この記事は、”Automatically detect sports highlights in video with Amazon SageMaker
動画からハイライトを抽出するのは、時間がかかり、複雑なプロセスです。この記事では、機械学習(ML)ソリューションを使用して、オリジナルの動画コンテンツからハイライト動画を自動的に作成する、スポーツイベントのインスタントリプレイに関する新たな取り組みを紹介します。ハイライト動画はダウンロード可能で、ユーザーが Web アプリで継続して視聴することができます。
Amazon SageMaker を使用して、ノーカットのスポーツ動画 (今回はサッカーの試合) を分析し、元の動画のハイライト (ペナルティキック) であるセグメントにタグを付けます。また、適当な学習データが利用できる場合に、他のスポーツだけでなく、別のタイプの動画にも、このエンドツーエンドのアーキテクチャを適用する方法について紹介します。
アーキテクチャの概要
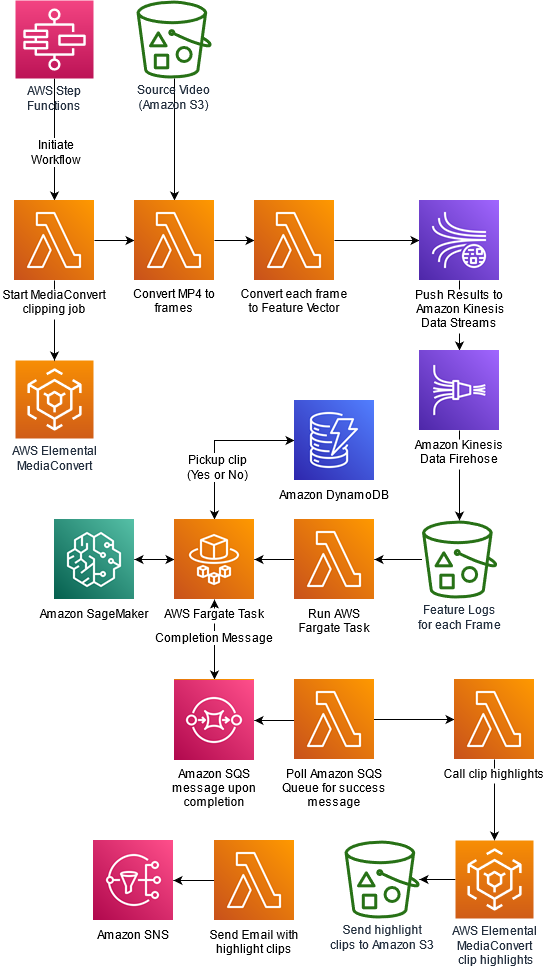
次の図は、ソリューションのアーキテクチャを示しています。
オーケストレーション概要
AWS Lambda 関数を後述する AWS Step Functions ワークフローで使用し、各ステップにおける AWS Lambda 関数の処理をオーケストレーションします。
ワークフローの最初のステップは、動画を個別のフレームに分割する MediaConvert ジョブを開始することです。MediaConvert ジョブが完了すると、Lambda 関数は各フレームを特徴ベクトルに変換します。Lambda 関数は、1枚ずつ画像を事前学習済みのモデル (Inception V3) に渡すことで特徴ベクトルを生成します。これらの特徴ベクトルは、Amazon Kinesis Data Streams と Amazon Kinesis Data Firehose を介してトピックとして送信され、最終的に Amazon S3 に保存されます。ワークフローの次のステップでは、特徴ベクトルのシーケンスに基づいて、動画セグメントが取り立てて関心を引くものであるかどうかを推論するために機械学習モデルを呼び出します。このモデルは、UCF101 でラベルとして定義されている動作が動画の中に含まれるか判定します。ここで、AWS Fargate は、特徴ベクトルのすべてのシーケンスをループし、推論の準備をし、SageMaker エンドポイントを使用して推論を実行し、Amazon DynamoDB テーブルに結果を順に並べる役割として機能します。Fargate タスクが完了すると、メッセージは Amazon SQS キューに送られます。Lambda 関数はこの Amazon SQS キューを定期的にポーリングします。完了メッセージが検出されると、Lambda 関数は MediaConvert ジョブをトリガーして、機械学習の推論結果に基づいてハイライトするセグメントを準備します。最後に、ハイライト動画のリンクを含む E メールが、ユーザーが指定したメールアドレスに送信されます。
手法
ディープラーニング技術を使用して、動画内のアクティビティを特定します。事前学習済みの Inception V3 モデルに基づく深層畳み込みニューラルネットワーク (CNN) を使用して、動画から抽出された画像の特徴量を生成し、LSTM (Long Short-Term memory) ネットワークを使用して、一連の特徴量から動作を推論します。CNN と LSTM はどちらも、ML ベースのコンピュータービジョンソリューションで使用されるニューラルネットワークの一種です。2D-CNN と LSTM に入る前に、ニューラルネットワークと関連用語について簡単に説明します。
ニューラルネットワーク
ニューラルネットワークは、動物の脳を構成する生物学的ニューラルネットワークにヒントを得て作られたコンピューターシステムです。脳の基本単位がニューロンであるように、人工ニューラルネットワークの構成要素はパーセプトロンです。パーセプトロンは非常に単純な処理を行います。パーセプトロンは大規模なメッシュネットワークに接続され、ニューラルネットワークを形成します。ニューラルネットワークはレイヤーに編成され、それらの間の接続は重み付けされます。ニューラルネットワークはアルゴリズムではなく、複数の異なる ML アルゴリズムが使用できるフレームワークです。この記事の後半では、動画から抽出された画像の特徴量を抽出するモデルを構築するときに、CNN の別のレイヤーについて記載します。
ニューラルネットワークは ML における教師あり学習手法です。つまり、類似したオブジェクトの数が増えるにつれてモデルがどんどん良くなるため、学習サンプルが増えるほど精度が向上します。
深層 CNN の用語を分析して、この手法が画像認識に有効な理由を理解しましょう。LSTM と組み合わせて、動画内のアクティビティの識別のためにこの技術を後ほど使用します。
深層畳み込みニューラルネットワーク
