Amazon Web Services ブログ
Amazon.com カタログチームが Amazon Bedrock で自己学習型生成 AI を構築した方法
本記事は 2026 年 1 月 23 日 に公開された「How the Amazon.com Catalog Team built self-learning generative AI at scale with Amazon Bedrock」を翻訳したものです。
Amazon.com のカタログは、顧客のショッピング体験を支える基盤です。検索、レコメンデーション、商品発見に必要な信頼できる商品情報を一元管理しています。出品者が新しい商品を登録すると、カタログシステムは寸法、素材、互換性、技術仕様などの構造化された属性を抽出し、顧客の検索行動に合ったタイトルなどのコンテンツを生成します。タイトルは色やサイズを単純に列挙するのではなく、出品者の意図、顧客の検索行動、発見しやすさのバランスを取る必要があります。毎日数百万件の登録でこうした複雑さが発生するため、カタログエンリッチメントは自己学習 AI の理想的な実証の場となっています。
本記事では、Amazon カタログチームが Amazon Bedrock で、精度を継続的に向上させながらコストを削減する自己学習システムを構築した方法を紹介します。
課題
生成 AI の運用環境では、モデルのパフォーマンス改善に継続的な取り組みが必要です。数百万の商品を処理する中で、エッジケース、新しい用語、精度が低下しやすいドメイン固有のパターンに必ず遭遇します。従来のアプローチでは、応用科学者が障害を分析し、プロンプトを更新し、変更をテストして再デプロイしていました。従来の方法でも機能しますが、リソースを大量に消費し、実際の処理量と多様性に追いつくのが困難です。課題は、システムを改善できるかどうか自体ではなく、手動介入に依存せずに自動的に改善する仕組みをどう作るかです。Amazon カタログでは、この課題に正面から取り組みました。大規模モデルは精度を提供しますが、私たちの処理量に対して効率的にスケールできません。一方、小規模モデルは出品者が最も支援を必要とする複雑で曖昧なケースに苦戦しました。どちらを選んでも妥協が必要に思えました。
ソリューションの概要
転機となったのは、ある実験でした。単一のモデルを選択する代わりに、複数の小規模モデルをデプロイして同じ商品を処理しました。モデル間で属性抽出結果が一致した場合、その結果を信頼できます。しかし、曖昧さ、コンテキストの欠如、モデルのエラーなどで意見が分かれた場合、重要な発見がありました。不一致は必ずしもエラーではなく、ほぼ常に複雑さを示すシグナルだったのです。不一致をシグナルとして活用する発想から、生成 AI のスケーリング方法を再考する自己学習システムを設計しました。複数の小規模モデルがコンセンサスを通じて定型的なケースを処理し、不一致が発生した場合にのみ大規模モデルを呼び出します。大規模モデルは、より深い調査と分析のための専門ツールにアクセスできるスーパーバイザーエージェントとして実装しています。スーパーバイザーは単に不一致を解決するだけでなく、再発防止に役立つ再利用可能な学習を生成し、動的なナレッジベースに保存します。学習価値が高いと判断された場合にのみ、より強力なモデルを呼び出して出力を修正します。その結果、コストが減少し品質が向上する自己学習システムが実現しました。以前はスーパーバイザー呼び出しをトリガーしていたエッジケースを、システムが自ら処理できるようになるためです。エラー率は継続的に低下しました。再トレーニングではなく、解決された不一致から蓄積された学習を小規模モデルのプロンプトに注入して実現しています。次の図は、自己学習システムのアーキテクチャを示しています。

自己学習アーキテクチャでは、商品データがジェネレーター・エバリュエーターワーカーを通じて流れ、不一致は調査のためにスーパーバイザーにルーティングされます。推論後、システムは出品者からのフィードバック(リスティングの更新やアピールなど)と顧客からのフィードバック(返品やネガティブレビューなど)も収集します。各ソースからの学習は階層的なナレッジベースに保存され、ワーカーのプロンプトに注入されて、継続的な改善ループを形成します。
