Amazon Web Services ブログ
大規模なデータウェアハウスをダウンタイムなしで IBM Netezza から Amazon Redshift に移行する方法
最近、EMEA 地域の大企業がオンプレミスの IBM Netezza データウェアハウスの Amazon Redshift への移行を決定しました。データのボリューム (非圧縮容量 270 TB、および 27,000 個を超えるテーブル)、このデータを活用する相互接続されたシステムの数 (4,500 個を超えるビジネスプロセス)、かつダウンタイムなしという要件を考えると、このプロジェクトが困難であれどもやりがいがあるものなることは明らかでした。この会社は、データウェアハウスがデプロイされているデータセンターを 1 年以内に廃止することを計画していたので、時間的な制約もありました。
データウェアハウスは会社の中核を成す部分であり、あらゆる部門のユーザーが業務を遂行するために必要なデータを収集し、日報を生成することを可能にします。ほんの数年間で、クラスターにアクセスする事業部門はほぼ 3 倍に増加し、ユーザー数は当初の 5 倍となり、クラスターが設計された 1 日あたりのクエリ数 50 倍分のクエリが実行されるようになりました。レガシーデータウェアハウスは、これ以上これらの部門のビジネスニーズに対応できなくなり、毎晩の ETL プロセスの実行がその時間制限を超え、ライブクエリに時間がかかりすぎる原因となっていました。
この会社は、データセンターの廃止時期が近づいていたこともあり、ビジネスユーザー間における全般的な不満から移行の計画に踏み切り、IT 部門が新しいアーキテクチャの定義とプロジェクトの実施を担当することになりました。
アマゾン ウェブ サービス (AWS) の迅速かつスケーラブルな OLAP データウェアハウスであり、データウェアハウスとデータレイク全体における全データの分析をシンプル化してコスト効率性を高める Amazon Redshift は、この会社の問題を解決するために申し分ありませんでした。Amazon Redshift は今後の成長のための完全な伸縮性、および需要が高いピーク時を補うための同時実行スケーリングなどの機能を提供するだけでなく、簡単に統合できる分析サービスの完全なエコシステムも提供します。
この記事では、このお客様が綿密に計画された移行プロセスに従い、AWS Schema Conversion Tool (SCT) と Amazon Redshift のベストプラクティスを活用することによって、ダウンタイムなしで IBM Netezza から Amazon Redshift への大規模なデータウェアハウス移行を実行した方法について説明します。
移行の準備
大規模なエンタープライズカスタマーは通常、データ分析のための中央リポジトリとしてデータウェアハウスシステムを使用することで、異種トランザクションデータベースからの運用データを集約し、ビジネスアプリケーションおよびレポートを介してアナリストチームに対応するための分析ワークロードを実行します。お客様は AWS を使用することにより、それぞれが需要の増加に応じてスケールし、異なるワークロードを処理する複数のコンピューティングリソースを利用する柔軟性のメリットを活かすことができます。
このセクションでは、このデータウェアハウスの IBM Netezza から Amazon Redshift への移行を準備するために従った手順を説明します。
ワークロードと依存性の特定
一般的に、お客様はデータウェアハウスで 3 つの異なるタイプのワークロードを実行しています。
- バッチプロセス: ETL ジョブなどの長時間実行されるプロセスで、多くのリソースと低レベルの同時実行性が必要です。