Inception V3 や YOLOV5 などの深層畳み込みニューラルネットワークは、画像認識やその他の付随するファインチューニングタスクに非常に効果的な手法であることが証明されています。より最近の Vision Transformer に基づくモデルも、最新の画像分類、物体検出、セグメンテーションマスクとして使用されています。画像認識にはさまざまな用途があります。人間が書いた数字の認識精度を向上させる技術として始まり、画像内の特定のオブジェクトや背景を識別してラベル付けするなど、より複雑な問題を解決するために進化しました。
深層 CNNは画像の分類と識別の問題をシンプルにして、結果の精度を大幅に向上しましたが、エンドツーエンドのソリューションをゼロから実装するのは簡単な作業ではありません。画像分類および画像認識ソリューションのための最先端の API ベースのソリューションを提供する Amazon Rekognition などのサービスを使用することをお勧めします。画像や動画のコンピュータビジョンの問題を解決するためにカスタムモデルが必要な場合、SageMaker は学習と推論のためのフレームワークを提供します。SageMaker は、BYOC (bring your own container) を使用した複数の ML フレームワークをサポートします。Keras でアクティビティ認識のモデルを開発し、推論用のモデルをデプロイするために、SageMaker で BYOC を使用しています。
畳み込み手法では、すべての画像を 1 つのピクセルのタイルとして処理するのではなく、固定サイズのスライディングウィンドウを使用して画像を複数のタイルに分割するため、ニューラルネットワークの出力がより堅牢で正確になります。タイルごとに次のレイヤーが個別に活性化され、画像のすべてのタイルが次のレイヤーに集約されて出力が生成されます。例えば、画像の左隅の 8 という数字を、画像の右隅の 8 と同じであると識別できます。これは「移動不変性」と呼ばれます。
LSTM
LSTM ネットワークは、リカレントニューラルネットワーク (RNN) の一種で、ループや特別なメモリユニットが存在するために情報を永続化できる特殊なセルまたはニューロンが含まれています。LSTM は特に時系列データ(今回のような静止フレームの時系列である動画分類のユースケース等)に関する学習タスク、とりわけ情報を長期間記憶する必要がある場合に役立ちます。
動画処理の課題
動画はパラパラ漫画のようなものだと理解することが重要です。各ページの静止画像をめくっていくと、動いていると感じるようになります。速くめくればめくるほど、よりスムーズに動いていると感じるようになります。
画像は2次元の空間に配置した連続的なピクセルとして格納されます。コンピュータプログラムはこのように画像を読み取ります。画像を拡張したものとして、動画には時間の次元が追加されています。動画は静止画像の時系列です。つまり、動画は 3次元の空間および時間にピクセルを配置したものということになります。
次元を追加すると、ML モデルを開発するためにより多くのコンピューティングとメモリが必要になります。動画入力を CNN や LSTM に送るには、多くの前処理が必要です。
前処理と処理が複雑化するだけでなく、動画データの研究に利用できるオープンデータセットも不足しています。
この記事では、UCF101 データセットで提供されているサンプルを使用して、モデルを構築し、推論用のエンドポイントをデプロイします。
動画の読み取りとフレームの抽出
ハイライトを抽出するために分析する動画ソースは Amazon Simple Storage Service (Amazon S3) にあるものとします。動画を個々のフレームに分割するために AWS Elemental MediaConvert を使用します。この MediaConvert ジョブは次の Lambda 関数からトリガーされます。
1. import json
2. import boto3
3.
4. s3_location = 's3://<ARTIFACT-BUCKET> /BYUfootballmatch.mp4'
5.
6.
7. def lambda_handler(event, context):
8. with open('mediaconvert.json') as f:
9. data = json.load(f)
10.
11. client = boto3.client('mediaconvert')
12. endpoint = client.describe_endpoints()['Endpoints'][0]['Url']
13.
14. myclient = boto3.client('mediaconvert', endpoint_url=endpoint)
15.
16.
17.
18. data['Settings']['Inputs'][0]['FileInput'] = s3_location
19.
20. response = myclient.create_job(
21. Queue=data['Queue'],
22. Role=data['Role'],
23. Settings=data['Settings'])
24.
