Amazon Web Services ブログ
Amazon S3 クライアントを使用した ML トレーニングにおけるデータ読み込みベストプラクティスの適用
Amazon Simple Storage Service (Amazon S3) は、アプリケーションの需要に応じて自動的にスケールする弾力性のあるサービスで、最新の ML ワークロードに必要な高スループットパフォーマンスを提供します。Amazon S3 Connector for PyTorch や Mountpoint for Amazon S3 などの高性能クライアントコネクタは、S3 REST API を直接扱うことなく、トレーニングパイプラインにネイティブな S3 統合を提供します。
この記事では、Amazon S3 汎用バケットから直接データを読み取る ML トレーニングワークロードのスループットを最適化するための実用的な技術と推奨事項を紹介します。ここで説明するデータ読み込み最適化技術の多くは、さまざまなストレージ基盤に広く適用できます。
これらの推奨事項を検証するため、代表的なコンピュータビジョン (CV) 学習ワークロード、具体的には数万の小さな JPEG ファイルを使用した画像分類タスクをベンチマークしました。S3 バケットからの複数のデータアクセスパターンを評価し、Amazon S3 Connector for PyTorch や Mountpoint for Amazon S3 を含むさまざまな S3 クライアントのパフォーマンスを比較しました。
調査結果によると、データセットを適切なサイズ (通常 100 MB ~ 1 GB) のデータシャードに統合し、シーケンシャルアクセスパターンと組み合わせることで、大幅に高いスループットが得られます。頻繁にアクセスされる学習データをキャッシュすることで、マルチエポック学習シナリオの効率がさらに向上します。最後に、評価した S3 クライアントの中で、Amazon S3 Connector for PyTorch が一貫して最高のスループットを達成し、S3 のデータアクセスに一般的に使用される他の方法を上回りました。
ML トレーニングパイプラインのパフォーマンスボトルネック
GPU は ML 計算の高速化に重要な役割を果たしますが、学習は相互に依存するいくつかの段階を持つ多面的なプロセスであり、そのいずれもがボトルネックになる可能性があります。以下の図は、典型的なエンドツーエンドの学習パイプラインを示し、これらの段階がどこで発生するかを強調しています。学習アルゴリズム、モデルアーキテクチャ、実装の詳細、ハードウェアなどの要素はすべて重要ですが、学習ワークロードを以下の 4 つの繰り返し高レベルステップを持つパイプラインとして考えると便利です。
- 学習サンプルの読み取り – 永続ストレージからメモリへ
- 学習サンプルの前処理 – デコード、変換、拡張などのステップをメモリ内で実行
- モデルパラメータの更新 – GPU 間で計算および同期された勾配に基づいて実行
- 学習チェックポイントの保存 – 障害発生時に最新の状態から学習を再開できるようにするため、定期的に実行
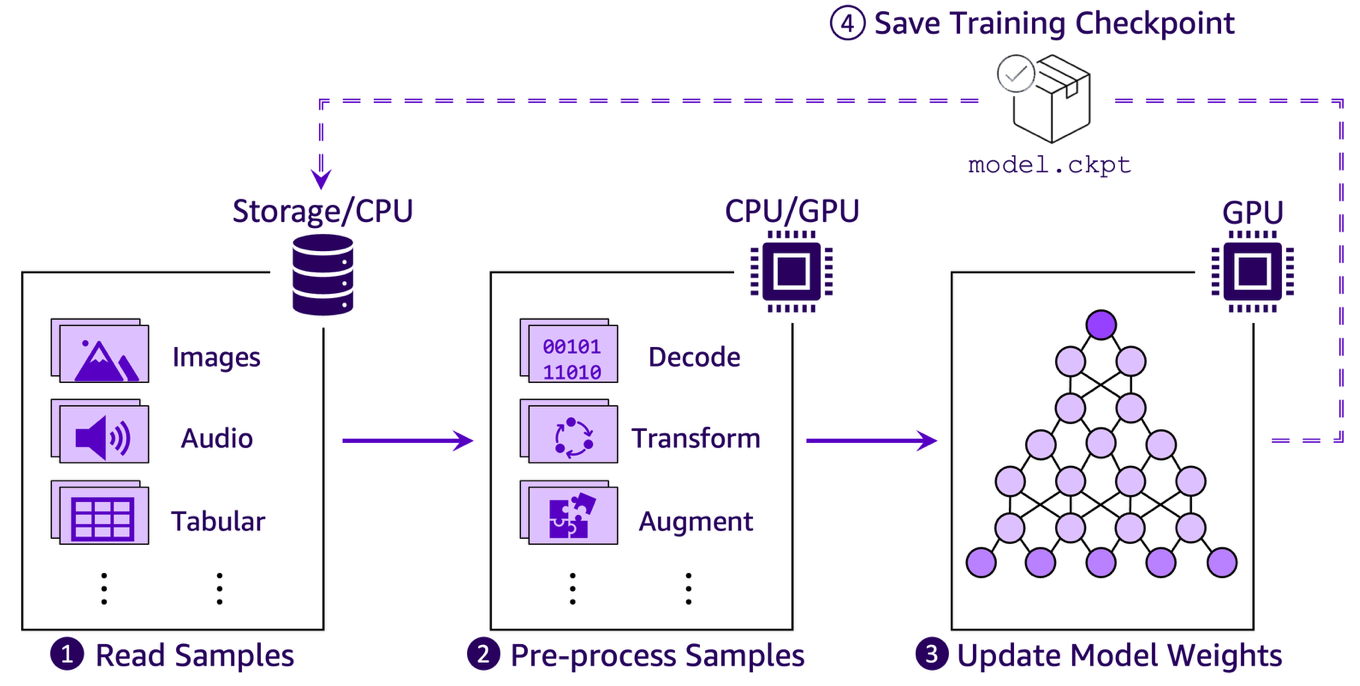
ML トレーニングパイプラインの実効スループットは、最も遅いステップによって制約されます。ステップ 3 (モデル更新の実際の計算) が最終的に重要ですが、クラウドベースの ML ワークロードには独自の課題があります。通常、コンピューティングとストレージリソースが設計上分離されているクラウド環境では、データ入力パイプライン (ステップ 1 ~ 2 )が重大なボトルネックとして頻繁に現れます。チェックポイント処理 (ステップ 4) も全体的な学習効率に影響を与える可能性がありますが、この記事では取り上げません。
