Amazon Web Services ブログ
AWS IoT とサーバーレスデータレイクを使用したフロントライン脳震盪モニタリングシステムの構築方法 – パート 2
本シリーズのパート 1 では、データレイクをサポートするデータパイプラインの構築方法について説明しました。そのために、Amazon Kinesis Data Streams、Kinesis Data Analytics、Kinesis Data Firehose、および AWS Lambda などの AWS の主なサービスを使用しました。パート 2 では、主要分析を使って実用的なデータを作成するサーバーレスデータレイクを作成することによってデータを処理し、可視化する方法について説明します。
サーバーレスデータレイクの作成と、AWS Glue、Amazon Athena、および Amazon QuickSight を使用したデータの調査
パート 1 で説明した通り、心拍数データは Kinesis Data Streams を使用して Amazon S3 バケットに保存できます。しかし、リポジトリにデータを保存するだけでは十分ではありません。分析のための有意義なデータを抽出できるように、リポジトリに関連する関連メタデータをカタログ化し、保存することができる必要もあります。
サーバーレスデータレイクには、完全マネージド型のデータカタログおよび ETL (抽出、変換、ロード) サービスである AWS Glue を使用できます。AWS Glue は、困難で時間のかかるデータ検出、変換、およびジョブスケジュールのタスクを簡素化し、自動化します。AWS Glue Data Catalog のデータを最適なパフォーマンスのためにパーティション分割して圧縮すると、S3 データへの直接クエリのために Amazon Athena を使用できます。その後、Amazon QuickSight を使用してデータを可視化できます。
以下の図は、このデモで作成されるデータレイクを表しています。

今現在、Amazon S3 には Kinesis プロセスからの raw データが保存されています。最初のタスクは、Data Catalog を準備して、クエリと分析のためにどのデータ属性を使用できるかを特定することです。このタスクを実行するには、AWS Glue で、AWS Glue クローラ によって作成されたテーブルを保持するデータベースを作成する必要があります。
AWS Glue クローラは S3 バケットにある raw データ をスキャンし、Data Catalog でデータテーブルを作成します。定期的に実行するためのスケジューラをクローラに追加して、必要に応じて新しいデータをスキャンできます。AWS Glue でデータベースとクローラを作成するための具体的な手順については、「AWS Glue と Amazon S3 を使用してデータレイクの基礎を構築する」を参照してください。
以下の図は、AWS Glue のクローラ設定の概要画面です。

クローラを設定したら、[完了] を選択して、ナビゲーションバーの [クローラ] を選択します。作成したクローラを選択してから、[クローラの実行] を選択します。

クローラのプロセスは、開始までに 20~60 秒かかる場合があります。これは Data Catalog に依存し、クローラ設定中に定義したとおり、データベース内にテーブルを作成します。

テーブル名を選択して、Data Catalog とテーブルを調べることができます。