- アドホッククエリ: アナリストがデータをクエリするなど、同時実行性が高いショートクエリです。
- ビジネスワークロード: 通常、BI アプリケーション、レポート、およびダッシュボードなどの混合ワークロードです。
このお客様の場合、複雑な ETL ジョブによるビジネスデータマートの構築、統計モデルの実行、およびレポートの生成を行い、アナリストがアドホッククエリを実行できるようにしていました。本質的に、これらのアプリケーションはバッチクエリとアドホッククエリの 2 つのワークロードのグループに分けられます。オンプレミスのプラットフォームは常に飽和状態で、許容可能なレベルのパフォーマンスを提供しながらこれらのワークロードが要求する同時実行性レベルに対応するために悪戦苦闘していました。
以下の図は、移行する前のお客様のアーキテクチャを示しています。
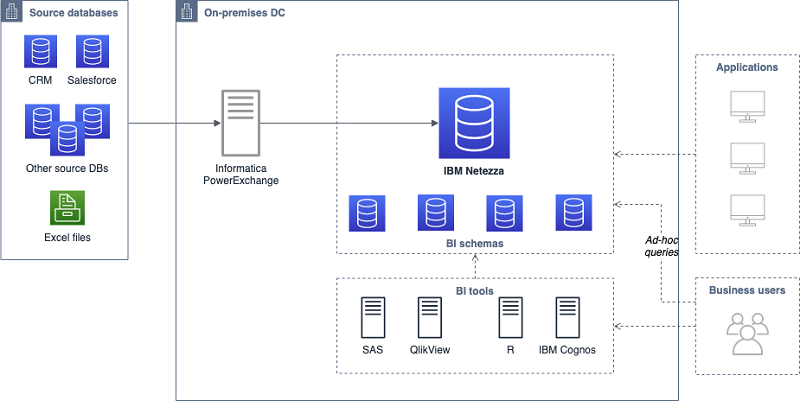
Amazon Redshift を使用することにより、お客様はすべての分析ワークロードの要件を満たすことができます。上の図にある古いデータウェアハウスでは、2 つの異なるマネージドサービスプロバイダーが 2 つの独立したデータとワークロードのセットを管理していました。新しいアーキテクチャでは、次のセクションで説明するように、データウェアハウスを 2 つの異なる Amazon Redshift クラスターに分割して、これらの異なるワークロードに対応することになりました。お客様はこれらの各クラスター内で、Amazon Redshift Workload Management (WLM) を設定することにより、同じワークロードの異なるアプリケーションのためにリソースと同時実行性を管理することができます。典型的な WLM セットアップはすべてのワークロードをキューと一致させるため、この場合、各クラスターにバッチとアドホックの 2 つのキューが設定されており、これらはスロット数と割り当てられたメモリ量がそれぞれ異なります。
ターゲットアーキテクチャのサイズ調整
今回のような異種間移行では、ソースデータベースで包括的な分析を行い、データとアプリケーションの両方をサポートする新しいアーキテクチャを設計するために十分なデータを収集する必要があります。
AWS Schema Conversion Tool はこのプロジェクトでの使用にぴったりでした。お客様はレポートを自動化し、異なるオブジェクト (データタイプ、UDF、およびストアドプロシージャなど) に対する移行の複雑性を見積もるために役立つ評価を生成することができたからです。
一般的なデータベース移行では、お客様が行の数で大規模テーブルを分類しますが、Amazon Redshift などの列指向データベースへの移行時には、最初からテーブル幅 (つまり列の数) も調べておくことが不可欠です。列指向データベースは通常、データの保存において行指向データベースよりも効率的ですが、行数が少ない幅広なテーブルは、列指向データベースに悪影響を及ぼす場合があります。Amazon Redshift 内の各テーブルに必要な最小テーブルサイズを見積もるには、AWS ナレッジセンターにあるこの式を使用します。
このお客様については、コアアプリケーションと、最小限のデータ依存性と異なるユーザーのセットを有する大型の分離ビジネスアプリケーションが明確に分かれていました。その結果、アーキテクチャ面での主な決定のひとつは、2 つの異なる Amazon Redshift クラスターを使用することでした。
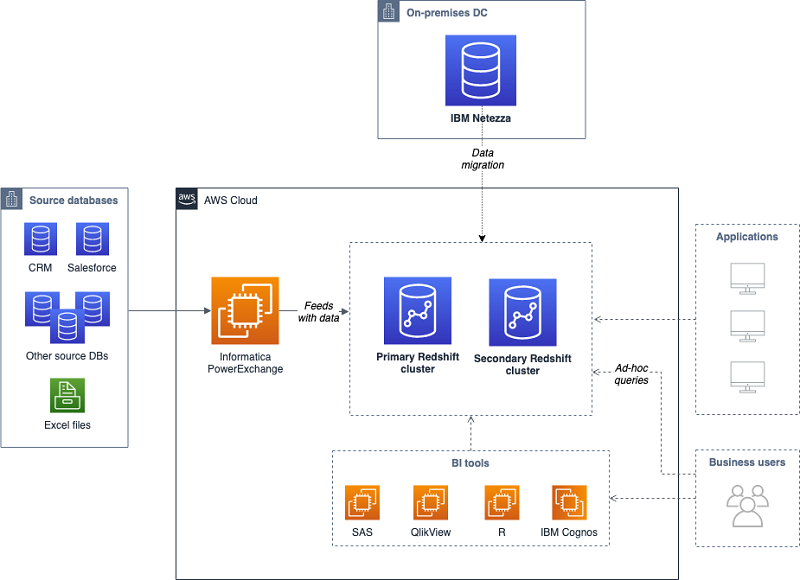
- プライマリクラスター: コアスキーマとデータの大半を保持し、ほとんどのビジネスアプリケーションに対応します。高いストレージ要件と、ここで実行される長時間のバッチプロセスのため、このクラスターのための推奨 Amazon Redshift ノードタイプは高密度ストレージファミリーです。