最新の GPU でも、処理するデータを待ってアイドル状態になっている場合、学習を加速できません。データ待ち時間が発生すると、より強力なコンピューティングハードウェアへ追加投資しても非効率であり、本番環境では高コストになります。最大の GPU 使用率を達成するには、GPU が継続的に学習データを処理できるように、データパイプラインを慎重に最適化する必要があります。
データ読み込みの課題
Amazon S3 からのデータ読み込みパフォーマンスに影響を与える最も重要な要素の 1 つは、学習中にデータがアクセスされるパターンです。特に、データ読み取り方法がシーケンシャルかランダムかによって、全体的なスループットとレイテンシーは大きく影響を受けます。これらのアクセスパターンが Amazon S3 の基礎特性とどのように相互作用するかを理解することが、効率的な入力パイプラインを設計するための鍵となります。
Amazon S3 上の ML ワークロードにおけるシーケンシャル読み取りとランダム読み取り
Amazon S3 からのデータ読み取りは、機械式アクチュエータアームを持つ従来のハードディスクドライブ (HDD) の動作に例えることができます。以下の図が示すように、HDD はデータブロックが連続して配置されている場合、アクチュエータアームの移動を最小限に抑えてシーケンシャルにデータを読み取ります。対照的に、ランダム読み取りでは、アクチュエータアームがディスク表面を飛び越えて散在するブロックにアクセスする必要があり、アームの物理的な再配置による遅延が発生します。

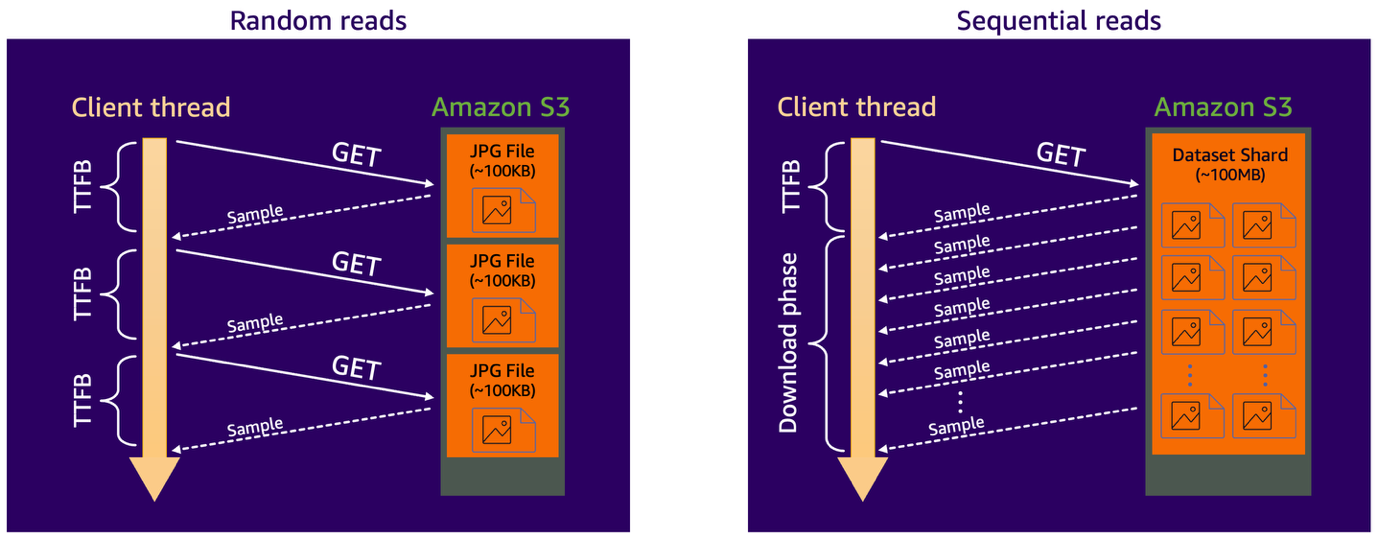
Amazon S3 上のデータにアクセスする際、状況は HDD の例にやや似ています。正確には、各 S3 リクエストは実際のデータ転送が始まる前に最初のバイトまでの時間 (TTFB) オーバーヘッドが発生します。このオーバーヘッドは、接続の確立、ネットワークラウンドトリップレイテンシー、S3 の内部操作 (データの場所の特定やディスクへのアクセスなど)、クライアント側のレスポンス処理など、いくつかのコンポーネントで構成されます。データ転送時間自体は取得されるデータのサイズに応じてスケールしますが、S3 GET リクエストの TTFB オーバーヘッドは主に固定されており、データオブジェクトのサイズとは独立しています。これを以下の図が示しています。
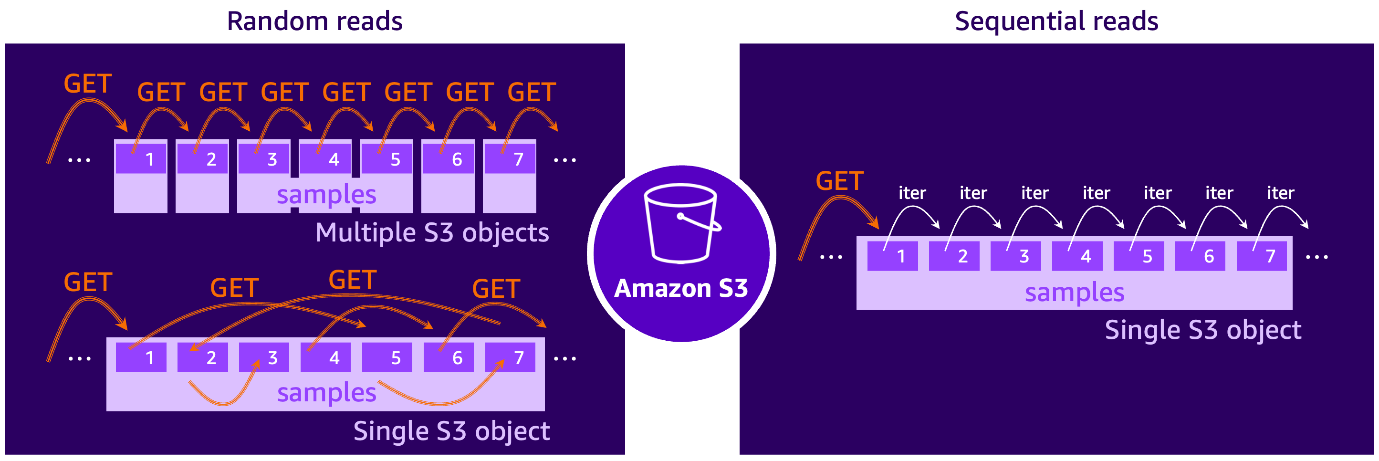
ML ワークロードを議論する際の HDD のアナロジーに従えば、例えばデータセットが S3 に保存された多数の小さなファイルで構成され、各ファイルに単一の学習サンプルが含まれている場合、クラウドストレージからのランダム読み取りパターンがあると言えます。あるいは、学習スクリプトが例えばバイト範囲の S3 GET リクエストを使用して、より大きなファイルシャード内のさまざまな部分からサンプルを取得する場合にも、ランダム S3 アクセスが発生します。これは、YouTube ビデオをシーンを前後にスキップしながら視聴するのに似ています。
逆に、データセットが大きなファイルシャードに整理され、各シャードに多くの学習サンプルが含まれ、それらを次々とシーケンシャルに反復できる場合、シーケンシャル読み取りパターンが発生します。この場合、単一の S3 GET リクエストで複数のサンプルを取得でき、ランダム読み取りシナリオよりもはるかに高いデータスループットが可能になります。このアプローチはデータのプリフェッチも効率化します。次のサンプルバッチを予測し、取得してメモリにバッファリングできるため、GPU がすぐに利用できる状態になります。