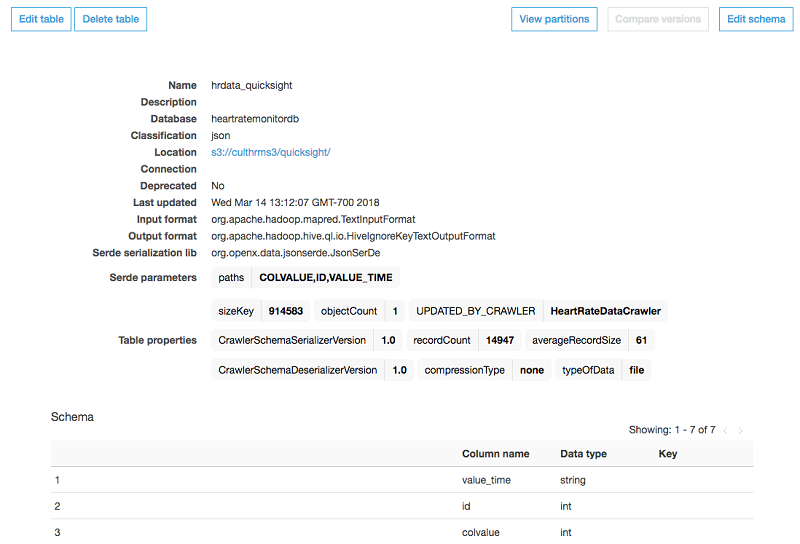
デモのテーブル詳細には、データにタイムスタンプである value_time、人物の ID である id、および心拍数である colvalue の 3 つの属性があります。これらの属性は AWS Glue クローラによって識別され、リストされます。データフォーマット (text) およびレコード数 (レコードサイズがそれぞれ 61 バイトのレコード約 15,000 個) などのその他情報も確認できます。
Raw データのクエリには Athena を使用できます。AWS Glue コンソールから直接 Athena にアクセスするには、以下に示すように、テーブルを選択してから、[アクション] メニューで [データの表示] を選択します。

前述したとおり、データは現在 JSON フォーマットで、パーティション分割されていません。これは Athena がより多くのデータをスキャンし続けることを意味し、クエリコストが高くなります。ベストプラクティスは、常にデータをパーティション分割し、データを Apache Parquet または Apache ORC などのカラムナフォーマットに変換することです。これによって、クエリの実行中におけるデータスキャンの量を減らすことができます。データスキャンを少なくすることは、低コストでのより良いクエリパフォーマンスを意味します。
これを達成するために、AWS Glue が ETL スクリプトを生成してくれます。これはデータ処理のために定期的に実行されるようにスケジュールでき、複雑なコードを記述する必要がなくなります。AWS Glue は、AWS によって管理されているウォーム Apache Spark クラスターの上で実行されるマネージド型サービスです。AWS Glue で独自のスクリプトを実行する、または要件に合う AWS Glue 提供のスクリプトを変更することができます。ソリューションのためのカスタムスクリプトの構築方法の例については、AWS Glue 開発者ガイド の「独自のカスタムスクリプトを提供する」を参照してください。
ジョブを作成するための詳細手順については、ブログ記事「AWS Glue と Amazon S3 を使用してデータレイクの基礎を構築する」を参照してください。以下の図は、このデモのための最終的な AWS Glue ジョブ設定の要約を示しています。
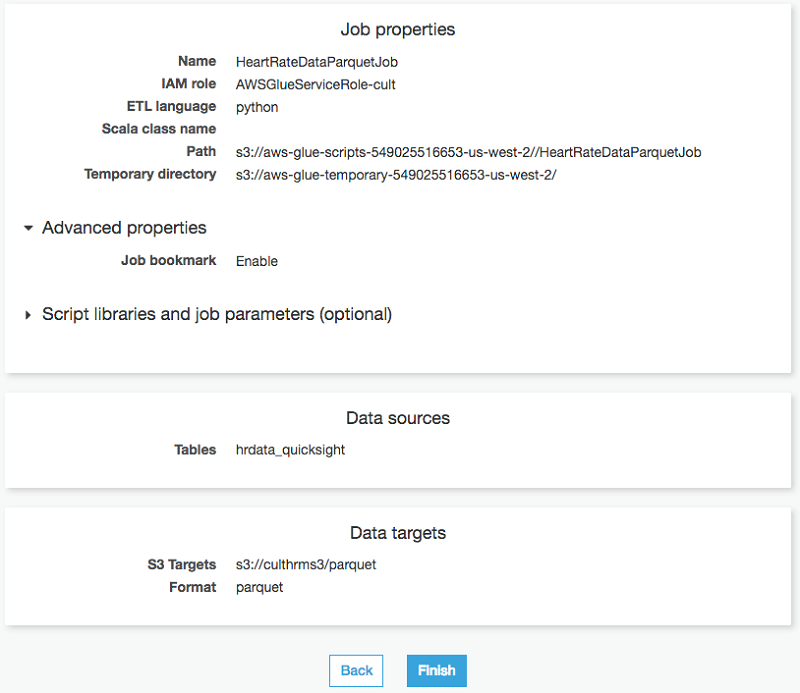
この設定例では、AWS Glue が状態情報を維持するために役立ち、古いデータの再処理を防ぐジョブブックマークが有効化されています。スケジュールされた時間間隔で再実行するときは、新しいデータのみを処理する必要があります。
[完了] を選択すると、AWS Glue が Python スクリプトを生成します。このスクリプトはデータを処理して、それをジョブ設定で指定した宛先の S3 バケットにカラムナフォーマットで保存します。
[ジョブの実行] を選択した場合、データの量と設定されたデータ処理ユニット (DPU) の台数に応じて、完了までに時間がかかります。デフォルトで、ジョブは 10 台の DPU で設定されており、増やすことができます。単一の DPU は、 4 vCPU のコンピューティングと 16 GB のメモリで構成される処理能力を提供します。
ジョブが完了したら、宛先の S3 バケットを調べてください。データが Parquet のカラムナフォーマットになっているのがわかります。
