Amazon Web Services ブログ
Amazon Neptune – フルマネージドのグラフデータベースサービス
現代の生活を可能にするために必要な全てのデータ構造やアルゴリズムの中でも、グラフは日々世界を変えています。ビジネスからは、複雑な関係性を持つリッチなデータが生まれ続け、また取り込まれ続けています。しかし開発者は未だにトラディショナルなデータベースの中でグラフのような複雑な関係性を扱うことを強要されています。必然的に、そのような関係性-リレーションシップが追加されるにつれ、パフォーマンスは劣化し、いらいらするくらい高コストで複雑なクエリとなっていきます。我々はそのようなモダンで複雑性が日々高まるようなデータセットやリレーションシップ、パターンを簡単に扱えるようにしたいと考えました。
Hello, Amazon Neptune
2017年11月29日、我々は限定プレビュー版のAmazon Neptuneを発表します。Amazon Neptuneにより、高度に接続されたデータセット間のリレーションシップから簡単に洞察を得ることができます。Neptuneのコア部分は、数十億ものリレーションシップが格納可能で、グラフに対してミリ秒レベルの遅延となるよう最適化された、専用の、高性能なグラフデータベースエンジンです。フルマネージドなデータベースとして提供されることで、Neptuneはお客様をメンテナンスやパッチ適用、バックアップ/リストアなどの退屈なオペレーションから解放し、アプリケーションに集中できるようにします。高速なフェイルオーバー、Point-in-Timeリカバリ、そしてマルチAZでの実装など高可用性のための各種機能も備えるサービスです。最大15個のリードレプリカによりクエリのスループットを秒間10万件レベルまでスケールさせることも可能です。Amazon NeptuneはAmazon VPC内で動作し、データを暗号化して保管でき、保管時や転送時にデータの整合性について完全に制御することができます。

このサービスにはたくさんの興味深い機能があるのですが、グラフデータベースというのは多くの方々にとってあまりなじみのないトピックかもしれません。そこで、まず理解する上で大切ないくつかの単語についてご紹介しましょう。
グラフデータベースとは
グラフデータベースは、頂点(ノード)と辺(エッジ、リレーションシップや接続)を、Key-Valueペアとして保持されるプロパティと共に格納します。グラフデータベースは、互いに接続され、複雑なコンテキストを持つ、互いの関係性を基にするデータにとても有効です。SNS、レコメンデーションエンジン、経路案内、物流最適化、自動診断、侵入検知やゲノム配列決定などのアプリケーションが例に挙げられます。
Amazon Neptuneは、グラフの表現と問い合わせのために、2つのオープンな業界標準をサポートします。
- Gremlinによって問合せ可能なApache TinkerPop3互換のプロパティグラフ。Gremlinはノード(頂点)につながるエッジ(辺)を個別にたどる探索を実現するグラフ探索言語です。
- SPARQLによって問合せ可能な RDF (Resource Description Framework)。SPARQLはW3Cによって提言されている標準の1つであるSemantic Webに基づいた宣言型言語です。subject (主語) → predicate (述語) → object (目的語) というモデルに基づいています。Neptuneは特に次の標準をサポートします:RDF1.1、SPARQL Query 1.1、SPARQL Update 1.1、SPARQL Protocol 1.1。
もしSPARQLやTinkerpPopで動作する既存のアプリケーションがあるのなら、Neptuneを使うための作業は単にアプリケーションの接続先エンドポイントをNeptuneを使うように変更するだけです。
さてそれではAmazon Neptuneの世界へ踏み出していきましょう。
Amazon Neptuneを起動してみよう
Neptuneのコンソール画面から “Launch Neptune” をクリックすることで、起動ウィザードが開始されます。

