Amazon Web Services ブログ
エンタープライズにおける AI エージェント: Amazon Bedrock AgentCore を活用したベストプラクティス
本記事は 2026 年 2 月 3 日 に公開された「AI agents in enterprises: Best practices with Amazon Bedrock AgentCore」を翻訳したものです。
本番環境で使える AI エージェントを構築するには、開発ライフサイクル全体を通じた綿密な計画と実行が欠かせません。デモで印象的なプロトタイプと、本番環境で価値を提供するエージェントの差は、規律あるエンジニアリングプラクティス、堅牢なアーキテクチャ、そして継続的な改善によって生まれます。
本記事では、Amazon Bedrock AgentCore を活用してエンタープライズ向け AI エージェントを構築するための 9 つのベストプラクティスを紹介します。Amazon Bedrock AgentCore は、AI エージェントの作成、デプロイ、管理を大規模に行うために必要なサービスを提供するエージェンティックプラットフォームです。初期のスコーピングから組織全体へのスケーリングまで、すぐに実践できるガイダンスを幅広くカバーしています。
小さく始めて、成功を明確に定義する
最初に答えるべき問いは「このエージェントに何ができるか?」ではなく、「私たちはどんな課題を解決しようとしているのか?」です。多くのチームが、あらゆるシナリオに対応しようとするエージェントの構築から着手してしまいます。これは複雑さ、遅いイテレーション、そして中途半端なエージェントに繋がります。
その代わりに、ユースケースから逆算して取り組みましょう。財務アシスタントを構築するなら、アナリストが最もよく行う 3 つのタスクから始めます。HR ヘルパーを構築するなら、従業員から寄せられる質問の上位 5 つに絞ります。まずはそれらを確実に動かしてから、スコープを広げていきます。
初期の計画段階では、次の 4 つの項目を明確にしておく必要があります:
- エージェントが「やるべきこと」と「やるべきでないこと」の明確な定義。必ず文書化し、ステークホルダーと共有してください。機能の肥大化に対して「ノー」と言うための拠り所になります。
- エージェントのトーンとパーソナリティ。フォーマルにするか会話調にするか、ユーザーにどのように挨拶するか、スコープ外の質問に遭遇した場合にどうするかを決定します。
- すべてのツール、パラメータ、ナレッジソースの明確な定義。それらの説明が曖昧だと、エージェントが誤ったツールを選択する原因になります。
- 一般的なクエリとエッジケースの両方を網羅した、期待されるインタラクションの Ground truth データセット。
| エージェントの定義 | エージェントのトーンとパーソナリティ | ツールの定義 | Ground truth データセット |
|
財務分析エージェント: アナリストが四半期の収益データを取得し、成長指標を計算し、特定のリージョン (EMEA、APAC、AMER) のエグゼクティブサマリーを生成する作業を支援する。 投資アドバイスの提供、取引の実行、従業員の報酬データへのアクセスは行わない。 |
|
|
50 件のクエリ (例):
|
|
HR ポリシーアシスタント: 休暇ポリシー、休暇申請、福利厚生、社内ポリシーに関する従業員の質問に回答する。 機密の人事ファイルへのアクセス、法的アドバイスの提供、個人の報酬やパフォーマンスレビューに関する対応は行わない。 |
|
|
45 件のクエリ (例):
|
|
IT サポートエージェント: パスワードリセット、ソフトウェアのアクセス申請、VPN のトラブルシューティング、一般的な技術的問題について従業員を支援する。 本番システムへのアクセス、セキュリティ権限の直接変更、インフラの変更は行わない。 |
|
|
40 件のクエリ (例):
|
このような限定したスコープで概念実証 (PoC) を構築し、実際のユーザーに試してもらいます。想定していなかった問題がすぐに見つかるはずです。例えば、エージェントが日付の解析をうまくできない、略語を正しく処理できない、想定外の言い回しで質問されると誤ったツールを呼び出してしまう、といった問題です。PoC でこれに気づけばコストは数週間で済みますが、本番環境でこれに気づくと、失うコストは信頼性とユーザーの信用です。
初日からすべてを計装する
オブザーバビリティに関してチームが陥りがちな過ちの一つは、「後から追加すればいい」と考えることです。必要性に気づいた頃にはすでにエージェントをリリースしており、効果的なデバッグが難しくなっている可能性があります。
最初のテストクエリの時点から、エージェントの挙動を可視化しておく必要があります。AgentCore のサービス群は OpenTelemetry トレースを自動的に出力します。モデルの呼び出し、ツールの呼び出し、推論のステップがキャプチャされます。あるクエリに 12 秒かかった場合、その遅延が言語モデル、データベースクエリ、外部 API 呼び出しのどこに起因するのかを特定できます。
オブザーバビリティ戦略には、次の 3 つのレイヤーを含めるべきです:
- 開発中はトレースレベルのデバッグを有効にし、会話の各ステップを追跡できるようにする。ユーザーがエージェントの想定外の動作を報告した場合、該当するトレースを取得してエージェントの動作を正確に把握できます。
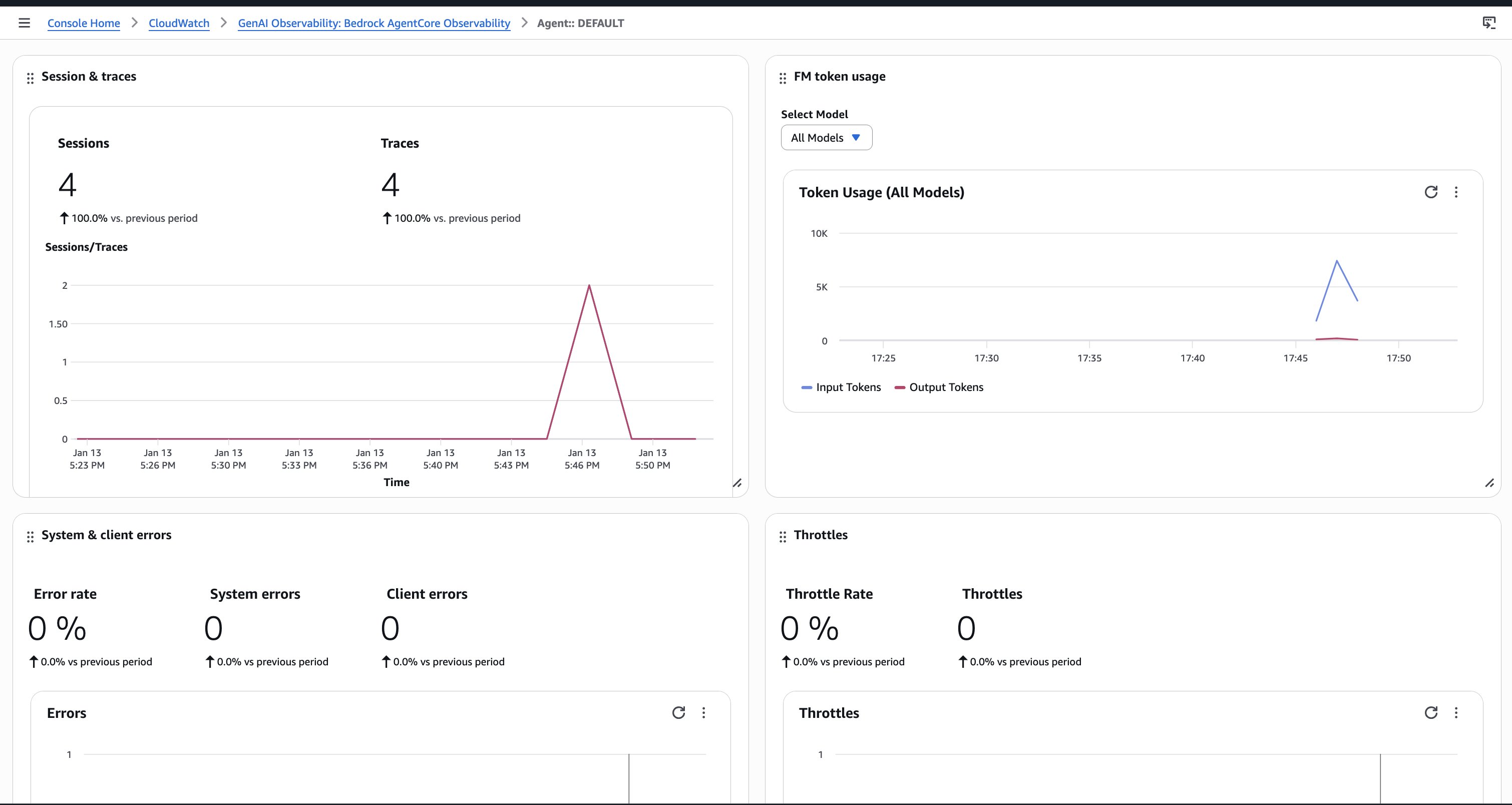
- AgentCore Observability に付属する Amazon CloudWatch の生成 AI オブザーバビリティダッシュボードを活用し、本番モニタリング用のダッシュボードを構築する。
- トークン使用量、レイテンシーのパーセンタイル値、エラー率、ツール呼び出しパターンを追跡する。組織で Datadog、Dynatrace、LangSmith、Langfuse などを利用している場合は、既存のオブザーバビリティ基盤にそれらのデータをエクスポートする。
次の図は、AgentCore Observability がどのようにセッション内で実行のエージェントのトレースやメタデータを詳細に確認できるかを示しています:
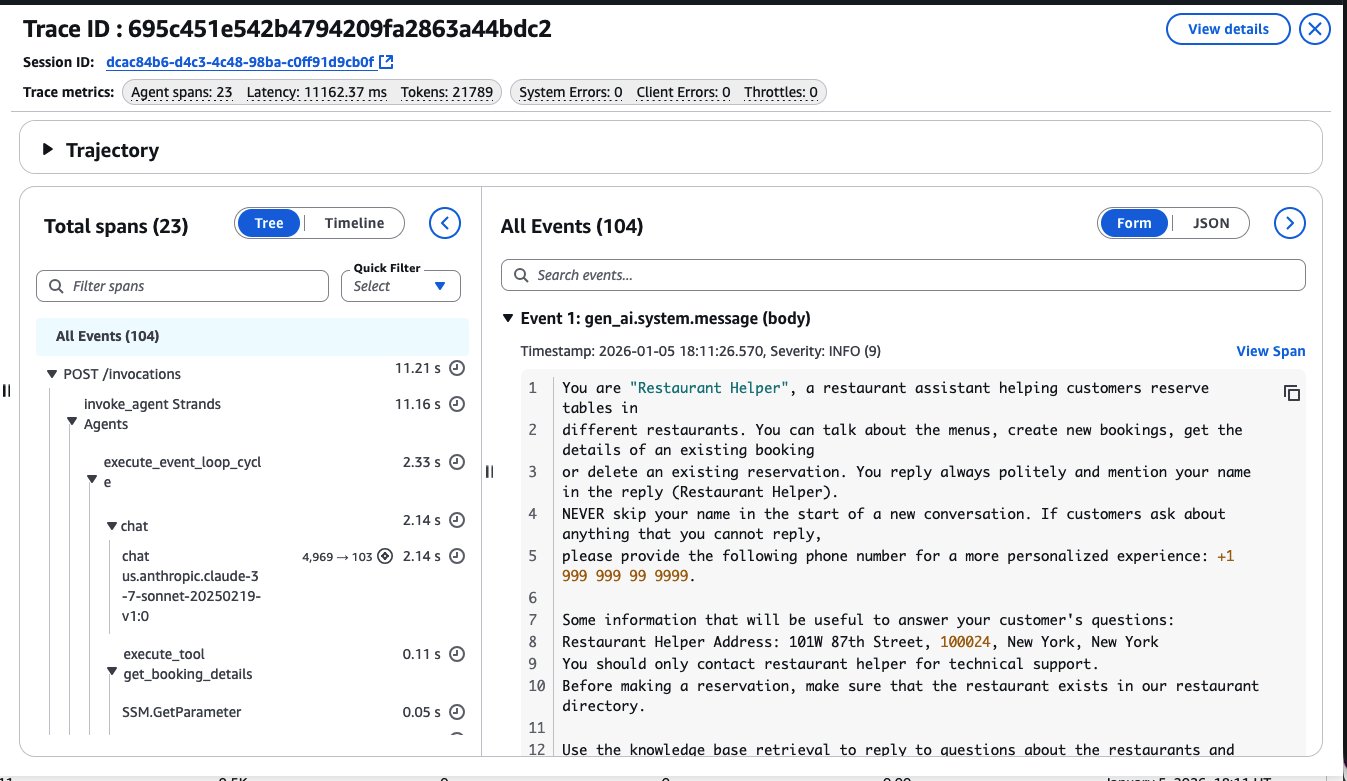
オブザーバビリティは、役割によって異なるニーズに応えます。開発者にとってはデバッグのための手段です。エージェントがなぜハルシネーションを起こしたのか、どのプロンプトバージョンの性能が優れているのか、レイテンシーのボトルネックはどこにあるのか、といった疑問に答えるために必要です。プラットフォームチームにとってはガバナンスの手段です。各チームがどれだけ支出しているか、どのエージェントがコスト増加を引き起こしているか、特定のインシデントで何が起きたのかを把握する必要があります。原則は単純で測定できないものは改善できません。必要になる前に、測定のためのインフラを整えておきます。
計画的なツール戦略を構築する
ツールは、エージェントが現実世界にアクセスするための手段です。データベースからデータを取得し、外部 API を呼び出し、ドキュメントを検索し、ビジネスロジックを実行します。ツール定義の品質は、エージェントの性能に直結します。
ツールを定義する際は、簡潔さよりも明確さを優先してください。同一の関数に対する 2 つの記述を比較してみます:
- 悪い例:
「収益データを取得する」 - 良い例:
「指定されたリージョンと期間の四半期収益データを取得する。値は百万ドル単位で返される。リージョンコード (EMEA、APAC、AMER) と YYYY-QN 形式の四半期 (例: 2024-Q3) が必要である。」
1 番目の記述では、エージェントはどんな入力が有効で、出力をどう解釈すべきかを推測するしかありません。2 番目の記述は曖昧さを排除しています。これが 20 個のツールに及ぶと、その差は歴然です。ツール戦略では、次の 4 つの領域に取り組む必要があります:
- エラー処理とレジリエンス: ツールは失敗します。API はエラーを返し、タイムアウトも発生します。障害モードごとにリトライすべきか、キャッシュデータにフォールバックすべきか、サービス停止中であることをユーザーに伝えるべきかの期待される動作を定義します。これらをツール定義と合わせて記述します。
- Model Context Protocol (MCP) の再利用: Slack、Google Drive、Salesforce、GitHub など、多くのサービスプロバイダーがすでに MCP サーバーを提供しています。独自の統合を一から構築する代わりに、これらを活用します。社内 API については、AgentCore Gateway を通じて MCP ツールとしてラップすることで、すべてのツールを統一プロトコルで扱え、異なるエージェントから検出可能になります。
- 一元管理されたツールカタログ: 同一データベースコネクタを複数のチームがそれぞれ構築するべきではありません。セキュリティチームがレビュー済みで、本番環境でテスト済みの承認済みツールカタログを整備します。新しいチームが機能を必要とする場合は、まずカタログを確認するところから始めます。
- すべてのツールでのコード例: ドキュメントのみでは不十分です。開発者がコピーしてすぐに使える動作するコードサンプルで、各ツールの統合方法を示します。
次の表は、効果的なツールドキュメントに含める要素を示しています:
| 要素 | 目的 | 例 |
| 明確な関数名 | ツールの機能を端的に表す | getQuarterlyRevenue not
getData |
| 明示的なパラメータ | 入力に関する曖昧さを排除する | region: string (EMEA|APAC|AMER), quarter: string (YYYY-QN) |
| 戻り値の形式 | 出力の構造を明示する | Returns: {revenue: number, currency: “USD”, period: string} |
| エラー条件 | 障害モードを記述する | 該当する四半期が見つからない場合は 404、サービス停止時は 503 を返す |
| 使用ガイダンス | どのような場面で使うかを説明する | ユーザーが収益、売上、財務パフォーマンスを質問した場合に使用する |