パーティション化は、データセットを様々なビッグデータシステムで効率的にクエリできるように、それらを整理するための重要な手法となっています。データは、ひとつ、または複数の列の重複しない値に基づいて、階層ディレクトリ構造にまとめられます。AWS Glue を使ってパーティション化されたデータセットを効率的に処理することに関する詳細については、ブログ記事「Work with partitioned data in AWS Glue」を参照してください。
新しいデータが S3 バケットに送信されるときにそのデータを処理するために、ジョブを定期的に実行するジョブ用のトリガーを作成できます。ジョブトリガーの設定方法に関する詳細な手順については、「AWS Glue でのジョブのトリガー」を参照してください。
次のステップは、テーブルを作成できるように Parquet データのクローラを作成することです。以下の画像は、今回の Parquet クローラの設定を示しています。
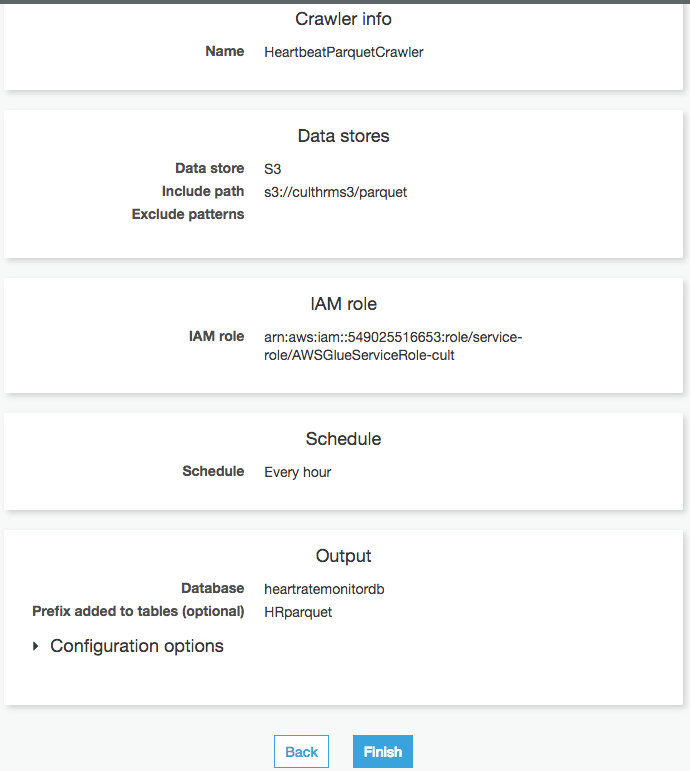
[完了] を選択してクローラを実行します。
データベースを調べると、ひとつ、または複数のテーブルが Parquet フォーマットで作成されているのがわかります。
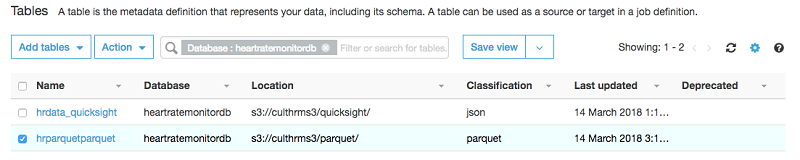
直接的なクエリ用にこの新しいテーブルを使用して、このデモのコストを削減し、クエリパフォーマンスを向上させることができます。
AWS Glue は Athena と統合されているため、Athena コンソールには、テーブルカタログを持つ AWS Glue カタログがすでに利用可能であることがわかります。前のステップで JSON データテーブルに対して行ったように、Athena から新しい Parquet テーブルの 10 行を 取得します。
以下の画像にあるように、Parquet フォーマットテーブルから心拍データの最初の 10 行を取得しました。この Athena クエリは、row フォーマットでスキャンされた 205 KB のデータと比較して、4.99 KB のデータしかスキャンしていません。また、ランタイムに関しても、クエリパフォーマンスに大幅な向上が見られました。

Amazon QuickSight でのデータの可視化
Amazon QuickSight は、組み合わされたデータを分析するために使用できるデータ可視化サービスです。詳しい手順については、Amazon QuickSight ユーザーガイドを参照してください。
Amazon QuickSight での最初のステップは、新しい Amazon Athena データソースを作成することです。AWS Glue で作成された心拍数データベースを選択し、次に AWS Glue クローラによって作成されたテーブルを選択します。
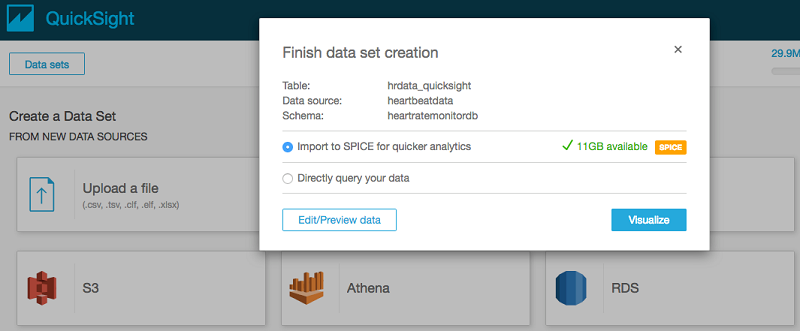
Import to SPICE for quicker analytics を選択します。このオプションはデータキャッシュを作成し、グラフのロード機能を向上させます。非データベースデータセットはすべて、SPICE を使用する必要があります。SPICE に関する詳細については、「SPICE 容量の管理」を参照してください。
