Amazon Web Services ブログ
AJA SSP が Apache Iceberg と AWS Glue Data Catalog でペタバイトスケールのデータ基盤の柔軟なクエリエンジンの選択とクエリの高速化を実現
※ この記事はお客様に寄稿いただき、AWS が加筆・修正したものとなっています。
株式会社 AJA は、株式会社サイバーエージェントのグループ会社として、ABEMA をはじめとしたプレミアム動画メディア向けの広告マーケットプレイス「AJA SSP」を提供しています。さらに、広告主向けプラットフォーム「AJA DSP」や、動画の考査を最短かつ簡便に行える「AJA Video Platform」、地上波テレビ CM の視聴データを活用しコネクテッド TV へ効果的に広告配信を行う「インクリー」、地上波テレビ CM の広告効果をデジタル広告と同一指標で評価・可視化できる運用サービス「ミエル TV」など、多彩なプロダクトを展開しています。これらのサービスを通じて、AJA は優良メディアの収益向上と企業の多様なマーケティング課題の解決に積極的に取り組んでいます。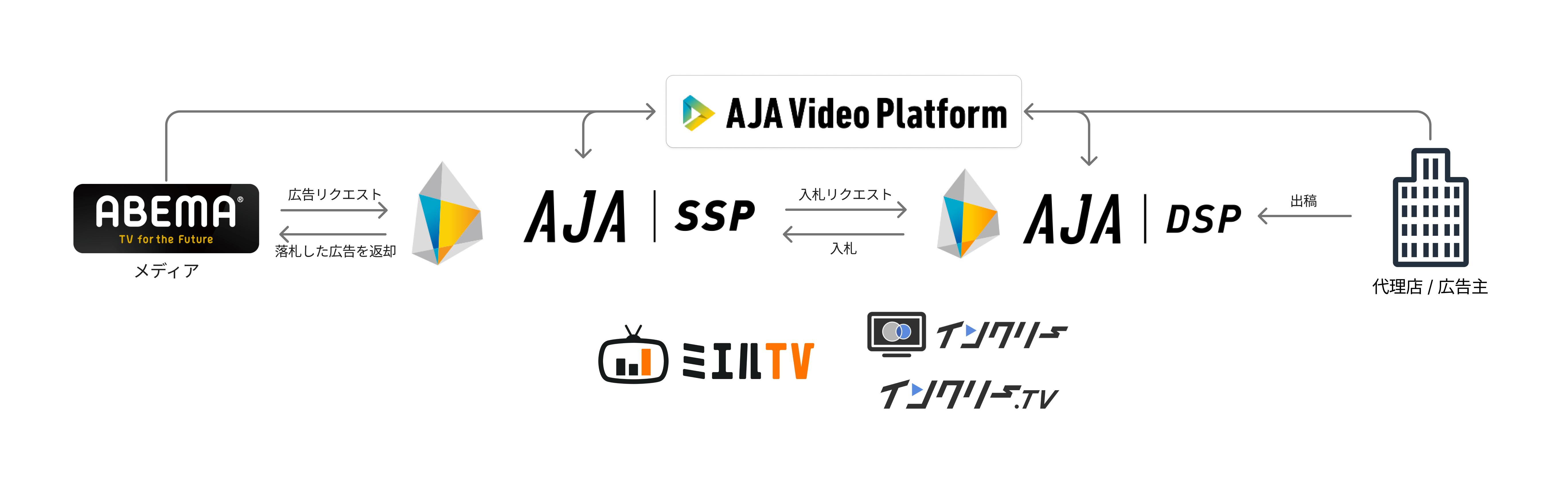
AJA SSP ではペタバイトスケールのデータ基盤を運用していますが、ビジネスがますます成長していく中で、アドホックなクエリのパフォーマンスや AJA DSP のデータとの統合的な分析に課題が生じていました。これらの課題を解決するために、Apache Iceberg を使ったアーキテクチャを導入しました。
Iceberg は大規模なデータを効率的に扱うことができるオープンなテーブルフォーマットで、Apache Spark や Trino、Apache Flink といった様々なエンジンやサービスがサポートしています。Apache Parquet のような列指向データファイルと、テーブル単位の統計データを含むメタデータファイルから構成されており、これによってファイルレベルのプルーニングを効率よく行うことができます。