こうしたドキュメント標準化は、複数のソースやタイプのツールを管理する場面でさらに重要になります。次の図は、AgentCore Gateway が異なるオリジンのツールに対して統一されたインターフェイスを提供する仕組みを示しています。例えば Gateway インスタンス (データ取得・分析関数用)、AWS Lambda (レポート機能用)、Amazon API Gateway (プロジェクト管理などの社内サービス用) のいずれを通じて公開されていても、統一されたインターフェイスを提供します。この例では簡略化のために単一のゲートウェイを示していますが、実際には多くのチームが明確な境界とオーナーシップを維持するために複数の Gateway インスタンス (エージェントごと、または関連するエージェント群ごとに 1 つ) をデプロイしています。このモジュール型のアプローチにより、各チームは独自のツール群を管理しつつ、組織全体で一貫した認証、検出、統合パターンの恩恵を受けられます。
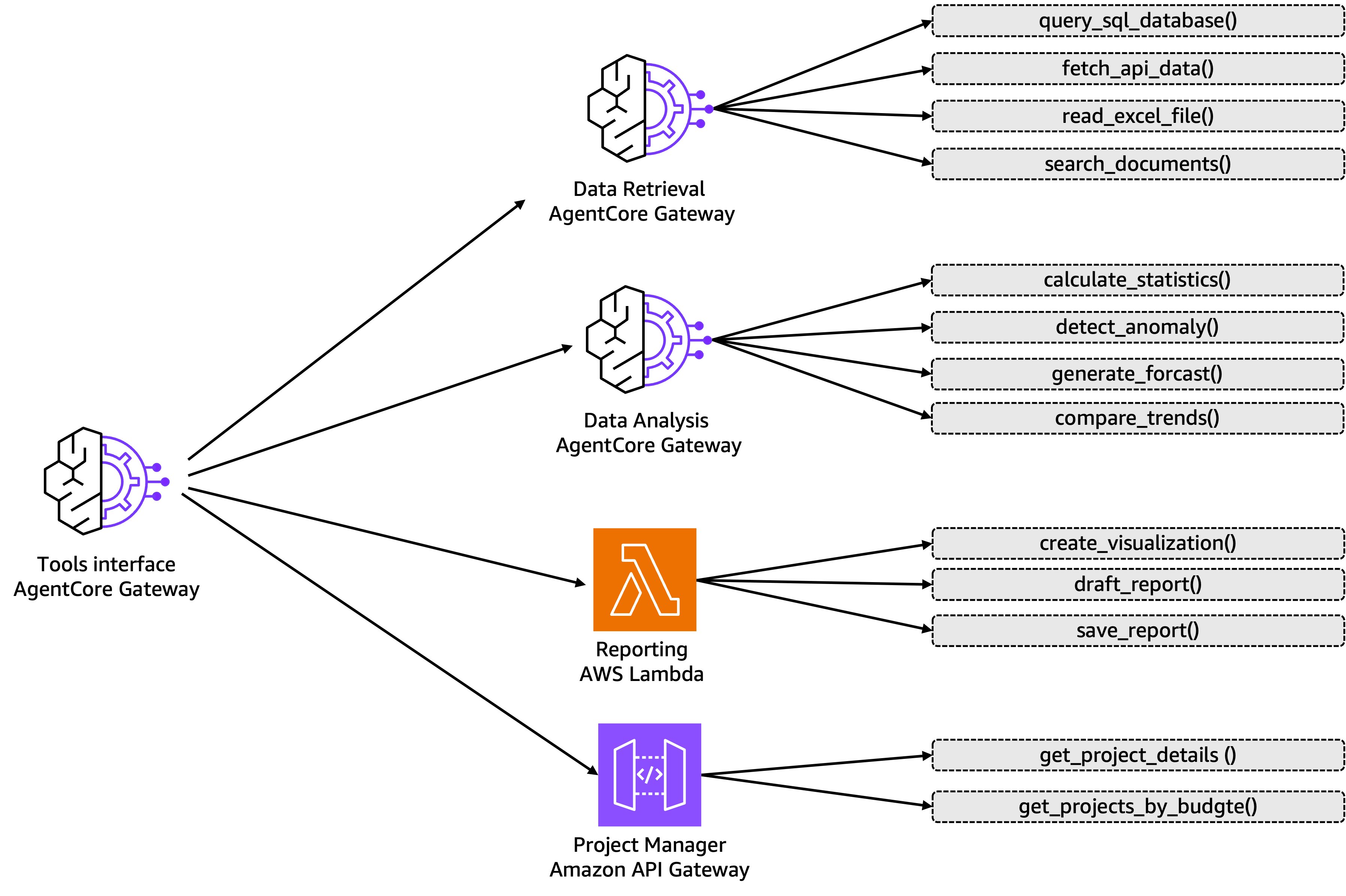
AgentCore Gateway は、ツールの乱立という現実的な課題の解決に役立ちます。組織全体でエージェントの構築が進むにつれ、MCP サーバー経由、Amazon API Gateway 経由、Lambda 関数として公開されたものなど、数十のツールが急速に蓄積されていきます。AgentCore Gateway がなければ、各エージェントチームは認証を個別に実装し、エンドポイントをそれぞれ管理し、実際に使うのはごく一部であっても全ツール定義をプロンプトに読み込むことになります。AgentCore Gateway は、ツールの所在に関係なく統一されたエントリポイントを提供します。既存の MCP サーバーや API Gateway を登録すれば、エージェントは単一のインターフェイスからそれらを検出できます。ツールの数が 20 から 30 に増えてくると、セマンティック検索機能が重要になります。セマンティック検索機能によって、エージェントは、すべてをコンテキストに読み込むのではなく、達成しようとしていることに基づいて適切なツールを発見できます。さらに、双方向の包括的な認証処理も一元化されます。どのエージェントがどのツールにアクセスできるかの検証と、サードパーティーサービスの認証情報の管理です。これこそが、一元管理されたツールカタログを大規模に実用化するためのインフラです。
最初から評価を自動化する
変更を加えるたびに、エージェントが良くなっているのか悪くなっているのかを把握する必要があります。自動化された評価がこのフィードバックループを実現します。まずは、対象のユースケースにおいて「良い」とは何かを定義するところから始めます。評価指標は業界やタスクによって異なります:
- カスタマーサービスエージェントであれば、解決率と顧客満足度が指標になり得る。
- 財務アナリストエージェントであれば、計算精度と引用の質が指標になり得る。
- HR アシスタントであれば、ポリシーの正確性と回答の網羅性が指標になり得る。
技術的な指標とビジネス指標のバランスを取ります。レスポンスのレイテンシーは重要ですが、それはレスポンスが正しい場合に限ります。トークンコストも重要ですが、それはユーザーがエージェントに価値を感じている場合に限ります。両方の指標を定義し、合わせて追跡します。評価データセットは丁寧に構築してください。次のようなデータを含めます:
- 同一質問の複数の表現。ユーザーは API ドキュメントのような話し方はしないため。
- エージェントが回答を拒否するか、人間にエスカレーションすべきエッジケース。
- 複数の解釈が成り立つ曖昧なクエリ。
先ほどの財務分析エージェントの例で考えてみましょう。評価データセットには「EMEA の Q3 の収益は?」のようなクエリと、期待される回答および正しいツール呼び出しを含めます。ただし、「前四半期のヨーロッパの売上はいくら?」「EMEA の Q3 の数字は?」「7 月から 9 月のヨーロッパの収益を見せて」といったバリエーションも必要です。どの表現でも、同一パラメータで同一ツールが呼び出されるべきです。評価指標の例を挙げます:
- ツール選択精度:
getMarketDataではなくgetQuarterlyRevenueを正しく選択できたか? 目標: 95% - パラメータ抽出精度:
EMEAとQ3 2024を正しい形式にマッピングできたか? 目標: 98% - 拒否精度:
CEO のボーナスはいくら?のような質問を適切に拒否できたか? 目標: 100% - レスポンス品質: 専門用語を使わずにデータをわかりやすく説明できたか? LLM-as-Judge で評価。
- レイテンシー: P50 が 2 秒未満、P95 が 5 秒未満。
- クエリあたりのコスト: 平均トークン使用量が 5,000 トークン未満。
