Amazon Web Services ブログ
Stable Diffusion で画像の部分的な差し替えを行う環境を、 Amazon SageMaker JumpStart で簡単に構築する
本記事では、テキストによる指示に基づいて、画像の一部を別の画像に置き換える方法 ( インペイント ) を紹介します。 Amazon SageMaker JumpStart を使うことで、 Stable Diffusion モデルでインペイントを行う環境を簡単に構築することができます。インペインティングを利用することで、画像素材の一部だけ新しい画像やスタイルに差し替えたり、劣化した画像の修復を行うことができます。例えば、モデルの写真で服装のデザインを複数パターン差し替えてアイデア出しに使ったりすることができます。
Stable Diffusion モデルはオリジナル画像、差し替えする箇所を示すマスク画像、テキストプロンプトの 3 つの入力から、インペイントを行います。次の画像は左が原画、中央がマスク画像、右がモデルによってインペイントされた画像です。最初の例では、原画とマスク画像、そして「白猫、青い目、セーターを着て、公園で寝ている」というテキストプロンプトと、「足の描き方が悪い」というネガティブプロンプトをモデルに与えています。2つ目の例では、”ピンクとブルーが混ざったカジュアルなロングドレスを優雅に着こなす女性モデル “というプロンプトを与えています。

この記事では、SageMaker JumpStart から Stable Diffusion のモデルを使いインペイントを行う方法について、Amazon SageMaker Studio の画面から行う方法と、 SageMaker Python SDK から行う方法の2つを解説します。
Amazon SageMaker JumpStart でインペイントを行うメリットと手順
Stable Diffusion のような大規模なモデルを推論するには、 GPU などの高速な演算が行えるハードウェアの性能を引き出すカスタム推論スクリプトが必要です。通常、スクリプト、モデル、および目的のインスタンスが効率的に動作することを確認するためにエンドツーエンドのテストが必要があります。JumpStart は、堅牢にテストされたすぐに使えるスクリプトを提供することで、このプロセスを簡素化します。これらのスクリプトには、 Amazon SageMaker Studio からワンクリックでアクセスしたり、JumpStart API からわずかなコード行でアクセスしたりすることができます。
以下のセクションでは、 SageMaker Studio 、そして JumpStart APIs を使用してモデルをデプロイし推論する方法を説明します。なお、モデルの利用用途は CreativeML Open RAIL++-M ライセンスで規定されているため、ご利用用途がライセンスに沿っているかご確認ください。
SageMaker Studio からインペイントを行う
このセクションでは、 SageMaker Studio から JumpStart を使って Stable Diffusion のモデルをデプロイし、インペイントの推論をする方法を解説します。次のビデオでは、JumpStart でインペイント用に事前学習された Stable Diffusion モデルを見つけ、それをデプロイする様子を示しています。モデルページには、モデルとその使用方法に関する重要な詳細が表示されます。推論を実行するために、レスポンスの速い推論に必要な GPU アクセラレーションを手頃な価格で提供する、ml.g5.2xlarge もしくは ml.p3.2xlarge インスタンスタイプを採用します。SageMaker にホスティングするインスタンスの構成が完了したら、Deploy を選択します。エンドポイントは、約 10 分以内に運用を開始し、推論リクエストを処理する準備が整います。
JumpStart には、新しく作成されたエンドポイントで推論するのに役立つサンプルノートブックが用意されています。 SageMaker Studio からノートブックにアクセスするには、モデルのページの「Studio からエンドポイントを使用する」セクションで「ノートブックを開く」を選択します。
SageMaker SDK からインペイントを行う
SageMaker Python SDK から JumpStart API を呼び出すことでインペイントを行うこともできます。このセクションでは、SageMaker Python SDK から JumpStart の事前学習済みモデルを選択、モデルを SageMaker エンドポイントにデプロイ、エンドポイント上で推論の一連の処理を実行します。次に各ステップで必要なコードを示しますが、完全なコードにアクセスするには、 Introduction to JumpStart Image editing – Stable Diffusion Inpainting を参照してください。
インペイント用に学習されたモデルをデプロイする
SageMaker は、学習や推論に Docker コンテナを利用します。JumpStart は、フレームワーク固有の SageMaker Deep Learning Containers (DLC) を利用します。最初に、学習と推論を行うスクリプトと追加のパッケージを取得します。次に、事前学習済みモデルを model_uris で取得します。このように、スクリプトとモデルを別々に取得することにより、1つの推論スクリプトで複数の事前学習済みモデルを使用することができます。次のコードは、このプロセスを示しています:
model_id, model_version = "model-inpainting-stabilityai-stable-diffusion-2-inpainting-fp16", "*"
# Retrieve the inference docker container uri
deploy_image_uri = image_uris.retrieve(
region=None,
framework=None, # automatically inferred from model_id
image_scope="inference",
model_id=model_id,
model_version=model_version,
instance_type=inference_instance_type,
)
# Retrieve the inference script uri
deploy_source_uri = script_uris.retrieve(model_id=model_id, model_version=model_version, script_scope="inference")
