Amazon Web Services ブログ
AWS Advanced JDBC Wrapper による JDBC クエリキャッシュの自動化
本記事は 2026 年 5 月 19 日 に公開された「Automated JDBC query caching with the AWS Advanced JDBC Wrapper」を翻訳したものです。
データベース負荷の大半を読み取りクエリが占めている場合、元データがほとんど変化しない場合でもレスポンスタイムが悪化し、コストが増加します。従来の対策はカスタムキャッシュレイヤーの構築ですが、クエリごとに外部キャッシュロジックを実装し、シリアライゼーションを処理し、データベースとの整合性を維持する必要があります。ビジネス機能の開発に割くべきリソースを大きく消費します。
本日、AWS Advanced JDBC Wrapper 向けの Remote Query Cache Plugin を発表します。クエリキャッシュを自動的に処理し、JDBC クエリをインターセプトして結果を Amazon ElastiCache for Valkey にキャッシュし、以降の同一クエリをキャッシュから提供します。アプリケーション側の変更はクエリに SQL ヒントを付加するだけです。
本記事では、Amazon CloudWatch Database Insights を使用してキャッシュ対象のクエリを特定する方法、Java アプリケーションで Remote Query Cache Plugin を設定する方法、Amazon CloudWatch でキャッシュの効果をモニタリングする方法を説明します。
外部キャッシュ実装の課題
データベースアプリケーションにキャッシュを追加する場合、通常 3 つの大きな障壁があります。
アプリケーションの複雑な改修: 既存アプリケーションにキャッシュを追加しようとする場合、サービスコードメソッドへのアノテーション、キャッシュパラメータの設定、別設定ファイルでの TTL 管理など、アプリケーション層での変更が必要です。変更はコードベース全体に広がり、特定のフレームワークに依存する場合があります。
新しい API とパターンの習得: キャッシュの統合には、新しいクライアントライブラリの習得、シリアライゼーションフレームワークの理解、キャッシュ障害時のエラーハンドリングの実装が必要です。既存のデータベースコードを維持しながら、これらの技術に習熟する必要があります。
キャッシュ管理の複雑さ: キャッシュの無効化、キャッシュサーバーの適切なサイジング、一貫したキャッシュキーの生成、キャッシュヒット率のモニタリング、キャッシュサーバーがダウンした時の安全な障害処理を手動で管理する必要があります。
結果として、キャッシュロジック構築に多大なリソースを投じるか、データベースコストの増大とパフォーマンス低下を許容するかの選択を迫られます。
AWS Advanced JDBC Wrapper Remote Query Cache Plugin による課題の解決
Remote Query Cache Plugin を使用すると、既存の PostgreSQL、MySQL、MariaDB アプリケーションにクエリ結果キャッシュを統合できます。プラグインはアプリケーションに対して透過的に動作し、自身でキャッシュレイヤーを構築するオーバーヘッドがありません。
キャッシュ対象のクエリに SQL ヒントを追加するだけで済みます。プラグインは Amazon ElastiCache for Valkey の確認、ミス処理、結果のシリアライゼーション、キャッシュへの自動格納を透過的に行います。
プラグインは既存の JDBC インターフェース経由で動作します。Spring Data JPA、Hibernate、Spring JDBC Template、ネイティブ JDBC など、使い慣れたパターンをそのまま使い続けられます。Valkey クライアント、シリアライゼーション、エラーハンドリングはプラグインがバックグラウンドで管理します。
プラグインはキャッシュキーを自動生成し、設定可能な TTL (time-to-live) 値で有効期限を管理し、キャッシュが利用不可の場合はデータベースクエリにフォールバックします。独自の計測コードを追加せずに Amazon CloudWatch へメトリクスを送信してモニタリングできます。
アーキテクチャ概要
Remote Query Cache Plugin のリードスルーキャッシュの動作を次の図に示します。
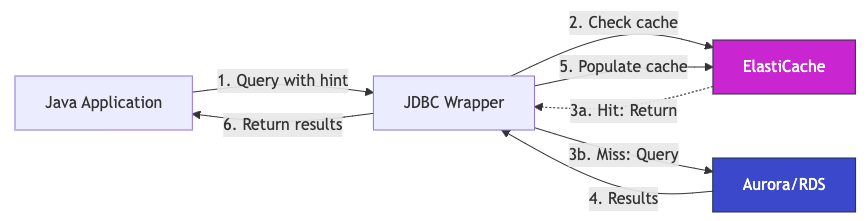
図 1: Java アプリケーション、Amazon ElastiCache for Valkey、Amazon Aurora または Amazon RDS 間の Remote Query Cache Plugin リードスルーキャッシュフロー
動作の仕組み:
- アプリケーションがキャッシュヒント (
/* CACHE_PARAM(ttl=<duration>) */) 付きのクエリを実行します。 - プラグインがクエリに一致するキャッシュ結果を ElastiCache で確認します。
- キャッシュヒット (3a): 結果がマイクロ秒単位でプラグインに返され、ステップ 4 と 5 はスキップします。キャッシュミス (3b): プラグインがクエリを Aurora/RDS データベースに転送します。
- データベースがクエリを実行し、最新の結果をプラグインに返します。
- プラグインが結果を非同期で ElastiCache に格納し、以降のリクエストに備えます。