以下は、AWS サービスを使用した自己学習パターンの簡略化されたリファレンスアーキテクチャです。本番システムはより複雑ですが、ここではコアコンポーネントとデータフローを示しています。
このシステムは、マルチモデルアーキテクチャに必要なインフラストラクチャを提供する Amazon Bedrock で構築できます。Amazon Bedrock では多様な基盤モデルにアクセスできるため、Amazon Nova Lite のような小規模で効率的なモデルをワーカーとして、Anthropic Claude Sonnet のような高性能なモデルをスーパーバイザーとしてデプロイでき、コストとパフォーマンスの両方を最適化できます。さらにコスト効率を高めるには、Amazon Elastic Compute Cloud (Amazon EC2) GPU インスタンスにオープンソースの小規模モデルをデプロイする方法もあり、ワーカーモデルの選択とバッチスループットの最適化を完全に制御できます。専門ツールと動的ナレッジベースを備えたスーパーバイザーエージェントを本番環境で運用するには、Bedrock AgentCore が提供するランタイムスケーラビリティ、メモリ管理、オブザーバビリティが役立ちます。
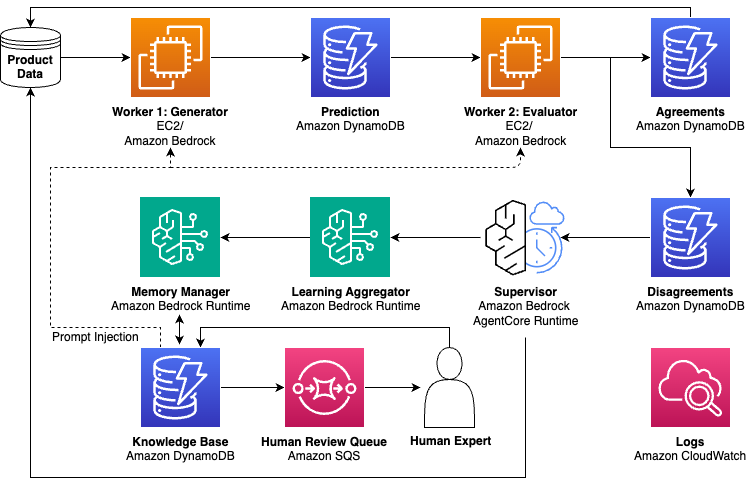
スーパーバイザーエージェントは Amazon の広範な Selection and Catalog Systems と統合されています。上の図は、エージェントの主要な機能とそれを支える AWS サービスの一部を示す簡略化されたビューです。商品データはジェネレーター・エバリュエーターワーカー(Amazon EC2 と Amazon Bedrock Runtime)を通じて流れ、一致した結果は直接保存され、不一致はスーパーバイザーエージェント(Bedrock AgentCore)にルーティングされます。学習アグリゲーターとメモリマネージャーはナレッジベースに Amazon DynamoDB を利用し、学習はワーカーのプロンプトに注入されます。人間によるレビュー(Amazon Simple Queue Service (Amazon SQS))とオブザーバビリティ(Amazon CloudWatch)がアーキテクチャを完成させます。本番環境では、スケール、信頼性、既存システムとの統合のために追加のコンポーネントが必要になる場合があります。
では、どのようにしてこのアーキテクチャに到達したのでしょうか?重要な洞察は予想外の場所から得られました。
不一致を学習機会に変える
デバッグセッション中に視点が変わりました。複数の小規模モデル(Nova Lite など)が商品属性について意見が分かれた場合、つまり技術用語の理解方法に基づいて同じ仕様を異なる方法で解釈した場合、最初は失敗とみなしていました。しかし、データは異なるストーリーを語っていました。小規模モデルが意見を異にした商品は、より多くの手動レビューと明確化が必要なケースと相関していたのです。モデルが意見を異にしたとき、それはまさに追加の調査が必要な商品でした。不一致は学ぶべきポイントを示していましたが、すべてのケースをエンジニアや科学者が深掘りすることは現実的ではありませんでした。スーパーバイザーエージェントはこれを大規模に自動的に行います。重要なのは、どのモデルが正しかったかを判断することではなく、将来の同様の不一致を防ぐのに役立つ学習を抽出することです。効率的なスケーリングの鍵はここにあります。不一致は推論時の AI ワーカーからだけではありません。推論後、出品者はリスティングの更新やアピールを通じて不一致を表明します。これは、元の抽出が重要なコンテキストを見逃していた可能性を示すシグナルです。顧客は返品やネガティブレビューを通じて不一致を表明し、商品情報が期待と一致しなかったことを示すことがよくあります。