Artificial Intelligence
AlexaTM 20B is now available in Amazon SageMaker JumpStart
July 2023: This post was reviewed for accuracy.
Today, we announce the public availability of Amazon’s state-of-the-art Alexa Teacher Model with 20 billion parameters (AlexaTM 20B) through Amazon SageMaker JumpStart, SageMaker’s machine learning hub. AlexaTM 20B is a multilingual large-scale sequence-to-sequence (seq2seq) language model developed by Amazon. You can use AlexaTM 20B for a wide range of industry use-cases, from summarizing financial reports to question answering for customer service chatbots. It can be applied even when there are only a few available training examples, or even none at all. AlexaTM 20B outperforms a 175 billion GPT-3 model on zero-shot learning tasks such as SuperGLUE and shows state-of-the-art performance for multilingual zero-shot tasks such as XNLI.
In this post, we provide an overview of how to deploy and run inference with the AlexaTM 20B model programmatically through JumpStart APIs, available in the SageMaker Python SDK. We exemplify how you can use this model to translate between multiple languages, summarize long-form text, answer questions based on a given context and generate text that appears indistinguishable from human-written text.
AlexaTM 20B and in-context learning
The Alexa Teacher Model (AlexaTM) program by Amazon Alexa AI is designed to build large-scale, multilingual deep learning models (primarily Transformer-based), aiming to improve generalization and handling data scarcity for downstream tasks. With large-scale pre-training, teacher models can generalize well to learn new tasks from sparse data and help developers improve performance on downstream tasks. AlexaTM 20B has shown competitive performance on common natural language processing (NLP) benchmarks and tasks, such as machine translation, data generation and summarization.
Using foundation models such as AlexaTM 20B reduces the need for expensive model pre-training and provides a state-of-the-art starting point to develop task models with less effort and less task-specific training data. One of the key abilities of foundation models is that we can teach a model to perform new tasks such as question and answering in different languages, with very small amounts of input examples and no fine-tuning or gradient updates required. This is known as in-context learning. With only a few examples of a new task provided as context for inference, the AlexaTM 20B model can transfer knowledge from what has been learned during large-scale pre-training, even across languages. This is called few-shot learning. In some cases, the model can perform well without any training data at all, with only an explanation of what should be predicted. This is called zero-shot learning. For example, let’s say we are using AlexaTM 20B for one-shot natural language generation. The input passed to the model is the training example in the form of attribute-value pairs, along with its corresponding output text narrative. The test example is then appended to form the full input prompt, as shown in the following figure.
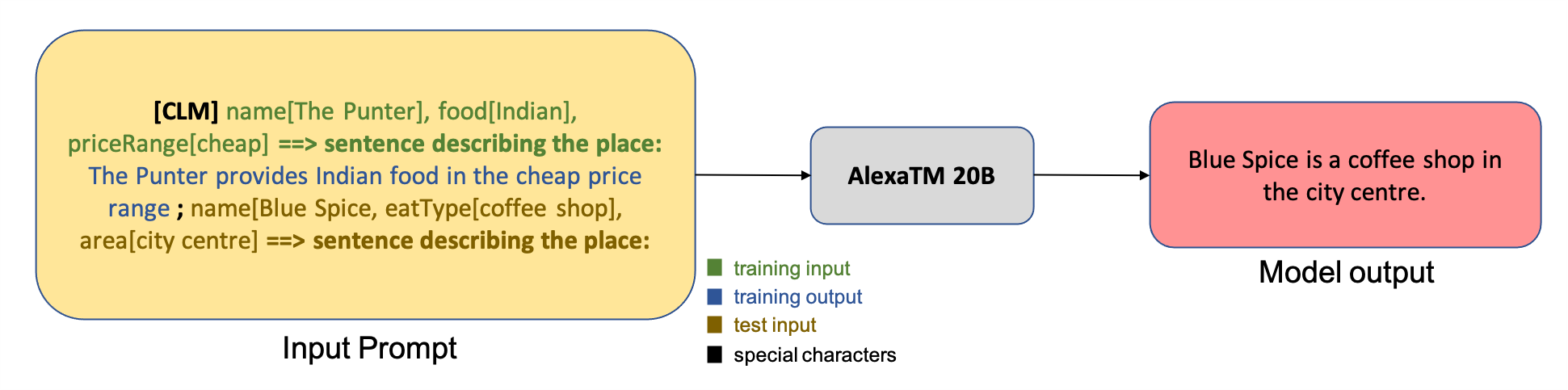
To learn more about the model, check out 20B-parameter Alexa model sets new marks in few-shot learning or the original paper.
Use of AlexaTM 20B is made available for non-commercial use and is covered under the Alexa Teacher Model License agreement.
Solution overview
The following sections provide a step-by-step demo on how to deploy the model, run inference, and do in-context-learning to solve few-shot learning tasks.
Note that the following section contains code snippets; the full code with all the steps in this demo is available in the accompanying notebook: In-context-learning with AlexaTM 20B in SageMaker JumpStart.
Deploy the model
To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more. You also need to create end-to-end tests for scripts, model and the desired instance types to validate that all three can work together. JumpStart removes this effort by providing ready-to-use scripts that have been robustly tested.