11 行目では、 AWS SDK for Python (Boto3) を使用して、次の JSON テンプレートを使用して MediaConvert クライアントを開始しています。コーデック設定、幅、高さ、および動画形式に固有のその他のパラメーターを指定できます。
1. {
2. "Queue": "arn:aws:mediaconvert:<REGION> :<AWS ACCOUNT NUMBER> :queues/Default",
3. "UserMetadata": {},
4. "Role": "arn:aws:iam::<AWS ACCOUNT ID> :role/MediaConvertRole",
5. "Settings": {
6. "OutputGroups": [
7. {
8. "CustomName": "MP4",
9. "Name": "File Group",
10. "Outputs": [
11. {
12. "ContainerSettings": {
13. "Container": "MP4",
14. "Mp4Settings": {
15. "CslgAtom": "INCLUDE",
16. "FreeSpaceBox": "EXCLUDE",
17. "MoovPlacement": "PROGRESSIVE_DOWNLOAD"
18. }
19. },
20. "VideoDescription": {
21. "Width": 1280,
22. "ScalingBehavior": "DEFAULT",
23. "Height": 720,
24. "TimecodeInsertion": "DISABLED",
25. "AntiAlias": "ENABLED",
26. "Sharpness": 50,
27. "CodecSettings": {
28. "Codec": "H_264",
29. "H264Settings": {
30. "InterlaceMode": "PROGRESSIVE",
31. "NumberReferenceFrames": 3,
32. "Syntax": "DEFAULT",
33. "Softness": 0,
34. "GopClosedCadence": 1,
35. "GopSize": 90,
36. "Slices": 1,
37. "GopBReference": "DISABLED",
38. "SlowPal": "DISABLED",
39. "SpatialAdaptiveQuantization": "ENABLED",
40. "TemporalAdaptiveQuantization": "ENABLED",
41. "FlickerAdaptiveQuantization": "DISABLED",
42. "EntropyEncoding": "CABAC",
43. "Bitrate": 3000000,
44. "FramerateControl": "INITIALIZE_FROM_SOURCE",
45. "RateControlMode": "CBR",
46. "CodecProfile": "MAIN",
47. "Telecine": "NONE",
48. "MinIInterval": 0,
49. "AdaptiveQuantization": "HIGH",
50. "CodecLevel": "AUTO",
51. "FieldEncoding": "PAFF",
52. "SceneChangeDetect": "ENABLED",
53. "QualityTuningLevel": "SINGLE_PASS",
54. "FramerateConversionAlgorithm": "DUPLICATE_DROP",
55. "UnregisteredSeiTimecode": "DISABLED",
56. "GopSizeUnits": "FRAMES",
57. "ParControl": "INITIALIZE_FROM_SOURCE",
58. "NumberBFramesBetweenReferenceFrames": 2,
59. "RepeatPps": "DISABLED"
60. }
61. },
62. "AfdSignaling": "NONE",
63. "DropFrameTimecode": "ENABLED",
64. "RespondToAfd": "NONE",
65. "ColorMetadata": "INSERT"
66. },
67. "AudioDescriptions": [
68. {
69. "AudioTypeControl": "FOLLOW_INPUT",
70. "CodecSettings": {
71. "Codec": "AAC",
72. "AacSettings": {
73. "AudioDescriptionBroadcasterMix": "NORMAL",
74. "Bitrate": 96000,
75. "RateControlMode": "CBR",
76. "CodecProfile": "LC",
77. "CodingMode": "CODING_MODE_2_0",
78. "RawFormat": "NONE",
79. "SampleRate": 48000,
80. "Specification": "MPEG4"
81. }
82. },
83. "LanguageCodeControl": "FOLLOW_INPUT"
84. }
85. ]
86. }
87. ],
88. "OutputGroupSettings": {
89. "Type": "FILE_GROUP_SETTINGS",
90. "FileGroupSettings": {
91. "Destination": "s3://<ARTIFACT-BUCKET>/MP4/"
92. }
93. }
94. },
95. {
96. "CustomName": "Thumbnails",
97. "Name": "File Group",
98. "Outputs": [
99. {
100. "ContainerSettings": {
101. "Container": "RAW"
102. },
103. "VideoDescription": {
104. "Width": 768,
105. "ScalingBehavior": "DEFAULT",
106. "Height": 576,
107. "TimecodeInsertion": "DISABLED",
108. "AntiAlias": "ENABLED",
109. "Sharpness": 50,
110. "CodecSettings": {
111. "Codec": "FRAME_CAPTURE",
112. "FrameCaptureSettings": {
113. "FramerateNumerator": 20,
114. "FramerateDenominator": 1,
115. "MaxCaptures": 10000000,
116. "Quality": 100
117. }
118. },
119. "AfdSignaling": "NONE",
120. "DropFrameTimecode": "ENABLED",
121. "RespondToAfd": "NONE",
122. "ColorMetadata": "INSERT"
123. }
124. }
125. ],
126. "OutputGroupSettings": {
127. "Type": "FILE_GROUP_SETTINGS",
128. "FileGroupSettings": {
129. "Destination": "s3://<ARTIFACT-BUCKET>/Thumbnails/"
130. }
131. }
132. }
133. ],
134. "AdAvailOffset": 0,
135. "Inputs": [
136. {
137. "AudioSelectors": {
138. "Audio Selector 1": {
139. "Offset": 0,
140. "DefaultSelection": "DEFAULT",
141. "ProgramSelection": 1
142. }
143. },
144. "VideoSelector": {
145. "ColorSpace": "FOLLOW"
146. },
147. "FilterEnable": "AUTO",
148. "PsiControl": "USE_PSI",
149. "FilterStrength": 0,
150. "DeblockFilter": "DISABLED",
151. "DenoiseFilter": "DISABLED",
152. "TimecodeSource": "EMBEDDED",
153. "FileInput": "s3:// <ARTIFACT-BUCKET>/BYUfootballmatch.mp4"
154. }
155. ]
156. }
157. }
MediaConvert ジョブの実行中に、別の Lambda 関数がジョブの完了をチェックします。この関数は次のように記述されます。
1. import json
2. import boto3
3. import pprint
4. def lambda_handler(event, context):
5.
6. client = boto3.client('mediaconvert')
7. endpoint = client.describe_endpoints()['Endpoints'][0]['Url']
8.
9. myclient = boto3.client('mediaconvert', endpoint_url=endpoint)
10.
11. response = myclient.list_jobs(
12. MaxResults=1,
13. Order='DESCENDING')
14.
15. #Status='SUBMITTED'|'PROGRESSING'|'COMPLETE'|'CANCELED'|'ERROR')
16. print(len(response['Jobs']))
17. Status = response['Jobs'][0]['Status']
18. Id = response['Jobs'][0]['Id']
19. print(Id, Status)
20.
