Amazon Web Services ブログ
Tag: Analytics

AWS における AI エージェント対応のデータ基盤 (2) — SageMaker Catalog で行・列レベルのアクセス権を透過的に適用する
本記事は、シリーズ「AWS における AI エージェント対応のデータ基盤」の第 2 回です。第 1 回では、A […]

AWS における AI エージェント対応のデータ基盤 (1) — ツールを配る時代から、データを返す時代へ
AI エージェントに本番データを分析させるには、単にモデルと API をつなぐだけでは足りません。認可、ビジネ […]

NATO のマルチドメインオペレーションへの進展: ハイパースケールクラウドによる同盟の変革
本ブログは 2025 年 2月 21 日に公開された AWS Public Sector ブログ「NATO’s […]

Amazon MWAA における Apache Airflow 3 の紹介:新機能と機能拡張
本日、Amazon Web Services (AWS) は、Amazon Managed Workflows for Apache Airflow (Amazon MWAA) における Apache Airflow 3 の一般提供開始を発表しました。このリリースにより、組織がクラウド上でデータパイプラインやビジネスプロセスをオーケストレーションするために Apache Airflow を使用する方法が変革され、強化されたセキュリティ、改善されたパフォーマンス、そして最新のワークフローオーケストレーション機能がもたらされます。

ビジネスインテリジェンスの再解釈 : Amazon QuickSight から Amazon Quick Suite への進化
本記事では、Amazon QuickSight が Amazon Quick Suite へと進化することをお知らせします。これは、組織の全メンバーが包括的なビジネスインサイトを容易に活用できるようになるための大きな前進です。この進化により、Quick Research、Quick Flows、Quick Automate、Quick Index など、複数の AI 搭載機能が導入されます。これらの機能は、エンタープライズレベルのセキュリティとガバナンスを維持しながら、Quick chat を通じて利用できます。

Amazon QuickSight BIOps – パート2 : API を使用したバージョン管理
本記事は、2025年8月6日に公開された Amazon QuickSight BIOps – Part 2: […]

Amazon Finance Automationが重要な財務アプリケーションを動かすため、AWSの目的特化型データベースを使って業務データストアを構築した事例について
Amazon Finance Automation (FinAuto) は Amazon Finance Op […]
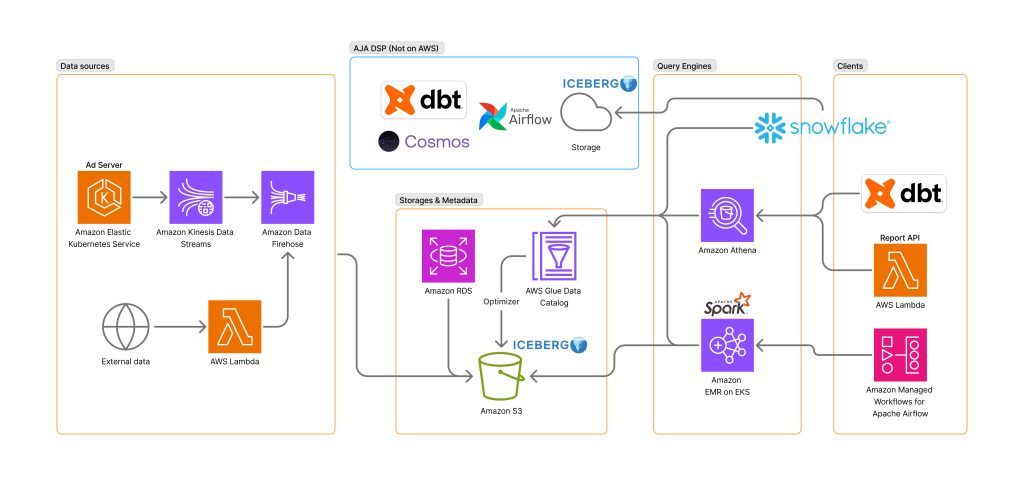
AJA SSP が Apache Iceberg と AWS Glue Data Catalog でペタバイトスケールのデータ基盤の柔軟なクエリエンジンの選択とクエリの高速化を実現
※ この記事はお客様に寄稿いただき、AWS が加筆・修正したものとなっています。 株式会社 AJA は、株式会 […]

Amazon MWAA v1.x から v2.x へのアップグレードのベストプラクティス
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) は、データ駆動型の意思決定をする組織にとって重要な基盤となっています。複雑なデータパイプラインを管理するためのスケーラブルなソリューションとして、Amazon MWAA は AWS サービスとオンプレミスのシステム間でシームレスなオーケストレーションを実現します。AWS がインフラストラクチャを管理していますが、お客様は責任共有モデルに従って Amazon MWAA 環境の更新を慎重に計画し実行する必要があります。

[教育業界向け] 手を動かしながら学ぶデータ分析ワークショップ [開催報告]
アマゾン ウェブ サービス ジャパン(以下、AWS)は 2025 年 5 月 30 日に、「 [教育業界向け] 手を動かしながら学ぶデータ分析ワークショップ」を AWS Startup Loft Tokyo にて開催しました。 近年、個別最適な学びと協働的な学びの実現に向けて教育業界におけるデータ分析の重要性が増しています。 本イベントでは、初等中等教育、EdTech のシステム構築に関わるベンダー、パートナー企業の方々をお招きし、教育業界におけるデータ利活用や AWS における実現方法に関して振り返りつつ、Amazon QuickSight を活用した教育データ分析ダッシュボードの構築を中心にハンズオンを体験していただきました。当日お集まりいただいた総勢 40 名以上の皆様には、改めて御礼申し上げます。本ブログではその開催報告をお届けします。