- セカンダリクラスター: 単一アプリケーションのための専用クラスターで、高い I/O が求められます。このクラスターのための推奨 Amazon Redshift ノードタイプは高密度コンピューティングファミリーです。
移行の計画
データ移行にはいくつかのアプローチがあります。多くの移行になくてはならない要件はダウンタイムの最小限化であり、これはこの記事で説明する移行パターンの主な要素でした。
データベース移行時の課題のひとつは、移行中にソースでの変更をキャプチャし、それらを移行先システムに適用することで、両方のシステムのデータを最新に保つことです。当然のことながら、データウェアハウスではトランザクション (OLTP) ワークロードではなく、長時間実行される ETL プロセスおよび分析ワークロード (OLAP) が実行されるべきです。一般に、これらの ETL プロセスはデータをバッチ単位で更新し、毎日行われるのが通常です。これは移行を簡素化します。移行中、データウェアハウスにデータをロードするこれらの ETL プロセスが両方のターゲットシステムに対して並行的に実行されるときには CDC が必要ないからです。
以下の図では、本番データウェアハウスでのダウンタイムを最小限にとどめるための並行アプローチに従って、この移行をお客様とどのように計画したかを要約しています。
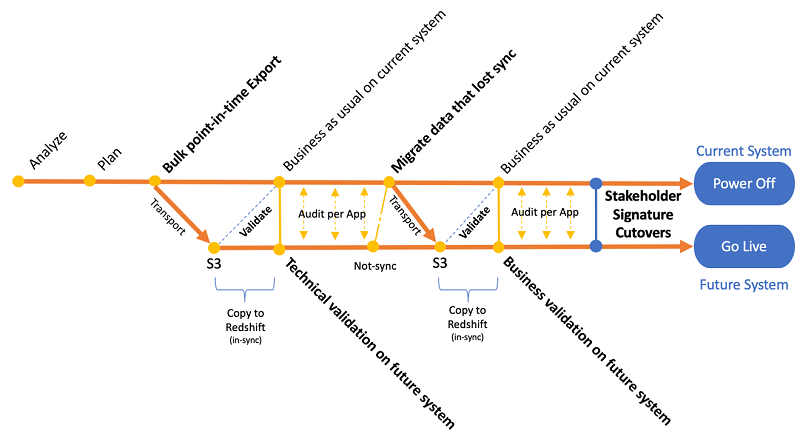
次のセクションで説明するとおり、このプロセスの主なステップは (1) データ移行、(2) 技術検証、(3) データ同期化、および (4) ビジネス検証です。
移行の実施
完全なデータ移行
初回データ移行は、このプロジェクトの最初のマイルストーンでした。このフェーズの主な要件は、(1) データソースへの影響を最小限に抑えること、および (2) データをできるだけ迅速に転送することでした。これらを行うために、AWS はデータベースのサイズ、ネットワークパフォーマンス (AWS Direct Connect または AWS Snowball)、および移行が異種間か同種間か (AWS Database Migration Service または AWS Schema Conversion Tool) に応じて数個のオプションを提供します。
今回の異種間移行では、お客様は AWS Schema Conversion Tool (SCT) を使用しました。SCT は、IBM Netezza が取り付けられているデータセンターに、それぞれが AWS SCT Data Extractor Agent を実行する複数の仮想マシンをプロビジョニングすることによってデータ移行の実施を可能にしました。これらのデータエクストラクタは、ソースデータベースに直接接続し、データをチャンク単位でターゲットデータベースに移行する Java プロセスです。
データ抽出エージェントのサイズ調整
移行に必要な Data Extractor Agent の数を見積もるには、ソース上の圧縮データ 1 TB あたり 1 つの Data Extractor Agent という経験則を考慮してください。もうひとつの推奨事項は、抽出エージェントを個々のコンピュータにインストールすることです。
各エージェントについて、以下の一般的なハードウェア要件を考慮します。
| CPU | 4 | データ移行中には多数の変換とパケットが処理されます。 |
| RAM | 16 | データチャンクは、ディスクにダンプされるまでメモリ内に保存されます。 |
| ディスク | 100 GB/~500 IOPS | 中間結果はディスクに保存されます。 |