スループットへの影響の分析:コンピュータビジョンのケーススタディ
さまざまなデータアクセスパターンがパフォーマンスにどのように影響するかをよりよく理解するために、データセットが多くの比較的小さな画像ファイル (各約 100 KB) で構成されるコンピュータビジョンタスクの 2 つのシナリオを見てみましょう。最初のシナリオでは、データセットはそのまま Amazon S3 Standard ストレージクラスに保存され、学習スクリプトは各画像をオンデマンドで取得します。これにより、各学習サンプルが独自の S3 GET リクエストを必要とするランダム読み取りアクセスパターンが作成されます。S3 Standard の TTFB レイテンシーは数十ミリ秒のオーダーであり、小さなファイルの実際のダウンロード時間はそれに比べて最小限であるため、データローダーのパフォーマンスはレイテンシーバウンドになります。つまり、クライアントスレッドはデータの到着を待っている間、ほとんどの時間をアイドル状態で過ごします。
2 番目のシナリオでは、データセットは S3 に保存される前に、より大きなファイルシャード(例えば各約 100 MB) に統合されます。これで、データローダーは単一の S3 GET リクエストで複数の学習サンプルをシーケンシャルに読み取ります。これにより、ワークロードは帯域幅バウンドにシフトし、サンプルごとの TTFB 影響が除去され、ダウンロードフェーズ中の連続サンプルの効率的なストリーミングが可能になります。
Amazon S3 からのデータ読み込みの最適化技術
S3 からの ML ワークロード用のランダムおよびシーケンシャルデータアクセスパターンについて説明したので、実際にデータ取り込みパイプラインを最適化する方法を見ていきましょう。
S3 向けに最適化された高性能ファイルクライアントの使用
利用可能なオプションが豊富であることを考えると、パフォーマンスの高い S3 ファイルクライアントを選択することは困難です。これに対処するため、2023 年に AWS は S3 用の 2 つのネイティブオープンソースクライアント、Mountpoint for Amazon S3 と Amazon S3 Connector for PyTorch を導入しました。両方とも AWS Common Runtime (CRT) 上に構築されており、CRT はリクエストの並列化、タイムアウト、リトライ、接続の再利用などのベストプラクティスのパフォーマンス最適化を実装するネイティブ S3 クライアントを含む、高度に最適化された C ベースのプリミティブのコレクションです。これにより、お客様は最小限の労力で最大の S3 スループットを達成できます。
Mountpoint for Amazon S3 は、コンピューティングインスタンスに S3 バケットをマウントし、既存のコードを変更することなくローカルファイルシステムとしてアクセスできるオープンソースのファイルクライアントです。これにより、ML トレーニングを含む幅広いワークロードに適しています。
Kubernetes 環境では、Mountpoint for Amazon S3 Container Storage Interface (CSI) Driver が S3 バケットをストレージボリュームとして提示することでこの機能を拡張し、コンテナが使い慣れたファイルシステムインターフェースを通じて S3 オブジェクトにアクセスできるようにします。最近リリースされた Mountpoint for Amazon S3 CSI v2 では、ドライバーはポッド間の共有キャッシングも導入しており、分散 ML ワークロードがローカルにキャッシュされたデータを再利用できるため、パフォーマンスとリソース効率の両方が向上します。CSI ドライバーは、あらゆる Kubernetes ベースのアプリケーションと互換性があり、Amazon Elastic Kubernetes Service (Amazon EKS) と統合でき、そこでは合理化されたインストールとライフサイクル管理のためのマネージドアドオンとして利用できます。