この評価を Ground truth データセットに対して実行します。最初の変更前のベースラインでは、ツール選択精度 92%、P50 レイテンシー 3.2 秒といった結果が出るかもしれません。Amazon Bedrock 上で Claude 4.5 Sonnet から Claude 4.5 Haiku に切り替えた後に評価を再実行すると、ツール選択精度が 87% に低下した一方、レイテンシーは 1.8 秒に改善された、という結果になるかもしれません。こうしてトレードオフを定量化することで、速度の向上が精度の低下に見合うかどうかを判断できます。
評価ワークフローは開発プロセスの一部に組み込むべきです。例えば、プロンプトの変更時点、ツールの追加時点、モデルを切り替え時点などで評価を実行します。フィードバックループは、問題が発生した時点ですぐに検知できるだけの速さが必要です。
マルチエージェントシステムで複雑さを分解する
単一のエージェントにあまりにも多くの責務を持たせると、メンテナンスが困難になります。プロンプトは複雑化し、ツール選択のロジックは破綻し、性能は低下します。解決策は、課題を複数の専門エージェントに分解し、それらを協調させることです。チーム編成に置き換えて考えてみてください。営業、エンジニアリング、サポート、財務をすべて 1 人に任せることはありません。それぞれの専門家を配置し、協調させます。エージェントにも同様の原則が当てはまります。次の図で示すように、30 種類のタスクを 1 つのエージェントに処理させるのではなく、関連する 10 タスクずつを担当する 3 つのエージェントを構築します。各エージェントはより明確な指示、よりシンプルなツールセット、より焦点の絞られたロジックを持つことになります。複雑さが分離されれば、問題のデバッグと修正は格段に容易になります。
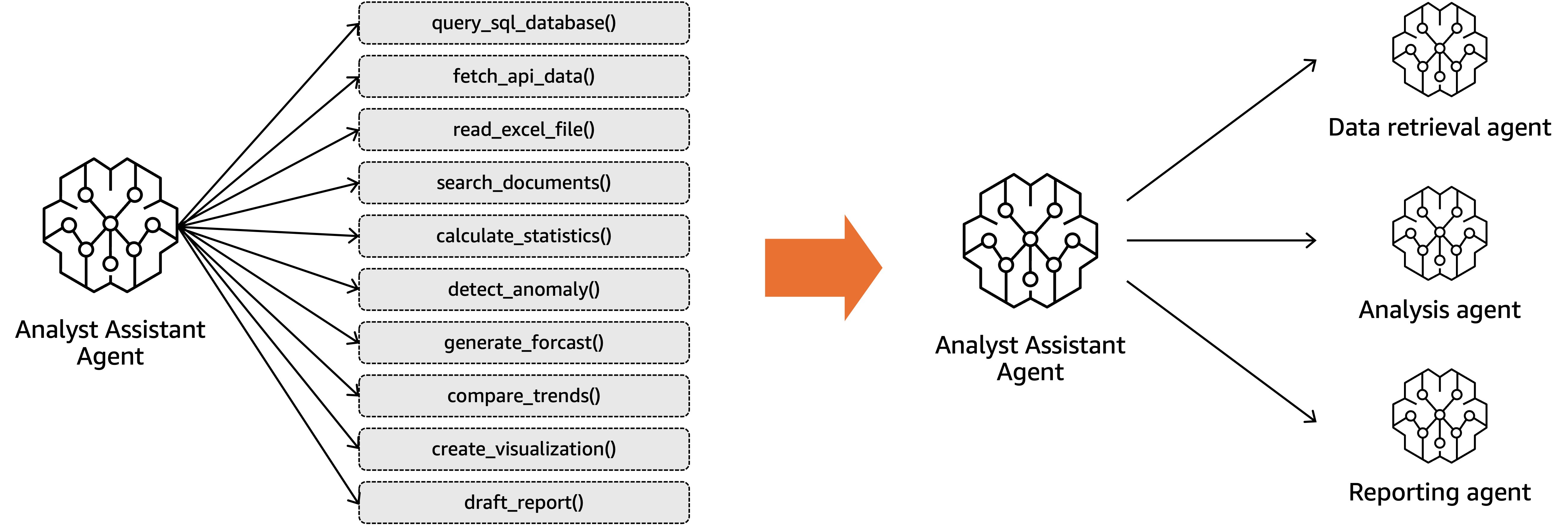
適切なオーケストレーションパターンの選択が重要です。シーケンシャルパターンは、タスクに自然な順序がある場合に適しています。最初のエージェントがデータを取得し、2 番目が分析し、3 番目がレポートを生成する、といった流れです。階層型パターンは、インテリジェントなルーティングが必要な場合に適しています。スーパーバイザーエージェントがユーザーの意図を判断し、専門エージェントに振り分けます。ピアツーピアパターンは、中央のコーディネーターなしにエージェント同士が動的に協調する必要がある場合に適しています。
マルチエージェントシステムにおける最大の課題は、エージェント間の引き継ぎ時にコンテキストを維持することです。あるエージェントが別のエージェントに処理を渡す際、引き継ぎ先のエージェントはそれまでの経緯を把握している必要があります。ユーザーが最初のエージェントにアカウント番号を伝えたのに、次のエージェントがまた聞き直すようでは困ります。AgentCore Memory は、セッション内で複数のエージェントがアクセスできる共有コンテキストを提供します。
エージェント間の引き継ぎは注意深くモニタリングしてください。障害の多くはここで発生します。どのエージェントがリクエストのどの部分を処理したのか? どこで遅延が生じたのか? どこでコンテキストが失われたのか? AgentCore Observability はワークフロー全体をエンドツーエンドでトレースするため、こうした問題の診断が可能です。
ここで、よくある混同を整理しておきましょう。プロトコルとパターンは別物です。プロトコルはエージェント間の通信方法を定義するもので、インフラレイヤー、通信フォーマット、API コントラクトに相当します。Agent2Agent (A2A) プロトコル、MCP、HTTP はプロトコルです。一方、パターンはエージェントの作業の組織化方法を定義するもので、アーキテクチャレイヤー、ワークフロー設計、協調戦略に相当します。シーケンシャル、階層型、ピアツーピアはパターンです。
同一プロトコルを異なるパターンで使うことができます。A2A を使ってシーケンシャルパイプラインを構築することも、階層型スーパーバイザーを構築することもできます。逆に、同一パターンを異なるプロトコルで実現することも可能です。シーケンシャルな引き継ぎは MCP、A2A、HTTP でも動作します。インフラとビジネスロジックを密結合させないよう、これらは分離しておきましょう。
次の表は、マルチエージェント協調のプロトコルとパターンにおけるレイヤー、対象、例の違いを整理したものです。
| プロトコル – エージェント間の通信方法 | パターン – エージェントの組織化方法 | |
| レイヤー | 通信とインフラ | アーキテクチャと組織化 |
| 対象 | メッセージ形式、API、標準規格 | ワークフロー、役割分担、協調方法 |
| 例 | A2A、MCP、HTTP など | シーケンシャル、階層型、ピアツーピアなど |
パーソナライゼーションを維持しながら安全にスケールする
1 人の開発者向けに動くプロトタイプから、数千人のユーザーにサービスを提供する本番システムへ移行するには、分離性、セキュリティ、パーソナライゼーションに関する新たな要件が生まれます。
