Amazon Web Services ブログ
次世代 SageMaker ノートブック — データ準備、リアルタイムコラボレーション、ノートブックの自動化が組み込まれた新世代の SageMaker ノートブック
2019 年に、初のデータサイエンス、および機械学習 (ML) 向けの完全統合開発環境 (IDE) である Amazon SageMaker Studio の提供を開始しました。SageMaker Studio では、データの準備からモデルのトレーニングとデバッグ、実験の追跡、モデルのデプロイと監視、パイプラインの管理に至るまで、すべての機械学習ステップを実行する専用ツールと統合された Jupyter Notebook にアクセスできます。
2022/11/30、機械学習開発ワークフロー全体の効率を高める次世代の Amazon SageMaker ノートブック を発表できることを嬉しく思います。組み込みのデータ準備機能により、データ品質を数分で改善したり、同じノートブックをチームでリアルタイムで編集したり、ノートブックのコードを本番稼働用のジョブに自動的に変換したりできるようになりました。
新着情報をお見せします。
データの準備を簡単にする、新しいノートブックの機能
新しい組み込みのデータ準備機能は、Amazon SageMaker Data Wrangler を利用しており、SageMaker Studio ノートブックで利用することができます。 SageMaker Studio ノートブックでは、Pandas データフレーム上に主要なビジュアライゼーションが自動的に生成されるため、データ分布を把握したり、欠損値、無効なデータ、外れ値などのデータ品質上の問題を特定したりすることができます。また、ML モデルのターゲット列を選択して、不均衡なクラスや相関の高い列など、ML 固有のインサイトを生成することもできます。その後、問題を解決するためのデータ変換に関する推奨事項が表示されます。データ変換は UI 内で直接適用することができ、SageMaker Studio ノートブックは対応する変換コードをノートブックのセルに自動的に生成し、データ準備パイプラインの再生に使用できます。