AWS では Amazon EMR や Amazon Athena、Amazon Data Firehose といったサービスで Iceberg テーブルを読み書きすることができ、AWS Glue Data Catalog の自動コンパクションといった運用をサポートする機能も提供されています。
本ブログでは、Iceberg や AWS のサービスを活用して、AJA SSP が課題解決に挑んだ取り組みについて述べます。
課題
AJA SSP では主に広告配信におけるプランニングやレポーティング、コンテンツ分析のために毎時 Amazon Managed Workflows for Apache Airflow (MWAA) で Spark のバッチ集計ジョブを実行しています。各集計ジョブは依存関係を持ち、再集計を行うこともあります。そのため直感的な構文で依存関係を定義し、また特定期間の同一ジョブをまとめて実行することができる Airflow を利用しています。これによって集計されたテーブルはメディアの広告枠の設定などを行う管理画面のレポート機能やアドホックな分析で Athena から参照されています。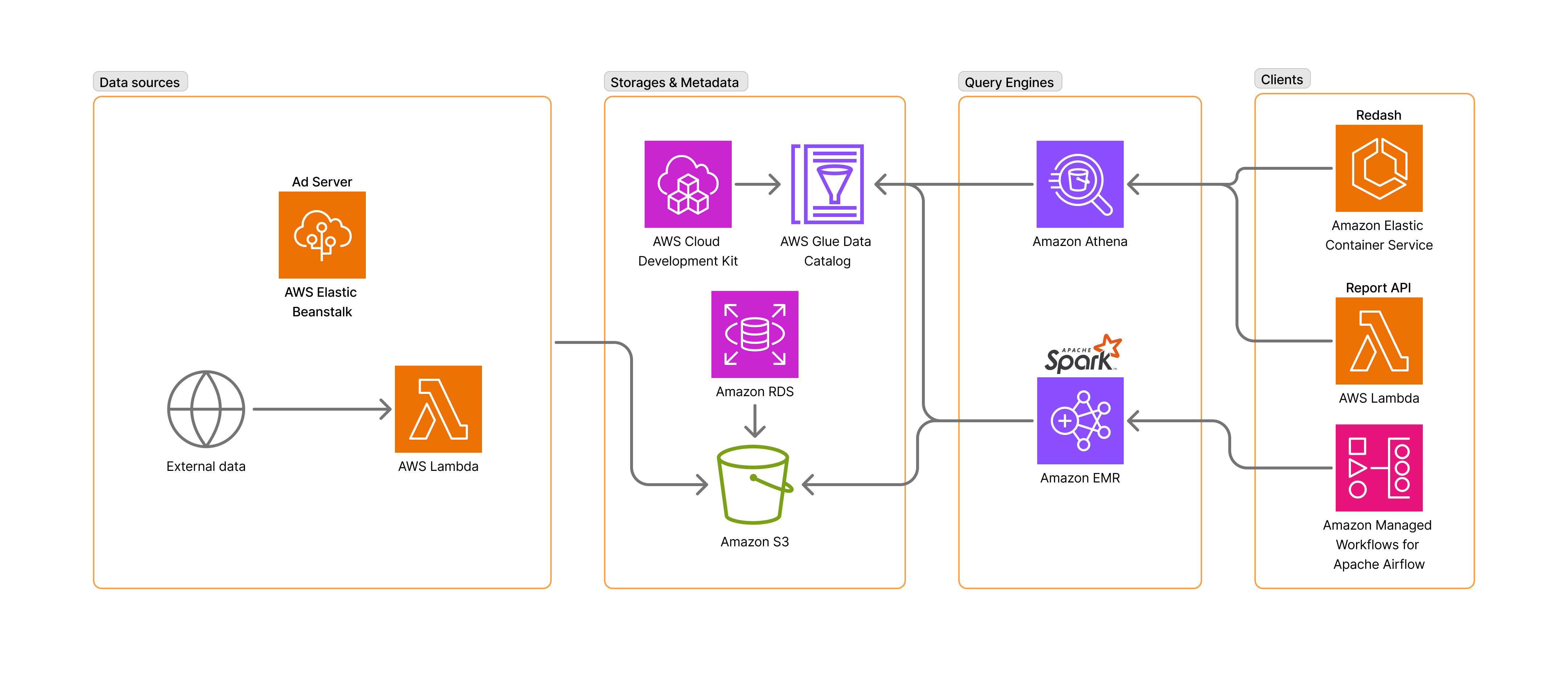
ビジネスの成長に伴い、組織としてもこれまで以上にデータを活用していく動きが進む中で 2 つの課題がありました。
ひとつはアドホックなクエリのパフォーマンスです。以前と比べて複雑な分析やトラブルシューティングを行うようになり、レポーティングのための集計済みサマリーテーブルでは粒度が大きすぎるため、生のログに近いテーブルを参照する機会が増えてきました。しかしそのようなテーブルは 1 日あたり数 TB ほどになり、数ヶ月にわたって参照したり複雑な JOIN を行ったりすると、Athena のクエリの完了まで数十分かかったり、scale factor 起因のリソース枯渇を示すエラーで失敗することもありました。