Amazon S3 Connector for PyTorch は、PyTorchのための、S3 と学習パイプラインを密接に連携できる機能です。この統合により、学習データへの高スループットアクセスと、Amazon S3 への直接的な効率的なチェックポイント処理が可能になります。学習データの読み取りやモデルチェックポイントの書き込み時に、パフォーマンス最適化を自動的に適用します。
コネクタは、ランダムアクセス用のマップスタイルデータセットと、シーケンシャルアクセスをストリーミングするための反復可能スタイルデータセットの両方をサポートしており、さまざまな ML 学習パターンに適しています。また、ローカルストレージに依存せずに S3 からチェックポイントを保存および読み込むことができる組み込みのチェックポイントインターフェースも含まれています。インストールは簡単 (例えば pip を使用) で、コネクタは追加のファイルシステムクライアントや複雑なシステムセットアップを必要とせず、GitHub で実証されているように、学習コードへの最小限の変更のみが必要です。
データセットのシャード化とシーケンシャル読み取りパターンの使用
S3 からのデータ読み込みを最適化するための効果的な戦略は、データセットを各々に多くの学習サンプルを含む、より少数のより大きなファイルシャードにシリアル化し、データローダーを使用してそれらのサンプルをシーケンシャルに読み取ることです。S3 micro-benchmark では、100 MB ~ 1 GB のシャードサイズが通常、優れたスループットを提供しました。ただし、理想的なサイズはワークロードによって異なる場合があります。小さなシャードはプリフェッチバッファからの準ランダムサンプリング動作を改善でき、大きなシャードは一般的により良いスループットを提供します。
シャード化の一般的なファイル形式には、tar (WebDataset などのライブラリを通じて PyTorch で頻繁に使用されます)と TFRecord (TensorFlow で tf.data と共に使用されます) があります。とはいえ、データのシャード化はシーケンシャル読み取りを保証するものではありません。データローダーがシャード内のサンプルにランダムにアクセスする場合 (Parquet や HDF5 などの形式で一般的)、シーケンシャルアクセスの利点が失われる可能性があります。パフォーマンス向上を完全に実現するには、各シャード内のサンプルが順番に読み取られるようにデータローダーを設計することをお勧めします。
トレーニングサンプルの並列化、プリフェッチ、キャッシング
ML パイプラインのデータ取り込みおよび前処理段階の最適化は、学習スループットの最大化、特にランダムデータアクセスパターンが避けられない場合に重要です。並列化、プリフェッチ、キャッシングなどの技術は、I/O ボトルネックを最小限に抑え、GPU を完全に利用する上で中心的な役割を果たします。
並列化は、データ読み込みパイプラインのスループットを向上させる最も効果的な方法の 1 つです。特に、データのデコードと前処理は、通信する必要なく同時に実行できる多くの独立したプロセスに分解できる、非常に並列化しやすい処理であることが多いためです。TensorFlow (tf.data) や PyTorch (ネイティブな DataLoader) などのフレームワークを使用して、ワーカープール (CPU スレッドまたはプロセス) のサイズを調整し、データ取り込みを並列化できます。