- プラグインが結果をアプリケーションに返します。
プラグインは初回アクセス時にキャッシュを格納するため、アプリケーションロジックの変更は最小限で、SQL ヒントの設定のみで済みます。
キャッシュ対象クエリの特定方法
すべてのクエリがキャッシュの恩恵を受けるわけではありませんが、まず着目すべきは頻繁に実行されデータベース負荷に大きく影響を与える SELECT 文です。通常、大規模なデータセットを集計または結合して小さく安定した結果セットを返すクエリが該当します。
Amazon Relational Database Service (Amazon RDS) と Amazon Aurora で稼働するデータベースの場合、CloudWatch Database Insights を使用してこれらのクエリを特定できます。describe-dimension-keys CLI コマンドは、db.load.avg 順にランク付けされた上位 SQL 文を返します。このメトリクスは平均アクティブセッション数を測定し、各クエリがどの程度データベースキャパシティを消費しているかを示します。
データベース負荷による上位 SELECT 文の特定
このコマンドは結果を SELECT 文のみにフィルタリングし、db.load.avg の降順でソートします。db.load.avg の値は、対象時間ウィンドウにおけるそのクエリの平均アクティブセッション数です。値が 0.42 の場合、そのクエリが平均して 1 つのアクティブデータベースセッションの 42% を占めていたことを意味します。リストの上位にあるクエリほどデータベースキャパシティを多く消費しており、キャッシュの有力な候補です。
出力例
通常のトラフィック下で稼働する EC サイトアプリケーションを考えてみましょう。コマンドは次のような出力を返す可能性があります。
最初の 3 つのクエリはキャッシュの有力候補です。商品カタログの結合 (db.load.avg 0.42)、ユーザープロファイルの参照 (0.18)、地域別税率の取得 (0.09) です。これらはデータベース負荷が高く、SELECT のみであり、変更頻度の低いデータに基づいています。4 番目のクエリ (リアルタイム注文件数、0.02) は、注文のたびに結果が変わるためキャッシュすべきではありません。
良い候補の判断基準
| シグナル | 確認すべきポイント |
高い db.load.avg |
クエリがデータベース負荷に大きく影響を与えている。 |
| SELECT 文 | 読み取りクエリのみキャッシュに適している。 |
| 安定した結果セット | 選択した TTL に対してデータの変更頻度が低い。 |
| 繰り返し実行 | 1分間に何度も呼び出される。頻度が高いほど効果が大きい。 |
候補を特定したら、/* CACHE_PARAM(ttl=<duration>) */ の形式でヒントを追加します。残りは Remote Query Cache Plugin が処理します。
前提条件
開始前に以下を確認してください。
- Amazon ElastiCache for Valkey サーバーレスキャッシュ (推奨)、セルフマネージド ElastiCache Valkey クラスター、またはセルフマネージド Valkey キャッシュ。
- AWS Advanced JDBC Wrapper 4.0.1 以降。
- PostgreSQL、MySQL、または MariaDB を JDBC で使用するアプリケーション。
Amazon ElastiCache Serverless はインフラ管理不要で自動スケーリングと高可用性が組み込まれているため推奨です。
Remote Query Cache Plugin によるキャッシュの設定
Remote Query Cache Plugin の有効化には、ドライバー依存関係の追加、接続の設定、キャッシュ対象クエリへの SQL クエリヒントの追加の 3 ステップが必要です。
ステップ 1: AWS Advanced JDBC Wrapper 依存関係の追加
まず、Maven 設定にラッパー依存関係を追加します (Gradle もサポートされています)。
Maven:
Gradle:
ステップ 2: キャッシュ接続の設定
データベース接続設定を更新して Remote Query Cache Plugin を有効にします。フレームワークによって設定が若干異なります。
Spring Boot の例 (application.yml):
データベース認証: この例ではプレースホルダーとしてユーザー名とパスワードを使用しています。AWS Advanced JDBC Wrapper は IAM データベース認証や AWS Secrets Manager など複数の認証方法をサポートしています。詳細は Secrets Manager Plugin を参照してください。
主な設定プロパティ:
wrapperPlugins=remoteQueryCache: Remote Query Cache Plugin を有効にします。cacheEndpointAddrRw: 読み書き操作用の Amazon ElastiCache エンドポイント。cacheName: Amazon ElastiCache クラスター名 (IAM 認証用)。cacheUsername: キャッシュのユーザー名 (Amazon ElastiCache Serverless の場合はdefaultを使用)。cacheIamRegion: IAM 認証用の AWS リージョン。cacheUseSSL=true: アプリケーションと ElastiCache 間の転送中データに TLS 暗号化を有効にします。すべてのデプロイでtrueに設定してください。