base_model_uri = model_uris.retrieve(model_id=model_id, model_version=model_version, model_scope="inference")次に、それらのリソースから SageMaker モデル オブジェクトを作成し、エンドポイントへのデプロイを行います:
# Create the SageMaker model instance
# Create the SageMaker model instance
model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
model_data=base_model_uri,
entry_point="inference.py", # entry point file in source_dir and present in deploy_source_uri
role=aws_role,
predictor_cls=Predictor,
name=endpoint_name,
)
# deploy the Model - note that we need to pass the Predictor class when we deploy the model through the Model class,
# in order to run inference through the SageMaker API
base_model_predictor = model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=endpoint_name,
)モデルデプロイ後、リアルタイムに予測を得ることができます。
エンドポイントへの入力
入力は、ベース画像、マスク画像、そしてマスクされた部分を埋めるためのプロンプトです。インペイントを効果的に行うためには、いくつかのベストプラクティスがあります。まず、インペイントする画像に適したマスク画像を使用します。適切なマスクはインペイントアルゴリズムが画像の欠落部分を補完するのを助け、より自然な外観を実現します。効果的にマスク画像を生成する CLIPSeg について本記事後半で説明するので、参考にしてください。高品質な画像は一般的に良い結果をもたらすので、ベース画像とマスク画像は品質が良く、互いに似ていることを確認してください。さらに、ディテールを維持し、アーティファクトを最小限に抑えるために、大きくて滑らかなマスク画像を利用します。
エンドポイントでは、ベース画像とマスクを生の RGB 値または base64 エンコードされた画像として受け取ります。ただし、生の RGB 値でペイロードを送受信すると、入力ペイロードとレスポンスサイズのデフォルトの制限にかかる場合があります。したがって、content_type = "application/json;jpeg" および accept = "application/json;jpeg" を設定して、base64 エンコードされた画像を使用することをお勧めします。
推論エンドポイントは、content_type に基づいて画像をデコードします:
content_type = "application/json;jpeg"の場合、入力ペイロードは、Base64 エンコードされた画像、テキストプロンプト、およびその他のオプションパラメータを含む JSON 辞書でなければなりません。content_type = "application/json"の場合、入力ペイロードは、生の RGB 値、テキストプロンプト、およびその他のオプションパラメータを含む JSON 辞書でなければなりません。
エンドポイントの出力
エンドポイントは生成された画像を JEPG 化して Base64 エンコードした値 もしくは生の RGB 値の JSON 辞書の 2 種類の出力を生成することができます。accept ヘッダを JPEG 画像なら application/json 、Base64 なら application/json;jpeg に設定することで、どちらの出力形式を希望するかを指定することができます。
accept = "application/json;jpeg"の場合、エンドポイントは JPEG 画像を base64.b64 エンコードしたバイトを含む JSON 辞書を返します。accept = "application/json"の場合、エンドポイントは、画像の RGB 値を含む JSON 辞書を返します。
なお、生の RGB 値でペイロードを送受信すると、入力ペイロードとレスポンスサイズのデフォルトの制限にかかる場合があります。したがって、content_type = "application/json;jpeg" および accept = "application/json;jpeg" を設定して、base64 エンコードされた画像を使用することをお勧めします。
次のコードは、推論リクエストの例です:
content_type = "application/json;jpeg"
with open(input_img_file_name, "rb") as f:
input_img_image_bytes = f.read()
with open(input_img_mask_file_name, "rb") as f:
input_img_mask_image_bytes = f.read()
encoded_input_image = base64.b64encode(bytearray(input_img_image_bytes)).decode()
encoded_mask = base64.b64encode(bytearray(input_img_mask_image_bytes)).decode()
payload = {
"prompt": "a white cat, blue eyes, wearing a sweater, lying in park",
"image": encoded_input_image,
"mask_image": encoded_mask,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 0,
"negative_prompt": "poorly drawn feet",
}
accept = "application/json;jpeg"
def query(model_predictor, payload, content_type, accept):
"""Query the model predictor."""