最初の画面では単にインスタンスに名前をつけてインスタンスタイプを選択するだけです。
次の画面では詳細なオプションを設定します。多くのオプションは、以前にAWSで Amazon Relational Database Service (RDS) や Amazon ElastiCache のようなインスタンスベースのデータベースサービスを利用したことがあれば、どこかで見たことのあるようなものでしょう。
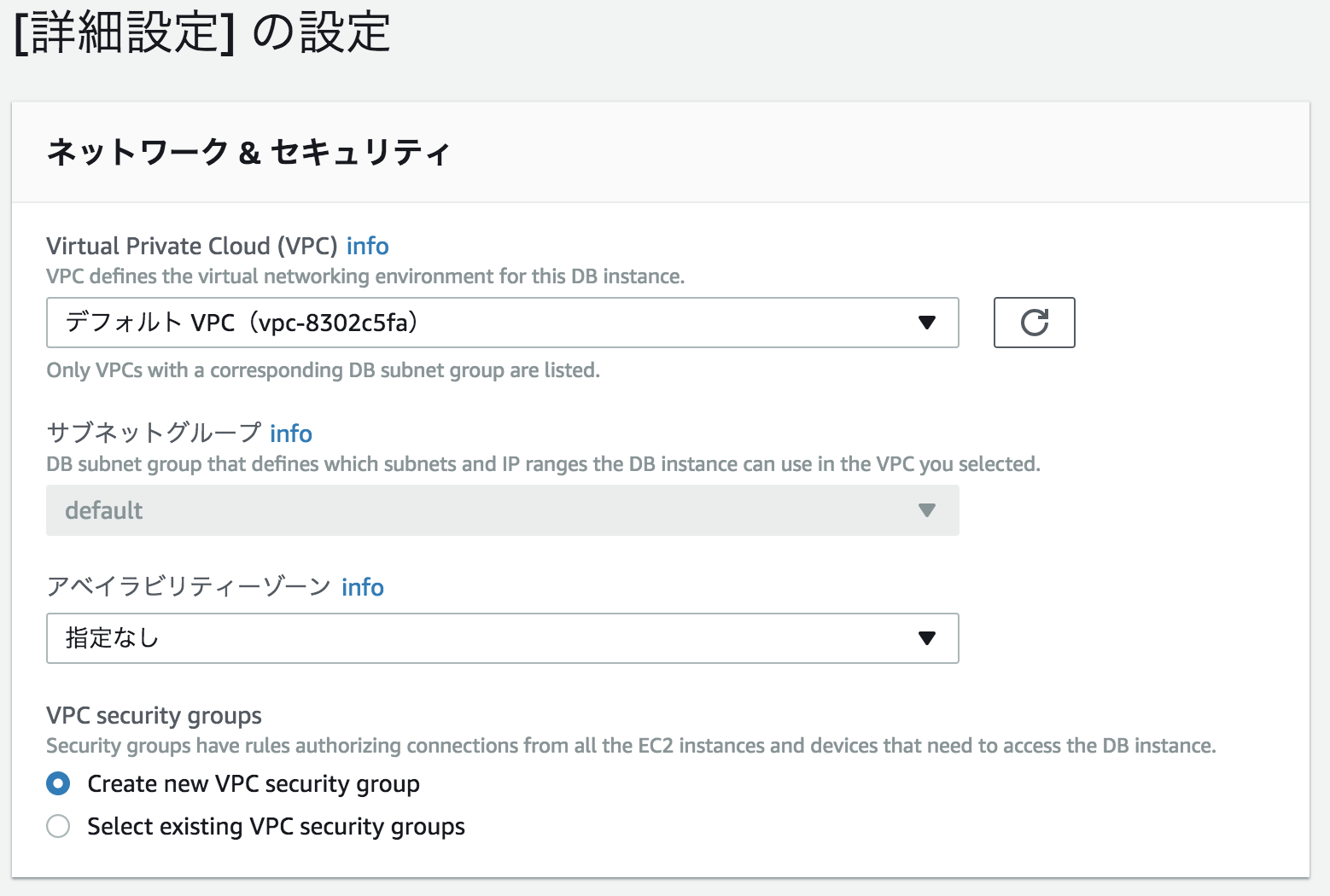
Amazon NeptuneはVPC内でセキュアに実行され、セキュリティグループにより簡単に特定のEC2インスタンスからのアクセス権を与えられます。