推論後の人間のシグナルは同じ学習パイプラインにフィードされ、スーパーバイザーがパターンを調査し、将来の商品全体で同様の問題を防ぐのに役立つ学習を生成します。スイートスポットを見つけました。中程度の AI ワーカー不一致率を持つ属性が最も豊富な学習をもたらしました。意味のあるパターンを表面化させるのに十分高く、解決可能な曖昧さを示すのに十分低いものです。不一致率が低すぎる場合、それは通常、学習可能なパターンではなく、ノイズや基本的なモデルの制限を反映しています。その場合は、より高性能なワーカーの使用を検討します。不一致率が高すぎる場合、ワーカーモデルまたはプロンプトがまだ十分に成熟していないことを示し、過度のスーパーバイザー呼び出しをトリガーしてアーキテクチャの効率性を損ないます。しきい値はタスクとドメインによって異なります。重要なのは、不一致がワーカー能力の根本的なギャップやランダムノイズではなく、調査する価値のある本当の複雑さを表す独自のスイートスポットを特定することです。
詳細: 仕組み
システムの中心には、並列で動作する複数の軽量ワーカーモデルがあります。一部は属性を抽出するジェネレーターとして、他は抽出を評価するエバリュエーターとして機能します。ワーカーは固定入力で非エージェント的な方法で実装でき、バッチ処理に適しスケーラブルです。ジェネレーター・エバリュエーターパターンは建設的な対立構造を生み出します。概念的には敵対的生成ネットワーク(GAN)の建設的な対立構造に似ていますが、私たちのアプローチはトレーニングではなくプロンプティングを通じて推論時に動作します。エバリュエーターには批判的であるよう明示的にプロンプトし、曖昧さ、欠落したコンテキスト、または潜在的な誤解について抽出を精査するよう指示します。この敵対的なダイナミクスにより、曖昧なケースが検出されずに通過するのではなく、本当の複雑さを表す不一致が表面化します。ジェネレーターとエバリュエーターが一致した場合、結果に高い信頼性があり、最小限の計算コストで処理します。コンセンサスパスはほとんどの商品属性を処理します。意見が分かれた場合、調査する価値のあるケースを特定し、スーパーバイザーをトリガーして意見の相違を解決し、再利用可能な学習を抽出します。
アーキテクチャは、不一致を普遍的な学習シグナルとして扱います。推論時には、ワーカー間の不一致が曖昧さをキャッチします。推論後には、出品者のフィードバックが意図との不整合をキャッチし、顧客のフィードバックが期待との不整合をキャッチします。3 つのチャネルがスーパーバイザーにフィードされ、全体的な精度を向上させる学習を抽出します。ワーカーが意見を異にすると、スーパーバイザーエージェント(より高性能なモデル)を呼び出し、意見の相違を解決してなぜ発生したかを調査します。スーパーバイザーはワーカーに欠けていたコンテキストや推論を特定し、洞察は将来のケースのための再利用可能な学習になります。たとえば、特定の技術用語に基づいて商品の使用分類についてワーカーが意見を異にした場合、スーパーバイザーは調査し、それらの用語だけでは不十分であり、視覚的なコンテキストやその他の指標を一緒に考慮する必要があることを明確にしました。スーパーバイザーは、その商品カテゴリに対して異なるシグナルを適切に重み付けする方法についての学習を生成しました。学習はすぐにナレッジベースを更新し、類似商品のワーカープロンプトに注入されると、数千のアイテム全体で将来の不一致を防ぐのに役立ちました。ワーカーには理論上スーパーバイザーと同じモデルを利用可能ですが、大規模なシステムを効率よく運用するには小規模モデルの使用が重要です。アーキテクチャ上の利点は非対称性から生まれます。軽量ワーカーがコンセンサスを通じて定型的なケースを処理し、より高性能なスーパーバイザーは不一致が高価値の学習機会を表面化させた場合にのみ呼び出されます。システムが学習を蓄積し不一致率が低下するにつれて、スーパーバイザー呼び出しは自然に減少します。効率性の向上はアーキテクチャに直接組み込まれています。ワーカー・スーパーバイザーの異質性は、より豊富な調査も可能にします。