組み込みのデータ準備機能を使用する
はじめに、pip は pandas Python パッケージと一緒に sagemaker_datawrangler をインストールしてインポートします。次に、分析するデータセットをノートブックの作業ディレクトリにダウンロードし、pandas を使ってデータセットを読み取ります。
import pandas as pd
import sagemaker_datawrangler
!aws s3 cp s3://<YOUR_S3_BUCKET>/data.csv .
df = pd.read_csv("data.csv")
データフレームを表示すると、各列の上部に主要なデータビジュアライゼーションが自動的に表示され、データインサイトが明らかになり、データ品質の問題が検出され、データ品質を向上させるための解決策が提案されます。ML 予測のターゲット列として列を選択すると、ターゲットのデータ型が混在している (リグレッションの使用の場合)、クラスあたりのインスタンス数が少なすぎる (分類のユースケースの場合) など、ターゲット固有のインサイトと警告が表示されます。
この例では、婦人服に関するカスタマーレビューと評価を含む女性用 E コマース服レビューデータセットを使用しています。このデータセットは Kaggle から取得したもので、合成データ品質の問題が追加されるように Amazon によって修正されました。

推奨されるデータ変換を確認してデータ品質を向上させ、UI で直接適用できます。サポートされているすべてのデータ変換のリストについては、ドキュメントを参照してください。データ変換を適用すると、SageMaker Studio ノートブックはそれらのデータ準備手順を別のノートブックセルに再現するコードを自動的に生成します。