| ネットワーク | 少なくとも 1 Gbit (10 Gbit 推奨) | リソースをプロビジョニングする間は、ソースから AWS SCT データ抽出エージェントへのネットワークホップの数を削減することが推奨されます。 |
データ抽出エージェントのためのインストール手順を実行するには、このドキュメントに従ってください。
移行されるデータのサイズとネットワークの速度に応じて、EC2 上でも Data Extractor Agent を実行するとよいかもしれません。大規模なデータウェアハウスのために、そしてダウンタイムを最小限化してデータ転送を最適化するためには、ソースにできるだけ近い場所に Data Extractor Agent をデプロイすることが推奨されます。たとえば、この移行プロジェクトでは、同時データ抽出とプロセスの迅速化のために、24 の個別の SCT Extractor Agent がオンプレミスデータセンターにインストールされました。これらの操作がデータソースに発生させるストレスのため、すべての抽出フェーズは週末と営業時間外に実行されました。
以下の図は、データ移行フェーズ中にデプロイされた移行アーキテクチャを表しています。
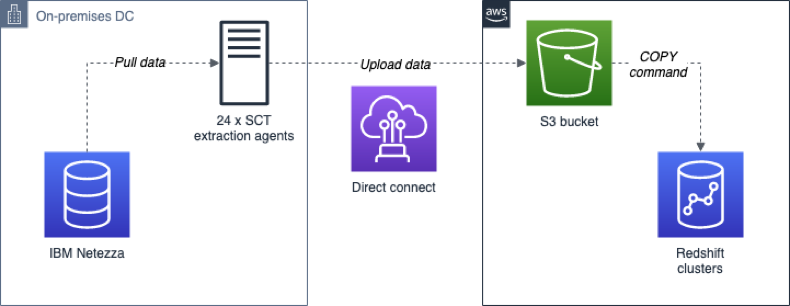
データ抽出タスクの作成
ソーステーブルは、デプロイされた SCT 抽出エージェントを使用して、テーブルごとに並行的に移行されました。これらの抽出エージェントは、データソース上の有効なユーザーを使用して認証し、抽出中にそのユーザーが利用できるリソースを調整できるようにします。データは SCT エージェントによってローカルに処理され、ネットワークを介して S3 にアップロードされました (AWS Direct Connect 経由)。他の移行シナリオには、AWS Snowball デバイスの使用が必要となる場合があることに留意してください。Snowball のドキュメントを確認して、どちらの転送手段がシナリオに適切かを判断してください。
移行計画中に実施された分析の一環として、お客様は大規模テーブル (2,000 万行、または 1 TB サイズを超えるテーブルなど) を特定しました。これらのテーブルからデータを抽出するため、お客様は AWS SCT で仮想パーティショニング機能を使用することで、テーブルのために数個のサブタスクを作成して、データ抽出プロセスを並列化しました。AWS では、仮想パーティションを使用して、移行されるスキーマごとに小規模テーブル用と大規模テーブル用の 2 つのタスクのグループを作成することを推奨します。
これらのタスクは、移行ウィンドウのための準備がすべて整うように、実行前に定義して作成することができます。次のドキュメントにアクセスして、AWS SCT データ抽出タスクの作成、実行、およびモニタリングを行ってください。
技術検証
最初に抽出されたデータが Amazon Redshift にロードされたら、移行に従事するパートナーチームによって開発された検証スクリプトを使用して、データ検証テストが並行的に実行されました。この段階の目標は、同じ入力からの IBM Netezza と Amazon Redshift の出力を比較して、本番ワークロードを検証することです。
このフェーズの対象となる典型的なアクティビティは以下のとおりです。
- 各テーブルのオブジェクトと行の数を数える。
- 移行されたすべてのテーブルについて IBM Netezza と Amazon Redshift の両方で同じデータのランダムサブセットを比較し、行ごとにデータが全く同じであることを検証する。
- 誤った列のエンコーディングをチェックする。
- 偏りのあるテーブルデータを特定する。
- ソートキーを活用していないクエリに注釈を付ける。
- 不適切な結合カーディナリティを特定する。
