
- Row sampling options で、All rows を選択します。
- IAM role で、
AWSGluestats-blog-<your-stack-name>を選択します。
- Generate statistics を選択します。

以下のスクリーンショットに示すように、統計情報生成の実行ステータスを確認できます。

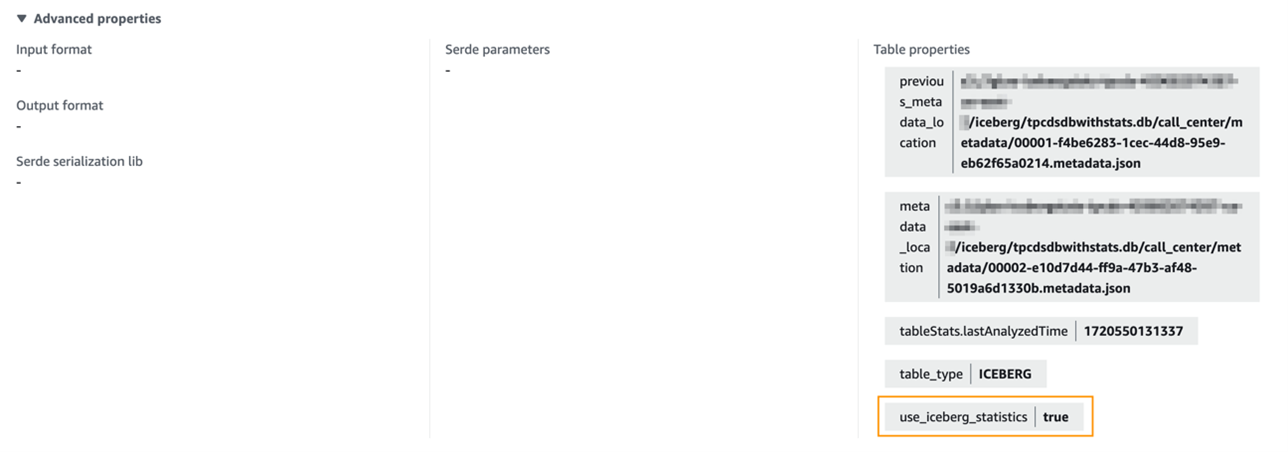
Iceberg テーブルのカラム統計情報を生成した後、そのテーブルの詳細なカラム統計情報を確認できます。

詳細プロパティセクションに、テーブルプロパティ use_iceberg_statistics=true があります。このパラメータは Glue Column Statistics ジョブによって追加されます。Amazon Athena は、これが true に設定されている場合にのみカラム統計情報を利用しようとします。一方、Amazon Redshift は、このパラメータに関係なく、統計情報が利用可能であればデフォルトで利用します。
統計情報の生成後、Amazon S3 の AWS Glue テーブルの基盤となるデータの場所に <id>.stat ファイルがあります。このファイルは Theta Sketch データ構造を保存する Puffin ファイルです。クエリエンジンはこの Theta Sketch アルゴリズムを使用して、テーブルを操作する際に NDV を効率的に推定でき、クエリパフォーマンスの最適化に役立ちます。
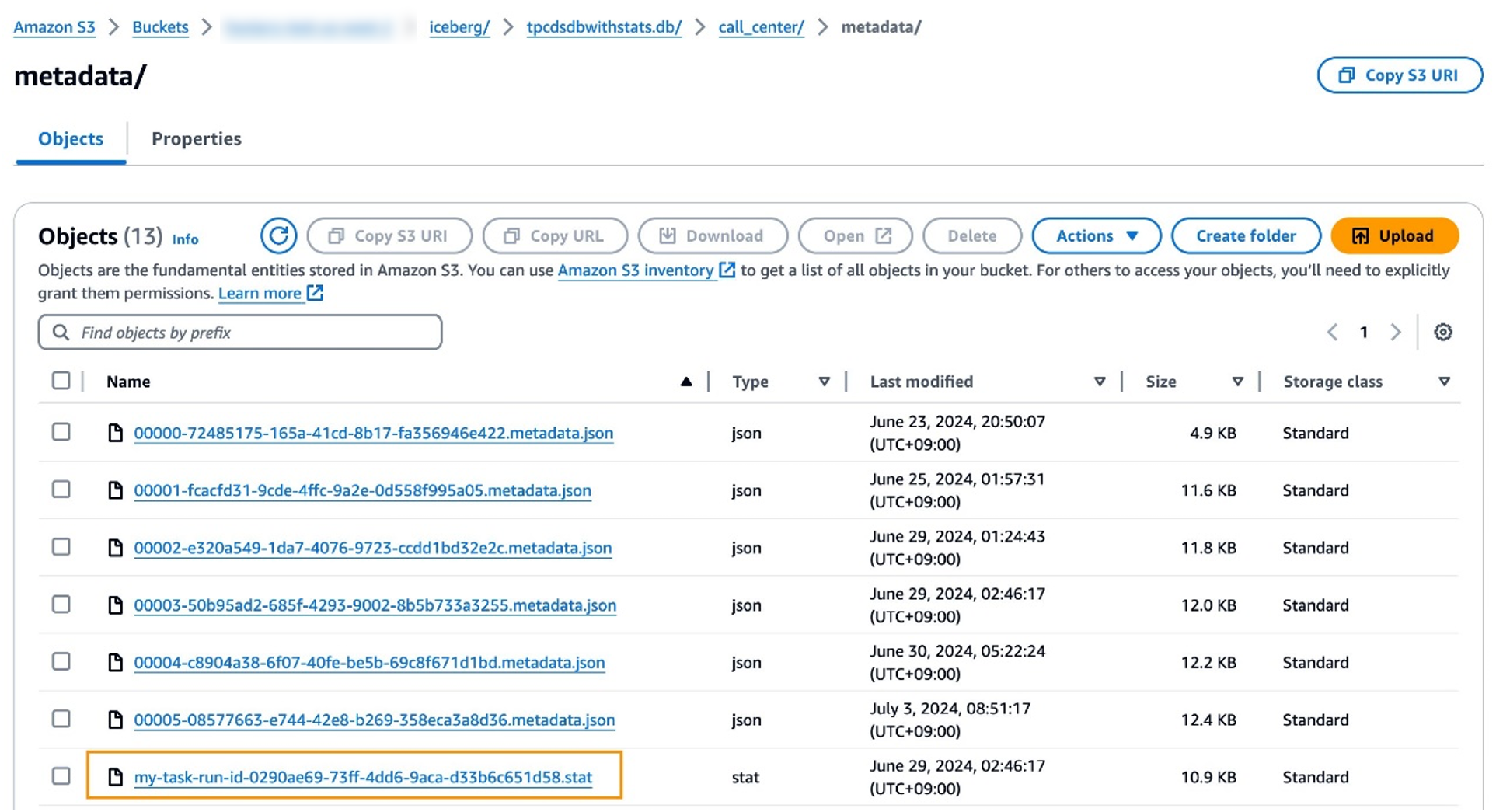
前の手順を繰り返して、catalog_sales、catalog_returns、warehouse、item、date_dim、store_sales、customer、customer_address、web_sales、time_dim、ship_mode、web_site、web_returns などのすべてのテーブルの統計情報を生成します。または、AWS Glue にすべてのテーブルのカラム統計情報を生成するよう指示する Lambda 関数を手動で実行することもできます。この関数の詳細については、この記事の後半で説明します。
すべてのテーブルの統計情報を生成した後、各クエリのクエリパフォーマンスを評価できます。
