Amazon Web Services ブログ
AWS Step Functions および AWS Glue を使用した Amazon Redshift ベースの ETL ワークフローのオーケストレーション
Amazon Redshift は、ペタバイト規模の完全マネージド型クラウドデータウェアハウスサービスで、現在お使いのものと同じ SQL ベースのツールとビジネスインテリジェンスアプリケーションを使用した迅速なクエリパフォーマンスを提供します。お客様の多くは、既存の SQL ベースのスクリプトを素早く移行するために既存の SQL 開発者スキルセットを使用する ETL (抽出、変換、ロード) エンジンとして Amazon Redshift を利用しておられると共に、Amazon Redshift が完全に ACID 対応であることから、ソースデータシステムからの変更データを統合するための効率的なメカニズムとしても利用しておられます。
この記事では、AWS Step Functions および AWS Glue Python Shell を使用して、完全にサーバーレスな方法でこれらの Amazon Redshift ベースの ETL ワークフローのタスクをオーケストレーションする方法をご紹介します。AWS Glue Python Shell は、SQL クエリを送信して応答を待つといった小規模から中規模の ETL タスクを実行するための Python ランタイム環境です。Step Functions は、一連の ETL タスクを簡単に実行して監視できるように、複数の AWS サービスをワークフローにまとめることを可能にします。AWS Glue Python Shell と Step Functions はどちらもサーバーレスであるため、サーバーのプロビジョニング、スケーリング、および管理を行う必要なく、ユーザー定義のイベントに応答してこれらを自動で実行し、スケールすることが可能です。
従来の SQL ベースのワークフローの多くは、トリガーおよびストアドプロシージャなどの内在のデータベース構成概念を使用しますが、ワークフローオーケストレーション、タスク、およびコンピュートエンジンの各コンポーネントをスタンドアロンサービスに分離することにより、各コンポーネントを開発、最適化、そして再利用することさえも可能になります。このため、この記事では Amazon Redshift を例として使用しますが、あらゆる SQL ベースの ETL をオーケストレーションする方法をより全般的に説明することを目的としています。
前提条件
この記事の例に沿って独自の AWS アカウントを使用しながら進めたいという場合は、S3 VPC エンドポイントへのルートがある少なくとも 2 つのプライベートサブネットを使った Virtual Private Cloud (VPC) が必要です。
VPC がない、またはこれらの要件を満たすかどうかが分からない場合は、以下のボタンを選択することで起動できる AWS CloudFormation テンプレートスタックをご用意しました。最初のページでスタックに名前を付け、残りはすべてデフォルト設定のままにしておきます。スタックに Create Complete が表示されるまで待ってから (これには数分しかかからないはずです)、他のセクションに進んでください。
![]()
シナリオ
この記事の例では、Amazon Customer Reviews Dataset を使って、シンプルな ETL プロセスを表す以下の 2 つのタスクを完了する ETL ワークフローを構築します。
- タスク 1: 2015 年以降のレビューが含まれたデータセットのコピーを S3 から Amazon Redshift テーブルに移動させる。
- タスク 2: 市場および製品カテゴリごとに「最も役に立つ」レビューを特定する出力ファイル一式を別の Amazon S3 ロケーションに生成する。これにより、分析チームが高品質レビューを収集できるようになります。
このデータセットは、Amazon Simple Storage Service (Amazon S3) バケット経由で公開されています。以下のタスクを完了してセットアップします。
ソリューションの概要
以下の図は、ソリューションアーキテクチャの全体を説明するものです。