学習のための特徴ベクトルの収集
各フレームは、事前学習済みの InceptionV3 モデルを通じて特徴量を抽出します。このモデルは、モデルのトレーニングに使用された ML フレームワーク (MXNet) とともに Lambda 関数内にパッケージ化できるほど小さくなっています。ここでは画像分類モデルの学習については説明しませんが、これを行うための全体的な手順は次のとおりです。
ILSVRC 2012 データを使用して、MXNet で InceptionV3 ネットワークを学習します。ネットワークアーキテクチャとデータセットの詳細については、Rethinking the Inception Architecture for Computer Vision を参照してください。
事前学習済みモデルを Lambda 関数 (model.json ファイルと model.params ファイル) に読み込み、最後のレイヤーを削除します。出力層では分類は実行しませんが、1024×1 サイズの特徴ベクトルを出力します。
フレームが Lambda 関数を通るたびに、Amazon Kinesis Data Streams を介してこの特徴ベクトルがデータストリームに出力されます。
このストリームのトピックは Amazon Kinesis Data Firehose を使用して収集され、別の S3 バケットに出力されます。
AWS Fargate ジョブでは、フレームが生成された元の順序に基づいてファイルが順序付けられます。この Lambda 関数の 1,000 個のインスタンスが並列にトリガーされ、関数ごとに 1 つのフレームを処理するため、出力の順序が若干ずれている可能性があります。Fargate の代わりに SageMaker Processing を使用することもできます。これにより、最終的なトレーニングデータが得られ、フレームのグループをハイライトとして識別できる SageMaker カスタム動画分類モデルで使用できます。この例では、サッカー動画のハイライトはペナルティキックです。
この Lambda 関数のコードは次のとおりです。
1. import logging
2. import boto3
3. import json
4. import numpy as np
5. import tempfile
6.
7. logger = logging.getLogger()
8. logger.setLevel(logging.INFO)
9. region =
10. relevant_timestamps = []
11.
12. import mxnet as mx
13.
14.
15. def load_model(s_fname, p_fname):
16. """
17. Load model checkpoint from file.
18. :return: (arg_params, aux_params)
19. arg_params : dict of str to NDArray
20. Model parameter, dict of name to NDArray of net's weights.
21. aux_params : dict of str to NDArray
22. Model parameter, dict of name to NDArray of net's auxiliary states.
23. """
24. symbol = mx.symbol.load(s_fname)
25. save_dict = mx.nd.load(p_fname)
26. arg_params = {}
27. aux_params = {}
28. for k, v in save_dict.items():
29. tp, name = k.split(':', 1)
30. if tp == 'arg':
31. arg_params[name] = v
32. if tp == 'aux':
33. aux_params[name] = v
34. return symbol, arg_params, aux_params
35.
36. sym, arg_params, aux_params = load_model('model2.json', 'model2.params')
37.
38. #load json and params into model
39. #mod = None
40.
41. # We bind the module with the input shape and specify that it is only for predicting. The number 1 added before the image shape (3x224x224) means that we will only predict one image at a tim
42.
43. # FULL MODEL
44. #mod = mx.mod.Module(symbol=sym, label_names=None)
45. #mod.bind(for_training=False, data_shapes=[('data', (1,3,224,224))], label_shapes=mod._label_shapes)
46. #mod.set_params(arg_params, aux_params, allow_missing=True)
47.
48.
49. from collections import namedtuple
50. Batch = namedtuple('Batch', ['data'])
51.
52. def lambda_handler(event, context):
53. # PARTIAL MODEL
54. mod2 = None
55. all_layers = sym.get_internals()
56. print(all_layers.list_outputs()[-10:])
57. sym2 = all_layers['global_pool_output']
58. mod2 = mx.mod.Module(symbol=sym2,label_names=None)
59. #mod2.bind(for_training=False, data_shapes = [('data', (1,3,224,224))], label_shapes = mod2._label_shapes)
60. mod2.bind(for_training=False, data_shapes=[('data', (1,3,299,299))])
61. mod2.set_params(arg_params, aux_params)
62.
63. #Get image(s) from s3
64. s3 = boto3.resource('s3')
65. bucket = s3.Bucket(event['bucketname'])
66. object = bucket.Object(event['filename'])
67.
68. #img = mx.image.imread('image.jpg')
69.
70. tmp = tempfile.NamedTemporaryFile()
71. with open(tmp.name, 'wb') as f:
72. object.download_fileobj(f)
73. img=mx.image.imread(tmp.name)
74. # convert into format (batch, RGB, width, height)
75. img = mx.image.imresize(img, 299, 299) # resize
76. img = img.transpose((2, 0, 1)) # Channel first
77. img = img.expand_dims(axis=0) # batchify
78.
79. mod2.forward(Batch([img]))
80. out = np.squeeze(mod2.get_outputs()[0].asnumpy())
81.
82. kinesis_client = boto3.client('kinesis')
83. put_response = kinesis_client.put_record(StreamName = 'bottleneck_stream',Data = json.dumps({'filename':event['filename'],'features':out.tolist()}), PartitionKey = "partitionkey")
84. return 'Wrote features to kinesis stream'
モデルの学習用にイメージにラベルを付ける
前述のとおり、UCF101 動作認識データセットを使用します。このデータセットは、次のコマンドを使用して Jupyter Notebook インスタンス内から取得できます。
!wget http://crcv.ucf.edu/data/UCF101/UCF101.rar
ダウンロードした.rar ファイルに含まれるすべての動作認識データセットについて、InceptionV3 から同じ特徴ベクトルを抽出します (このファイルには、soccer penalty や soccer juggling といったラベルのように、今回のサッカーの例に関連する動作を含む 101 種類の動作のサンプルが含まれています)。
TensorFlow でカスタム LSTM モデルを作成し、前のステップで抽出した特徴量を使用してモデルを学習します。LSTM モデルは次のように構成されています。
レイヤ 1 – 2048 個の LSTM セルレイヤ 2 – 512 個の Dense セルレイヤ 3 – Dropout レイヤ (p=0.5)レイヤ 4 – 101 クラスの Softmax レイヤ
Model.summary() は次のサマリーを出力します。
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 2048) 33562624
_________________________________________________________________
dense_1 (Dense) (None, 512) 1049088
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 101) 51813
=================================================================
Total params: 34,663,525
Trainable params: 34,663,525
Non-trainable params: 0
___________________________
より関連性の高いデータセットを使用して、必要なクラスのみを分類タスクに含める必要があります。今回選択した問題の性質上、このオープンデータセットのみを利用しましたが、お客様独自の動画からハイライトを抽出する場合は、独自にラベル付けした動画データセットを使用することができます。
Notebook で次のコードを使用してモデルを保存します。
trainedmodel.save('lstm_model.h5')
SageMaker を使用してモデルをホストするために、次のコードを含むコンテナと Dockerfile を作成します。推論のための Python エントリポイントのコードを次に示します。
1. #!/usr/bin/env python
2. from __future__ import print_function import os import sys import traceback import numpy as np import pandas as pd
3. import tensorflow as tf from keras.layers import Dropout, Dense from keras.wrappers.scikit_learn import
4. KerasClassifier from keras.models import Sequential from keras.models import load_model def train():
5. print('Starting the training.')