シーケンシャルアクセスパターンの場合、経験則としては、ワーカースレッドの数を利用可能な CPU コアの数に合わせることです。ただし、CPU カウントが高いインスタンス (例えば 20 を超える) では、やや小さいプールサイズを使用すると効率が向上します。
対照的に、ランダムアクセスパターン、特に S3 から直接読み取る場合、ベンチマークでは CPU カウントよりも大きなプールサイズが有益であることが証明されました。例えば、8 個の vCPU を持つ EC2 インスタンスでは、PyTorch の num_workers 設定を 64 以上に増やすと、データスループットが大幅に向上しました。
とはいえ、並列化を増やすことは万能薬ではありません。過度の並列化は CPU とメモリリソースを圧倒し、ボトルネックを I/O から前処理にシフトさせる可能性があります。適切なバランスを見つけるために、特定のワークロードのコンテキスト内でベンチマークを行うことが重要です。
プリフェッチは、データ読み込みを GPU 計算から分離することで並列化を補完します。プロデューサー-コンシューマーパターンを使用して、プリフェッチはデータを非同期で準備し、メモリにバッファリングすることで、GPU が必要とするときに次のバッチが準備できるようにします。適切なサイズのプリフェッチバッファと適切に調整されたワーカープールサイズは、I/O と前処理のレイテンシーを償却し、全体的な学習スループットを向上させるのに役立ちます。
キャッシングは、同じデータサンプルが複数回読み取られるランダムアクセスパターンを持つマルチエポック学習ワークロードに特に効果的です。Mountpoint for Amazon S3 などのツールは、データセットオブジェクトをインスタンスストレージ (例えば NVMe ディスク)、EBS ボリューム、またはメモリにローカルに保存する組み込みのキャッシングメカニズムを提供します。繰り返される S3 GET リクエストを削除することで、キャッシングは学習速度とコスト効率を向上させます。
学習中は入力データセットが通常静的なままであるため、繰り返される S3 リクエストオーバーヘッドを減らすために、無期限のメタデータ TTL で Mountpoint を構成することをお勧めします (--metadata-ttl indefinite を設定します、Mountpoint for S3 ドキュメントを参照ください)。さらに、ベンチマークでは、NVMe へのデータキャッシングも有効にし、Mountpoint がオブジェクトをローカルに保存できるようにしました。キャッシュは、最も最近使用されていないファイルを削除することでスペースを自動的に管理し、デフォルト設定では、ディスク容量の少なくとも 5%を空きスペースとして確保します (設定可能)。キャッシングから完全に恩恵を受けるには、インスタンスに頻繁にアクセスされるデータを保持するのに十分なディスクスペースがあることを確認してください。
パフォーマンスケーススタディ:Amazon S3 Standard からのデータ読み込み
前述のベストプラクティスを検証するため、ランダムおよびシーケンシャルデータアクセスパターンの両方で、現実的なコンピュータビジョン (CV) 学習ワークロードをシミュレートする一連のベンチマークを実施しました。正確な結果は特定のユースケースによって異なる場合がありますが、パフォーマンスの傾向と洞察は、ML トレーニングパイプライン全体に広く適用できます。
ベンチマークセットアップ