統計情報ありで Redshift Spectrum でクエリを実行する
前の手順で、指定された RPU (デフォルトは 128) で Redshift Serverless ワークグループをセットアップし、S3 バケットに TPC-DS 3TB データセットを準備し、カラム統計情報付きの Iceberg テーブルを作成しました。
統計情報テーブルで Redshift Spectrum を使用して提供されたクエリを実行するには、以下の手順を完了します:
- Redshift クエリエディタ v2 で、ダウンロードしたファイル
redshift-tpcds-sample.sqlの Redshift Query for tables with column statistics セクションに記載されているクエリを実行します。 - 各クエリの実行時間を記録します。
Redshift Serverless 128 RPU と TPC-DS 3TB データセットを使用して、NDV 情報が有益であると予想される 10 個の選択された TPC-DS クエリのサンプル実行を行いました。各クエリを 10 回実行しました。以下の表に示す結果は、カラム統計情報を使用したクエリのパフォーマンス改善率でソートされています。
| TPC-DS 3T クエリ | カラム統計情報なし | カラム統計情報あり | パフォーマンス改善率 (%) |
| Query 16 | 305.0284 | 51.7807 | 83.0 |
| Query 75 | 398.0643 | 110.8366 | 72.2 |
| Query 78 | 169.8358 | 52.8951 | 68.9 |
| Query 95 | 35.2996 | 11.1047 | 68.5 |
| Query 94 | 160.52 | 57.0321 | 64.5 |
| Query 68 | 14.6517 | 7.4745 | 49.0 |
| Query 4 | 217.8954 | 121.996 | 44.0 |
| Query 72 | 123.8698 | 76.215 | 38.5 |
| Query 29 | 22.0769 | 14.8697 | 32.6 |
| Query 25 | 43.2164 | 32.8602 | 24.0 |