6. try:
7. model = load_model('lstm_model.h5')
8. print('Model is loaded ... Training is complete.')
9. except Exception as e:
10. # Write out an error file. This will be returned as the failure Reason in the DescribeTrainingJob result.
11. trc = traceback.format_exc()
12. with open(os.path.join(output_path, 'failure'), 'w') as s:
13. s.write('Exception during training: ' + str(e) + '\n' + trc)
14. # Printing this causes the exception to be in the training job logs
15. print(
16. 'Exception during training: ' + str(e) + '\n' + trc,
17. file=sys.stderr)
18. # A non-zero exit code causes the training job to be marked as Failed.
19. sys.exit(255) if __name__ == '__main__':
20. train()
21. # A zero exit code causes the job to be marked a Succeeded.
22. sys.exit(0)
Docker イメージをコンテナ化し、Amazon Elastic Container Registry (Amazon ECR) にプッシュします。
1. %%sh
2.
3. # The name of our algorithm
4. algorithm_name=kerassample14
5.
6. cd container
7.
8. chmod +x keras-model/train
9. chmod +x keras-model/serve
10.
11. account=$(aws sts get-caller-identity --query Account --output text)
12.
13. # Get the region defined in the current configuration (default to us-west-2 if none defined)
14. region=$(aws configure get region)
15. region=${region:-us-west-2}
16.
17. fullname="${account}.dkr.ecr.${region}.amazonaws.com/${algorithm_name}:latest"
18. echo $fullname
19. # If the repository doesn't exist in ECR, create it.
20.
21. aws ecr describe-repositories --repository-names "${algorithm_name}" > /dev/null 2>&1
22.
23. if [ $? -ne 0 ]
24. then
25. aws ecr create-repository --repository-name "${algorithm_name}" > /dev/null
26. fi
27.
28. # Get the login command from ECR and execute it directly
29. $(aws ecr get-login --region ${region} --no-include-email)
30.
31. # Build the docker image locally with the image name and then push it to ECR
32. # with the full name.
33.
34. docker build -t ${algorithm_name} .
35. docker tag ${algorithm_name} ${fullname}
36.
37. docker push ${fullname}
最後に、SageMaker でモデルをホストします。
1. account = sess.boto_session.client('sts').get_caller_identity()['Account']
2. region = sess.boto_session.region_name
3. image = f'<account number>.dkr.<region>.amazonaws.com/<containername>:latest'
4.
5. classifier = sage.estimator.Estimator(
6. image,
7. role,
8. 1,
9. 'ml.c5.2xlarge',
10. output_path="s3://{}/output".format(sess.default_bucket()),
11. sagemaker_session=sess)
12.
13.
14. from sagemaker.predictor import csv_serializer
15. predictor = classifier.deploy(1, 'ml.m5.xlarge', serializer=csv_serializer)
SageMaker は、入力が一連の特徴ベクトル (例えば、10 枚のフレームあるいは画像が 10×1024 の特徴行列に対応します) であり、出力が UCF101 の 101 個のクラスの確率分布となる推論を実行するエンドポイントを提供します。今回は soccer penalty クラスだけが関心事となります。このブログでは、UCF101 データセットを使用していますが、お客様独自のユースケースでは、関連性の高い動作認識データセットや事前学習済みモデルの調査に時間をかけてください。
ハイライトの抽出
このアーキテクチャでは、Fargate ジョブは一連の特徴ベクトルを入力として SageMaker の estimator を順次呼び出し、一連のフレームを取り上げるかどうかの判定結果を Amazon DynamoDB テーブルに保存します。Fargate ジョブが完了すると、別の Lambda 関数 (次のコードを参照) が DynamoDB テーブルを使用してクリッピングジョブの定義を編集し、それを MediaConvert ジョブに送信します。この MediaConvert ジョブは、元の動画を目的の動作クラスに分類された小さなセクションに分割します。今回はサッカーのペナルティキックになります。抽出された動画は、同じ Lambda 関数内から Boto3 コマンドを使用して、アカウントの外部からアクセスできるように公開されます。
1. import json
2. import boto3
3. import time
4. from boto3.dynamodb.conditions import Key, Attr
5. import math
6.
7. s3_location = 's3://<ARTIFACT-BUCKET>/BYUfootballmatch.mp4'
8.
9. def start_mediaconvert_job(data, sec_in, sec_out):
10.
11.
12. client = boto3.client('mediaconvert')
13. endpoint = client.describe_endpoints()['Endpoints'][0]['Url']
14.
15. myclient = boto3.client('mediaconvert', endpoint_url=endpoint)
16.
17. data['Settings']['Inputs'][0]['FileInput'] = s3_location
18.
19. starttime = time.strftime('%H:%M:%S:00', time.gmtime(sec_in))
20. endtime = time.strftime('%H:%M:%S:00', time.gmtime(sec_out))
21.
22. data['Settings']['Inputs'][0]['InputClippings'][0] = {'EndTimecode': endtime, 'StartTimecode': starttime}
23.
24. data['Settings']['OutputGroups'][0]['Outputs'][0]['NameModifier'] = '-from-'+str(sec_in)+'-to-'+str(sec_out)
25.