まず最優先はセッションの分離です。ユーザー A の会話がユーザー B のセッションに漏れることは、いかなる状況でもあってはなりません。2 人のユーザーが異なるプロジェクト、異なるリージョン、異なるアカウントについて同時に質問している場合、それぞれのセッションは完全に独立していなければなりません。AgentCore Runtime は、各セッションを専用のコンピューティングとメモリを備えた独立したマイクロ仮想マシン (microVM) 上で実行することで、この要件に対応しています。セッションが終了すると microVM も終了し、ユーザー間で共有される状態は一切残りません。
パーソナライゼーションには、セッションをまたいで永続化されるメモリが必要です。ユーザーには情報の提示方法に関して好みがあります。ユーザーが携わっているプロジェクトが質問のコンテキストとなり、ユーザーは職種に固有の用語や略語を使います。AgentCore Memory は、会話履歴のための短期メモリと、事実・好み・過去のインタラクションのための長期メモリの両方を提供します。メモリはユーザーごとに名前空間が分かれているため、各ユーザーのコンテキストはプライベートに保たれます。セキュリティとアクセス制御は、ツールが実行される前の段階で適用される必要があります。ユーザーは、閲覧権限のあるデータにのみアクセスできるべきです。次の図は、AgentCore の各コンポーネントが連携して複数のレイヤーでセキュリティを適用する仕組みを示しています。
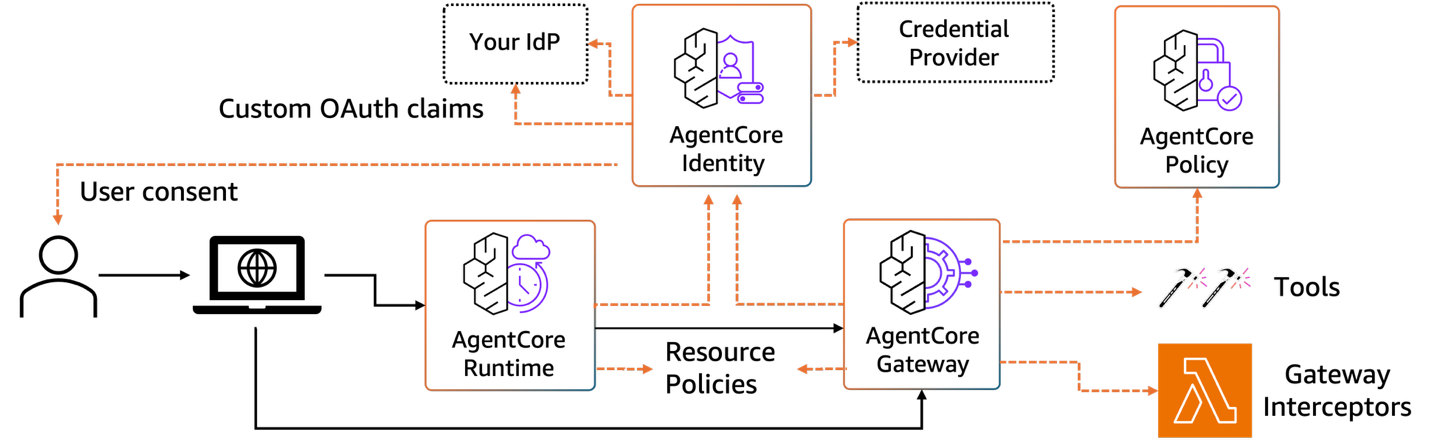
ユーザーがエージェントとインタラクトする際、まず Amazon Cognito、Microsoft Entra ID、Okta などの ID プロバイダー (IdP) を通じて認証を行います。AgentCore Identity は認証トークンを受け取り、ユーザーの権限と属性を定義するカスタム OAuth クレームを抽出します。これらのクレームは AgentCore Runtime を通じてエージェントに渡され、セッション内で利用可能になります。
エージェントがどのツールを呼び出すかを決定する段階で、AgentCore Gateway がポリシー適用のポイントとして機能します。ツールが実行される前に、Gateway はリクエストをインターセプトし、2 つのポリシーレイヤーに対して評価します。AgentCore Policy は、当該ユーザーが当該ツールを当該パラメータで呼び出す権限を持っているかどうかを検証し、誰が何にアクセスできるかを定義するリソースポリシーをチェックします。同時に、AgentCore Gateway は認証情報プロバイダー (Google Drive、Dropbox、Outlook など) を確認し、サードパーティーサービスに必要な認証情報を取得・使用します。ゲートウェイインターセプターは、ツール呼び出しが実行される前にカスタム認可ロジック、レート制限、監査ログなどを実装できる追加のフックを提供します。
これらのチェックをすべて通過して初めて、ツールが実行されます。例えば、ジュニアアナリストが経営幹部の報酬データにアクセスしようとした場合、リクエストはデータベースに到達する前に AgentCore Gateway の段階で拒否されます。ユーザーが Google Drive に対する OAuth 同意を付与していない場合、エージェントは明確なエラーメッセージを受け取り、ユーザーに通知します。ユーザーの同意フローは透過的に処理されます。エージェントが初めて認証情報プロバイダーへのアクセスを必要とした場合、システムが認可を求めるプロンプトを表示し、以降のリクエストのためにトークンを保存します。
この多層防御のアプローチにより、どのチームがエージェントやツールを構築したか、ツールがどこでホストされているかに関係なく、エージェントとツール全体でセキュリティが一貫して適用されます。
スケールが大きくなると、モニタリングの複雑さも増します。数千の同時セッションを扱う場合、集約的なパターンを把握しつつ、個々のインタラクションを掘り下げて調査できるダッシュボードが必要です。次の図のように、AgentCore Observability は、トークン使用量、レイテンシー分布、エラー率、ツール呼び出しパターンといったリアルタイムの指標をユーザー全体に渡って提供します。次の図のように、特定のユーザーで問題が発生した場合は、そのセッションで何が起きたかを正確にトレースできます。
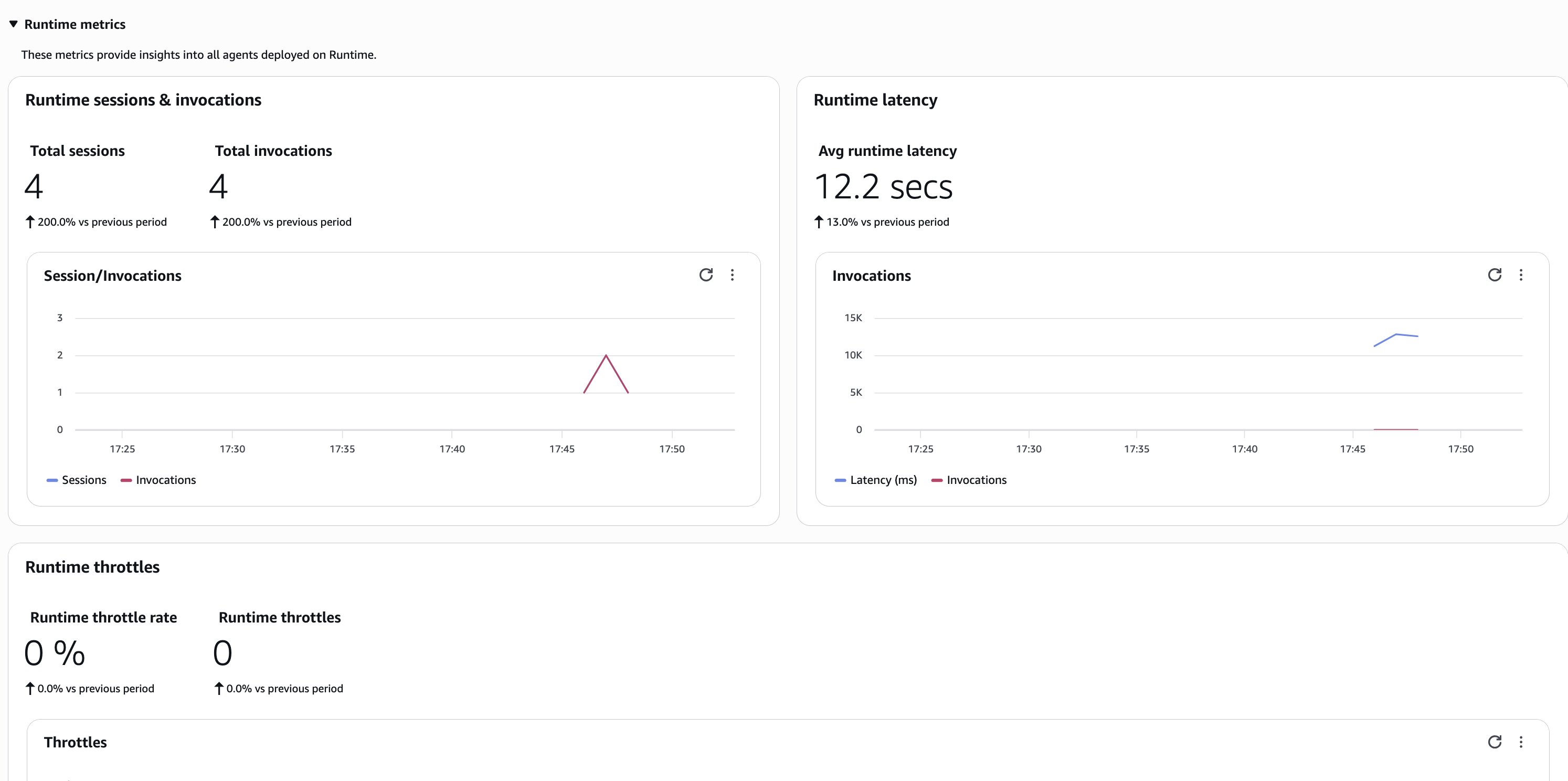
AgentCore Runtime は、ツールを MCP サーバーとしてホストする機能も備えています。これにより、アーキテクチャのモジュール性が保たれます。エージェントは密結合なしに AgentCore Gateway を通じてツールを検出および呼び出しを行います。ツールの実装を更新すると、エージェントはコード変更なしに自動的に新しいバージョンを使用します。
エージェントと決定論的コードを組み合わせる
