Amazon Web Services ブログ
Amazon Managed Streaming for Apache Kafka (MSK) – 一般利用可能
お客様がストリーミングデータを使用している様子を見て、いつも驚いてしまいます。たとえば、ビジネスと専門分野で世界で最も信頼されるニュース会社の 1 つである Thomson Reuter は、分析データを取り込み、分析し、可視化して、製品チームが継続的にユーザーエクスペリエンスを向上させるのを支援しています。Hay Day、Clash of Clans、Boom Beach などのゲームを提供するソーシャルゲームの会社である Supercell は、1 日あたり 450 億のイベントを処理するリアルタイムのゲーム内データ配信を行っています。
re:Invent 2013 で当社は Amazon Kinesis をローンチして以来、顧客が AWS 上でストリーミングデータを操作する方法を継続的に拡大してきました。いくつかの利用可能なツールには、次のものがあります。
- Kinesis Data Streams。固有のアプリケーションでデータストリームを取り込み、保存し、処理します。
- Kinesis Data Firehose。, データを変換し、 Amazon S3、Amazon Elasticsearch Service、および Amazon Redshift などの保存先に収集します。
- Kinesis Data Analytics。SQL または Java (Apache Flink アプリケーション経由) を使用して継続的にデータを分析します。たとえば、異常を検出したり、時系列集約のために使用するためなどです。
- Kinesis Video Streams。メディアストリームの処理を簡素化します。
re:Invent 2018 では、私達はオープンプレビューで Amazon Managed Streaming for Apache Kafka (MSK) を紹介しました。これは、ストリーミングデータを処理するために容易に Apache Kafka を使用するアプリケーションを構築し、実行することを可能にする完全に管理されたサービスです。
私は、Amazon MSK が一般公開されたことをお伝えできて大変うれしく思います。
仕組みの説明
Apache Kafka (Kafka) は顧客がクリックストリームイベント、トランザクション、IoT イベント、アプリケーション、マシンログなどのストリーミングデータを取り込むことを可能にし、リアルタイムの分析を実行し、継続的な変換を実行し、このデータをデータレイクやデータベースにリアルタイムで配布するアプリケーションを有するオープンソースのプラットフォームです。 ストリーミングデータストアとして Kafka を使用して、ストリーミングデータを作るアプリケーション (producers) をストリーミングデータを消費するアプリケーション (consumers) から切り離すことができます。