「データベースの設定」では、パラメータグループやポート、クラスター名などの追加のオプションを設定できます。

次の部分ではKMSベースの保存データの暗号化、フェイルオーバーの優先度、そしてバックアップの保存期間を設定できます。

RDSと同様、データベースのメンテナンスはサービス側で制御されます。
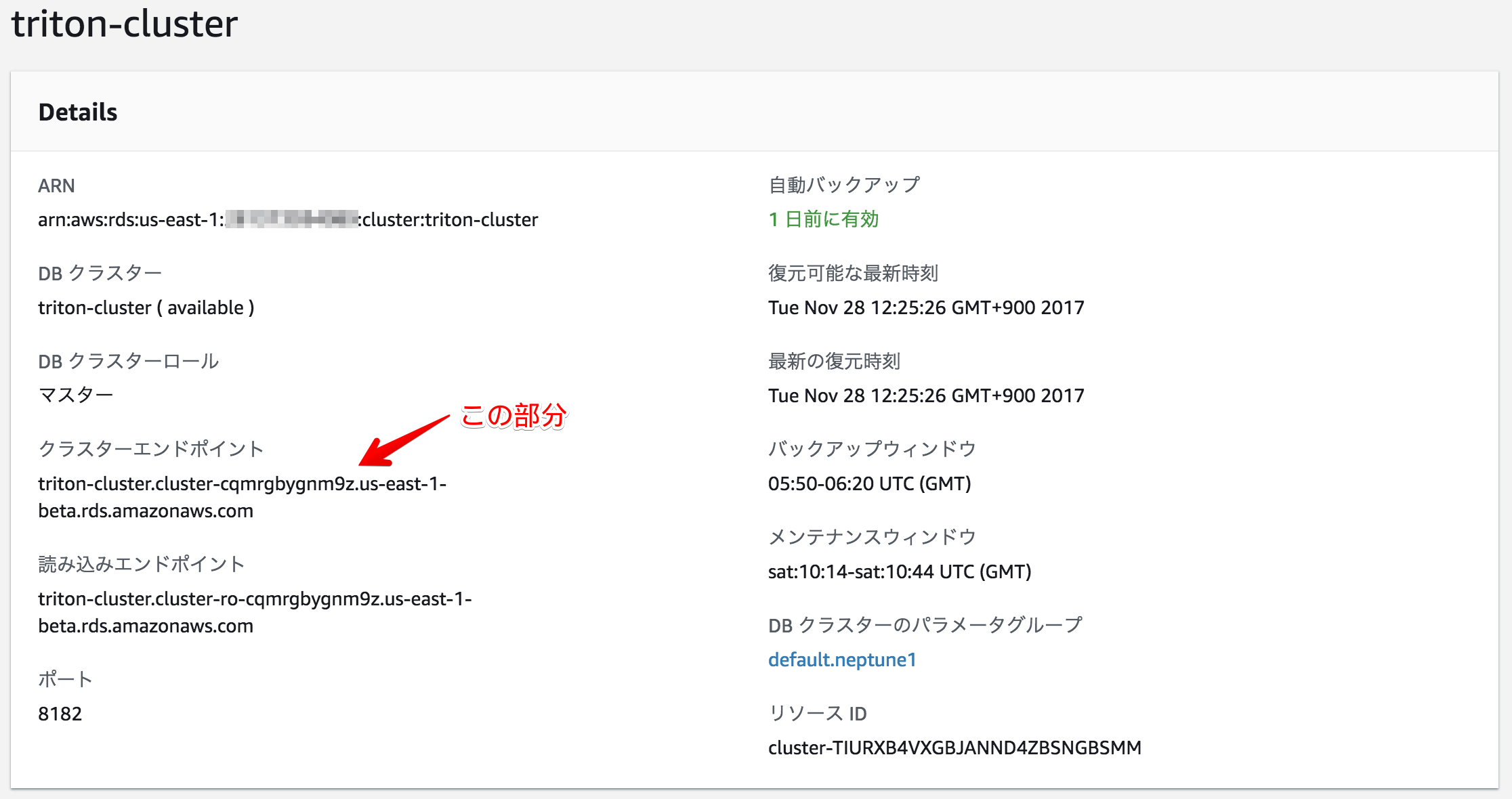
いったんインスタンスのプロビジョニングが完了すると、クラスターの詳細ページで接続エンドポイントを見つけることができます。私の場合は以下のようになります。
Amazon Neptuneを使ってみよう
前述のように、Amazon Neptuneでは2つの異なるクエリエンジンを使用できます。
Gremlinのエンドポイントに接続するには、次のようにクラスターのエンドポイントに/gremlinを付ければOKです。
同様に、SPARQLのエンドポイントに接続するには/sparqlを付けます。
(訳注:httpsで接続するためには事前にSSLの設定が必要となります)
クエリを実行する前にデータベースを作成する必要があります。ここではAWS re:Inventのモデルを作成し、それをバルクロードAPIを用いてデータベースにインサートすることを考えます。プロパティグラフの場合、Neptuneはノード、ノードのプロパティ、エッジ、そしてエッジのプロパティをデータとして持つ Amazon Simple Storage Service (S3) 上のCSVファイルをロードできます。
典型的なノード用のCSVファイルは以下のようになります。
また、エッジ用のCSVファイルは以下のようになります。
同様の形式のCSVファイルをNeptuneにロードするために実行するコマンドは以下のようになります。
次のように返されるはずです。
この結果を元に、ロードのステータスを確認することができます。
ノードと同様にエッジについても、この独自のデータフォーマット形式でのローディング作業を行うことになります。
RDFについては、Neptuneは4つのデータフォーマット形式 – Turtle、N-Triples、N-Quads、そしてRDS/XML – をサポートします。これらはすべて同じローディングAPIでロードすることができます。
ここまでで、データベースにデータが格納され、いくつかのクエリを実行することができるようになります。Gremlinでは、Graph Traversals – グラフ探索 – としてクエリを記述します。私は Paul McCartney のファンなので、彼が出席するすべてのセッションを探したいと思います。
このコードはまず、”Paul McCartney”という値の”name”プロパティを持つすべてのノード(1人だけです!)を探索します。次に、そのノードからの”attends”型のエッジを探索し、その先に繋がるノードのIDを結果として返します。
どうやらPaulは忙しそうですね。
本記事ではグラフデータベースができることの大まかな概要を述べてきましたが、いかがでしたでしょうか? グラフデータベースは多くのお客様に対して多くの新たな可能性を切り拓くものであり、Amazon Neptuneによって巨大なデータでも格納し、クエリを実行することが容易になります。私は、我々のお客様により作り上げられた驚くべき新サービスを見て非常に興奮しています。
– Randall (本記事はSAの五十嵐が翻訳しました。原記事はこちら)
追記:本記事を執筆するにあたり多大な支援を受けたBrad BebeeとDivij Vaidyaに感謝します!