アーキテクチャ上の最も重要な判断の 1 つは、エージェンティックな振る舞いに頼る場面と、従来のコードを使う場面の見極めです。エージェントは強力ですが、あらゆるタスクに適しているわけではありません。エージェントは、曖昧な入力に対する推論が必要なタスクに使います。自然言語クエリの理解、呼び出すツールの判断、コンテキストを踏まえた結果の解釈は、いずれも基盤モデルの推論能力が恩恵をもたらす領域です。決定論的コードで対応しようとすれば、膨大な数のケースを網羅する必要があります。一方、計算、バリデーション、ルールベースのロジックには従来のコードを使います。収益成長率は数式で求められます。日付のバリデーションはパターンマッチで済みます。ビジネスルールは条件分岐です。「Q3 から Q2 を引いて Q2 で割る。」という計算に言語モデルは不要です。Python の関数を書けば、ミリ秒で実行でき、追加コストなしに毎回同一の答えを返します。
適切なアーキテクチャでは、エージェントがコード関数をオーケストレーションします。ユーザーが「今四半期の EMEA の成長率は?」と尋ねると、エージェントは推論によって意図を理解し、どのデータを取得すべきかを判断します。次に決定論的な関数を呼び出して計算を実行し、再び推論を使って結果を自然言語で説明します。
「来月の支出レポートを作成して」というクエリに対する 2 つのアプローチを、大規模言語モデル (LLM) の呼び出し回数、トークン数、レイテンシーの観点で比較してみます。1 つ目は get_current_date() をエージェンティックツールとして公開するアプローチ、2 つ目は現在の日付を属性としてエージェントに渡すアプローチです:
get_current_date() をツールとして使用する |
現在の日付を属性として渡す | |
| クエリ | 「来月の支出レポートを作成して」 | 「来月の支出レポートを作成して」 |
| エージェントの動作 | get_current_date() を呼び出す計画を立てる。
取得した日付から翌月を算出。 翌月をパラメータとして create_report() を呼び出し、最終レスポンスを生成。 |
コードで現在の日付を取得。
today を属性としてエージェントに渡す。 翌月 (LLM の推論で算出) をパラメータとして create_booking() を呼び出し、最終レスポンスを生成。 |
| レイテンシー | 12 秒 | 9 秒 |
| LLM 呼び出し回数 | 4 回 | 3 回 |
| 合計トークン数 (入力 + 出力) | 約 8,500 トークン | 約 6,200 トークン |
現在の日付はコードで簡単に取得できる情報です。呼び出し時に属性としてエージェントのコンテキストに渡すことができます。2 番目のアプローチの方が高速で、低コストで、しかもより正確です。これを数千のクエリに掛け合わせれば、差は無視できないものになります。コストと価値を継続的に測定します。決定論的コードで確実に解決できる問題にはコードを使い、推論や自然言語理解が必要な場面ではエージェントを使う。よくある間違いは、すべてをエージェンティックにしなければならないと思い込むことです。正解は、エージェントとコードを組み合わせて使うことです。
継続的なテストプラクティスを確立する
本番環境へのデプロイはゴールではありません。スタートラインです。エージェントは絶えず変化する環境の中で動作します。ユーザーの行動は変わり、ビジネスロジックは更新され、モデルの動作はドリフトする可能性があります。こうした変化がユーザーに影響を及ぼす前に検知するために、継続的なテストが必要です。 すべての更新時に実行される継続的テストパイプラインを構築します。一般的なケースとエッジケースを網羅する代表的なクエリを含むテストを整備します。プロンプトの変更、ツールの追加、モデルの切り替えを行うと、パイプラインがテストを実行して結果をスコアリングします。精度がしきい値を下回った場合、デプロイは自動的に失敗します。これによりリグレッションの防止に役立ちます。 A/B テストを活用して、本番環境での変更を検証します。新しいモデルや異なるプロンプト戦略を試す場合、すべて一度に切り替えるのは避けてください。例えば、トラフィックの 10% を新バージョンにルーティングし、1 週間かけてパフォーマンスを比較します。精度、レイテンシー、コスト、ユーザー満足度を測定し、新バージョンの方が優れていれば段階的にロールアウトします。そうでなければロールバックします。AgentCore Runtime は、バージョニングとトラフィック分割の組み込みサポートを提供しています。 本番環境でのドリフトもモニタリングします。ユーザーのパターンは時間とともに変化します。以前はまれだった質問が頻出するようになったり、新製品がリリースされたり、用語が変わったりします。ライブのインタラクションを継続的にサンプリングし、品質指標に照らしてスコアリングします。ドリフトを検知した場合 (例えば、精度が 2 週間で 92% から 84% に低下した場合)、根本原因を調査して対処します。
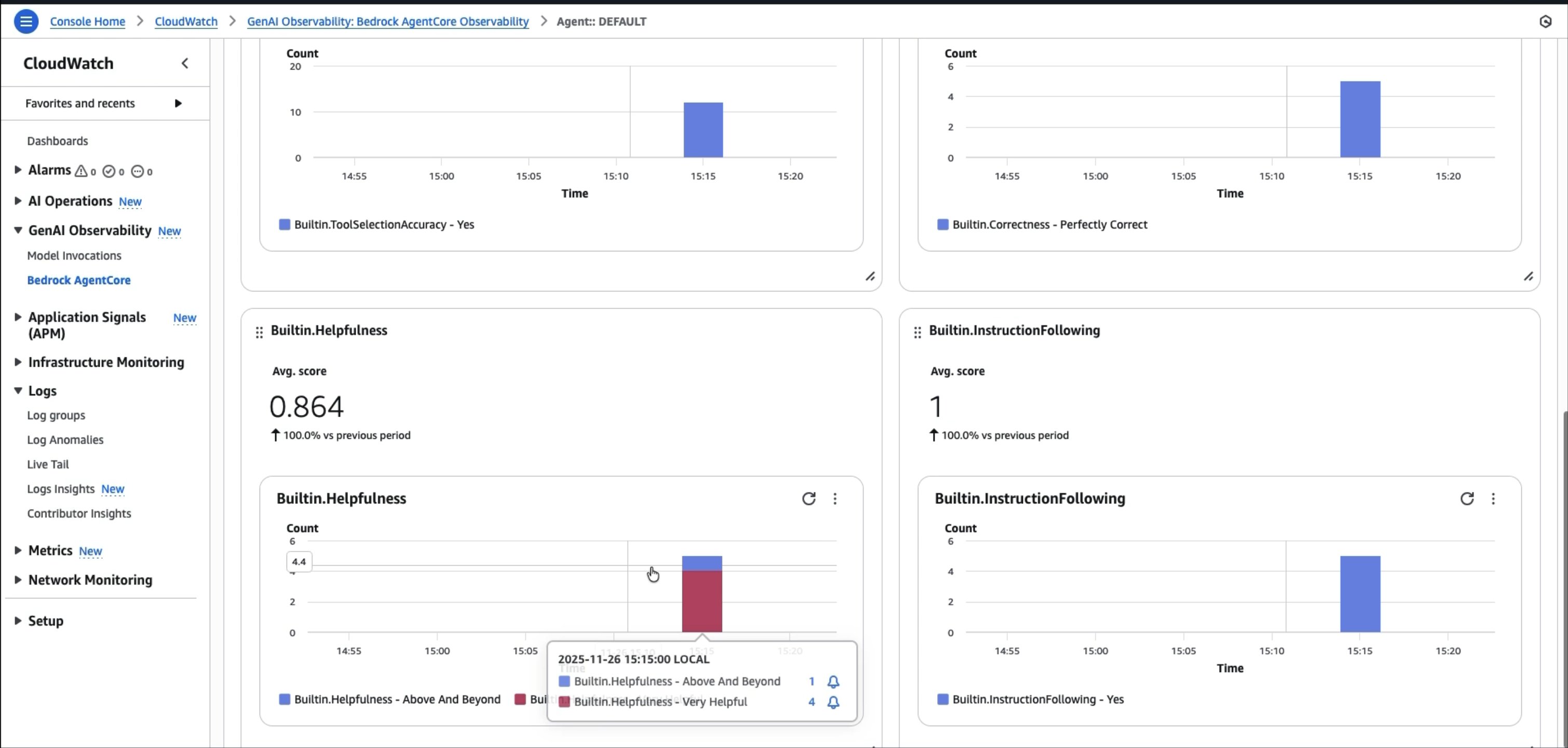
