Amazon Web Services ブログ
Tag: Amazon Athena

Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetr […]

【寄稿】SIEMからデータ基盤へ – 三井物産デジタルアセットマネジメントのAWS Security Lake活用事例
こんにちは。ソリューションアーキテクトの松本 敢大です。三井物産デジタル・アセットマネジメント株式会社(以下、 […]

国防総省の演習において AWS がレジリエントかつセキュアなエッジトゥクラウドを実証
本ブログは 2025 年 4 月 24 日に公開された AWS Public Sector ブログ「AWS d […]
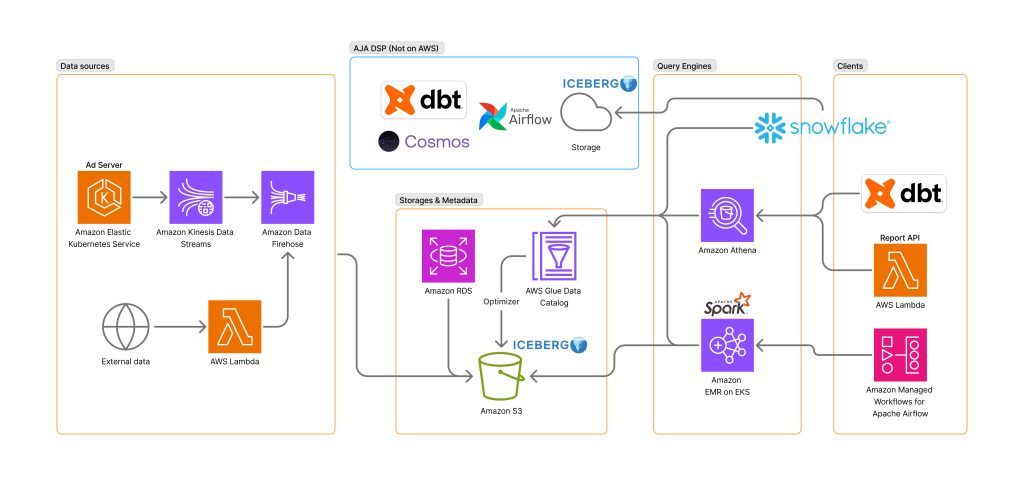
AJA SSP が Apache Iceberg と AWS Glue Data Catalog でペタバイトスケールのデータ基盤の柔軟なクエリエンジンの選択とクエリの高速化を実現
※ この記事はお客様に寄稿いただき、AWS が加筆・修正したものとなっています。 株式会社 AJA は、株式会 […]

Amazon Athena のパフォーマンスチューニング Tips トップ 10
Amazon Athena は、オープンソースのフレームワークに基づいた対話型分析サービスで、標準の SQL を使って Amazon Simple Storage Service (Amazon S3) に格納されたオープンテーブルおよびファイル形式のデータを簡単に分析できます。この投稿では、クエリのパフォーマンスを向上させるためのヒントのトップ10を紹介します。Amazon S3 へのデータ保存とクエリ特有のチューニングに関連する側面に焦点を当てます。
AWS でスケーラブルな IoT アナリティクスを実現
2024年7月25日をもってAWS IoT Analyticsへの新規顧客の利用を終了することを決定しました。 […]

Trusted Advisor Organizational Dashboard の詳しい概要
本ブログ投稿では、Cloud Intelligence Dashboards フレームワークの一部としてインタラクティブでカスタマイズ可能な Amazon QuickSight ダッシュボードテンプレートである Trusted Advisor Organizational (TAO) Dashboard を紹介します。統合された Trusted Advisor レポートを可視化することで、組織はすべての AWS アカウントにわたって、よりコスト効率の高い設定やより強固なセキュリティ体制、よりパフォーマンスに優れたアプリケーションに向けて最適化を行うことができます。
Amazon Athena を活用したスコープ 1 のカーボンフットプリント推定方法
現在、400 を超える組織が 2040 年までに温室効果ガス排出量実質ゼロを達成することを公約した The C […]

トランザクション処理可能なオープンテーブルフォーマット(OTF)のために Amazon Athena for Apache Spark と Spark SQL を活用する
Amazon Athena for Apache Spark は、インタラクティブに Spark プログラムを実行できるサーバーレスサービスです。この投稿では、Amazon Athena for Apache Spar を使って Apache Iceberg、Apache Hudi、Linux Foundation Delta Lake などのオープンソースのトランザクション処理可能なテーブルフォーマット (Open Table Format – OTF) を利用する方法をガイドします。

Amazon S3 におけるマルチテナント SaaS データのパーティション化と分離
多くの software-as-a-service (SaaS)アプリケーションはマルチテナントデータを Amazon Simple Storage Service(Amazon S3) に保存しています。Amazon S3 にマルチテナントデータを配置するには、バケットとキーにテナントデータをどのように分散させるかを考える必要があります。また、SaaS ソリューションのセキュリティ、管理性、パフォーマンスを損なうことなく行う必要があります。この記事では、 Amazon S3 でテナントデータをパーティション化する際に適用できるさまざまな戦略を説明します。