SageMaker gives you the ability to run Docker containers extensively for training and inferencing. JumpStart uses these available framework-specific SageMaker Deep Learning Containers (DLCs). We start by fetching the optimized DLC (deploy_image_uri) using the model_id. Then we fetch the model_uri containing the model parameters, along with inference handling scripts and any associated dependencies. Next, we create a model instance in SageMaker and deploy it to a real-time endpoint. See the following code:
Deploying AlexaTM 20B requires a GPU-backed instance with at least 50 GB of CPU memory and at least 42 GB of GPU memory. SageMaker provides many such instances that support real-time inference. We tested this solution on three instances: ml.g4dn.12xlarge, ml.p3.8xlarge, ml.p3.16xlarge. See the following code:
Next, we deploy the model to a SageMaker real-time endpoint:
AlexaTM 20B requires 40 GB of disk space in the inference container. An ml.g4dn.12xlarge instance fulfills this requirement. For instance types ml.p3.8xlarge and ml.p3.16xlarge, we attach an Amazon Elastic Block Store (Amazon EBS) volume to handle the large model size. Therefore, we set volume_size = None when deploying on ml.g4dn.12xlarge and volume_size=256 when deploying on ml.p3.8xlarge or ml.p3.16xlarge.
Deploying the model may take up to 10 minutes. After the model is deployed, we can get predictions from it in real time!
Run inference
AlexaTM 20B is a text generation model which, given a partial sequence (a sentence or piece of text), generates the next set of words. The following code snippet gives you a glimpse of how to query the endpoint we deployed and parse the outputs for auto-completion task. To send requests to a deployed model, we use a JSON dictionary encoded in UTF-8 format. The endpoint response is a JSON object containing a list of generated texts.
Next, we query the endpoint and parse the response on a sample input text:
AlexaTM 20B currently supports 10 text generation parameters during inference: max_length, num_return_sequences, num_beams, no_repeat_ngram_size, temperature, early_stopping, do_sample, top_k, top_p, and seed. For detailed information on valid values for each parameter and their impact on the output, see the accompanying notebook: In-context-learning with AlexaTM 20B in SageMaker JumpStart.
In-context learning
In-context learning refers to the following: we provide the language model with a prompt, which consists of training input-output pairs that demonstrate the task. We append a test input to the prompt and allow the language model to make predictions by conditioning on the prompt and predicting the next tokens or words. This is a highly effective technique to solve few shot-learning problems, in which we learn a task from a few training samples.
Next, we show how you can use AlexaTM 20B for several 1-shot and zero-shot tasks via in-context learning. Unlike prior sequence-to-sequence models, AlexaTM 20B was trained on causal language modeling in addition to denoising, which makes it a good model for in-context learning.
1-shot text summarization
Text summarization is the task of shortening the data and creating a summary that represents the most important information present in the original text. 1-shot text summarization refers to the setting where we learn to summarize the text based on a single training sample. The following code is a text summarization sample from the XSUM dataset:
We use the following prompt for summarization when only one training sample is provided. The generated text from the model is interpreted as the predicted summary of the test article.

The output is as follows:
1-shot natural language generation
Natural language generation is the task of producing text narratives given the input text. The following sample shows a training sample from the E2E dataset:
We use the following prompt for natural language generation when only one training sample (1-shot) is provided. The generated text from the model is interpreted as the predicted text narrative for the test input (test_inp).

The output is as follows:
1-shot machine translation
Machine translation is the task of translating text from one language to another. The following example shows a training sample from the WMT19 dataset in which we need to translate from German to English:
We use the following prompt for machine translation when only one training sample (1-shot) is provided. Generated text from the model is interpreted as the translation of the test input (test_inp).

The output is as follows:
Zero-shot extractive question answering
Extractive question answering is the task of finding the answer to a question from the context paragraph. The following is an example of a context and a question from the SQuAD v2 dataset:
Note that we don’t have any training samples for our task. Instead, we create a dummy question about the last word in the prompt , based on the test_context (dummy-shot). Therefore, we’re actually doing zero-shot extractive question answering.
We use the following prompt for extractive question answering when no training sample is provided. Generated text from the model is interpreted as the answer to the test question.
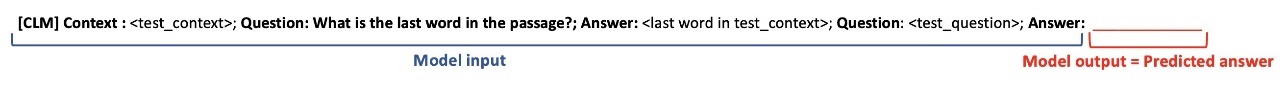
The output is as follows:
Prompt Engineering
Prompt engineering can sometimes be an art. Even small changes to the prompt template can result in significant changes to the model’s performance on a specific task. The following are a few pieces of advice for writing good prompt templates. First, it’s important to remember that the model was trained to learn the structure of real sentences (causal language modeling). As such, it’s best to ensure that your prompt template is grammatically and structurally correct in natural language. Second, this particular model benefits from dummy shots to help teach it the structure expected in the answer, as demonstrated above. Third, it’s always advised to examine task performance over a variety of candidate prompt templates. Promptsource and Natural Instructions are two open-source frameworks for standardizing prompt templates, and they provide a variety of example prompts used for existing modeling tasks. Additionally, Appendix B of the AlexaTM 20B paper provides the prompt templates used to generate the results presented in the paper. There is a growing sub-field dedicated to the automatic creation and learning of the best prompts for a task, including both natural language and continuous prompts. This is beyond the scope of this tutorial.