query_response = model_predictor.predict(
payload,
{
"ContentType": content_type,
"Accept": accept,
},
)
return query_response
query_response = query(model_predictor, json.dumps(payload).encode("utf-8"), content_type, accept)
generated_images = parse_response(query_response)インペイントを調整するパラメータ
Stable Diffusion インペインティングモデルは、画像生成のための多くのパラメータをサポートしています:
- image – オリジナル画像。
- mask – 画像生成時に黒く塗られた部分はそのままで、白い部分が置き換わる画像。
- prompt – 画像生成のガイドとなるプロンプト。文字列または文字列のリスト。.
- num_inference_steps (optional) – 画像生成時のノイズ除去のステップ数.ステップ数が多いほど高画質になります.指定する場合は、正の整数である必要があります。推論ステップ数が多いと,応答時間が長くなることに注意してください.
- guidance_scale (optional) – ガイダンススケールを高くすると、画質は落ちる一方、よりプロンプトに近い画像が生成されます。指定する場合は、float である必要があります。
guidance_scale <=1は無視されます。 - negative_prompt (optional) – このプロンプトには沿わないように、画像生成をガイドします。指定する場合は、文字列または文字列のリストが指定でき、
guidance_scaleとともに使用されます。guidance_scaleが無効の場合、これも無効になります。さらに、プロンプトが文字列のリストである場合、 negative_prompt も文字列のリストである必要があります。 - seed (optional) – 再現性のためにランダム化された状態を固定します。指定する場合は、整数である必要があります。同じシードで同じプロンプトを使用すると、結果の画像は常に同じになります。
- batch_size (optional) – 1 回のフォワードパスで生成する画像の数です。小さいインスタンスを使用したり、多くの画像を生成する場合は、
batch_sizeを小さい数(1~2)にします。画像数 = プロンプト数 *num_images_per_prompt
制限とバイアス
Stable Diffusion はインペインティングにおいて素晴らしい性能を発揮しますが、いくつかの制限やバイアスを抱えています。例えば次の点が上げられますが、これらに限定されるものではありません:
- 学習データには、顔や手足の特徴を持つ十分な画像が含まれていないため、モデルは正確な顔や手足を生成しない可能性があります。
- Stable Diffusion は、成人向けコンテンツを含む LAION-5B データセットで学習されており、さらなる検討なしに製品として使用するのは適さない可能性があります。
- モデルは英語のテキストでトレーニングされているため、英語以外の言語ではうまく動作しない可能性があります。
- このモデルは、画像内のテキストをうまく生成することができません。