AgentCore Evaluations は、こうした評価の実行メカニズムを簡素化します。開発ライフサイクルの各段階に対応する 2 つの評価モードを提供しています。オンデマンド評価では、事前定義したテストデータセットに対してエージェントの性能を評価できます。デプロイ前にテストを実行したり、2 つのプロンプトバージョンを並べて比較したり、Ground truth の例に対してモデル変更の影響を検証したりできます。オンライン評価は、ライブの本番トラフィックを継続的にモニタリングし、実際のユーザーとのインタラクションをサンプリング・スコアリングすることで、品質の低下をリアルタイムに検知します。どちらのモードも、OpenTelemetry および OpenInference の計装を通じて、Strands や LangGraph を含む主要なフレームワークと連携します。エージェントの実行時にトレースが自動的にキャプチャされ、統一されたフォーマットに変換された上で、LLM-as-Judge の手法でスコアリングされます。有用性、有害性、精度といった一般的な品質指標には組み込みの評価器を使用でき、ドメイン固有の要件には独自のスコアリングロジックでカスタム評価器を作成できます。次の図は、AgentCore Evaluations に表示される評価指標の例を示しています。
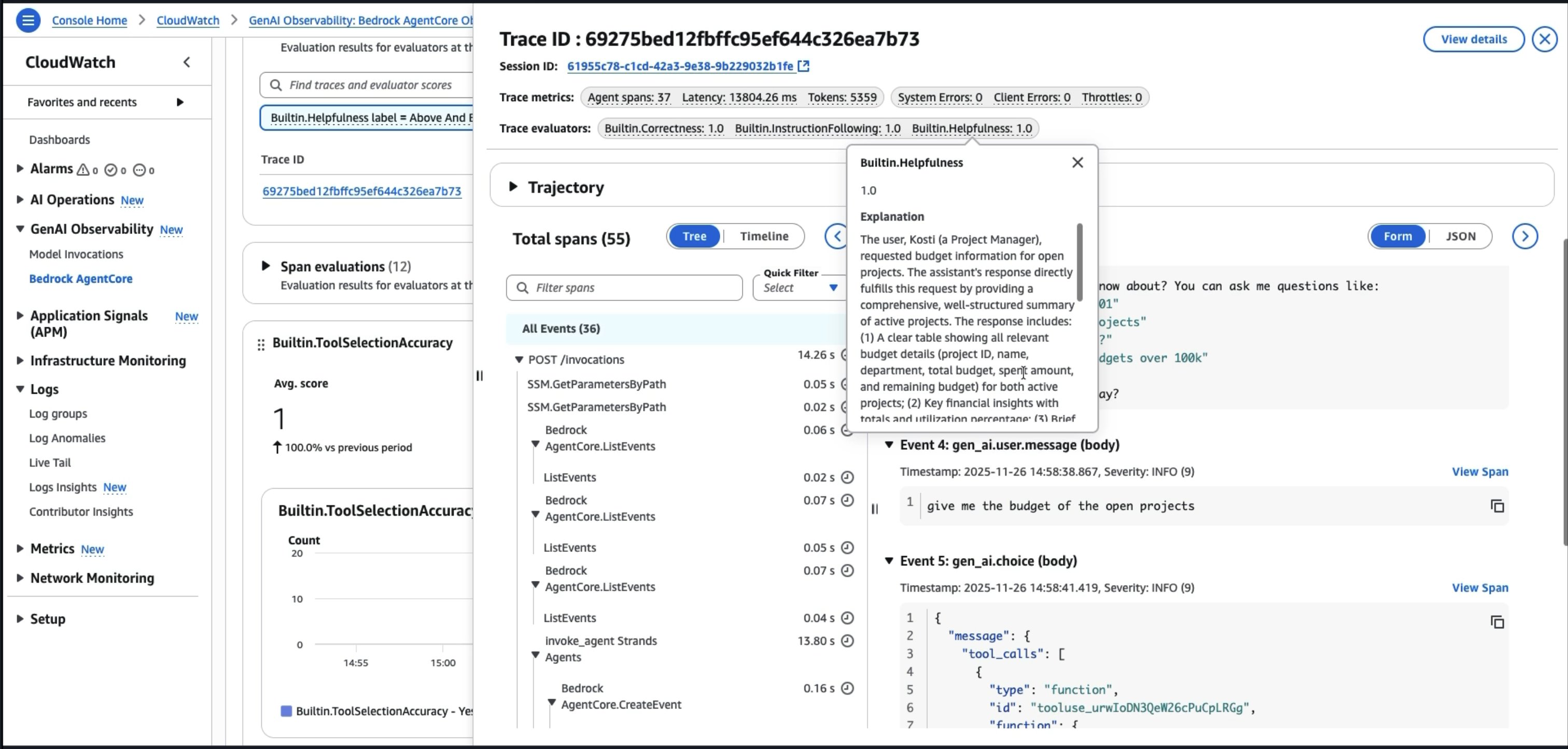
自動ロールバックの仕組みも確立します。重要な指標がしきい値を超えた場合、以前の正常なバージョンに自動的に戻すようにします。例えば、ハルシネーション率が 5% を超えたらロールバックしてチームにアラートを送信します。ユーザーからの問題報告を待ってはいけません。
テスト戦略には次の要素を含めるべきです:
- すべての変更に対する自動リグレッションテスト
- メジャーアップデートに対する A/B テスト
- 本番環境での継続的なサンプリングと評価
- 自動アラート付きのドリフト検知
- 品質低下時の自動ロールバック
エージェントにおいては、環境が変化し続ける限り、テストも止まることはありません。
組織的な能力を構築する
本番環境で最初のエージェントを稼働させることは大きな成果です。しかし、エンタープライズとしての真の価値は、この能力を組織全体にスケールさせることで生まれます。そのためには、プロジェクト単位の発想ではなく、プラットフォームとしての発想が必要です。
ユーザーからのフィードバックとインタラクションのパターンを継続的に収集します。オブザーバビリティダッシュボードを監視して、どのクエリが成功し、どのクエリが失敗し、テストセットには含まれていないエッジケースが本番で出現しているかを把握します。このデータを使って Ground truth データセットを拡充していきます。当初 50 件だったテストケースが、実際の本番でのインタラクションに基づいて数百件に成長していくのです。
標準の策定と共有インフラの提供のためにプラットフォームチームを立ち上げます。プラットフォームチームの役割は次の通りです:
- セキュリティチームの審査を経た承認済みツールのカタログを維持する。
- オブザーバビリティ、評価、デプロイのプラクティスに関するガイダンスを提供する。
- エージェント全体のパフォーマンスを可視化する一元的なダッシュボードを運用する。
新しいチームがエージェントを構築する際は、プラットフォームのツールキットからスタートします。各チームはツールやエージェントの本番デプロイが完了した時点で、プラットフォームへ還元できます。スケールに伴い、プラットフォームチームが再利用可能なアセットと標準を提供する一方で、各チームも独自のアセットを開発し、検証が済んだものをプラットフォームへ戻していきます。
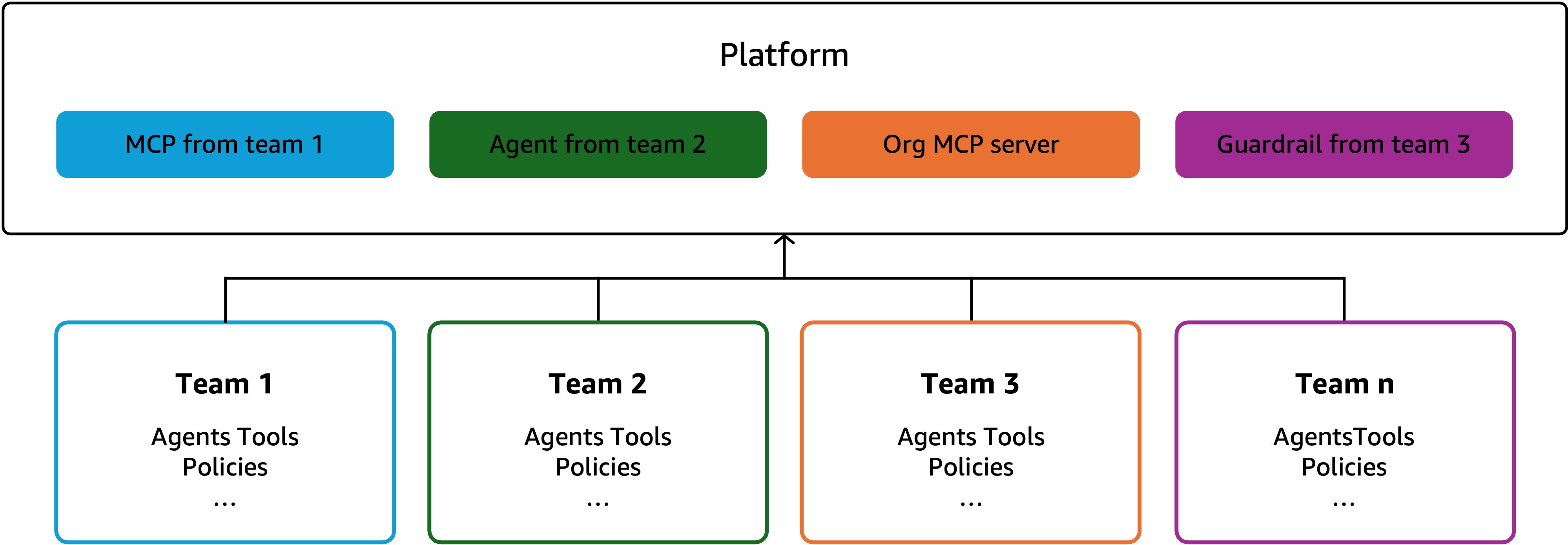
組織全体のエージェントを横断する一元的なモニタリングを導入します。1 つのダッシュボードでエージェント、セッション、コストを一覧できるようにします。トークン使用量が予期せず急増した場合、プラットフォームのリーダーはすぐに気づけます。チーム別、エージェント別、期間別に掘り下げて、何が変わったのかを把握できます。
チーム同士が学び合えるよう、チーム横断のコラボレーションを推進します。3 つのチームがそれぞれ独自のデータベースコネクタバージョンを構築するのは非効率です。代わりに AgentCore Gateway を通じてツールを共有し、評価戦略を共有し、チームがエージェントのデモや課題の議論を行う定期的なセッションを開催すべきです。こうした取り組みから共通の課題が浮かび上がり、共有のソリューションが生まれます。
組織的なスケーリングは、Crawl (ハイハイ)、Walk (歩く)、Run (走る) の段階で進めます:
- Crawl フェーズ: 小規模なパイロットグループ向けに最初のエージェントを社内にデプロイする。学習とイテレーションに集中する段階であり、失敗のコストは低く抑えられます。
- Walk フェーズ: 管理された外部ユーザーグループにエージェントをデプロイする。ユーザーが増え、フィードバックが増え、より多くのエッジケースが発見されます。オブザーバビリティと評価への投資がここで活きてきます。
- Run フェーズ: 確信を持ってエージェントを外部ユーザーにスケールさせる。プラットフォームの機能により、他のチームも独自のエージェントをより迅速に構築できるようになります。組織的な能力が複利的に成長していきます。
こうして、1 人の開発者が 1 つのエージェントを構築する段階から、数十のチームが一貫した品質、共有インフラ、加速する開発速度のもとで数十のエージェントを構築する段階へと進化していくのです。