もうひとつはプロダクトを跨いだデータの分析です。AJA SSP は AWS 上、AJA DSP は他社クラウド上で動いていることもあり、手動でデータをエクスポートしアップロードするといった運用が行われていました。その結果、分析に時間を要し、また再利用性やデータの鮮度も低下していました。あわせて、組織のデータを最大限活用できるようにしつつも、意図しない用途でデータが利用されないよう適切なアクセス権限の設定も必要でした。
取り組み
この 2 つの課題を解決するため Iceberg を中心とした構成に移行しました。
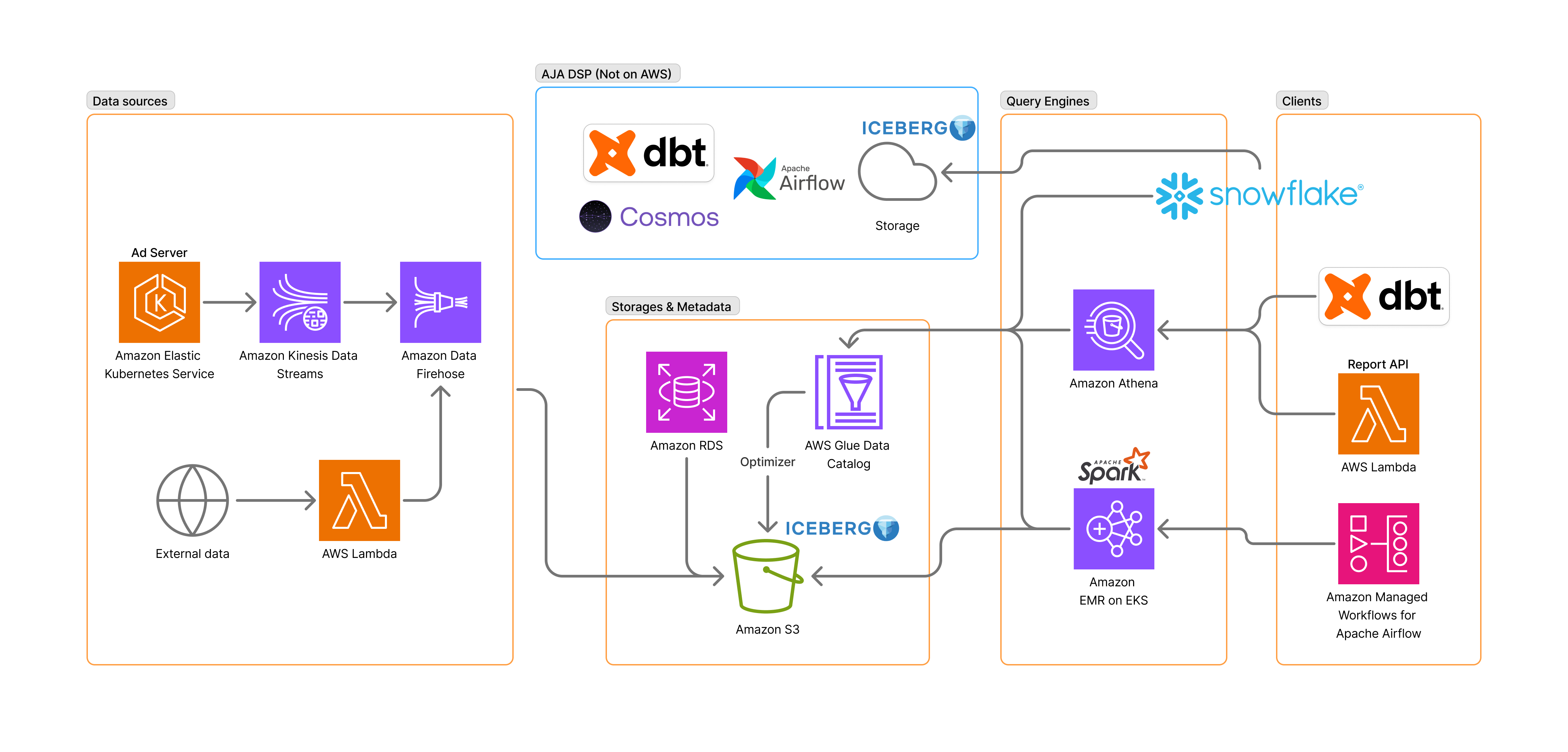
アドホックなクエリを実行する基盤として Snowflake を採用しました。Snowflake は各種クラウド上で動くフルマネージドなデータプラットフォームで、コンピューティングリソースであるウェアハウスのサイズを大きくすることで重いクエリにも対応でき、ウェアハウスを自動で起動、シャットダウンさせることにより、実行したクエリに対する従量課金のように利用することができます。アクセス制限に関してはテーブルだけではなく行や列に対してもかけることができます。また、Snowflake を使っている他の組織とのデータ連携が容易である点も採用する決め手となりました。