26. response = myclient.create_job(
27. Queue=data['Queue'],
28. Role=data['Role'],
29. Settings=data['Settings'])
30.
31. def lambda_handler(event, context):
32.
33.
34. dynamodb = boto3.resource('dynamodb')
35. table = dynamodb.Table('sports-lstm-final-output')
36. response = table.scan()
37. timeins = []
38. timeouts=[]
39. for i in response['Items']:
40. if(i['pickup']=='yes'):
41. timeins.append(i['timein'])
42. timeouts.append(i['timeout'])
43.
44. timeins = sorted([int(x) for x in timeins])
45. timeouts =sorted([int(x) for x in timeouts])
46. mintime =min(timeins)
47. maxtime =max(timeouts)
48.
49. print('mintime='+str(mintime))
50. print('maxtime='+str(maxtime))
51.
52. print(timeins)
53. print(timeouts)
54. mystarttime = mintime
55.
56. #find continuous range
57. ranges = {}
58. maxisofar=0
59. rangecount = 0
60. lastnum = timeouts[0]
61. for i in range(len(timeins)-1):
62. c=0
63. if(timeouts[i] >= lastnum):
64. for j in range(i,len(timeouts)-1):
65. if(timeins[j+1] - timeins[j] == 20 and timeouts[j] - timeins[i] == 40 + c*20 ):
66. c=c+1
67. continue
68. if(timeins[i+1] - timeins[i] > 20 and timeouts[j] - timeins[i] == 40 ):
69. print('single frame',i,j)
70. ranges[rangecount] = {'start':timeins[i], 'end':timeouts[i], 'count':1}
71. rangecount=rangecount+1
72. lastnum = timeouts[i+1]
73. continue
74.
75. if(c>0):
76.
77. ranges[rangecount] = {'start':timeins[i], 'end':timeouts[i+c], 'count':c}
78. rangecount=rangecount+1
79. lastnum = timeouts[i+c+1]
80.
81. print(lastnum)
82. if(lastnum == timeouts[-1]):
83. # Last frame is a single frame
84. ranges[rangecount] = {'start':timeins[-1], 'end':timeouts[-1], 'count':1}
85.
86. print(ranges)
87. #Find max continuous range
88. maxc = 0
89. maxi = 0
90. for i in range(len(ranges)):
91. if maxc < ranges[i]['count']:
92. maxi = i
93. maxc = ranges[i]['count']
94. buffer = 1 #seconds
95.
96.
97. with open('mediaconvert.json') as f:
98. data = json.load(f)
99.
100. # DO THIS for ALL RANGES