ステップ 3: 対象クエリへの SQL ヒントの追加
キャッシュ対象のクエリに TTL (time-to-live) 付きの SQL ヒントを追加してマークします。構文は SELECT 文の先頭に /* CACHE_PARAM(ttl=<duration>) */ を付けます。
Spring Data:
Remote Query Cache Plugin のドキュメントに、Hibernate と Spring Data の追加例が掲載されています。
OpenTelemetry によるパフォーマンスモニタリング
Remote Query Cache Plugin は AWS Distro for OpenTelemetry (ADOT) Collector を通じてキャッシュメトリクスを送信するよう設定できます。ヒット数とミス数、バイパスイベント、ヘルスチェックステータスを取得でき、キャッシュの効果をリアルタイムに把握できます。分散トレーシングを有効にして、クエリがキャッシュとデータベースのどちらにアクセスしたかも確認できます。プラグインは Remote Query Cache Plugin テレメトリドキュメントとテレメトリ設定ガイドに記載の方法で AWS X-Ray にトレースを転送します。
図 2: OpenTelemetry 経由で収集されたキャッシュヒット/ミスメトリクス、ヘルスチェック、クエリパフォーマンスを表示する Amazon CloudWatch ダッシュボード
セキュリティの考慮事項
本ソリューションは AWS 責任共有モデルに従います。AWS が ElastiCache と RDS/Aurora の基盤インフラストラクチャを保護します。アクセス制御の設定、暗号化の有効化、認証情報の管理はお客様の責任です。
転送中の暗号化: 接続 URL で cacheUseSSL=true を設定し、アプリケーションと ElastiCache 間の全トラフィックを暗号化します。
保管時の暗号化: Amazon ElastiCache Serverless はデフォルトで保管時の暗号化が有効です。ノードベースのクラスターでは、作成時に AtRestEncryptionEnabled=true を設定します。
ElastiCache の IAM 認証: 静的パスワードの代わりに IAM 認証を使用するには、接続 URL で cacheIamRegion と cacheName を設定します。アプリケーションの IAM ロールに以下のポリシーをアタッチします。
Performance Insights CLI 用の IAM 権限: aws pi describe-dimension-keys と aws rds describe-db-instances コマンドには以下の最小権限が必要です。
クリーンアップ
テスト用に Amazon ElastiCache for Valkey クラスターを作成した場合、継続的な課金を避けるため ElastiCache コンソールまたは AWS CLI で削除してください。キャッシュを削除すると、キャッシュされた全データが完全に削除されます。新しいキャッシュをプロビジョニングするまで、アプリケーションはデータベースへの直接クエリにフォールバックします。
コード変更を元に戻すには:
- 接続 URL から
wrapperPlugins=remoteQueryCacheとキャッシュパラメータを削除します。 - クエリから
/* CACHE_PARAM(ttl=...) */ヒントを削除します。 - 他の Wrapper プラグインを使用していない場合、ビルド設定から Wrapper 依存関係を削除します。
まとめ
本記事では、最小限のアーキテクチャ変更でデータベース負荷を削減しアプリケーションパフォーマンスを向上させる自動クエリキャッシュの方法を紹介しました。AWS Advanced JDBC Wrapper Remote Query Cache Plugin を設定して Amazon ElastiCache for Valkey と通信し、SQL ヒントを使用してキャッシュ対象クエリをマークします。キャッシュの検索、シリアライゼーション、コネクションプーリング、認証、障害時の安全なフォールバックはすべて自動的に管理されます。繰り返しの読み取りクエリを Amazon ElastiCache にオフロードすることで、書き込みが多い処理やレイテンシーが重要なオペレーション用にデータベースキャパシティを確保できます。
まず、Aurora または RDS インスタンスで Amazon CloudWatch Database Insights を使用し、データベース負荷による上位 SELECT クエリを特定してください。本記事の aws pi describe-dimension-keys コマンドを実行して候補を洗い出します。次に、最も負荷の高い候補に /* CACHE_PARAM(ttl=<duration>) */ ヒントを追加し、ラッパーを設定してアプリケーションをデプロイします。PostgreSQL 直接接続、AWS JDBC Wrapper、Remote Query Cache Plugin のクエリレイテンシーを並べて比較するには、GitHub の jdbc-caching-demo サンプルをお試しください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Kenta Nagasue がレビューしました。