Amazon Web Services ブログ
AWS GlueとJDBCを使用したSAP HANAからのデータ抽出
必要なデータを検索するためにSAP GUIを果てしなくクリックすることがありませんか?そして、必要な結果を得るための単純なクエリを実行するだけのために、表をスプレッドシートに出力しなければならないときがありませんか?
私にはあります。そのため、SAPデータに簡単にアクセスして、思い通りに利用できる場所に格納したいと思っていました。
この記事では、AWS Glueを使用してSAP HANAとの接続を構成し、 Amazon S3にデータを抽出します。このソリューションにより、SAPをさまざまな分析サービスや可視化サービスに公開し、必要な結果を得ることのできる、シームレスなメカニズムを実現します。
概要
SAPからデータを抽出するために利用できるツールはいろいろとあります。ただし、それらのほとんどすべては、実装、展開、およびライセンスの取得に数か月かかります。また、これらは「一方通行のドア」のアプローチです。意思決定を行った後に元の状態に戻るのが困難です。
AWSには、“双方向のドア”という哲学があります。AWS Glue、Amazon Athena、そしてAmazon QuickSightは、AWSが提供する従量課金制のクラウドネイティブなサービスです。
- AWS Glue – この完全マネージドの抽出、変換、およびロード (ETL)を行うサービスにより、分析用のデータを簡単に準備、やり取りできます。実装または管理するインフラストラクチャはありません。AWS Glueは、完全マネージドのスケールアウトされるApache Spark環境で、ETLジョブを実行するために必要なリソースの展開、構成、スケーリングを処理します。
- Athena – このインタラクティブなクエリサービスにより、標準SQLを使用してS3のデータを簡単に分析できます。Athenaはサーバーレスなため、管理するインフラストラクチャはなく、実行するクエリに対してのみ料金が発生します。S3にあるデータを指定し、スキーマを定義して、標準SQLを使用してクエリの実行を開始するだけです。
- Amazon QuickSight – この完全マネージドで高速なクラウドベースのビジネスインテリジェンスサービスにより、組織内のすべての人に洞察を簡単に提供できます。Amazon QuickSightを使用すると、ML Insightsを含むインタラクティブなダッシュボードを簡単に作成、公開できます。
ウォークスルー
この記事では、上述のAWSリソースに加えてAWS Secrets Managerを使用して、SAP HANAとの接続を構成し、データを抽出します。
前提条件
接続を構成する前に、認証情報、接続詳細、およびJDBCドライバーを安全な場所に保存する必要があります。まず、この演習用にS3バケットを作成します。
S3バケットとフォルダの作成
- S3コンソールから、
sap-kna1というS3バケットを作成します。オブジェクトが一般公開されないように、Amazon S3 ブロックパブリックアクセスを使用します。. sap-kna1バケットを作成したら、[フォルダの作成]を選択します。- [フォルダの作成]ページから、[出力]用の[フォルダの名前やプレフィックスの名前]を入力します。
これで、新しいバケットと階層を使用する準備ができました。
次に、Secrets Managerを使用して、認証情報と接続詳細を安全に保存します。
新しいシークレットの作成
- Secrets Managerコンソールから、[新しいシークレットを保存する]、[その他のシークレット]と選択します。
- [シークレットキー/値]タブから [行を追加]ボタンで次のパラメータごとの行を作成し、次の値を入力していきます。
- [db_username]として、[SAPABAP1]を入力します。 これは、主要なSAPスキーマへの読み取りアクセス権を持ち、参照する予定のテーブルに対する読み取り権限を持つHANAデータベースユーザーです。詳細については、DBAまたはSAP Basisチームと連携してください。