101. for i in range(len(ranges)):
102. if ranges[i]['count']:
103. sec_in = math.floor(ranges[i]['start']/20.0) - buffer
104. sec_out = math.ceil(ranges[i]['end']/20.0) + buffer #20:1 was the framer rate in original video
105. sec_in = 0 if sec_in<0 else sec_in
106. start_mediaconvert_job(data, sec_in, sec_out)
107. time.sleep(1)
108.
109. print(ranges)
110. return json.dumps({'bucket':'elemental-media-input','prefix':'High','postfix':'mp4'})
デプロイの前提条件
このソリューションをデプロイするには、Amazon S3 バケットを作成して ARTIFACT-BUCKET として指定する必要があります。このバケットは、動画ファイルとモデルアーティファクトの保存に使用されます。次の AWS CLI コマンドを実行して Amazon S3 バケットを作成できます。(訳者注:<ARTIFACT-BUCKET> の部分を作成したいバケット名に書き換えてから実行します。)
aws s3api create-bucket --bucket <ARTIFACT-BUCKET >
次に、次のコマンドを実行して、必要なアーティファクトをアーティファクトバケットにコピーします。
aws s3 cp s3://aws-ml-blog/artifacts/sportshighlights/ \
s3://<ARTIFACT-BUCKET > --recursive --copy-props none
AWS CloudFormation を使用してソリューションをデプロイする
本記事では、リソースの作成とワークフローの設定に使用する AWS CloudFormatio n テンプレートを提供しています。AWS CloudFormation では、インフラストラクチャをコードとして扱うことで、AWS リソースのモデル化、プロビジョニング、管理が可能となります。
これを自分のアカウントにデプロイするには、次の手順に従います。
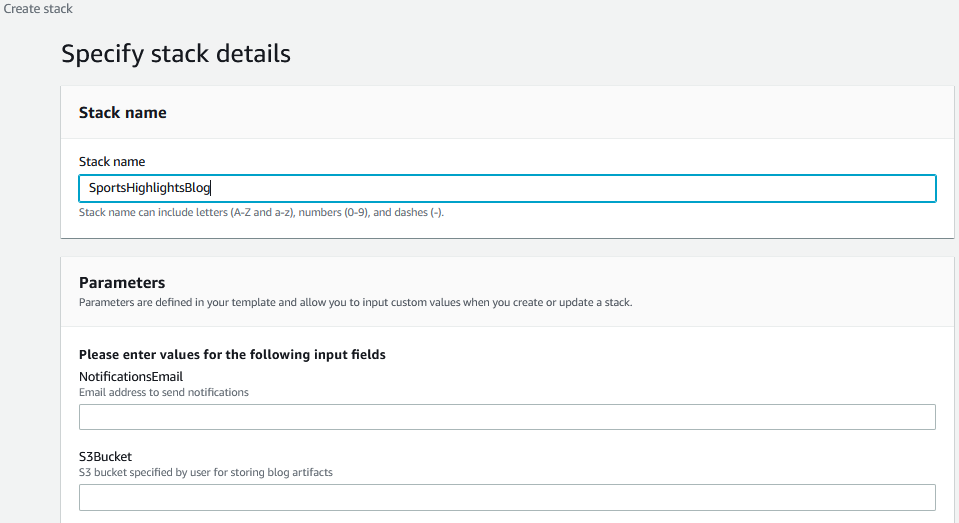
[Launch Stack] を選択します。
スタックの名前を入力します。
Step Functions ワークフローからの通知を受信する E メールアドレスを入力します。
[S3Bucket] には、前に作成した ARTIFACT-BUCKET の名前を入力します。
[Next] をクリックします。
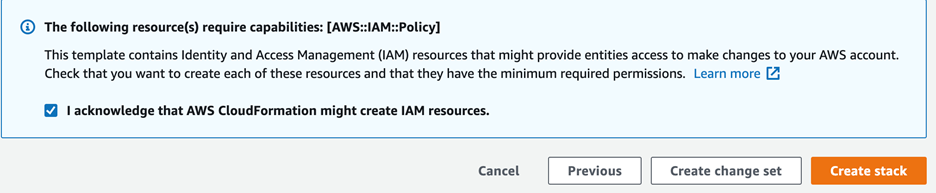
[Review] ページで、[I acknowledge that AWS CloudFormation might createIAM resources.] を選択します。
[Create stack] を選択します。
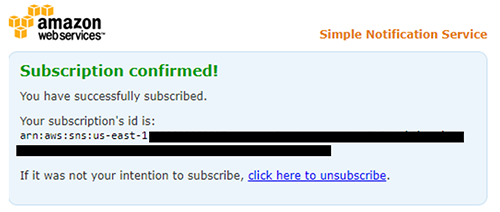
スタックが正常に作成されると、トピックへのサブスクライブのリクエストが記載された E メールが届きます。[Confirm subscription] を選択します。
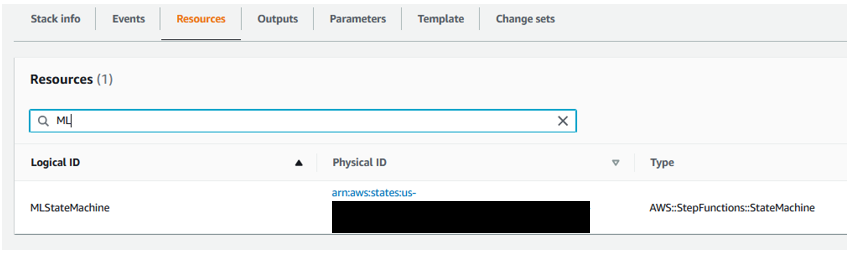
AWS CloudFormation コンソールから、作成したスタックの [Resources] タブに移動します。MLStateMachine リソースのハイパーリンク (Physical ID) をクリックします。
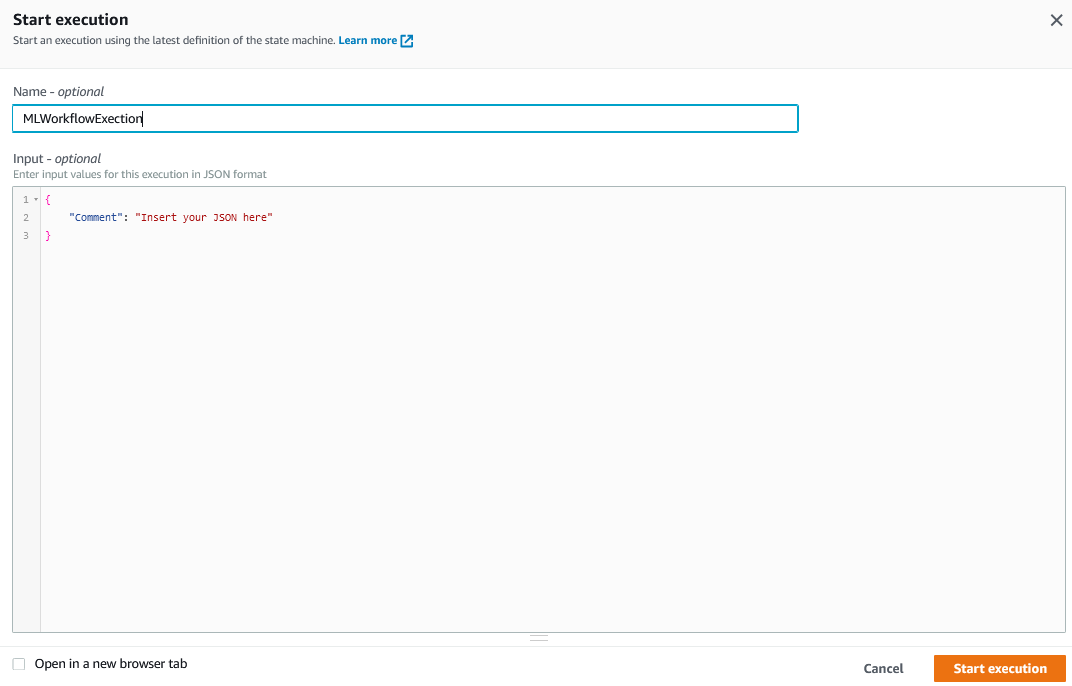
Step Functions コンソールに移動します。[Start Execution] を選択します。
[Name] を入力し、[Input] はデフォルトのまま [Start Execution] を選択します。
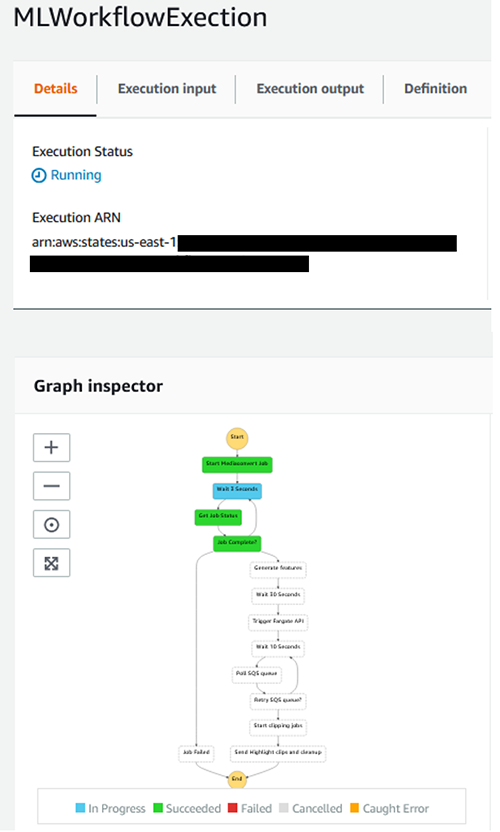
[Graph Inspector] に移動すると、Step Functions の実行の進行状況をモニターできます。
Step Functions ワークフローが完了するまで待ちます。