管理画面などのアプリケーションでは性能に関して課題がなく、新たに認証情報を与える必要がない Athena を引き続き利用する方針だったので、Snowpipe などで Snowflake に S3 のデータをロードすることは Single Source of Truth (SSOT) の観点で望ましくありませんでした。S3 を外部テーブルとして参照すればこの点は解消できますが、Snowflake 側にもスキーマ定義が必要となり、スキーマの二重管理の懸念がありました。一方で Iceberg テーブルとして作成すると、Snowflake 側でのスキーマ定義が不要となりスキーマまで含めた SSOT を実現できます。さらに Glue Data Catalog を参照することで Iceberg のメタデータファイルのパスを渡すことなくテーブル名だけで最新のデータを参照することができます。
// Snowflakeで実行するDDL
// カタログ統合を作成
CREATE CATALOG INTEGRATION IF NOT EXISTS GLUE_CATALOG_INTEGRATION
CATALOG_SOURCE = GLUE
CATALOG_NAMESPACE = '(database_name)'
TABLE_FORMAT = ICEBERG
GLUE_AWS_ROLE_ARN = 'arn:aws:iam::...:role/...'
GLUE_CATALOG_ID = '...'
GLUE_REGION = 'ap-northeast-1'
ENABLED = TRUE;
// 外部ボリュームを作成
CREATE EXTERNAL VOLUME IF NOT EXISTS AJA_SSP_ICEBERG
STORAGE_LOCATIONS = (
(
NAME = 'AJA_SSP_ICEBERG'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://...'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::...:role/...'