この例では、ターゲット列として [評価] を選択します。ターゲット列のインサイトでは、優先度の高い警告で、この列はクラスあたりのインスタンスが少なすぎること、中程度の優先度の警告で、クラスがアンバランスすぎることを示しています。提案に従って、まれなターゲット値を削除し、欠損値を削除しましょう。また、一部の機能列の提案に従い、不足している値を [レビューテキスト] 列から削除し、[部門名] 列も削除します。
変換を適用すると、ノートブックは次のコードを生成します。
# Pandas code generated by sagemaker_datawrangler
output_df = df.copy(deep=True)
# Code to Drop rare target values for column: Rating to resolve warning: Too few instances per class
rare_target_labels_to_drop = ['-100', '100']
output_df = output_df[~output_df['Rating'].isin(rare_target_labels_to_drop)]
# Code to Drop missing for column: Rating to resolve warning: Missing values
output_df = output_df[output_df['Rating'].notnull()]
# Code to Drop missing for column: Review Text to resolve warning: Missing values
output_df = output_df[output_df['Review Text'].notnull()]
# Code to Drop column for column: Division Name to resolve warning: Missing values
output_df=output_df.drop(columns=['Division Name'])これで、必要に応じてコードを確認して変更したり、機械学習開発ワークフローの一部としてデータ変換の統合を開始したりできます。
チームベースの共有とリアルタイムコラボレーションのための共有スペースのご紹介
SageMaker Studio では、データサイエンスチームや ML チームがノートブックをリアルタイムで読み、編集し、同時に実行できるワークスペースを提供し、開発プロセスにおけるコラボレーションやコミュニケーションを効率化する共有スペースを提供するようになりました。共有スペースでは、共有スペース内のファイルの共有に使用できる共有 Amazon EFS ディレクトリを提供します。共有スペースで作成したタグ付け可能な SageMaker リソースにはすべて自動的にタグが付けられるため、スペースで取り組んでいるビジネス上の問題に関連する ML リソース (トレーニングジョブ、実験、モデルなど) を整理し、フィルタリングして表示できます。これは、AWS Budgets や AWS Cost Explorer などのツールを使用してコストを監視し、予算を計画するのにも役立ちます。
それだけではありません。同じ AWS アカウント内に複数の SageMaker ドメインを作成して、アクセスを絞り込み、リソースを組織内のさまざまなチームやビジネスユニットに分離することもできます。それでは、SageMaker ドメイン内にユーザー用の共有スペースを作成する方法を説明します。
共有スペースを使用する
SageMaker コンソールまたは AWS CLI を使用して、SageMaker ドメイン用の共有スペースを作成できます。SageMaker コンソールの使用を開始するには、[ドメイン] に移動し、新しいドメインを選択または作成して、ドメイン詳細ページで [スペース管理] を選択します。次に、[作成] を選択し、共有スペースに名前を付けます。