Kafka は代表的なエンタープライズデータストリーミングおよびメッセージングのフレームワークですが、本番稼働でセットアップ、スケール、および管理することが困難な場合があります。 Amazon MSK は、これらの管理タスクを行い、以下の高可用性とセキュリティのためのベストプラクティスに従った環境で、Apache ZooKeeper とともに、Kafka のセットアップ、設定、および実行することを容易にします。
MSK クラスタは常にMSK サービスにより管理される Amazon VPC の中で実行されます。MSK リソースは、次の建築図面に記載されているように、自分のアカウントに表示される Elastic Network Interfaces (ENI) を通じて、自分自身の VPC、サブネット、セキュリティグループが利用できるようになります。
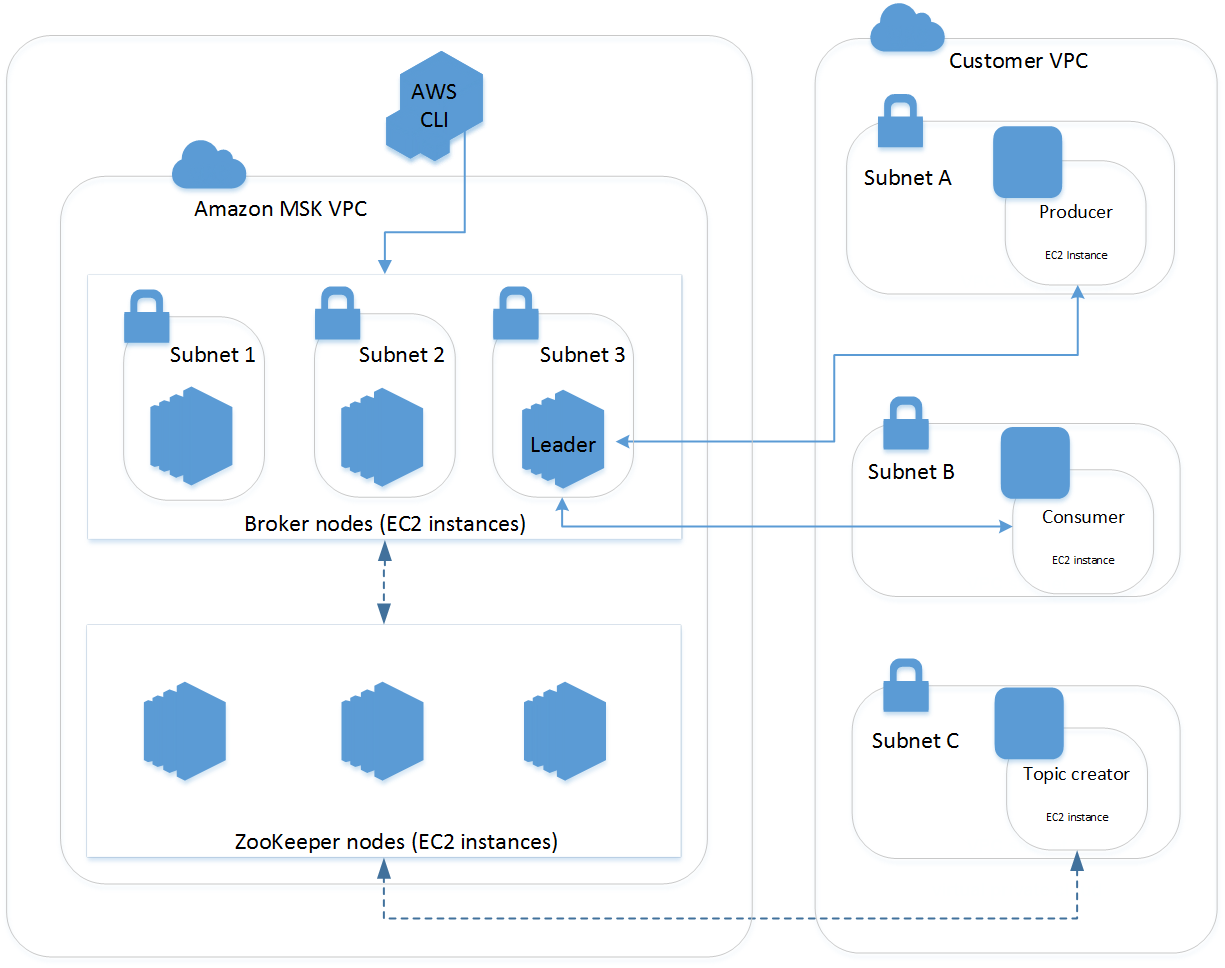
顧客は数分でクラスターを作成でき、AWS Identity and Access Management (IAM) を使用してクラスターアクションをコントロールし、AWS Certificate Manager (ACM)により完全に管理された TLS 民間証明機関を使用してクライアントを認可し、AWS Key Management Service (KMS) 暗号キーを使用して保存データを暗号化できます。
Amazon MSK は継続的にサーバーの健全状態を監視し、サーバーが故障したときにサーバーを交換し、サーバーパッチングを自動化し、サービスの一部として追加費用なしで高可用性の ZooKeeper ノードを運用します。Key Kafka パフォーマンスメトリックは、コンソールと Amazon CloudWatch で発行されます。Amazon MSK は、Kafka バージョン 1.1.1 および 2.1.0 と完全に互換性があるため、お使いのアプリケーションの実行を続行し、Kafka 互換ツールとフレームワークをコードを変更せずに、使用できるようになります。
オープンプレビュー中の顧客のフィードバックに基づいて、Amazon MSK は次のような特長を備えています。
- クライアントとブローカーの間、ブローカー間のTLS経由の転送中の暗号化
- ACM 民間証明機関を使用した相互 TLS 認証
- Kafka バージョン 2.1.0 のサポート
- 可用性 99.90% の SLA
- HPAA 対応
- クラスター全体のストレージ スケール拡大
- MSK API ロギングのためのAWS CloudTrade の統合
- クラスター タギングとタグベースの IAM ポリシーアプリケーション
- トピックとブローカーのためのカスタムのクラスター全体の設定の定義
AWS CloudFormation サポートは今後数週間で利用可能になります。
クラスターの作成
AWS マネジメントコンソールを使用したクラスターを作成しましょう。クラスターに名前を付け、クラスターを使用する VPC と Kafka のバージョンを選択します。