)
);
// AWS Glue Data Catalogに登録されているIcebergテーブルを使用して、Apache Icebergテーブルを作成
CREATE OR REPLACE ICEBERG TABLE TABLE_NAME
CATALOG = GLUE_CATALOG_INTEGRATION,
EXTERNAL_VOLUME = AJA_SSP_ICEBERG,
CATALOG_TABLE_NAME = '(table_name)',
CATALOG_NAMESPACE = '(database_name)',
AUTO_REFRESH = TRUE;他社クラウドのデータも含めて Iceberg に統一することで同様の手順でデータを参照することができ、用途に応じて自由にクエリエンジンを選択できる環境が整いました。
Spark での Iceberg テーブルの読み書き方法については従来と大きく変わりませんでした。移行中は新旧両方のテーブルに書き込んでいます。
/* 旧テーブルへの書き込み */
df.write.mode(SaveMode.Overwrite).parquet(s"s3://.../ymd=.../hour=...")
/* Spark で Glue Data Catalog や S3 と合わせて Iceberg を利用する際の設定
"spark.sql.catalog.iceberg": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.iceberg.warehouse" : "s3://.../",
"spark.sql.catalog.iceberg.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"spark.sql.catalog.iceberg.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
*/
/* 新テーブルへの書き込み */
df.writeTo(s"iceberg.(database_name).(table_name)")).overwritePartitions()ただ、運用にするにあたってテーブルのスキーマをどう定義するかという問題があります。
従来のテーブルは AWS CDK で作成していたのですが、現状 CDK で Iceberg テーブルを作成し、スキーマの更新などを行うと Iceberg テーブルとして扱われなくなるという課題があります。そのため、当初は Amazon Athena for Apache Spark の Notebook から手動で CREATE TABLE を実行していましたが、本格的な運用が始まりバージョン管理に乗せるにあたって、宣言的にスキーマを定義できたり SQLFluff でフォーマットをかけられるといった点で、dbt 公式の Athena アダプタである dbt-athena で 0 件のレコードを append することでテーブルの作成およびスキーマの更新のみを行うようにしました。
{{ config(
materialized = 'incremental',
incremental_strategy = 'append',
table_type = 'iceberg',
format = 'parquet',
s3_data_naming = 'table',
on_schema_change = 'append_new_columns',
partitioned_by = ['ymd', 'hour']
) }}
SELECT
CAST(NULL AS DATE) AS ymd,
CAST(NULL AS INT) AS hour,
...
WHERE falseしかし、この方法は特定のテーブルプロパティしか設定できず、パーティションが更新できないといった Athena 由来の制約があります。AJA DSP では先んじて dbt による集計に移行し、Cosmos で dbt の model を Airflow の DAG に変換して動かしていることもあり、 AJA SSP でも将来的には集計ごと dbt-spark に移行することも検討しています。
ちなみに、集計ジョブは従来 EMR on EC2 で動かしていましたが、配信サーバーの Amazon Elastic Kubernetes Service (EKS) 移行に伴い、EMR on EKS に移行し、同じクラスタで Spark のジョブも動かすようにしました。これにより配信サーバーと集計でクラスタ管理の知見を共用できるようになったことに加え、余剰リソースを集計に割けるようになり、また、集計分のリソースを配信サーバーがスケールアウトする際のバッファとして用いることもできるようになりました。
パフォーマンス
普段実行されているクエリの中からプルーニングが十分効くであろうクエリを選んで比較してみました。
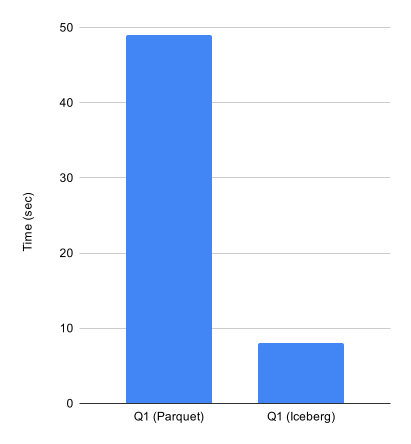
70 TB ほどのログの中から特定リクエスト ID のレコードを抽出するクエリを Athena で 実行したところ、Parquet では 49 秒かかっていたのに対して同じパーティション粒度の Iceberg では 8 秒で完了しました。
加えて、Glue Data Catalog の統計情報の生成ジョブを実行し JOIN に用いるカラムの Number of Distinct Values (NDV) を含む Puffin ファイルを生成したところ、クエリでの順番にかかわらず、ハッシュテーブルが小さくなるように JOIN の順番が最適化されることも確認できました。
なお、次のテーブルプロパティを設定することで Parquet ファイルに Bloom Filter が書き込まれるようになり、カーディナリティが高いカラムにおいて Row group に特定の値のデータが存在し得るかの判定が効率化されることが期待されます。しかし今回のケースでは、スキャン量のみが増加する結果となりました。
ALTER TABLE (database_name).(table_name)
SET TBLPROPERTIES (
'write.parquet.bloom-filter-enabled.column.(col_name)' = 'true',
'write.parquet.bloom-filter-max-bytes' = '10485760',
'write.parquet.bloom-filter-fpp.column.(col_name)' = '0.01'
)
/*
$ parquet bloom-filter xxx.parquet -c (col_name) -v aaa,bbb,ccc
Row group 0:
--------------------------------------------------------------------------------
value aaa maybe exists.