すべてのベンチマークは、NVIDIA A10G GPU と 32 個の vCPU を搭載した Amazon Elastic Compute Cloud (Amazon EC2) g5.8xlarge インスタンスで実行されました。ベンチマークワークロードは、画像分類タスク用の google/vit-base-patch16-224-in21k バックボーン ViT モデルを使用し、100,000 枚の合成 JPEG 画像 (各約 115 KB) を含む 10 GB のデータセットで学習しました。データセットは、次のいずれかの S3 クライアントを使用して、学習スクリプトによって Amazon S3 Standard からオンデマンドで直接ストリーミングされました。
- fsspec ベースのデータローダー – クラウドオブジェクトストア用の人気のあるオープンソースインターフェースである fsspec に基づく TorchData DataPipes の実装。TorchData は v0.10 でDataPipes を廃止しましたが、fsspec は S3 からの ML データアクセスに広く使用されています。
- Mountpoint for Amazon S3 (データキャッシングなし) – AWS が開発した高スループットのオープンソースファイルクライアント。この構成では、メタデータキャッシングは有効ですが、学習サンプルはエポック間でローカルにキャッシュされません。
- Mountpoint for Amazon S3 (データキャッシング) – 前のクライアントと同じですが、エポック全体で頻繁にアクセスされるサンプルを保存するために、ローカルディスクキャッシングが有効になっています。
- S3 Connector for PyTorch – PyTorch のデータセット API と緊密に統合された高性能のオープンソース S3 インターフェースで、AWS がメンテナンスしています。
各ベンチマーク構成は、事前のローカルダウンロードや前処理なしに、学習中にデータセットをオンデマンドでストリーミングしました。
ベンチマークの目標
ベンチマークは以下を探求するために設計されました。
- データローダーでの並列化設定の調整の効果
- Mountpoint for Amazon S3 を使用したローカルディスクキャッシングのパフォーマンスへの影響
- シーケンシャル読み取りパターンの採用によるスループット向上
- データセットシャードサイズと持続的なデータ読み込みパフォーマンスの関係
両方のアクセスパターンについて、前処理段階には JPEG デコードと 224×224×3 へのリサイズが含まれ、その後 128 のミニバッチにバッチ化されました。この軽量なセットアップにより、CPU バウンドのオーバーヘッドを最小限に抑えながら、現実的なエンドツーエンドのパイプラインを維持することができました。
再現性とベストプラクティス
独自の環境で同様のベンチマークを再現するために、さまざまな S3 データ読み込み構成をサポートする専用のベンチマークツールを提供しています。
一貫性のある意味のある結果を得るために:
- 各 S3 クライアントに対して同一の EC2 インスタンスタイプを使用します。
- 各テストデータセットを別々の S3 バケットに配置して、トラフィックを分離し、クライアント間の干渉を避けます。
- S3 バケットと同じ AWS リージョンで実験を実行して、レイテンシーとネットワークの変動を最小限に抑えます。
これらのベストプラクティスに従うことで、クリーンな測定値を取得し、独自のワークロードでさまざまなデータ読み込み戦略を確実に比較できます。
ランダムアクセスでの単一エポックベンチマーク
Amazon S3 から直接データセットをストリーミングする際の並列化の効果を評価するために、潜在的な OS レベルのキャッシングからの干渉を避けるため、1 エポックのベンチマーク (学習データセット全体を 1 回読み込み) を実行しました。