- Stable Diffusion インペインティングは、通常、256 × 256 や 512 × 512 ピクセルなどの低解像度の画像で最適に動作します。高解像度の画像(768 × 768 以上)を扱う場合、この方法は望ましい品質と詳細さのレベルを維持するのに苦労することがあります。
- シードの使用は再現性のコントロールに役立ちますが、Stable Diffusion インペインティングは、入力やパラメーターのわずかな変更で結果にばらつきが生じることがあります。このため、特定の要件に合わせて出力を微調整するのは難しいかもしれません。
- 特に、画像内の広い範囲を描画する場合や、描画領域の全体的な一貫性と品質が不可欠な場合、複雑なテクスチャやパターンの生成に苦労することがあります。
制限とバイアスの詳細については、Stable Diffusion インペインティングのモデルカードを参照してください。
プロンプトからマスク画像を生成してインペイントを行う
インペイントを行うために必要なマスク画像はどのように用意すれば良いでしょう? CLIPSeg は、画像とテキストの関係を事前学習した CLIP(Contrastive Language-Image Pretraining)モデルの力を利用して、入力画像からマスクを生成する高度な深層学習技術です。この手法は、画像のセグメンテーション、インペインティング、操作などのタスクのためのマスクを効率的に作成する方法を提供します。CLIPSeg は、CLIP を使用して入力画像のテキスト記述を生成します。次に、テキストを使用して、テキストに関連する画像内のピクセルを識別するマスクを生成します。このマスクを用いて、画像の関連部分を分離し、さらに処理することができます。
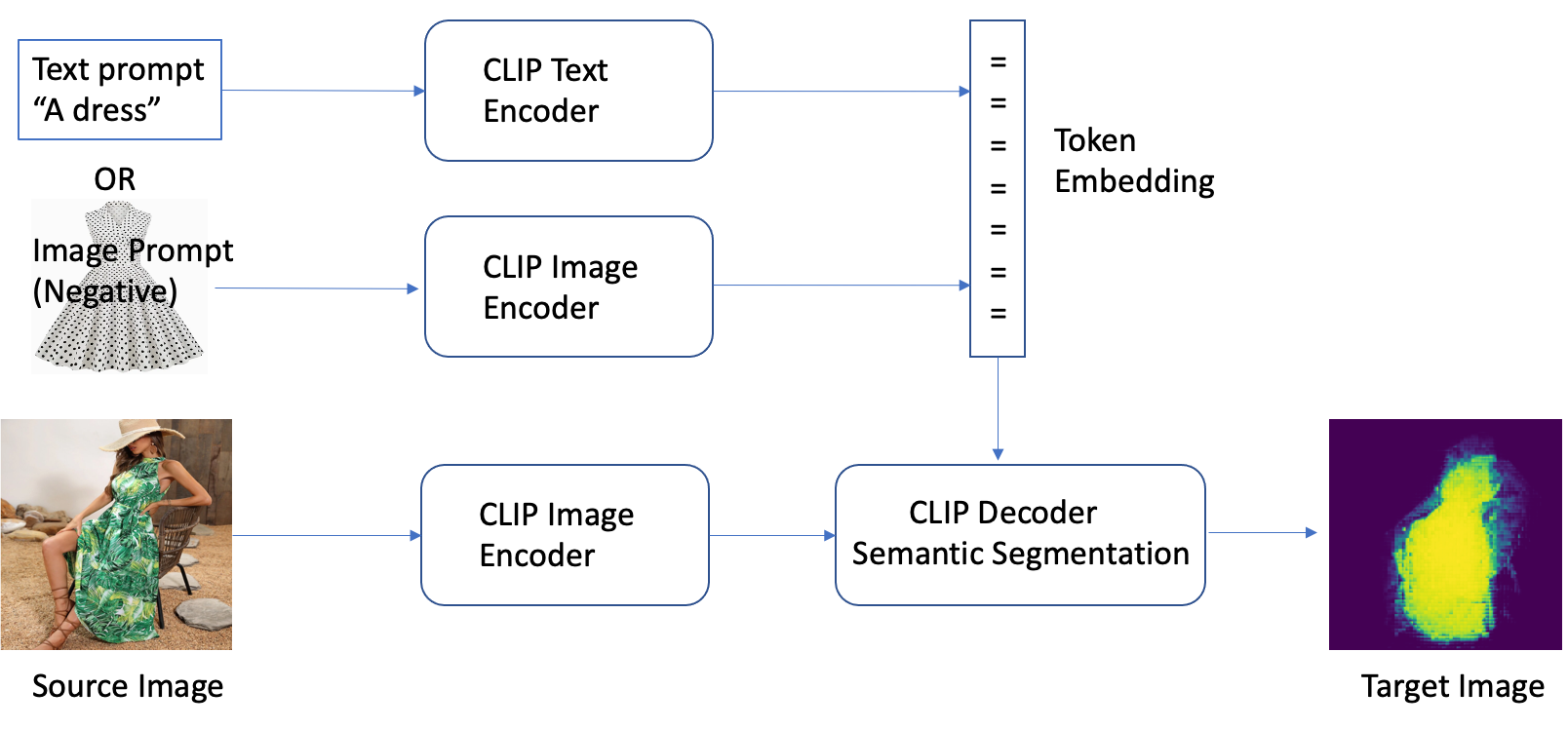
CLIPSeg は、入力画像からマスクを生成する他の方法と比較して、いくつかの利点があります。第一に、画像のセグメンテーションとマスクの指定を単一のアルゴリズムで処理できるため、より効率的です。第二に、画像のテキスト記述に近いマスクを生成できるため、より正確なマスクが生成できます。第三に、さまざまな画像からマスクを生成することができるため、汎用性が高いことです。
しかし、CLIPSeg にはいくつかの欠点もあります。第一に、この技術は、特定のドメインや専門分野を網羅していない可能性のある CLIP モデルに依存しているため、対応できる被写体に制限がある場合があります。第二に、画像のテキスト記述のエラーに影響されやすいため、繊細な手法となる可能性があります。
CLIPSeg を簡単にデプロイできるサンプルノートブックを二つ用意しました。1つ目のノートブックは CLIPSeg をプリプロセッサにした Stable Diffusion In-painting のパイプラインのエンドポイントをデプロイするもので、単一のエンドポイントで CLIPSeg によるマスク作成と Stable Diffusion In-painting を行うものです。マスクの作成とインペイントを一度に行う場合こちらが便利です。 2つ目のノートブックは CLIPSeg のみを単体でデプロイするもので、SageMaker JumpStart In-painting Model と併用する形で利用できます。こちらはユーザーがマスク画像を手直しする場合の使用を想定しています。