- 大きな varchar 型列があるテーブルに対処する。
- ターゲット環境に接続された時にプロセスがクラッシュしないことを確認する。
- 毎日のバッチジョブの実行を検証する (ジョブの所要時間、処理された行の数)。
これらのアクティビティの大半を実行するために適切な手法は、Top 10 Performance Tuning Techniques for Amazon Redshift で見つけることができます。
データ同期化
このフェーズでは、技術検証フェーズ中にソースとの同期性を失ったテーブルとスキーマをお客様が再度移行しました。最初の完全なデータ移行セクションで説明したものと同じメカニズムを使用することと、データマートを生成する ETL プロセスが新しいシステムですでに実行されていることから、データはこの同期化フェーズ後も最新に保たれます。
ビジネス検証
2 番目のデータ移行が正常に実行され、データの移動が技術的に検証された後の最後のタスクは、データウェアハウスユーザーに最終検証に参加してもらうことでした。会社全体の異なる事業部門からのこれらのユーザーは、JDBC/ODBC クライアント、Python コード、PL/SQL プロシージャ、カスタムアプリケーションなど、様々なツールとメソッドを使ってデータウェアハウスにアクセスしました。 この移行にとって、最終的なカットオーバーが実行される前に、それぞれのプロセスが Amazon Redshift とシームレスに機能することをすべてのエンドユーザーが検証し、それらのプロセスを適合させていることが重要でした。
このフェーズは約 3 か月かかり、いくつかのタスクで構成されていました。
- Amazon Redshift エンドポイントに接続するために、ビジネスユーザーのツール、アプリケーション、およびスクリプトを適合させる。
- S3 からの、または S3 に対する COPY/UNLOAD オペレーションで、ODBC/JDBC を介して共有ストレージからの、または共有ストレージに対するデータ移動を置き換えることで、ユーザーのデータのロードとダンプ手順を変更する。
- Amazon Redshift PostgreSQL 実装の詳細を考慮に入れながら、互換性のないクエリを変更する。
- IBM Netezza と Amazon Redshift の両方に対してビジネスプロセスを実行し、結果と実行時間を比較して、問題または予想外の結果があれば移行を担当するチームにそれらを必ず通知することで、そのケースを詳細に分析できるようにする。
- テーブルのソートキーを考慮し、Amazon Redshift がクエリを計画して実行する方法を理解するために EXPLAIN コマンドをフルに活用することで、クエリパフォーマンスを調整する。
ビジネス検証フェーズは、すべてのエンドユーザーが足並みをそろえ、最終的なカットオーバーのための準備を整えるための鍵でした。Amazon Redshift のベストプラクティスに従うことは、エンドユーザーがその新しいデータウェアハウスの機能性を活用することを可能にしました。
ソフトカットオーバー
すべての移行タスクと検証タスクが実行された後、すべての ETL、ビジネスプロセス、外部システム、およびユーザーツールが正常に Amazon Redshift に接続され、テストされました。
この時点で、すべてのプロセスを古いデータウェアハウスから切り離し、データハウスの電源を安全に落として廃棄することができます。
まとめ
この記事では、オンプレミスの IBM Netezza から Amazon Redshift への大規模なデータウェアハウス移行を正常に実行するために行った手順を説明しました。これらと同じ手順を、その他あらゆるソースデータウェアハウスに外挿することが可能です。