- [db_password]として、[NotMyPassword123]を入力します。これは、Secrets Managerを使用して暗号化するHANAデータベースユーザーのパスワードです。
- [db_url]として、[jdbc:sap://10.0.52.188:30013/?instanceNumber=00&databaseName=S4A]を入力します。MDCシステムのテナントデータベースに接続します。詳細については、DBAまたはSAP Basisチームと連携してください。
- [db_table]として、[KNA1]を入力します。ここでは、SAPの顧客マスターにあるKNA1データを使用します。
- [driver_name]として、[com.sap.db.jdbc.Driver]を入力します。 このエントリーは、AWS GlueジョブにSAP HANA JDBCドライバーを使用することを示しています。
- [output_bucket]として、[s3://sap-kna1/output/]を入力します。 これは、JDBCドライバーと出力ファイルを整理するために使用する上述で作成したバケットです。
これらの値をすべて入力すると、画面は次のスクリーンショットのようになります。

- ページの下部で、暗号化キーを選択します。この演習では、提供されているデフォルトキーを使用します。任意のキーを自由に使用できますが、そのキーにアクセスできることを確認してください。
- [次]を選択します。
- [シークレットの名前]として、[SAP-Connection-Info]を入力します。
- (オプション) 説明を入力します。
- [次]を選択します。
- シークレットはローテーションできますが、この演習では、デフォルトの[自動ローテーションを無効にする]のままにし、[次]を選択します。
- 次のページでは、シークレットの構成を確認し、[保存]を選択します。
次のスクリーンショットは、シークレットが正常に保存されたことを示しています。

次に、AWS GlueジョブのためのIAMロールを作成します。このIAMロールは、抽出ジョブを作成する前に作成するか、実行中に作成できます。この演習では事前に作成します。
IAMロールの作成
- IAMコンソールから、左側のナビゲーションペインで[ロール]を選択し、[ロールの作成]を選択します。信頼されたエンティティのロールタイプはAWSサービスである必要があるため、この記事では[AWS Glue]を選択します。
- [次のステップ: アクセス権限]を選択します。
- ポリシー名の下を検索し、次のポリシーのチェックボックスを選択します。
- [AWSGlueServiceRole]
- [SecretsManagerReadWrite] このポリシーにより、AWS GlueジョブはSecrets Managerに保存されているデータベースの認証情報にアクセスできます。このポリシーは公開されており、テスト目的でのみ使用されます。カスタムポリシーを作成して、ETLジョブで使用するシークレットのみにアクセスを絞り込みます。
- [AmazonS3FullAccess] このポリシーにより、AWS GlueジョブはS3に保存されているデータベースJARSにアクセスし、AWS GlueジョブのPythonスクリプトをアップロードできます。
- [AmazonAthenaFullAccess] このポリシーにより、Amazon QuickSightをサポートするために、AthenaがS3の抽出ファイルを読み取れるようになります。
- [次のステップ: 確認]を選択します。
- [ロール名]には、例えば、[GluePermissions]を入力します。
- (オプション) [ロールの説明]欄に説明を入力します。
- [ポリシー]の下に上述で選択した4つのポリシーがあることを確認します。
- [ロールの作成]を選択します。