スーパーバイザーは選択的に呼び出されるため、すべての商品に対して取得するのは非現実的ですが、複雑な不一致を解決する際に重要なコンテキストを提供する追加のシグナル(顧客レビュー、返品理由、出品者履歴)を取り込む余裕があります。シグナルが顧客が商品情報をどのように提示してほしいかについての一般化可能な洞察(どの属性を強調するか、どの用語が響くか、仕様をどのようにフレーミングするか)をもたらす場合、結果として得られる学習は、リソース集約的なシグナルを再度取得することなく、類似商品全体の将来の推論に役立ちます。時間とともにフィードバックループが形成されます。より良い商品情報は返品やネガティブレビューの減少につながり、それは顧客満足度の向上を反映しています。
ナレッジベース: 学習のスケーリング
スーパーバイザーは個々の商品レベルで不一致を調査します。数百万のアイテムを処理するため、商品固有の洞察を再利用可能な学習に変換するスケーラブルな方法が必要です。集約戦略はコンテキストに適応します。大量のパターンはより広い学習に合成され、ユニークまたは重要なケースは個別に保存されます。LLM ベースのメモリマネージャーがナレッジツリーをナビゲートして各学習を配置する階層構造を使用しています。ルートから始めて、カテゴリとサブカテゴリを走査し、各レベルで既存のパスを続けるか、新しいブランチを作成するか、既存の知識とマージするか、古い情報を置き換えるかを決定します。動的な機構により、ナレッジベースは論理的な構造を維持しながら新しいパターンとともに進化できます。推論中、ワーカーは商品カテゴリに基づいてプロンプトで関連する学習を受け取り、過去の不一致からのドメイン知識を自動的に組み込みます。ナレッジベースはトレーサビリティも提供します。抽出が間違っているように見える場合、どの学習がそれに影響を与えたかを正確に特定できます。監査は実用的なタスクになります。数百万の出力のサンプルをレビューする代わりに(人間の労力はスケールに比例して増加します)、チームはナレッジベース自体を監査できます。ナレッジベースは推論量に関係なく比較的固定されたサイズのままです。ドメインエキスパートはエントリを追加または改良することで直接貢献でき、再トレーニングは不要です。単一の適切に作成された学習は、数千の商品全体で即座に精度を向上させることができます。ナレッジベースは人間の専門知識と AI の能力を橋渡しし、自動化された学習と人間の洞察が連携します。
学んだ教訓とベストプラクティス
自己学習アーキテクチャが効果的な場面:
- 大量の推論: 入力の多様性が複合的な学習を促進する場合
- 品質が重要なアプリケーション: コンセンサスが自然な品質保証を提供する場合
- 進化するドメイン: 新しいパターンや用語が常に出現する場合
低量のシナリオ(学習のための不一致が不十分)や、固定された変更のないルールを持つユースケースにはあまり適していません。
成功の重要な要因:
- 不一致の定義: ジェネレーター・エバリュエーターペアでは、エバリュエーターが抽出に改善が必要とフラグを立てたときに不一致が発生します。複数のワーカーでは、それに応じてしきい値をスケールします。重要なのは、ワーカー間の建設的な対立構造を維持することです。不一致率が生産的な範囲外(低すぎるまたは高すぎる)の場合は、より高性能なワーカーまたは改良されたプロンプトを検討してください。
- 学習効果の追跡: 不一致率は時間とともに減少する必要があります。これが主要な健全性指標です。率が横ばいの場合は、知識の取得、プロンプトの注入、またはエバリュエーターの批判性を確認してください。
- 知識の整理: 学習を階層的に構造化し、実行可能に保ちます。抽象的なガイダンスは役に立ちません。具体的で具体的な学習が将来の推論を直接改善します。
よくある落とし穴
- インテリジェンスよりもコストに焦点を当てる: コスト削減は副産物であり、目標ではありません
- ラバースタンプエバリュエーター: ジェネレーターの出力を単に承認するエバリュエーターは意味のある不一致を表面化させません。抽出に積極的に挑戦し批評するようプロンプトしてください
- 不十分な学習抽出: スーパーバイザーは個々のケースを修正するだけでなく、一般化可能なパターンを特定する必要があります