CLIPSeg と Stable Diffusion In-painting を利用する事例については、「 Amazon SageMaker を使った生成 AI によるバーチャルファッションスタイリング」をご参照ください。
クリーンアップ
ノートブックの実行が終わったら、プロセスで作成されたすべてのリソースを削除して、課金が停止していることを確認してください。エンドポイントをクリーンアップするコードは、ノートブックの最後に記載されています。
まとめ
この投稿では、画像の指定した範囲を編集できる Stable Diffusion インペインティングモデルを簡単にデプロイできる JumpStart を使う方法を紹介しました。このデモのすべての手順を含む完全なコードは、 Introduction to JumpStart – Enhance image quality guided by prompt ノートブックに掲載されています。このソリューションを実際に試してみて、コメントをお寄せください。
このモデルとその仕組みの詳細については、次のリソースを参照してください:
- High-Resolution Image Synthesis with Latent Diffusion Models
- Stable Diffusion ローンチのお知らせ
- Stable Diffusion 2.0リリース
- Stable Diffusion Inpainting model card
JumpStartについてもっと詳しく知りたい方は、以下の記事をご覧ください:
- Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart
- Upscale images with Stable Diffusion in Amazon SageMaker JumpStart
- AlexaTM 20B is now available in Amazon SageMaker JumpStart
- Run text generation with Bloom and GPT models on Amazon SageMaker JumpStart
- Run image segmentation with Amazon SageMaker JumpStart
- Run text classification with Amazon SageMaker JumpStart using TensorFlow Hub and Hugging Face models
- Amazon SageMaker JumpStart models and algorithms now available via API
- Incremental training with Amazon SageMaker JumpStart
- Transfer learning for TensorFlow object detection models in Amazon SageMaker
- Transfer learning for TensorFlow text classification models in Amazon SageMaker
- Transfer learning for TensorFlow image classification models in Amazon SageMaker
翻訳はソリューションアーキテクト 前川 泰毅 が担当しました。原文はこちらです。