次に、アベイラビリティーゾーン(AZ)、VPS で使用するための対応するサブネットを選択します。次の手順では、各 AZ にデプロイする Kafka ブローカーの数を選択します。より多くのブローカーが、異なるブローカーにパーティションを割り当てることで、クラスターの処理量を拡大できるようにしています。

自分のリソースを検索し、フィルタリングするためのタグを追加し、Amazon MSK API に IAM ポリシーを適用し、コストを追跡します。ストレージについては、1 ブローカー当たりのデフォルトのストレージ容量サイズのままにします。
クラスター内で暗号化を使用し、クライアントとブローカー間ではTLS とプレーンテキスト トラフィックの両方を許可することを選択します。保存データについては、AWS 管理対象顧客ま⒮jターキー(CMK)を使用しますが、KMS を使用して、さらにコントロールするために、アカウントで CMK を選択できます。プライベート TLS 証明書を使用して、クラスターに接続するクライアントのアイデンティティを認証できます。この機能は、ACM から民間認証機関(CA)を使用しています。現時点について、このオプションは選択しないでおきます。

高度な設定は、デフォルト値のままにします。たとえば、ここで私のブローカーに異なるインすタンスタイプを選択することもできました。これらの設定の中には、AWS CLI を使用して更新できるものもあります。
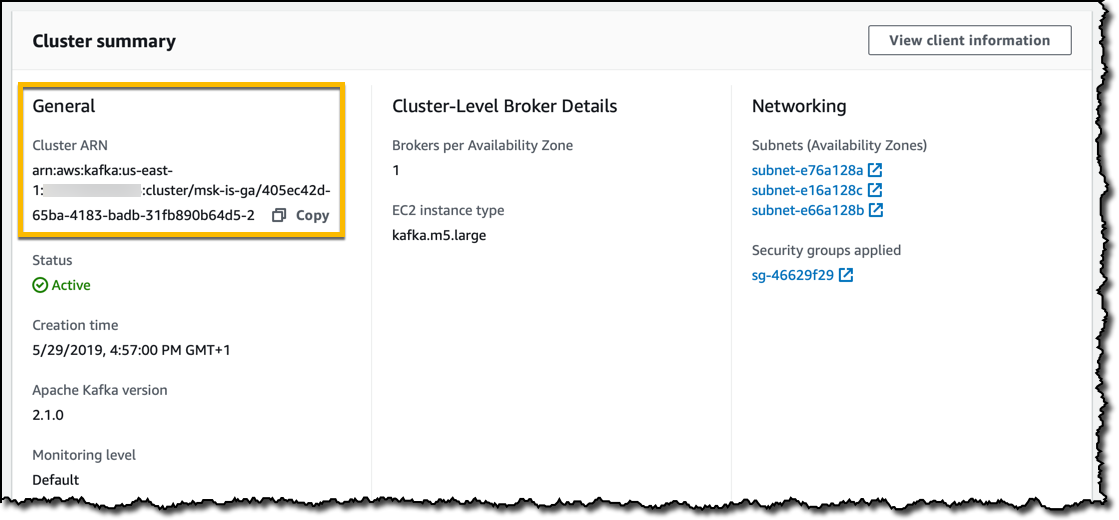
クラスターを作成し、CLI または SDK 経由でインターラクションするときに使用できる Amazon Resource Name (ARN) を含む、クラスターサマリーからステータスを監視します。
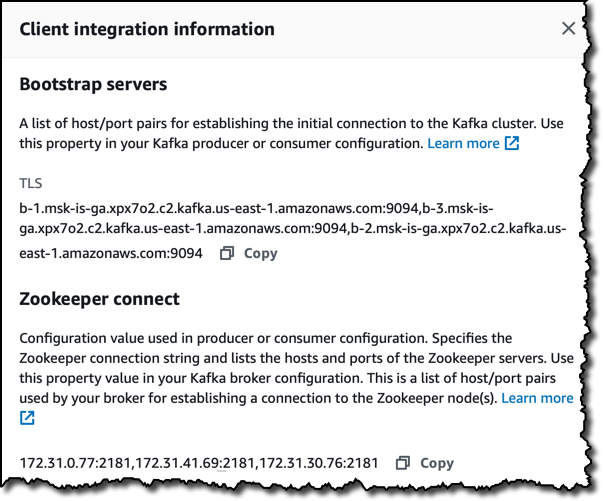
ステータスがアクティブのときに、クライアント情報セクションでは、次のようなクラスターに接続するための特定の詳細情報を示します。
- ブートストラップサーバーは、Kafka ツールを使用して、クラスターに接続できます。
- Zookeeper は、ホストとポートのリストを接続します。
AWS CLI を使用して同様の情報を得ることができます。
aws kafka list-clustersにより、特定リージョンのクラスターの ARN を確認しますaws kafka get-bootstrap-brokers --cluster-arn <ClusterArn>を使用して、Kafka ブートサーバーを取得しますaws kafka describe-cluster --cluster-arn <ClusterArn>を使用して、Zookeeper 接続文字列を含むクラスターの詳細を確認します
Kafka の使用の簡単なデモ