結果は 24.0〜83.0% の明確なパフォーマンス改善を示しました。
詳しく見るために、最も高いパフォーマンス改善を示した Query 16 を調べてみましょう:
TPC-DS Query 16:
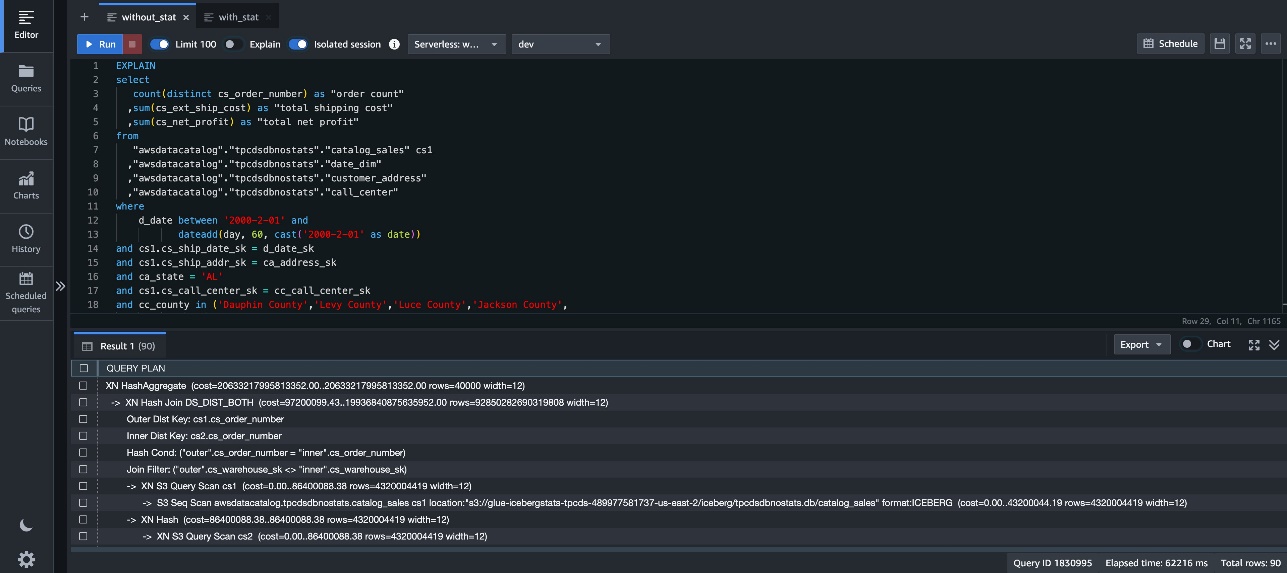
ANALYZE クエリを使用して、カラム統計情報の有無によるクエリプランの違いを比較できます。
以下のスクリーンショットは、カラム統計情報なしの結果を示しています。
以下のスクリーンショットは、カラム統計情報ありの結果を示しています。

カラム統計情報を使用した結果、いくつかの顕著な違いが観察できます。高レベルでは、クエリの全体的な推定コストが 20633217995813352.00 から 331727324110.36 に大幅に削減されています。
2 つのクエリプランは異なる結合戦略を選択しました。
以下は、カラム統計情報なしのクエリプランに含まれる 1 行です:
以下は、カラム統計情報ありのクエリプランの対応する行です:
カラム統計情報なしのテーブルのクエリプランは、大きなテーブルを結合する際に DS_DIST_BOTH を使用しましたが、カラム統計情報ありのテーブルのクエリプランは DS_BCAST_INNER を選択しました。結合順序もカラム統計情報に基づいて変更されています。これらの結合戦略と結合順序の変更は、主にカラム統計情報によって可能になったより正確な結合カーディナリティの推定によって駆動され、より最適化されたクエリプランにつながります。
統計情報ありで Amazon Athena でクエリを実行する
Iceberg の統計情報が Amazon Athena のパフォーマンスにどのように影響するかも調べてみましょう。
統計情報テーブルで Amazon Athena を使用して提供されたクエリを実行するには、以下の手順を完了します:
- Athena クエリエディタで、ダウンロードしたファイル
athena-tpcds-sample.sqlの Athena Query for tables with column statistics セクションに記載されているクエリを実行します。 - 各クエリの実行時間を記録します。