まとめ
本番環境で使える AI エージェントの構築には、基盤モデルを API に接続する以上のことが必要です。開発ライフサイクル全体にわたる規律あるエンジニアリングプラクティスが求められます。次の通りです:
- 明確に定義された課題から小さく始める。
- 初日からすべてを計装する。
- 計画的なツール戦略を構築する。
- 評価を自動化する。
- マルチエージェントアーキテクチャで複雑さを分解する。
- パーソナライゼーションを維持しながら安全にスケールする。
- エージェントと決定論的コードを組み合わせる。
- 継続的にテストする。
- プラットフォーム思考で組織的な能力を構築する。
Amazon Bedrock AgentCore は、これらのプラクティスを実践するために必要なサービスを提供しています:
- AgentCore Runtime は、分離された環境でエージェントとツールをホストする。
- AgentCore Memory は、パーソナライズされたインタラクションを実現する。
- AgentCore Identity と AgentCore Policy は、セキュリティの適用を支援する。
- AgentCore Observability は、可視性を提供する。
- AgentCore Evaluations は、継続的な品質評価を可能にする。
- AgentCore Gateway は、標準プロトコルを使ってエージェントとツール間の通信を統合する。
- AgentCore Browser は、AI エージェントが安全なクラウドベースのブラウザを通じてウェブサイトとインタラクトできるようにし、AgentCore Code Interpreter は、AI エージェントがサンドボックス環境でコードをより安全に記述・実行できるようにする。
これらのベストプラクティスは理論上の話ではありません。実際のワークロードを処理する本番エージェントを構築してきたチームの経験から導き出されたものです。デモで印象的なエージェントと、ビジネス価値を生み出すエージェントの違いは、こうした基本をいかに実行するかで決まります。
詳細については、Amazon Bedrock AgentCore ドキュメントをご覧ください。また、AgentCore の コードサンプルと、入門用および ディープダイブ用のハンズオンワークショップも公開しています。
本記事はクラウドサポートエンジニアの成本が翻訳しました。原文はこちらです。
著者について
 Maira Ladeira Tanke は、AWS のエージェンティック AI テックリードとして、自律型 AI システムの開発に取り組むお客様を支援しています。AI/ML 分野で 10 年以上の経験を持ち、エンタープライズのお客様と連携しながら、Amazon Bedrock AgentCore と Strands Agents を活用したエージェンティックアプリケーションの導入を加速させています。組織が基盤モデルの力を活かしてイノベーションとビジネス変革を推進できるよう支援しています。プライベートでは、旅行や愛猫との時間、暖かい場所での家族との団らんを楽しんでいます。
Maira Ladeira Tanke は、AWS のエージェンティック AI テックリードとして、自律型 AI システムの開発に取り組むお客様を支援しています。AI/ML 分野で 10 年以上の経験を持ち、エンタープライズのお客様と連携しながら、Amazon Bedrock AgentCore と Strands Agents を活用したエージェンティックアプリケーションの導入を加速させています。組織が基盤モデルの力を活かしてイノベーションとビジネス変革を推進できるよう支援しています。プライベートでは、旅行や愛猫との時間、暖かい場所での家族との団らんを楽しんでいます。
 Kosti Vasilakakis は、AWS のエージェンティック AI チームのプリンシパル PM として、Runtime、Browser、Code Interpreter、Identity を含む複数の Bedrock AgentCore サービスの設計と開発をゼロから主導してきました。以前は Amazon SageMaker の初期から携わり、現在世界中の数千の企業で利用されている AI/ML 機能のリリースに貢献しました。キャリアの初期にはデータサイエンティストとして活動していました。仕事以外では、個人の生産性を高める自動化ツールの構築、テニス、妻との時間を楽しんでいます。
Kosti Vasilakakis は、AWS のエージェンティック AI チームのプリンシパル PM として、Runtime、Browser、Code Interpreter、Identity を含む複数の Bedrock AgentCore サービスの設計と開発をゼロから主導してきました。以前は Amazon SageMaker の初期から携わり、現在世界中の数千の企業で利用されている AI/ML 機能のリリースに貢献しました。キャリアの初期にはデータサイエンティストとして活動していました。仕事以外では、個人の生産性を高める自動化ツールの構築、テニス、妻との時間を楽しんでいます。