Kafka の使用を開始するために、同じ VPC で 2 つの EC2 インスタンスを作成します。1 つは producer で、もう1 つは consumer です。クライアントマシンとして設定するために、Apache ウェブサイトから、またはミラーから Kafka ツールをダウンロードし、展開しました。 Kafka を実行するには Java 8 が必要なので、Amazon Corretto 8 をインストールします。
producer のインスタンスでは、Kafka ディレクトリで、データを producer から consumer に送信するためにトピックをさk受精します。
bin/kafka-topics.sh --create --zookeeper <ZookeeperConnectString> \
--replication-factor 3 --partitions 1 --topic MyTopic
次に、コンソールベースの producer を開始します。
bin/kafka-console-producer.sh --broker-list <BootstrapBrokerString> \
--topic MyTopic
Kafkaディレクトリの consumer インスタンスでは、コンソールベースの consumer を開始します。
bin/kafka-console-consumer.sh --bootstrap-server <BootstrapBrokerString> \
--topic MyTopic --from-beginning
ここで、トピックを作成し、producer(最上部のターミナル)からそのトピックの consumer (最下部のターミナル)にメッセージを送信する簡単なデモの録画を示します。

料金と可用性
価格は Kafka ブローカー時間ごと、およびプロビジョニングしたストレージ時間ごとに設定されています。お使いのクラスターで使用される Zookeeper ノードにはコストがかかりません。 AWS データ転送速度は、MSK から出入りするデータ転送に適用されます。ブローカー間のデータ転送およびブローカーとZooKeeper ノード間のデータ転送を含む、リージョンのクラスター内のデータ転送に対する請求はありません。
(オープンソース Kafka に同梱される) MirrorMaker などのツールを使用して、クラスターから MSK クラスターにデータを複製するために、既存の Kafka クラスターを MSK に移行することができます。
上位互換は、Amazon MSK の中核となる理念です。Kafka プラットフォームのコード変更は、オープンソースにリリースされます。
Amazon MSK は米国東部 (バージニア北部)、米国東部 (オハイオ)、米国西部 (オレゴン)、アジアパシフィック (東京)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、 欧州 (フランクフルト)、欧州 (アイルランド) 、欧州 (パリ)、欧州 (ロンドン) で利用できます。
ストリーミングアプリケーションを構築してクラウドに移行するために、Amazon MSK を使用する方法を確認するのを楽しみにしています。