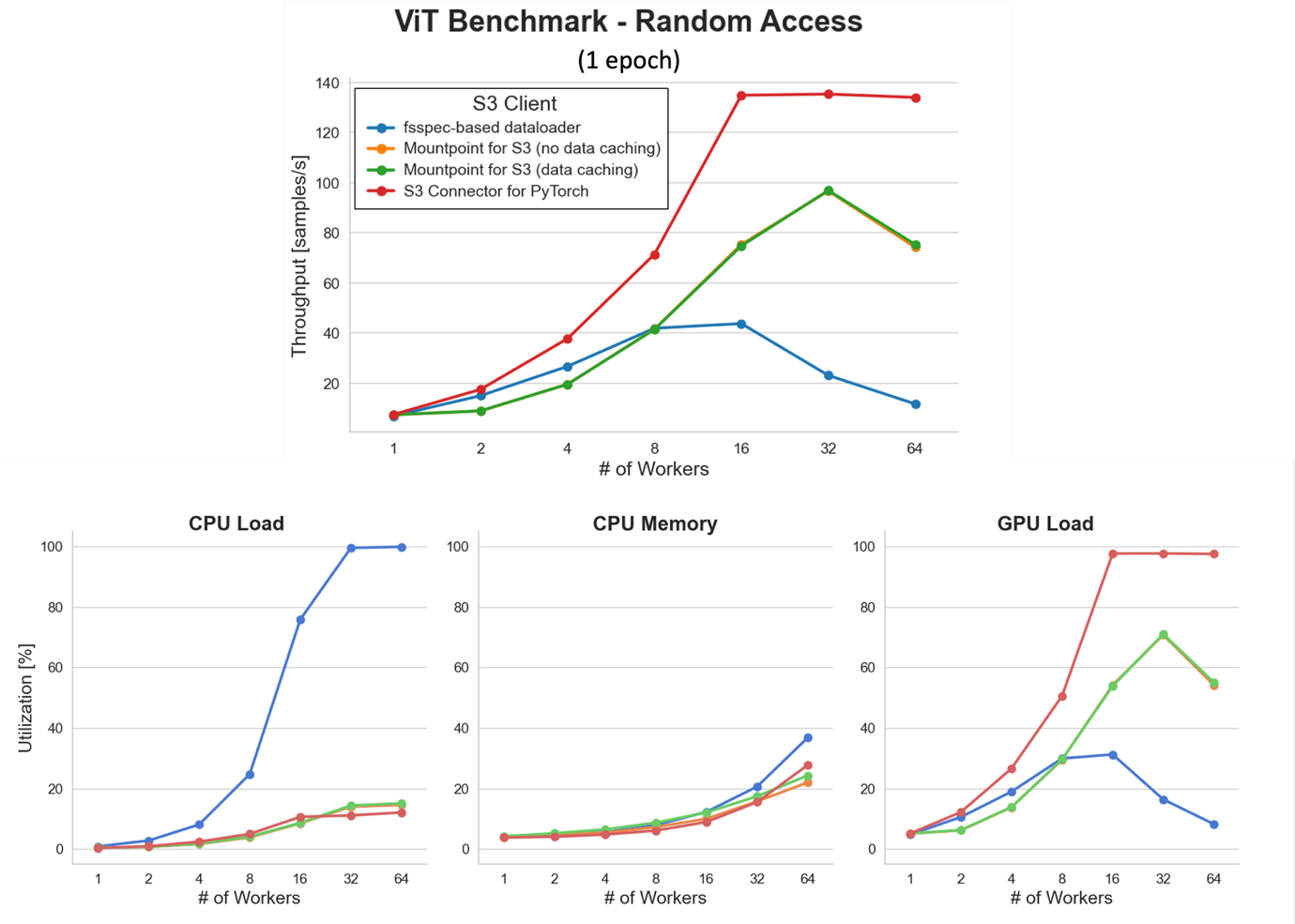
少ないワーカー数では、すべての S3 クライアントがデータ取り込みボトルネックを示し、全体的なスループットを制限します。並列化の度合いが増加すると、スループットが大幅に向上します。特に、S3 Connector for PyTorch は、16 ワーカー以上でほぼ GPU 飽和 (約 138 サンプル/秒) に達します。
ただし、ワーカープールの積極的なスケーリングは、CPU とメモリの負荷を増加させます。これは fsspec ベースのデータローダーで特に顕著で、32 ワーカーで約 100% の CPU 使用率に達し、CPU バウンドのボトルネックを引き起こし、GPU 使用率を低下させ、全体的なサンプルスループットを減少させます。対照的に、S3 Connector for PyTorch は負荷下でより良い効率を維持し、高性能 S3 クライアントを使用することの重要性を強調しています。
データキャッシングありとなしの Mountpoint for Amazon S3 は、この 1 エポックベンチマークでほぼ同じパフォーマンスを提供します。これは予想通りで、各サンプルが一度だけ読み取られ、キャッシングが利点を提供しないためです。次に説明するマルチエポックシナリオでキャッシングの利点を再検討します。
ランダムアクセスでのマルチエポックベンチマーク
Mountpoint for Amazon S3 のキャッシング機能は、頻繁にアクセスされる S3 オブジェクトをローカルストレージに保存することで、学習パフォーマンスを大幅に向上させ、エポック間で取得レイテンシーとリクエストコストを削減します。ベンチマークでは、最初のエポック中にアクセスされたデータセットファイルがローカルにキャッシュされます。2 番目のエポック以降、データセット全体がディスクから提供され、データローダーワーカープールが 16 であっても GPU を完全に飽和させ、スループットを最大化します。
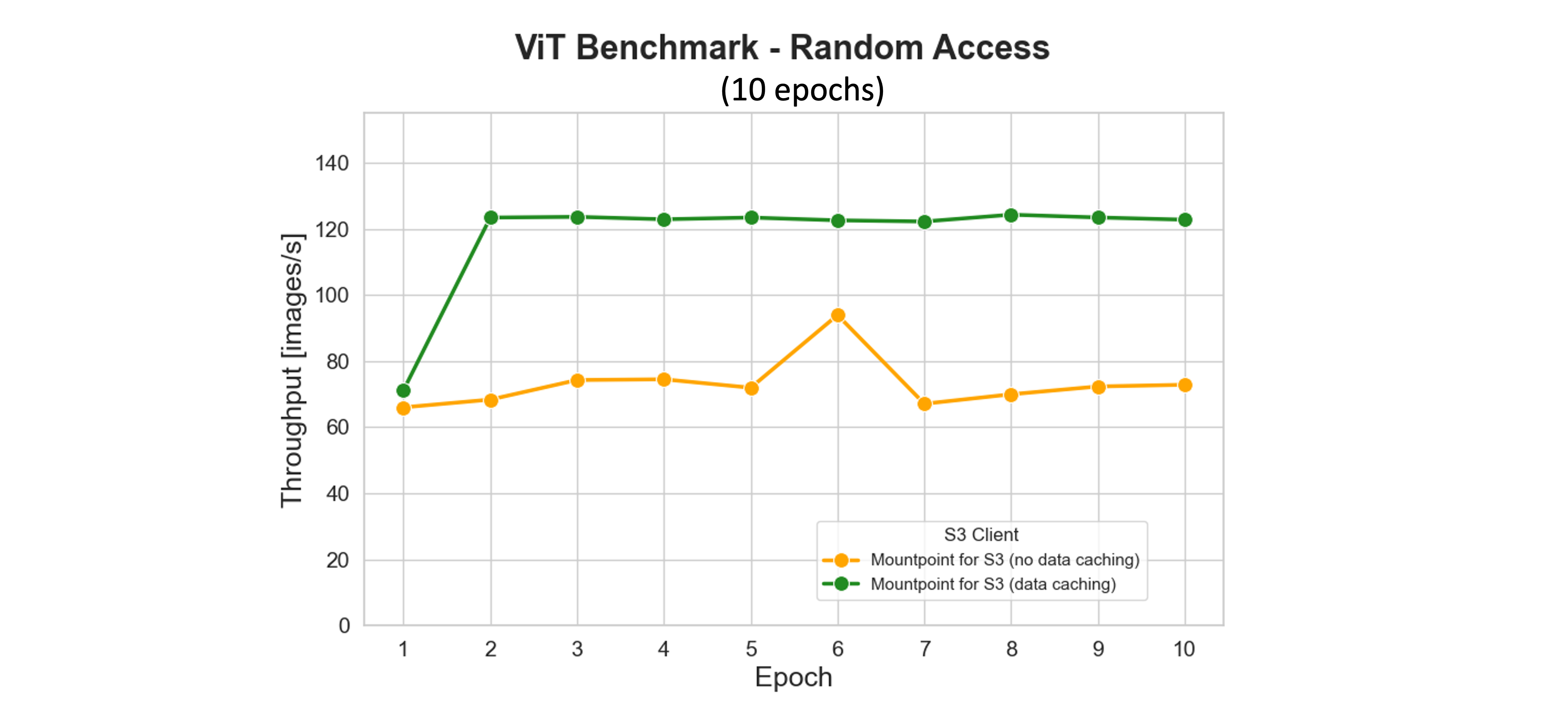
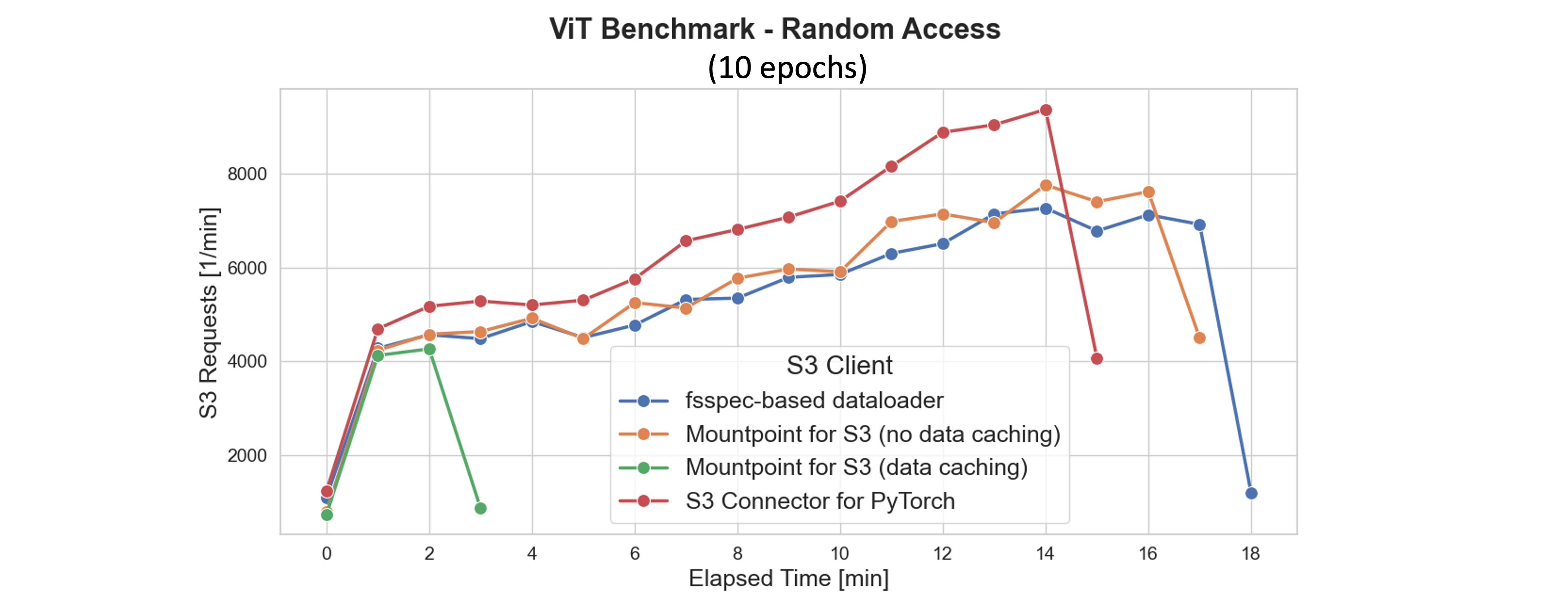
次のプロットに示されているように、キャッシングはトレーニングを加速するだけでなく、ネットワークトラフィックと S3 リクエスト量も最小限に抑えます。最初のエポックの終わり (約 2 分マークあたり) までに、Mountpoint は S3 への GET、LIST、HEAD リクエストをさらに削減します。対照的に、キャッシングなしの S3 クライアントは、各エポックで同じデータを継続的に再ダウンロードし、より高いレイテンシーと運用コストを発生させます。
シーケンシャルアクセスでの単一エポックベンチマーク
シーケンシャルデータアクセスの利点を検証するために、以前と同じセットアップ (8 データローダーワーカー)を使用してベンチマークを再実行しましたが、シャードサイズが 4 MB ~ 256 MB の tar 形式のシリアル化されたデータセットに切り替えました。
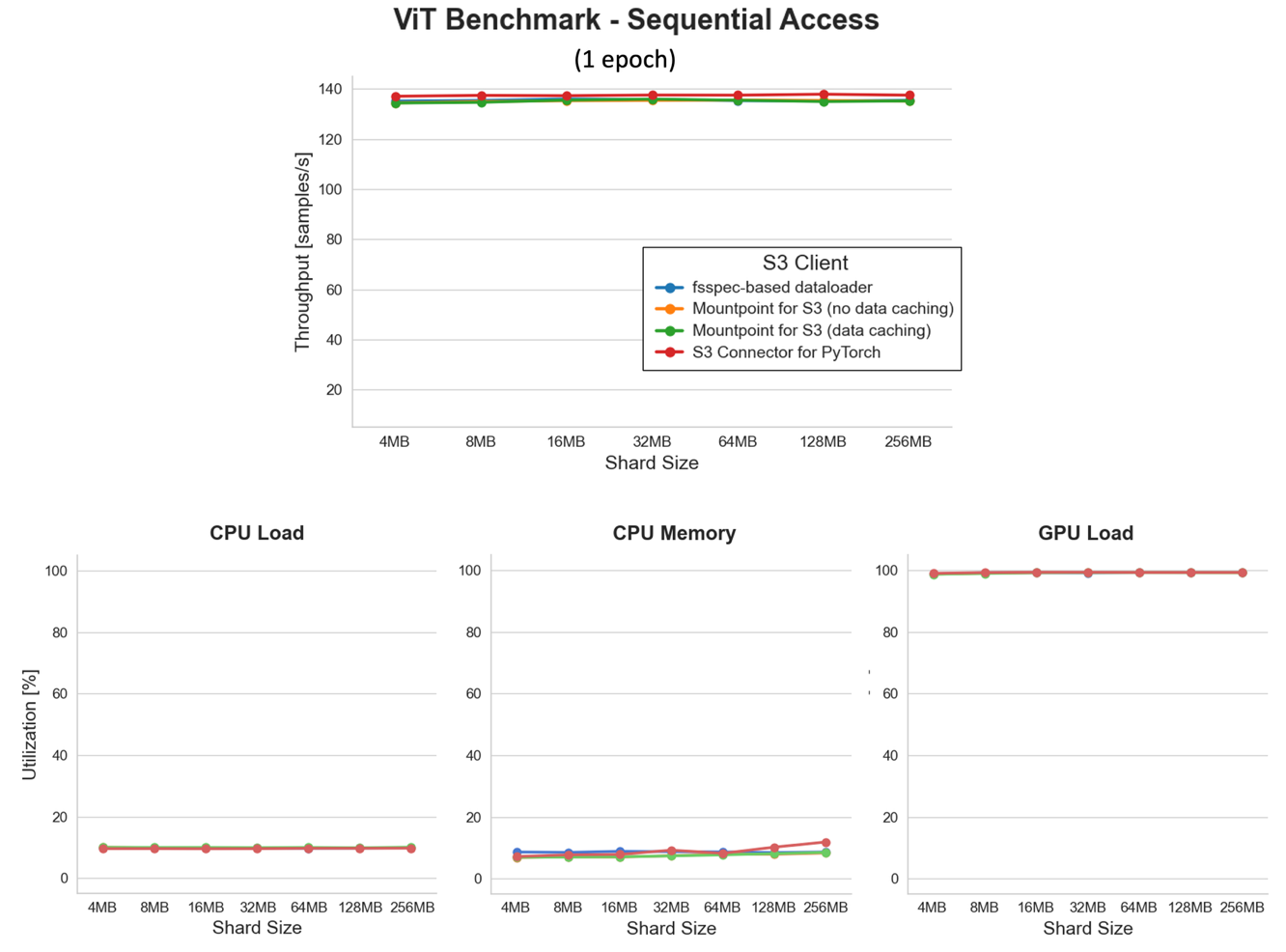
一見すると、このベンチマークの結果は地味に見えるかもしれません。すべての折れ線プロットが平坦です。しかし待ってください、それこそが素晴らしい部分ではないでしょうか? GPU 負荷は一貫して約 100% の使用率で平坦であり、すべてのファイルシャードサイズにわたって GPU を完全に飽和させていることを意味します。それを一貫して低い CPU 使用率と組み合わせると、非常に注目すべき成果が得られます!