- 知識の腐敗: 整理がなければ、学習は検索不能で使用不能になります
ポイント: 不一致率の低下を最重要指標として追跡してください。システムが本当に学習しているかどうかを示す指標です。
デプロイ戦略: 2 つのアプローチ
- 学習してからデプロイ: 基本的なプロンプトから始めて、本番前環境でシステムに積極的に学習させます。その後、ドメインエキスパートがナレッジベースを監査し(個々の出力ではなく)、学習したパターンが望ましい結果と一致していることを確認します。承認されたら、検証済みの学習でデプロイします。これは、良いとは何かをまだ知らない新しいユースケースに最適です。不一致は適切なパターンを発見するのに役立ち、ナレッジベースの監査により本番前にそれらを形成できます。
- デプロイして学習: 改良されたプロンプトと良好な初期品質から始め、本番環境での継続的な学習を通じて継続的に改善します。これは、品質を事前に定義できるが、時間の経過とともにドメイン固有のニュアンスをキャプチャしたい、よく理解されたユースケースに最適です。
どちらのアプローチも同じアーキテクチャを使用します。選択は、新しい領域を探索しているか、馴染みのある領域を最適化しているかによって異なります。
まとめ
カタログエンリッチメントの実験から、重要な真実が明らかになりました。AI システムは時間の中で凍結される必要はありません。不一致を失敗ではなく学習シグナルとして受け入れることで、実際の使用を通じてドメイン知識を蓄積するアーキテクチャを構築しました。システムが汎用的な理解からドメイン固有の専門知識へと進化するのを見ました。業界固有の用語を学習しました。カテゴリによって異なるコンテキストルールを発見しました。通常の事前トレーニングされたモデルでは対処できない要件にも対応しました。再トレーニングなしで、ナレッジベースに保存されワーカープロンプトに注入された学習を通じて実現しました。同様のアーキテクチャを運用するチーム向けに、Amazon Bedrock AgentCore は専用の機能を提供します:
- AgentCore Runtime は、ルーチンケースの迅速なコンセンサス決定を処理しながら、スーパーバイザーが複雑な不一致を調査する際の拡張推論をサポートします
- AgentCore Observability は、どの学習がインパクトを与えているかの可視性を提供し、チームが知識の伝播を改良し、大規模な信頼性を維持するのに役立ちます
影響はカタログ管理にとどまりません。大量の AI アプリケーションはこのプロセスから恩恵を受ける可能性があり、Amazon Bedrock の多様なモデルへのアクセス機能により、このアーキテクチャの実装は簡単です。重要なのは、「どのモデルを使用すべきか?」から「特定のパターンを学習するシステムをどう構築するか?」へと問いが変わったことです。新しいユースケースで学習してからデプロイするか、確立されたユースケースでデプロイして学習するかにかかわらず、実装は簡単です。タスクに適したワーカーから始め、スーパーバイザーを選択し、不一致が学習を促進するようにします。適切なアーキテクチャがあれば、推論のたびにドメイン知識をキャプチャする機会になります。スケーリングだけでなく、AI システムに組織的な知識を蓄積することが重要です。
謝辞
本プロジェクトは、Ankur Datta (Senior Principal Applied Scientist – Everyday Essentials Stores のサイエンスリーダー)、Zhu Cheng (Applied Scientist)、Xuan Tang (Software Engineer)、Mohammad Ghasemi (Applied Scientist) の貢献とサポートなしには実現できませんでした。設計、実装、数多くの実りあるブレインストーミングセッション、そしてすべての洞察に満ちたアイデアと提案への貢献に感謝いたします。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。