Amazon Athena と TPC-DS 3TB データセットを使用して、NDV 情報が有益であると予想される 10 個の選択された TPC-DS クエリのサンプル実行を行いました。各クエリを 10 回実行しました。以下の表に示す結果は、カラム統計情報を使用したクエリのパフォーマンス改善率でソートされています。
| TPC-DS 3T クエリ | カラム統計情報なし | カラム統計情報あり | パフォーマンス改善率 (%) |
| Query 70 | 65.831 | 22.075 | 66.47 |
| Query 95 | 24.231 | 8.334 | 65.56 |
| Query 36 | 41.497 | 17.073 | 58.86 |
| Query 94 | 17.787 | 6.122 | 58.6 |
| Query 35 | 44.749 | 19.05 | 57.43 |
| Query 16 | 18.609 | 8.696 | 53.27 |
| Query 18 | 10.487 | 5.965 | 43.12 |
| Query 2 | 32.823 | 18.788 | 42.76 |
| Query 59 | 39.496 | 24.15 | 38.85 |
| Query 11 | 58.844 | 39.224 | 33.34 |
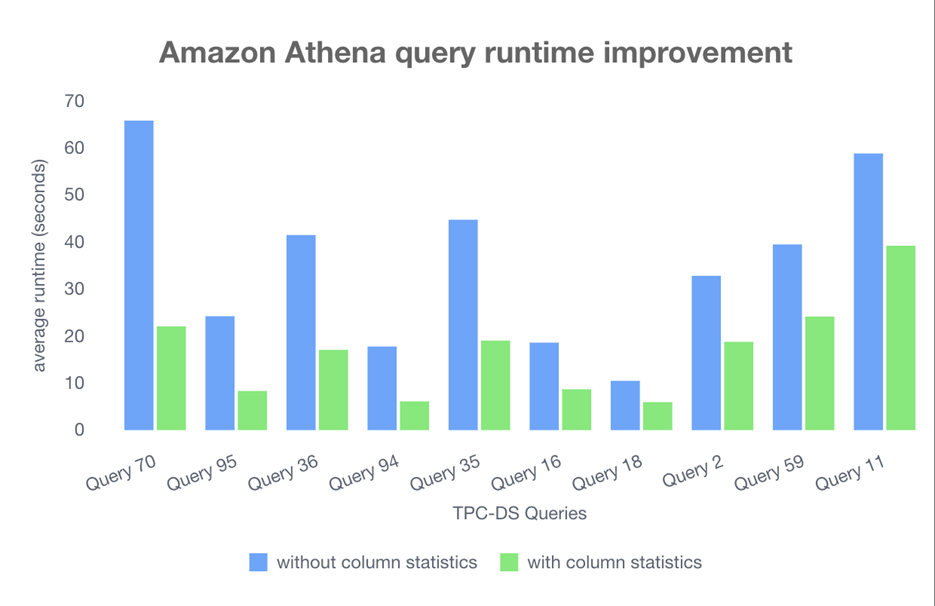
結果は 33.34〜66.47% の明確なパフォーマンス改善を示しました。
詳しく見るために、最も高いパフォーマンス改善を示した Query 70 を調べてみましょう:
TPC-DS Query 70:
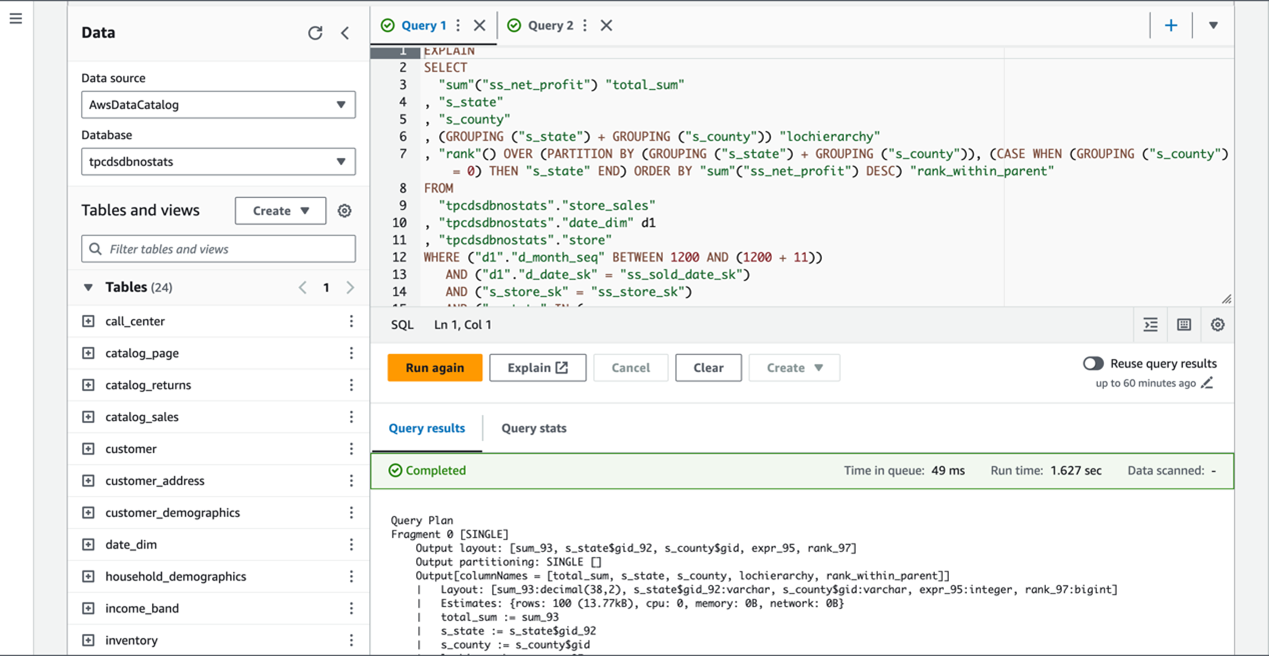
EXPLAIN クエリを使用して、カラム統計情報の有無によるクエリプランの違いを比較できます。
以下のスクリーンショットは、カラム統計情報なしの結果を示しています。
以下のスクリーンショットは、カラム統計情報ありの結果を示しています。
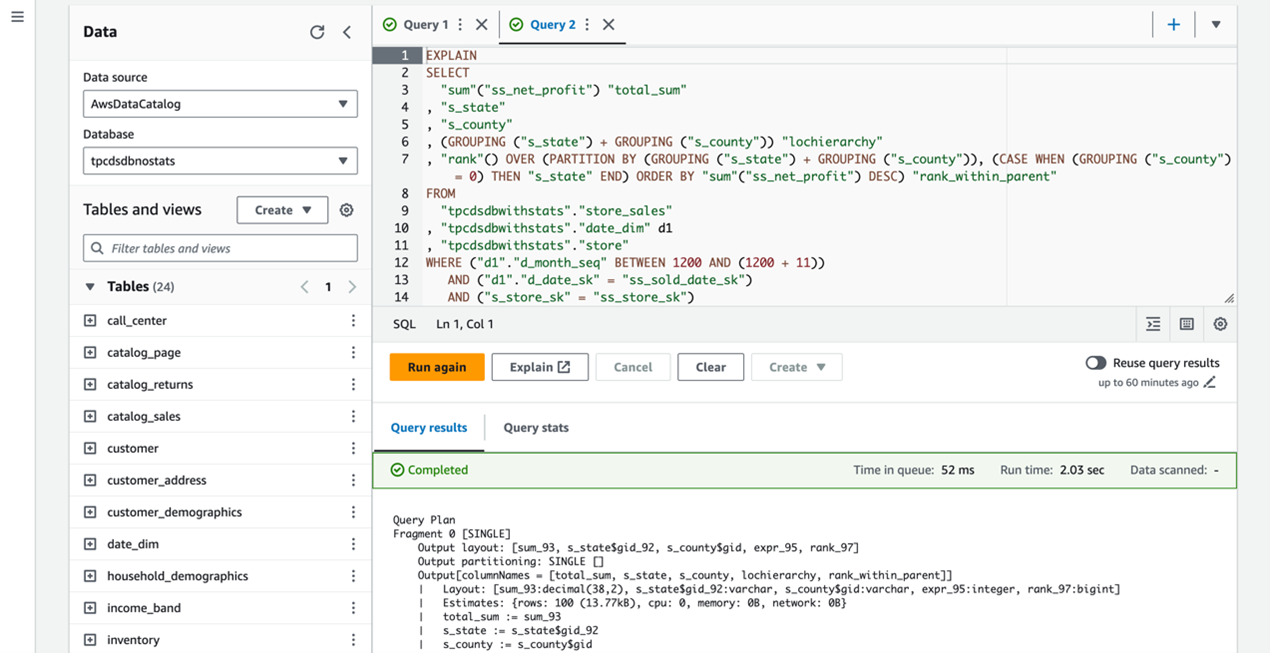
カラム統計情報の使用により、いくつかの重要な違いが明らかになります。
統計情報なしでは、スキャンするレコード数や CPU コストの多くの推定値が「?」ですが、統計情報ありでは具体的な数値が提供されます。
以下は、カラム統計情報なしのクエリプランに含まれる行です:
以下は、カラム統計情報ありのクエリプランの行です:
CBO はこれらの具体的な推定値を持つことで、より効率的なプランを生成できます。
例えば、2 つのクエリプランは異なる結合戦略を選択しました。
以下は、カラム統計情報なしのクエリプランに含まれる 1 行です:
以下は、カラム統計情報ありのクエリプランの対応する行です:
統計情報なしでは、オプティマイザは PARTITIONED 分散を選択し、ノード間で大量のデータ移動が必要になります。統計情報ありでは、適切な場合に REPLICATED 分散を選択し、小さなテーブルをすべてのノードにブロードキャストできます。これにより、ネットワークトラフィックが削減され、並列処理の効率が向上します。
AWS Glue カラム統計情報の実行をスケジュールする
最適なクエリパフォーマンスを維持するには、カラム統計情報を最新の状態に保つことが重要です。このセクションでは、Lambda と EventBridge Scheduler を使用して Iceberg テーブルのカラム統計情報の生成を自動化する方法を説明します。この自動化により、手動介入なしでカラム統計情報を最新の状態に保つことができます。
必要な Lambda 関数と EventBridge スケジュールは、CloudFormation テンプレートを通じてすでに作成されています。Lambda 関数は AWS Glue カラム統計情報の実行を呼び出すために使用されます。まず、以下の手順を完了して、Lambda 関数がどのように設定されているかを確認します:
- Lambda コンソールで、ナビゲーションペインの Functions を選択します。
- 関数
GlueTableStatisticsFunctionv1を開きます。
Lambda 関数をより明確に理解するために、Code セクションのコードを確認し、Configuration の環境変数を調べることをお勧めします。
以下のコードスニペットに示すように、Lambda 関数は AWS SDK for Python (Boto3) ライブラリを通じて start_column_statistics_task_run API を呼び出します。

次に、以下の手順を完了して、EventBridge スケジュールがどのように設定されているかを確認します:
- EventBridge コンソールで、ナビゲーションペインの Scheduler の下にある Schedules を選択します。
- CloudFormation コンソールで作成されたスケジュールを見つけます。
このページでは、イベントのスケジュールを管理および設定します。以下のスクリーンショットに示すように、スケジュールは毎日特定の時刻 (この場合は UTC 午後 8:27) に Lambda 関数を呼び出すように設定されています。これにより、AWS Glue カラム統計情報が定期的かつ予測可能に実行されます。

クリーンアップ
上記のすべての手順を完了したら、AWS CloudFormation を使用して作成したすべての AWS リソースをクリーンアップすることを忘れないでください:
- CloudFormation スタックを削除します。
- TPC-DS データセットの Iceberg テーブルと AWS Glue ジョブスクリプトを保存している S3 バケットを削除します。
まとめ
この記事では、Iceberg テーブルのカラムレベル統計情報を作成できる Data Catalog の新機能を紹介しました。Iceberg テーブルは、Puffin ファイルに NDV を効率的に推定するために使用できる Theta Sketch を保存します。Redshift Spectrum の CBO はこれを使用してクエリプランを最適化し、クエリパフォーマンスの向上とコスト削減につながります。
Data Catalog のこの新機能を試して、カラムレベル統計情報を生成し、クエリパフォーマンスを向上させてください。コメントセクションでフィードバックをお聞かせください。詳細については、AWS Glue Catalog ドキュメントをご覧ください。
著者について
 Sotaro Hikita ソリューションアーキテクトとして、幅広い業界、特に金融業界のお客様がより良いソリューションを構築できるよう支援しています。特にビッグデータ技術とオープンソースソフトウェアに情熱を持っています。
Sotaro Hikita ソリューションアーキテクトとして、幅広い業界、特に金融業界のお客様がより良いソリューションを構築できるよう支援しています。特にビッグデータ技術とオープンソースソフトウェアに情熱を持っています。