Clean up
After you’re done running the notebook, make sure to delete all resources created in the process to ensure that your billing is stopped. Code to clean up the endpoint is provided in the associated notebook.
Conclusion
In this post, we showed how to deploy the AlexaTM 20B model on a SageMaker endpoint and run inference. You can use the AlexaTM 20B model for in-context-learning for a variety of few-shot learning tasks. To learn more about AlexaTM 20B, refer to 20B-parameter Alexa model sets new marks in few-shot learning or the original paper.
The authors would like to acknowledge the technical contributions of Maciej Rudnicki, Jakub Debski, Ashish Khetan, Anastasiia Dubinina, Vitaliy Korolev, Karl Albertsen, Saleh Soltan, and Mariusz Momotko toward making this launch possible.
About JumpStart
JumpStart is the machine learning (ML) hub of Amazon SageMaker that offers over 350 pre-trained models, built-in algorithms, and pre-built solution templates to help you get started with ML fast. JumpStart hosts state-of-the-art models from popular model hubs such as TensorFlow, PyTorch, Hugging Face, and MXNet, which support popular ML tasks such as object detection, text classification, and text generation. The ML research community has put a large amount of effort into making a majority of recently developed models publicly available for use. JumpStart aims to help you find right the ML models and algorithms, and immediately start building models. Specifically, JumpStart provides the following benefits:
- Easy access with the UI and SDK – You can access models and algorithms in JumpStart programmatically using the SageMaker Python SDK or through the JumpStart UI in Amazon SageMaker Studio. Currently, AlexaTM 20B is only accessible through the SageMaker Python SDK.
- SageMaker built-in algorithms – JumpStart provides over 350 built-in algorithms and pre-trained models, along with corresponding training scripts (if supported), inferencing scripts, and example notebooks. Scripts are optimized for each framework and task, and provide features such as GPU support, automatic model tuning and incremental training. Scripts are also tested against SageMaker instances and features so that you don’t run into compatibility issues.
- Pre-built solutions – JumpStart provides a set of 23 solutions for common ML use cases, such as demand forecasting and industrial and financial applications, which you can deploy with just a few clicks. Solutions are end-to-end ML applications that string together various AWS services to solve a particular business use case. They use AWS CloudFormation templates and reference architectures for quick deployment, which means they’re fully customizable.
- Support – SageMaker provides a range of support, such as maintaining up-to-date versions when new SageMaker features or Deep Learning Container versions are released, and creating documentation on how to use JumpStart contents in a SageMaker environment.
To learn more about JumpStart and how you can use open-source pre-trained models for a variety of other ML tasks, check out the following AWS re:Invent 2020 video.
- Run text generation with Bloom and GPT models on Amazon SageMaker JumpStart
- Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart
- Run image segmentation with Amazon SageMaker JumpStart
- Run text classification with Amazon SageMaker JumpStart using TensorFlow Hub and Hugging Face models
- Amazon SageMaker JumpStart models and algorithms now available via API
- Incremental training with Amazon SageMaker JumpStart
- Transfer learning for TensorFlow object detection models in Amazon SageMaker
- Transfer learning for TensorFlow text classification models in Amazon SageMaker
- Transfer learning for TensorFlow image classification models in Amazon SageMaker
About the Authors
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
 Jack FitzGerald is a senior applied scientist with Alexa AI, where he currently focuses on large language modeling, multilingual text modeling, and machine learning operations.
Jack FitzGerald is a senior applied scientist with Alexa AI, where he currently focuses on large language modeling, multilingual text modeling, and machine learning operations.
 João Moura is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is mostly focused on NLP use cases and helping customers optimize deep learning model training and deployment. He is also an active proponent of low-code ML solutions and ML-specialized hardware.
João Moura is an AI/ML Specialist Solutions Architect at Amazon Web Services. He is mostly focused on NLP use cases and helping customers optimize deep learning model training and deployment. He is also an active proponent of low-code ML solutions and ML-specialized hardware.
 June Won is a product manager with SageMaker JumpStart and Built-in Algorithms. He focuses on making ML contents easily discoverable and usable for SageMaker customers.
June Won is a product manager with SageMaker JumpStart and Built-in Algorithms. He focuses on making ML contents easily discoverable and usable for SageMaker customers.
 Pulkit Kapur is the product lead for the Alexa Teacher Model program with Alexa AI, focusing on generalized intelligence and applications of Alexa’s multitask multimodal foundation models.
Pulkit Kapur is the product lead for the Alexa Teacher Model program with Alexa AI, focusing on generalized intelligence and applications of Alexa’s multitask multimodal foundation models.