この記事では、純粋なリフト&シフト移行を説明しましたが、これは完全な企業データレイクへの変換プロセスの第一歩にすぎません。AWS が提供する強力な分析ツールとサービスを最大限に活用するために必要な一連のさらなるステップがあります。
- インタラクティブクエリのキューで Amazon Redshift の同時実行スケーリング機能をアクティブ化して、ピークキャパシティのためのクラスターをプロビジョニングする必要なく、使用率が高い期間にクラスターがシームレスに拡大されるようにする。
- S3 でデータレイクを作成し、頻繁にアクセスされないデータをオフロードして、高パフォーマンスのためにワームデータおよびホットデータを Amazon Redshift クラスターに維持する。
- ビジネスニーズの必要に応じて分析クエリでコールドデータとホットデータを組み合わせることができるように Amazon Redshift Spectrum を活用する。
- データウェアハウスのパフォーマンスに影響を及ぼすことなくコールドデータをクエリできるように Amazon Athena を使用する。
私たちが Amazon Redshift への大規模な移行で成功を収める上で重要だと考える点をいくつか指摘しておきたいと思います。
- Amazon Redshift クラスターサイズの初期調整を正確に行うための PoC から初める。
- 影響を受けるすべてのシステムに対する明確な手順が含まれる詳細な移行計画を策定する。
- エンドユーザーが移行プロセスと完全に連携するようにし、エンドユーザーのプロセスのすべてが最終的なカットオーバーの実行前に検証されることを確実にする。
- Amazon Redshift の機能性とパフォーマンスを最大限に活用するため、Amazon Redshift のベストプラクティスと手法に従う。
- 早い段階から、そしてプロセス全体を通じて AWS アカウントチームと協力する。AWS アカウントチームは、移行プロジェクトで望ましい結果を得るための AWS スペシャリスト、Professional Services、およびパートナーへの窓口です。
この記事が皆さんのお役に立つことを願っています。コメントまたはご質問などがありましたら、ぜひお知らせください。
著者について
 Guillermo Menendez Corral はアマゾン ウェブ サービスのソリューションアーキテクトです。SW アプリケーションの設計と構築に関して 12 年を越える経験を持つ Guillermo は、現在分析と機械学習に焦点を当てたアーキテクチャ面でのガイダンスを AWS のお客様に提供しています。
Guillermo Menendez Corral はアマゾン ウェブ サービスのソリューションアーキテクトです。SW アプリケーションの設計と構築に関して 12 年を越える経験を持つ Guillermo は、現在分析と機械学習に焦点を当てたアーキテクチャ面でのガイダンスを AWS のお客様に提供しています。
 Arturo Bayo はアマゾン ウェブ サービスのビッグデータコンサルタントです。Arturo は、EMEA 全域のエンタープライズカスタマーでデータ駆動の文化を推進し、データおよび分析に関する革新的なソリューションを構築するために AWS のお客様とパートナーと連携しながら、ビジネスインテリジェンスとデータレイクのプロジェクトにおける専門的なガイダンスを提供しています。
Arturo Bayo はアマゾン ウェブ サービスのビッグデータコンサルタントです。Arturo は、EMEA 全域のエンタープライズカスタマーでデータ駆動の文化を推進し、データおよび分析に関する革新的なソリューションを構築するために AWS のお客様とパートナーと連携しながら、ビジネスインテリジェンスとデータレイクのプロジェクトにおける専門的なガイダンスを提供しています。