[Visualize] を選択して、SPICE がデータをキャッシュにインポートするのを待ちます。また、S3 バケットに対して新しいデータがパイプライン化されると、そのデータが SPICE にロードされるように定期的な更新をスケジュールすることもできます。
SPICE インポートが完了すると、ビジュアルダッシュボードを簡単に作成できます。以下の図は、デバイスごとの心拍数レコードの頻度を表示するグラフです。 最初のグラフは、デバイスごとに心拍数の頻度の割合を示す水平積み上げ棒グラフです。2 番目のグラフでは、心拍数デバイスに対する心拍数グループを見ることができます。

結論
大規模ストリーミングデータの処理は、すべての業界に関連する事柄です。人の健康問題に取り組むためにウェアラブルデバイスを使ってデータ処理する場合、または製造拠点における予知保全に対応する場合にかかわらず、AWS は、全体的な IT 支出を管理しやすいレベルに維持しながら、データの取り込みと分析をシンプル化するために役立ちます。
この 2 回シリーズでは、心拍数センサーからストリーミングデータを取り込んで、実用的な洞察を作成するように可視化する方法について学びました。ビッグデータおよび機械学習分野で使用できる現在の最先端技術は、テラバイトそしてペタバイトものデータを取り込み、そのプロセスから有益かつ実用的な情報を抽出することを可能にします。
その他の参考資料
この記事が役に立つと思われる場合は、Work with partitioned data in AWS Glue、および 10 visualizations to try in Amazon QuickSight with sample data も併せてお読みください。
著者について
 Saurabh Shrivastava は世界各国のシステムインテグレーターと連携するパートナーソリューションアーキテクト/ビッグデータスペシャリストです。Saurabh は AWS のパートナーおよびお客様と連携して、ハイブリッド環境と AWS 環境でスケーラブルアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
Saurabh Shrivastava は世界各国のシステムインテグレーターと連携するパートナーソリューションアーキテクト/ビッグデータスペシャリストです。Saurabh は AWS のパートナーおよびお客様と連携して、ハイブリッド環境と AWS 環境でスケーラブルアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
 Abhinav Krishna Vadlapatla は アマゾン ウェブ サービスのソリューションアーキテクトです。Abhinav は、AWS を使用してスケーラブルでセキュアなソリューションを構築するためのクラウド導入においてスタートアップ企業と小企業をサポートしています。そのかたわらで、料理と旅行を楽しんでいます。
Abhinav Krishna Vadlapatla は アマゾン ウェブ サービスのソリューションアーキテクトです。Abhinav は、AWS を使用してスケーラブルでセキュアなソリューションを構築するためのクラウド導入においてスタートアップ企業と小企業をサポートしています。そのかたわらで、料理と旅行を楽しんでいます。
 John Cupit は AWS の Global Telecom Alliance Team のためのパートナーソリューションアーキテクトです。John は、クラウドを活用して通信キャリア業界を変えることに情熱を傾けています。John には大学を卒業した息子と娘がおり、娘は就職していますが、息子はテュレーン大学ロースクールの 1 年生です。このため、お金もなければ副業する時間もありません。