value bbb NOT exists.
value ccc NOT exists.
*/続いて、特定パターンでの週間リクエスト数とユニークユーザー数の集計は、スキャン量は 15 GB 程度ですが時間のかかるクエリでした。元々の Athena + Parquet では 5 分かかっていましたが、Iceberg にすることで 103 秒で実行でき、スキャン量も 5 GB まで減りました。さらに Snowflake の X-Large ウェアハウスでは 77 秒、4X-Large では 15 秒まで短縮することができ、リソースを増やして高速にクエリを実行する選択肢ができました。
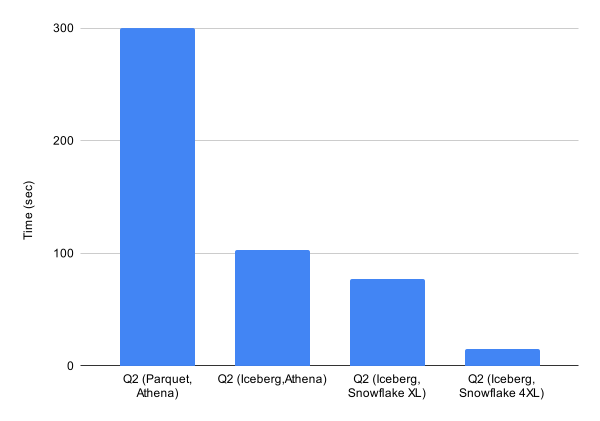
Iceberg を採用することで、従来の Athena のクエリも高速化しました。Athena は実行したクエリでスキャンされたデータ量に基づいて計算される従量課金なので、スキャン量が減ったことでコストも削減できました。さらに、Snowflake では、ウェアハウスを大きくすることでさらなる高速化が実現できました。結果として、Iceberg でコストパフォーマンスを改善しつつ、求める要件によって柔軟にクエリエンジンを選べるようになりました。
最後に
AJA SSP では Iceberg の採用によって、エンジンが柔軟に選択できるようになり、クエリのパフォーマンスも向上したことで分析サイクルを高速に回せるようになりました。ひとつ目の課題として挙げたアドホックなクエリのパフォーマンスは、Iceberg との組み合わせによりクエリエンジンを問わず効果が確認されています。2 つ目の課題であったプロダクトを跨いだデータの分析も、AJA SSP、AJA DSP それぞれの Iceberg フォーマットのデータを Snowflake から参照することによって SSOT で実現できました。Iceberg というオープンなテーブルフォーマットで S3 に保持しておくことは、耐久性やコストパフォーマンス、技術選定の自由度の高さといった点でも利点があると考えています。
今後の AWS の機能拡充にも期待しています。Iceberg への移行にあたり AWS の皆様には技術的な相談に乗っていただき感謝申し上げます。
著者
|
坂本 泰規(Taiki Sakamoto) 株式会社 AJA, データマネージメントチーム リーダー |
|
半場 光晴(Mitsuharu Hamba) アマゾンウェブサービスジャパン合同会社, ソリューションアーキテクト |