IAMロールを作成したら、次のスクリーンショットに示すように、S3バケットにJDBCドライバーをアップロードします。この例では、SAPサポートサイトで入手できるSAP HANAドライバーを使用しています。
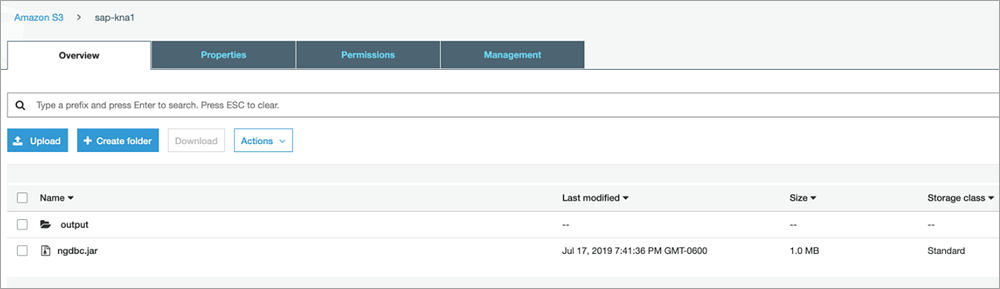
ソリューションの構成
前提条件を設定したら、SAP HANAのためのAWS Glueジョブを作成します。
AWS Glueジョブの接続
- AWS Glueコンソールから、左側のナビゲーションペインで[データベース]の下の[接続]を選択し、[接続の追加]を選択します。
- [接続名]として[KNA1]を入力し、 [接続タイプ]として[JDBC]を選択します。
- (オプション) 説明を入力します。
- [次]を選択します。
- [JDBC URL]、[ユーザー名]、[パスワード]、[VPC]、そして[サブネット]に値を入力します。
- [セキュリティグループ]は、[default]を選択します。
- [次]を選択します。
- 接続プロパティと接続アクセスパラメータを確認し、[完了]を選択します。
次に、実際のAWS Glueジョブを作成します。
AWS Glueジョブの作成
- 左側のナビゲーションペインで[ETL]を選択し、[ジョブ]を選択します。
- [ジョブの追加]を選択します。
- ジョブプロパティを入力します。
- [名前]として、ジョブに名前をつけます (この演習では、KNA1)。
- [IAMロール]は、 上述で作成したIAMロールを選択します (GluePermissions)。
- [このジョブ実行]は、[ユーザーが作成する新しいスクリプト]を選択します。
- [Type]は、[Python shell]を選択します。
- [スクリプトファイル名]には、[KNA1]を入力します。
- [スクリプトが保存されているS3パス]には、上述で作成したS3バケットを指定します。
- [セキュリティ設定、スクリプトライブラリおよびジョブパラメータ]の下にある[依存 JARSパス]には、JDBCドライバーの格納場所を入力します。例えば、[s3://sap-kna1/ngdbc.jar]です。
- 他のすべてのフィールドはデフォルトのままにしておきます。
- [次]を選択します。
- [接続]の概要ページの[必要な接続]で接続[KNA1]を追加し、[ジョブを保存してスクリプトを編集]を選択します。スクリプトエディターが開きます。
- 空白のエディタの中で次のスクリプトを追加し、[保存]を選択します。
ETLジョブの実行
AWS Glueジョブを作成したので、次のステップはそれを実行することです。
- スクリプトエディタで、新しいジョブを保存したことを再確認し、[ジョブを実行]を選択します。
- パラメータを確認し、[ジョブの実行]を選択します。
今回が最初の実行のため、次のスクリーンショットに示すように、5〜10分間、日付と時刻の右側に[実行の保留中]のメッセージが表示される場合があります。舞台裏では、AWSはジョブを実行するためにSparkクラスターをスピンアップしています。
成功した実行ジョブのログは、次のスクリーンショットのようになります。
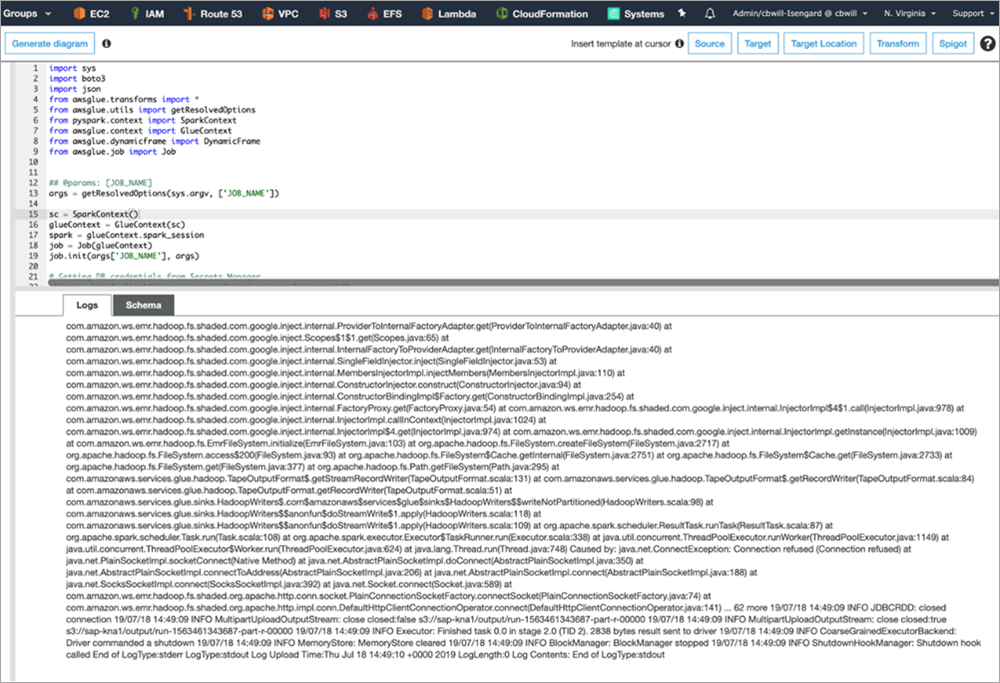
もしエラーが発生した場合は、Amazon CloudWatchの/aws-glue/jobs/配下から確認します。
- 抽出されたファイルを表示するには、上述で定義したS3出力バケットに移動し、ファイルをダウンロードして内容を確認します。

データの可視化
SAPからS3にデータを取得できました。エンドユーザーが自身のロジックを適用し、スプレッドシートで通常行うことを自動化できるように、コンテキスト化する方法が必要です。これを行うには、S3からAthena、およびAmazon QuickSightとの間でデータの統合を構成します。
AWS Glueデータベースの作成
- AWS Glueの画面で、[データベース]、[データベースの追加]と選択します。
- [データベース名]には[KNA1]を入力し、 それ以外のフィールドは空のまま、[作成]を選択します。