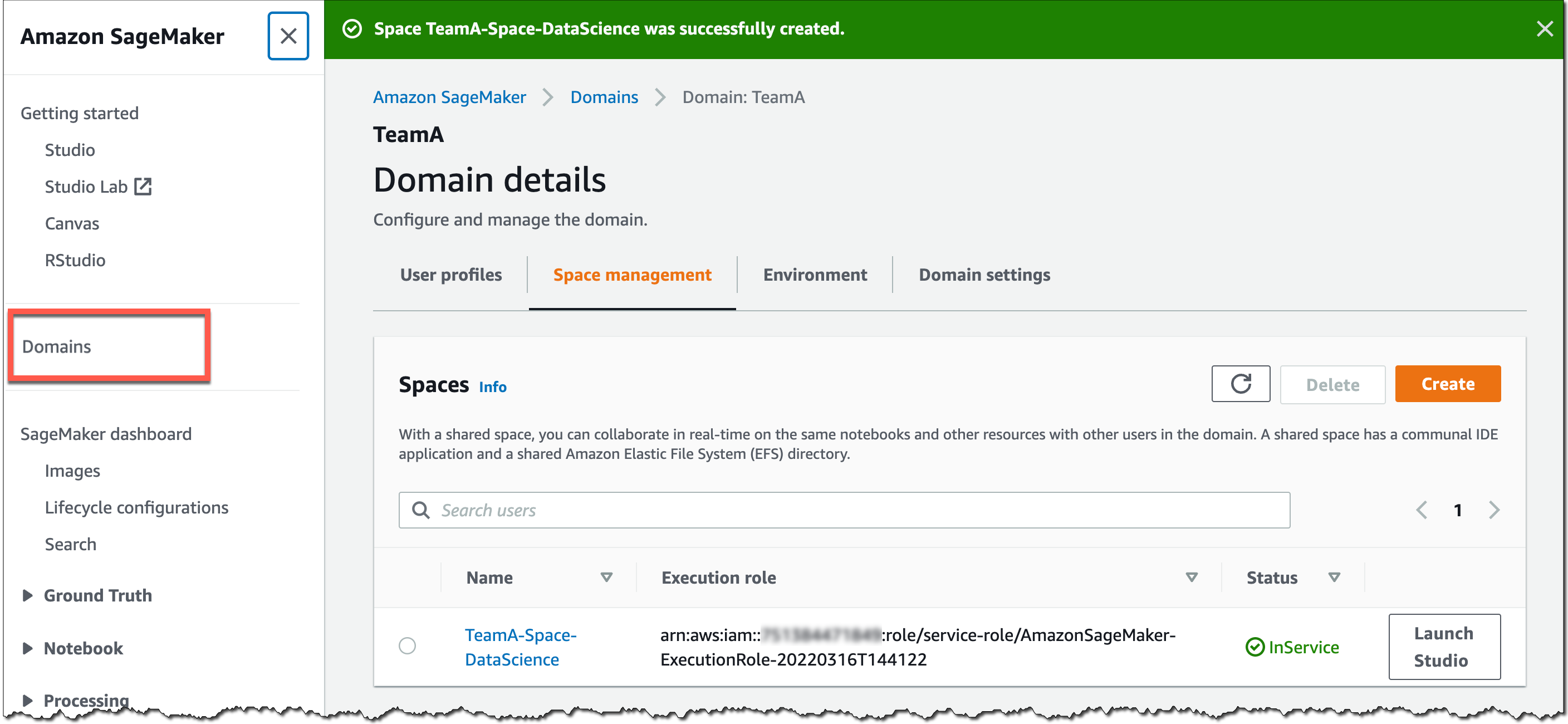
この SageMaker ドメインのユーザーは、SageMaker ドメインのユーザープロファイルを使用して共有スペースを起動して参加できるようになりました。
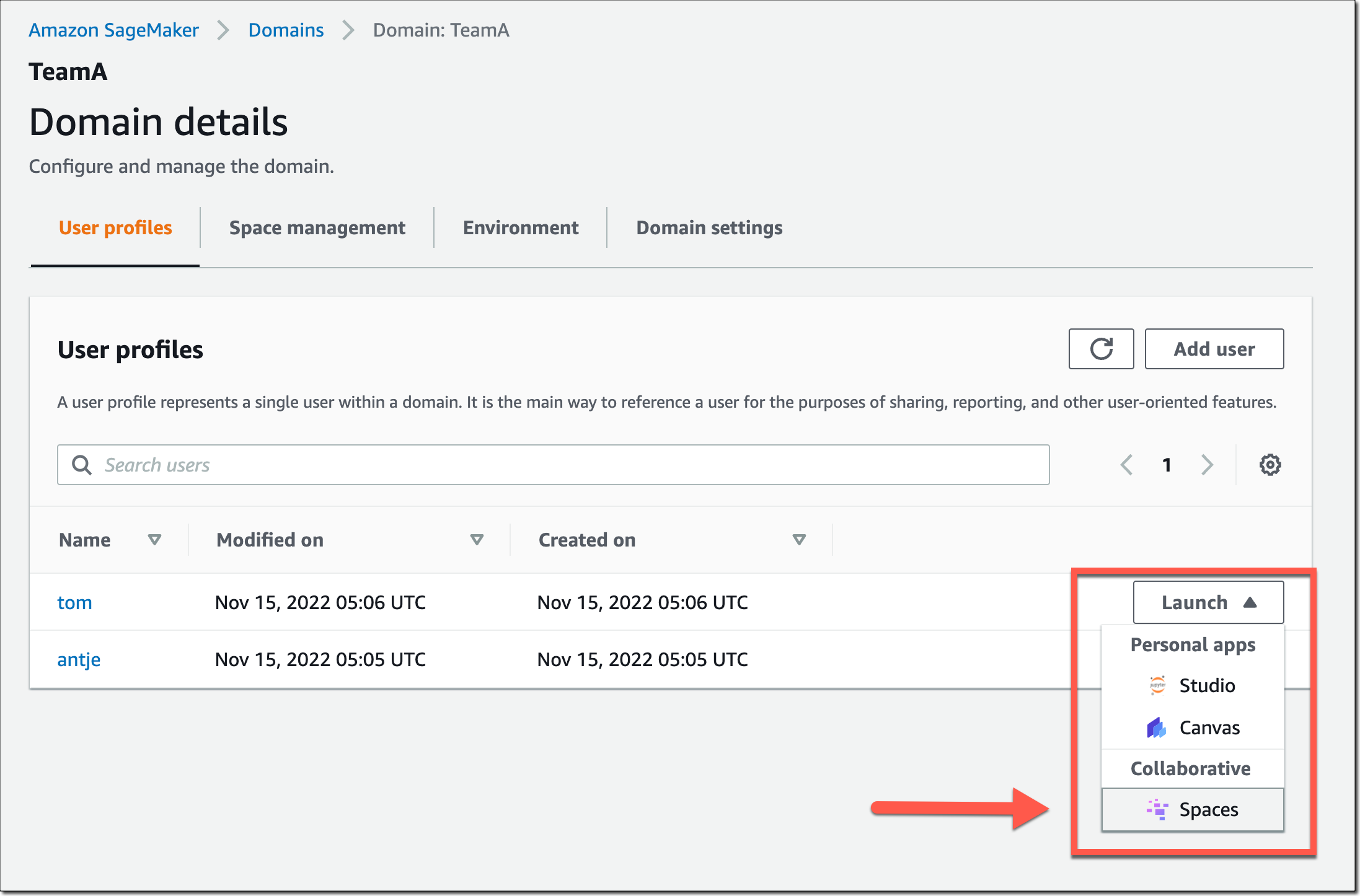
共有スペースで、左側のナビゲーションメニューにある新しいコラボレーターアイコンを選択します。これで、このスペースで他に誰がアクティブかを確認できるようになりました。次のスクリーンショットは、左側のユーザー tom がノートブックファイルを編集しているところを示しています。右側では、ユーザー antje が、そのノートブックのセルを現在編集しているユーザー名の注釈とともに、編集内容をリアルタイムで確認しています。

ノートブックのコードを本番稼働対応のジョブに自動的に変換する新しいノートブック機能
ノートブックを選択して、基盤となるインフラストラクチャを管理しなくても本番環境で実行できるジョブとして自動化できるようになりました。SageMaker ノートブックジョブを作成すると、SageMaker Studio はノートブック全体のスナップショットを取得し、その依存関係をコンテナにパッケージ化し、インフラストラクチャを構築して、定義したスケジュールに従ってノートブックを自動ジョブとして実行し、ジョブの完了時にインフラストラクチャのプロビジョニングを解除します。ノートブックのこの機能は、機械学習を学び、実験するためのコンピューティング、ストレージ、セキュリティを提供する無料の機械学習開発環境である SageMaker Studio Lab でも利用できるようになりました。
ノートブック機能を使用してノートブックを自動化する
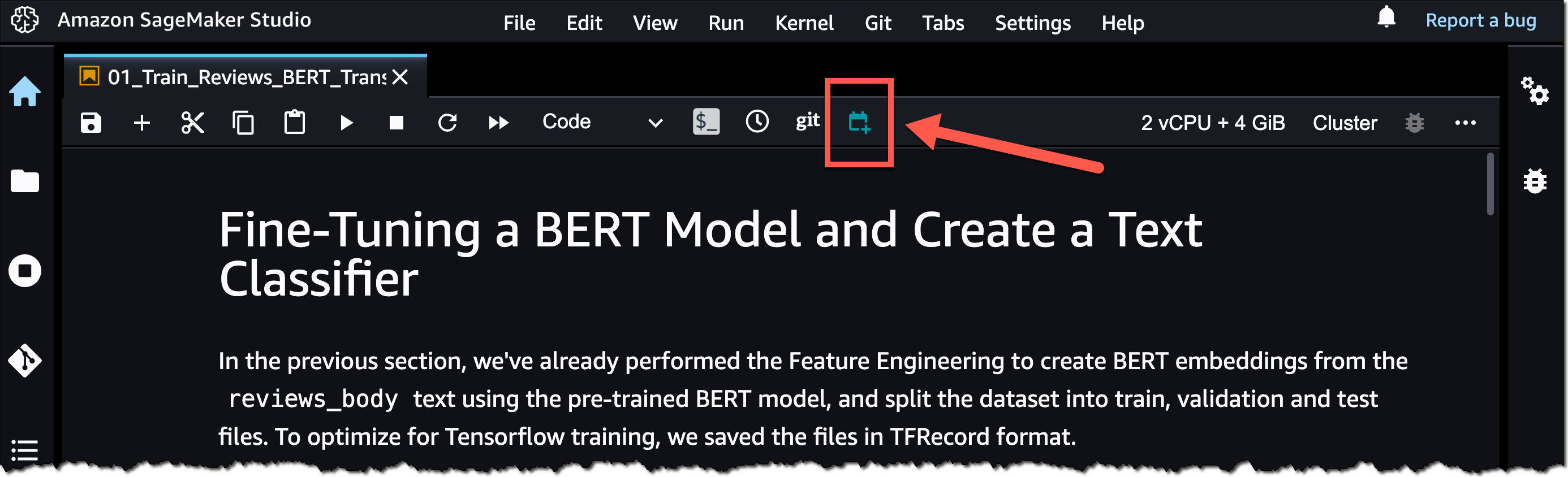