 Noritaka Sekiyama AWS Glue チームのプリンシパルビッグデータアーキテクトです。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇には新しいロードバイクでサイクリングを楽しんでいます。
Noritaka Sekiyama AWS Glue チームのプリンシパルビッグデータアーキテクトです。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇には新しいロードバイクでサイクリングを楽しんでいます。
 Kyle Duong AWS Glue および AWS Lake Formation チームのシニアソフトウェア開発エンジニアです。ビッグデータ技術と分散システムの構築に情熱を持っています。
Kyle Duong AWS Glue および AWS Lake Formation チームのシニアソフトウェア開発エンジニアです。ビッグデータ技術と分散システムの構築に情熱を持っています。
 Kalaiselvi Kamaraj Amazon のシニアソフトウェア開発エンジニアです。Amazon Redshift クエリ処理チーム内のいくつかのプロジェクトに携わり、現在は Redshift データレイクのパフォーマンス関連プロジェクトに注力しています。
Kalaiselvi Kamaraj Amazon のシニアソフトウェア開発エンジニアです。Amazon Redshift クエリ処理チーム内のいくつかのプロジェクトに携わり、現在は Redshift データレイクのパフォーマンス関連プロジェクトに注力しています。
 Sandeep Adwankar AWS のシニアプロダクトマネージャーです。カリフォルニアのベイエリアを拠点に、世界中のお客様と協力して、ビジネスおよび技術要件を、お客様がデータの管理、セキュリティ、アクセス方法を改善できる製品に変換しています。
Sandeep Adwankar AWS のシニアプロダクトマネージャーです。カリフォルニアのベイエリアを拠点に、世界中のお客様と協力して、ビジネスおよび技術要件を、お客様がデータの管理、セキュリティ、アクセス方法を改善できる製品に変換しています。
この記事は Kiro が翻訳を担当し、Solutions Architect の Sotaro Hikita がレビューしました。