シーケンシャルアクセスでの理論上の最大ベンチマーク
前述のベンチマークの結果は興味深い疑問を提起します。シーケンシャルアクセスで、このセットアップで達成できる理論上の最大スループットはどれぐらいでしょうか?調査のために、方程式から GPU バウンドのモデル学習段階を削除し、CPU 上での読み取りと前処理段階のみを残しました。ワーカープールサイズ 8 の結果を次のプロットに示します。
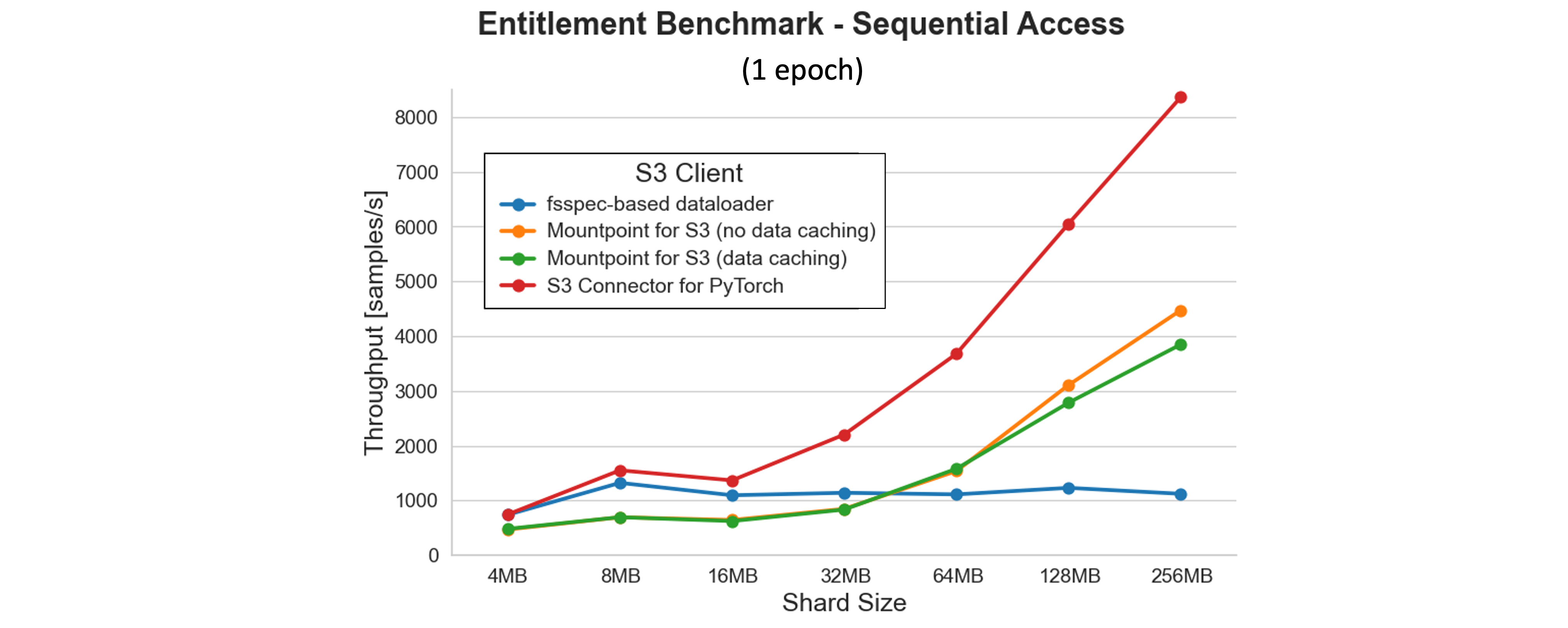
結果は、fsspec ベースのデータローダーを除くすべてのクライアントで、シャードサイズが大きいほどスループットが向上することを示しています。S3 Connector for PyTorch は最高のパフォーマンスを提供し、テストされた最大のシャードサイズで 8,000 サンプル/秒を超えます。より高い並列化 (32 ~ 64 ワーカー) またはより大きなシャードでは、スループットはさらにスケールし、拡張テストで 12,000 サンプル/秒を超えました。
結論
クラウドでの最新の ML トレーニングパイプラインのパフォーマンスを完全に引き出すには、データ取り込みの最適化が不可欠です。この記事では、ランダムなデータ読み取りや、小さいファイルサイズのデータを使うことがレイテンシーオーバーヘッドを増加させ、スループットを著しく制限する一方で、シーケンシャルアクセスパターンを持つ統合データセットが帯域幅を最大化し、GPU を完全に利用できることを示しました。
Mountpoint for Amazon S3 や S3 Connector for PyTorch などの高性能 Amazon S3 クライアントを使用することが、トレーニングパフォーマンスに大きな違いをもたらすことを探求しました。また、データセットをより大きなファイルにシャード化し、並列化設定を調整し、冗長な S3 リクエストを最小限に抑えるためにキャッシングを適用する利点も示しました。Amazon S3 Standard からのデータアクセスに焦点を当てたベンチマークは、これらのベストプラクティスがアイドル GPU 時間を大幅に削減し、コンピューティングリソースから最大の価値を得るのに役立つことを確認しています。
学習ワークロードが成長するにつれて、データパイプライン設計を見直し続けてください。データ読み込みに関する慎重な決定は、コスト効率と結果までの時間において大きな利益をもたらすことができます。
著者について
 Dr. Alexander Arzhanov は、ドイツのフランクフルトを拠点とするシニア AI/ML スペシャリストソリューションアーキテクトです。彼は、EMEA 地域全体で AWS の顧客が ML ソリューションを設計および展開するのを支援しています。AWS に入社する前、Alexander は宇宙における重元素の起源を研究しており、大規模な科学計算で ML を使用した後、ML に情熱を持つようになりました。
Dr. Alexander Arzhanov は、ドイツのフランクフルトを拠点とするシニア AI/ML スペシャリストソリューションアーキテクトです。彼は、EMEA 地域全体で AWS の顧客が ML ソリューションを設計および展開するのを支援しています。AWS に入社する前、Alexander は宇宙における重元素の起源を研究しており、大規模な科学計算で ML を使用した後、ML に情熱を持つようになりました。
 Ilya Isaev は、英国ケンブリッジを拠点とする Amazon S3 のソフトウェアエンジニアです。彼は、顧客が Amazon S3 で学習データとモデルチェックポイントを効率的に保存および管理できるよう支援し、高性能 GPU インスタンスの大規模クラスター向けのリアルタイムデータアクセスパフォーマンスの改善に焦点を当てています。
Ilya Isaev は、英国ケンブリッジを拠点とする Amazon S3 のソフトウェアエンジニアです。彼は、顧客が Amazon S3 で学習データとモデルチェックポイントを効率的に保存および管理できるよう支援し、高性能 GPU インスタンスの大規模クラスター向けのリアルタイムデータアクセスパフォーマンスの改善に焦点を当てています。
 Roy Allela は、AWS のシニア AI/ML スペシャリストソリューションアーキテクトです。彼は、小規模なスタートアップから大企業まで、AWS の顧客が AWS 上で基盤モデルを効率的に学習および展開するのを支援しています。彼は計算最適化問題と AI ワークロードのパフォーマンス向上に情熱を持っています。
Roy Allela は、AWS のシニア AI/ML スペシャリストソリューションアーキテクトです。彼は、小規模なスタートアップから大企業まで、AWS の顧客が AWS 上で基盤モデルを効率的に学習および展開するのを支援しています。彼は計算最適化問題と AI ワークロードのパフォーマンス向上に情熱を持っています。
翻訳はソリューションアーキテクトの 長谷川 大 が担当しました。原文はこちらです。