はじめに、SageMaker Studio でノートブックファイルを開きます。次に、ノートブックファイルを右クリックし、[ノートブックジョブの作成] を選択するか、次のスクリーンショットで強調表示されているように [ノートブックジョブの作成] アイコンを選択します。
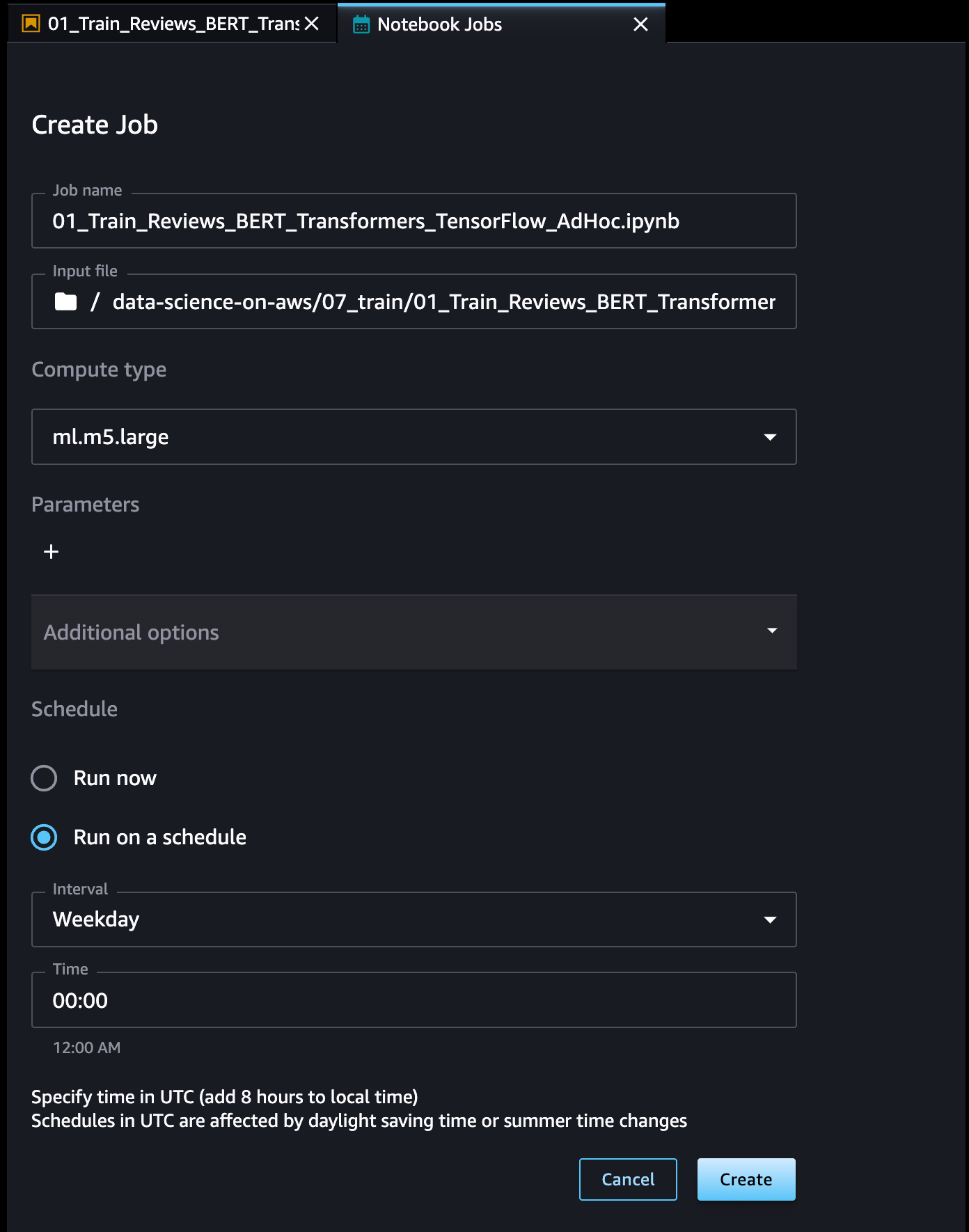
ノートブックジョブの名前を定義し、入力ファイルの場所を確認し、使用するコンピューティングタイプを指定し、ジョブをすぐに実行するか、スケジュールに従って実行するかを指定します。その後、[Create] (作成) を選択します。
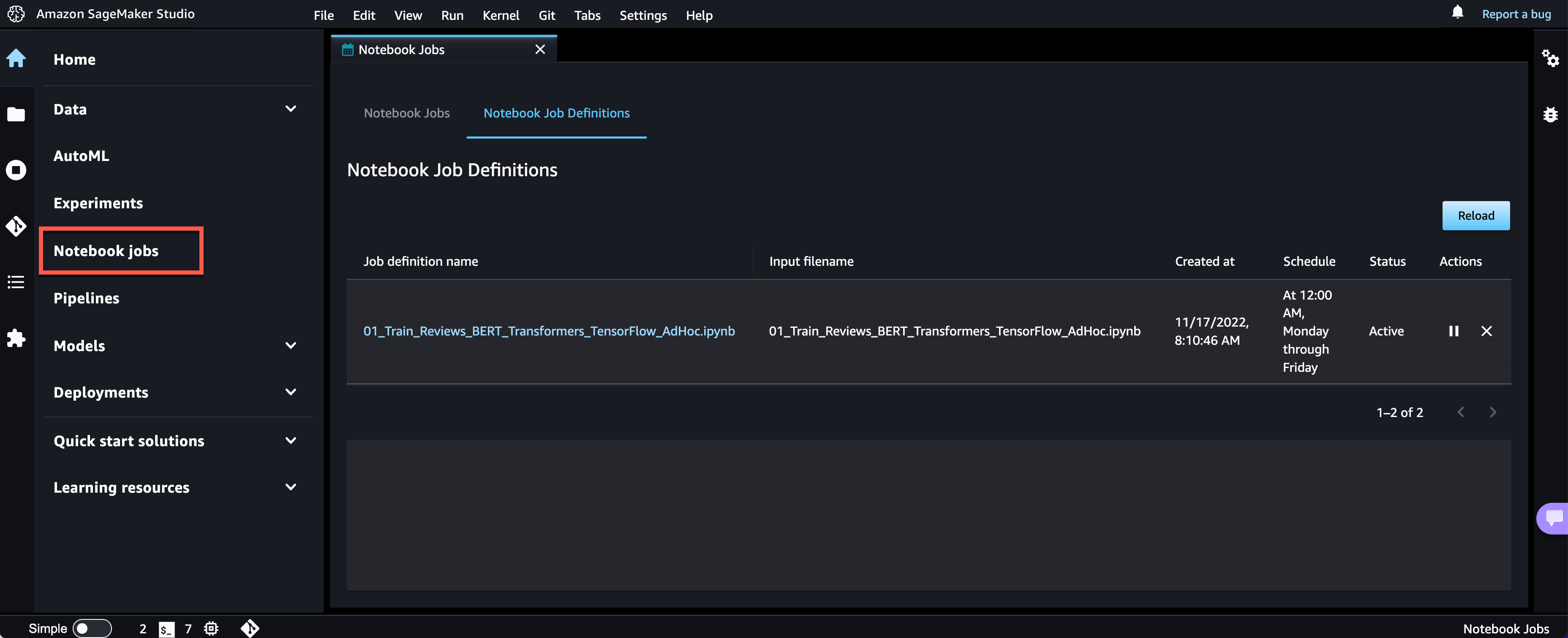
ノートブックジョブが作成されました。すべてのノートブックジョブ定義を UI で確認できます。
今すぐご利用いただけます
Amazon SageMaker Studio の新しいノートブック機能では、Amazon SageMaker Studio が利用可能なすべての AWS リージョンで利用できるようになりました。ただし、AWS 中国リージョンは除きます。
リリース時には、SageMaker Data Wrangler が提供する組み込みのデータ準備機能が SageMaker Studio ノートブックと以下のノートブックカーネルイメージでサポートされています。
- パイソン 3 (データサイエンス) と Python 3.7
- パイソン 3 (データサイエンス 2.0) と Python 3.8
- パイソン 3 (データサイエンス 3.0) と Python 3.10
- Spark Analytics 1.0 と 2.0
詳細については、Amazon SageMaker ノートブックを参照してください。
次世代の Amazon SageMaker ノートブックを使って ML プロジェクトの構築を今すぐ始めましょう。
– Antje
原文はこちらです。