John Cupit は AWS の Global Telecom Alliance Team のためのパートナーソリューションアーキテクトです。John は、クラウドを活用して通信キャリア業界を変えることに情熱を傾けています。John には大学を卒業した息子と娘がおり、娘は就職していますが、息子はテュレーン大学ロースクールの 1 年生です。このため、お金もなければ副業する時間もありません。
 David Cowden は AWS の新興パートナーと連携するパートナーソリューションアーキテクト/IoT スペシャリストです。David はお客様と連携して、IoT 分野でスケーラブルなアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
David Cowden は AWS の新興パートナーと連携するパートナーソリューションアーキテクト/IoT スペシャリストです。David はお客様と連携して、IoT 分野でスケーラブルなアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
 Josh Ragsdale は AWS のエンタープライズソリューションアーキテクトです。非常に大きな規模のクラウド運用モデルへの適応に焦点を当てています。Josh はサイクリングと野外で家族と過ごす時間を楽しんでいます。
Josh Ragsdale は AWS のエンタープライズソリューションアーキテクトです。非常に大きな規模のクラウド運用モデルへの適応に焦点を当てています。Josh はサイクリングと野外で家族と過ごす時間を楽しんでいます。
 Pierre-Yves Aquilanti 博士は AWS の特化型 HPC シニアソリューションアーキテクトです。Pierre-Yves は、石油およびガス業界で、大規模 HPC システムのための R&D アプリケーションを最適化し、アップストリームための機械学習の可能性を実現することに数年間従事しました。彼と彼の家族は、人、文化経験、そして新鮮なドリアンを食べるためにもういちどシンガポールに住みたいと思っています。
Pierre-Yves Aquilanti 博士は AWS の特化型 HPC シニアソリューションアーキテクトです。Pierre-Yves は、石油およびガス業界で、大規模 HPC システムのための R&D アプリケーションを最適化し、アップストリームための機械学習の可能性を実現することに数年間従事しました。彼と彼の家族は、人、文化経験、そして新鮮なドリアンを食べるためにもういちどシンガポールに住みたいと思っています。
 Manuel Puron は AWS のエンタープライズソリューションアーキテクトです。Manuel はクラウドセキュリティと IT サービス管理に 10 年以上携わっており、電気通信業界に重点を置いています。Manuel はビデオゲーム、そして新しい文化を発見するために新たな場所に旅することが好きです。
Manuel Puron は AWS のエンタープライズソリューションアーキテクトです。Manuel はクラウドセキュリティと IT サービス管理に 10 年以上携わっており、電気通信業界に重点を置いています。Manuel はビデオゲーム、そして新しい文化を発見するために新たな場所に旅することが好きです。