- [分類子]、[分類子の追加]と選択します。[分類子]に[KNA1]を入力し、[作成]を選択します。
- [テーブル]を選択し、[テーブルの追加]から[クローラーを使用してテーブルを追加]を選択します。
- クローラーの名前は[KNA1]とし、 [選択された分類子]に[KNA1]を追加します。
- [データストア]を選択し、抽出ファイルのための[インクルードパス]を指定します。
- [次]を選択します (他のデータストアは追加しません)。
- [既存のIAMロールを選択]を選択し、[GluePermissions]を選択します。
- この演習では、[オンデマンドで実行]を選択します。
- [データベース]は、データベース[KNA1]を選択します。
- [完了]を選択します。
- 次のページで、[今すぐ実行]を選択します。
- クローラーが完了したら、クローラーの右側にある[ログ]を選択して、CloudWatchでログを表示します。
Athenaでクエリの作成
- Athenaコンソールで、AWS Glueクローラーによって作成されたテーブルを選択します。
- テーブルをプレビューするには、[クエリ実行]を選択します。これにより、ユーザーは複数のデータセットに対してクエリを実行し、最小限のリフトでプレビューすることができます。
次に、これらのクエリを可視化に拡張して、データをさらに充実させます。
Amazon QuickSightでS3バケットアクセスの有効化
- Amazon QuickSightコンソールを開きます。
- Amazon QuickSightを初めて使用する場合は、[QuickSightアカウントの作成]ページが表示されます。[QuickSightアカウント名]に[KNA1]を入力し、[通知用のEメールアドレス]にメールアドレスを入力します。
- [完了し、Amazon QuickSightに移動]を選択します。
- 右上の[QuickSightの管理]、[セキュリティとアクセス権限]を選択します。
- [接続された製品とサービス]の下の[追加または削除する]を選択します。
- 次の画面の[接続された製品とサービス]で[Amazon S3]、[sap-kna1]と選択し、[バケットの選択]を選択します。.
- [更新]を選択してから、Amazon QuickSightアイコンを選択します。
Amazon QuickSightで可視化の作成
- Amazon QuickSightコンソールから、[新しい分析]、[新しいデータセット]と選択します。
- [Athena]を選択します。
- [新規Athenaデータソース]ページで、[データソース名]に[KNA1]を入力し、[データソースを作成]を選択します。
- [テーブルの選択]ページで、[データベース: 複数のテーブルを含みます。]に[KNA1]を選択します。[テーブル: 可視化できるデータを含みます。]には、[出力]を選択し、[選択]を選択します。
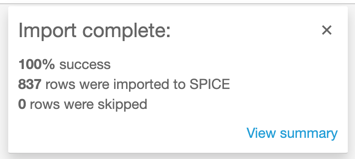
- [迅速に分析するためにSPICEにインポート]、[可視化]と選択します。インポートが完了したというメッセージが表示されます。
Amazon QuickSightのドラッグアンドドロップ機能により、S3とAthenaを使用して持ち込まれたフィールドから可視化を構成できるようになりました。

結論
この記事では、AWS Glueを使用してSAP HANAとの接続を構成し、S3にデータを抽出する方法を説明しました。これにより、SAPをさまざまな分析サービスや可視化サービスに公開し、必要な結果を得ることのできる、シームレスなメカニズムを実現します。データをスプレッドシートに出力するために、SAPのトランザクションコードSE16を使用する必要はなくなりました。データを取り扱うには別のツールにアップロードするだけで済みます。
SAPにHANAのライセンスモデルを問い合わせて、データを抽出するときにHANA内でサポート可能な機能を使用していいかを確認してください。
翻訳はPartner SA 河原が担当しました。原文はこちらです。