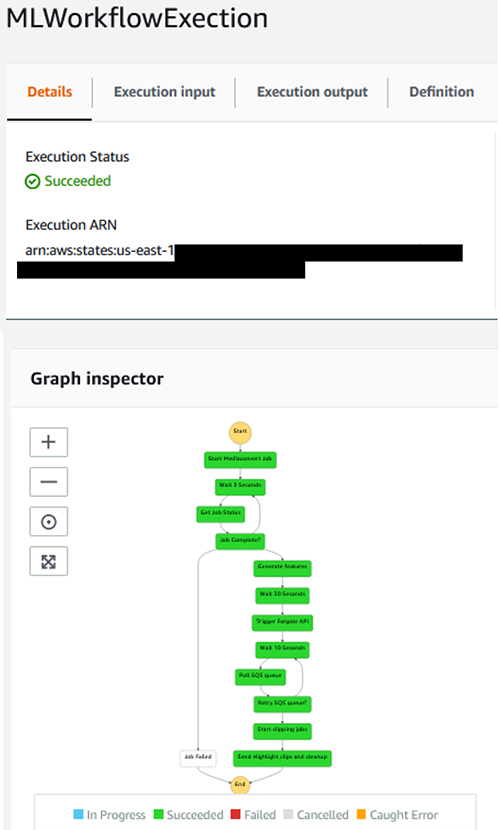
Step Functions の実行が完了すると、元の動画のハイライト動画となる Amazon S3 ファイルが記載された E メールが届きます。ベストプラクティスに従い、これらのハイライト動画はパブリックには公開されません。作成した Amazon S3 バケットに移動すると、HighlightClips という名前のフォルダに動画が出力されています。
最後に、以下の動画を入力とした場合の結果を確認してみてください。
以下のペナルティキックのハイライト動画が生成されています。
クリーンアップ
継続的な課金が発生しないようにするには、AWS CloudFormation コンソールからスタックを削除して、インフラストラクチャをクリーンアップします。
ブログ用に作成したアーティファクトバケットを空にします。次の AWS CLI コマンドを実行できます。
aws s3 rm s3://<ARTIFACT-BUCKET > --recursive
aws s3api delete-bucket --bucket <ARTIFACT-BUCKET >
その後、AWS マネジメントコンソールで AWS CloudFormation に移動し、作成したスタックを選択して [Delete] を選択します。
まとめ
この記事では、カスタム SageMaker モデルを使用して、ノーカットのスポーツ動画からハイライトを生成する方法を説明しました。このソリューションを拡張して、スラムダンク、タッチダウン、ホームラン、シクサーズ(訳者注:NBA のフィラデルフィア・セブンティシクサーズ)を含むハイライトを、お気に入りのスポーツ動画、または他の番組、映画、会議、その他の動画形式のコンテンツから生成できます。ただし、事前学習済みモデルまたはユースケースに固有のモデルを学習している場合に限ります。
前処理をより簡単にする方法の詳細については、Amazon SageMaker Processing を参照してください。
PAN Resnet 101、TSM、R2+1D BERT などの最新の動作認識モデルをファインチューニングする方法、またはエンドポイントとして SageMaker でホストする方法の詳細については、Deploy a Model in Amazon SageMaker を参照してください。
著者について
翻訳はソリューションアーキテクト千代田が担当しました。原文はこちら です。



 Shreyas Subramanian は AI/ML のスペシャリストソリューションアーキテクトであり、機械学習を使用して AWS クラウドでのビジネス上の課題を解決することで、お客様を支援しています。
Shreyas Subramanian は AI/ML のスペシャリストソリューションアーキテクトであり、機械学習を使用して AWS クラウドでのビジネス上の課題を解決することで、お客様を支援しています。 Mohit Mehta は、AI/ML とビッグデータテクノロジーの専門知識を持つ AWS プロフェッショナルサービス組織のリーダーです。Mohit は、コンピューターサイエンスの修士号、12 種類の AWS 認定、ウィリアム・アンド・メアリー大学で MBA、ミシガン・ロス・スクール・オブ・ビジネスで GMP を取得しています。
Mohit Mehta は、AI/ML とビッグデータテクノロジーの専門知識を持つ AWS プロフェッショナルサービス組織のリーダーです。Mohit は、コンピューターサイエンスの修士号、12 種類の AWS 認定、ウィリアム・アンド・メアリー大学で MBA、ミシガン・ロス・スクール・オブ・ビジネスで GMP を取得しています。 Vikrant Kahlir は、ソリューションアーキテクチャチームのプリンシパルアーキテクトです。AWS の Strategic カスタマーの製品およびエンジニアリングチームと協力して、マネージドデータベース、AI/ML、HPC、自律コンピューティング、IoT 向けの AWS サービスを使用したテクノロジーソリューションでお客様を支援しています。
Vikrant Kahlir は、ソリューションアーキテクチャチームのプリンシパルアーキテクトです。AWS の Strategic カスタマーの製品およびエンジニアリングチームと協力して、マネージドデータベース、AI/ML、HPC、自律コンピューティング、IoT 向けの AWS サービスを使用したテクノロジーソリューションでお客様を支援しています。