このプロセスにおけるステップは以下のとおりです。
- ステートマシンが AWS Secrets Manager からデータベース接続情報、および S3 から .sql ファイルを取得するためのパラメータを持つ AWS Glue Python Shell ジョブの一連を実行します (単一のジョブを使用する方法と理由はこの後で詳しく説明します!)。
- AWS Glue Python Shell ジョブの実行はそれぞれ、Amazon Redshift クラスターに接続し、.sql ファイルに含まれているクエリを送信するためにデータベース接続情報を使用します。
- タスク 1: クラスターが Amazon Redshift Spectrum を利用して S3 からデータを読み込み、それを Amazon Redshift テーブルにロードします。Amazon Redshift Spectrum は一般に、Amazon Redshift にデータをロードする手段として使用されます。(詳細については、Amazon Redshift Spectrum 12 のベストプラクティスのステップ 7 を参照してください。)
- タスク 2: クラスターが集約クエリを実行し、UNLOAD コマンドでその結果を別の Amazon S3 ロケーションにエクスポートします。
- ステートマシンは、パイプラインが失敗した場合に、Amazon Simple Notification Service (SNS) トピックに通知を送信することもできます。
- ユーザーは、クラスターからのデータをクエリする、および/または S3 からレポート出力ファイルを直接取得することができます。
この記事では、タスクとオーケストレーションコンポーネントの構築に特化したステップに集中できるように、ETL 環境を素早く起動するための AWS CloudFormation テンプレートをご用意しました。このテンプレートは、以下のリソースを起動します。
- Amazon Redshift クラスター
- Amazon Redshift クラスターの情報と認証情報を保存するための Secrets Manager シークレット
- Python スクリプトと .sql ファイルが事前にロードされた S3 バケット
- AWS Glue Python Shell ジョブのための Identity and Access Management (IAM) ロール
これらの手順を手動で完了する方法については、以下のリソースを参照してください。
- VPC で Redshift クラスターを作成する
- AWS Secrets Manager によるシークレットの作成と管理
- Amazon Simple Storage Service (S3) の使用開始
- IAM ロールの作成
![]()
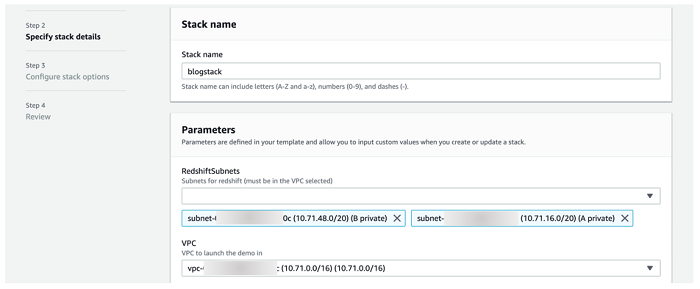
以下のスクリーンショットにあるように、少なくとも 2 つのプライベートサブネットと、対応する VPC を選択するようにしてください。上記の VPC テンプレートを使用している場合は、VPC が 10.71.0.0/16 として表示され、サブネット名が A private および B private として表示されます。
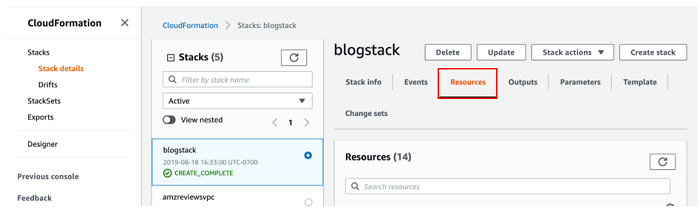
スタックの起動には 10~15 分かかります。Create Complete が表示されたら、次のセクションに進むことができます。以下のスクリーンショットにある、AWS CloudFormation コンソールの [リソース] タブの内容を記録しておいてください。これらのリソースは、この記事全体で参照されます。
AWS Glue Python Shell での構築
AWS マネジメントコンソールの AWS Glue に移動することから始めます。
接続の実行
Amazon Redshift クラスターは VPC に格納されているため、まず AWS Glue を使って接続を作成する必要があります。接続には、データストアへのアクセスに必要な VPC ネットワーク情報を含めたプロパティがあります。この接続は、最終的に Glue Python Shell ジョブにアタッチします。ジョブが Amazon Redshift クラスターにアクセスできるようにするためです。
メニューバーから [接続] を選択し、[接続の追加] を選択します。以下のスクリーンショットにあるように、接続に blog_rs_connection などの名前を付けて、[接続タイプ] に [Amazon Redshift] を選択してから、[次へ] を選択します。

[クラスター] に、AWS CloudFormation テンプレートが起動されたクラスターの名前、つまり blogstack-redshiftcluster-#### を入力します。この記事のために提供された Python コードはすでに資格情報の取得を処理するため、ここで入力するデータベース情報の残りの値は、ほとんどがプレースホルダーです。接続に関連付けている主要な情報は、ネットワーク関連のものです。
正しいクラスター情報がなくては接続をテストできないことに注意してください。テストすることに関心がある場合は、以下のスクリーンショットにあるように、正しいクラスターを選択した後で [データベース名] と [ユーザー名] が自動入力されることに注意してください。ここにある手順に従って Secrets Manager からパスワードを取得し、[パスワード] フィールドに貼り付けます。

ETL コードレビュー
この例で使用されている 2 つの主な Python スクリプトを見てみましょう。
Pygresql_redshift_common.py は、Secrets Manger からクラスターの接続情報と資格情報を取得し、クラスターへの接続を確立して、クエリをそれぞれ送信できる関数一式です。渡されたパラメータ経由でランタイムのクラスター情報を取得することによって、これらの関数は、ジョブがアクセスできる任意のクラスターに接続することを可能にします。これらの関数は、この手順に従って python .egg ファイルを作成することによって、ライブラリにパッケージ化することができます (AWS CloudFormation テンプレート起動の一環としてすでに完了されています)。AWS Glue Python Shell はいくつかの python ライブラリをネイティブにサポートすることに留意してください。
AWS Glue Python Shell ジョブは、呼び出されると rs_query.py を実行します。これは、呼び出しで渡されたジョブ引数を解析することによって開始されます。これらの引数の一部を使用して S3 から .sql ファイルを取得した後、クラスターに接続し、pygresql_redshift_common.py からの関数を使用してファイル内のステートメントをクラスターに送信します。従って、先ほどパッケージ化した Python ライブラリを使用して任意のクラスターに接続することに加えて、任意の SQL ステートメントを取得して実行することもできます。つまり、パイプラインの各タスクを完了するためにどこに接続し、何を送信するべきかについてのパラメータを渡すだけで、すべての Amazon Redshift ベースの ETL のために単一の AWS Glue Python Shell ジョブを管理することができるということです。
Glue Python Shell ジョブの作成
次に、コードを実行します。
- AWS Glue コンソールページの左にあるメニューの [ジョブ] に移動して、そこから [ジョブの追加] を選択します。
- ジョブに blog_rs_query といった名前を付けます。
- [IAM ロール] には、前に AWS CloudFormation コンソールの [リソース] セクションから記録したものと同じ [GlueExecutionRole] を選択します。
- [Type] には [Python shell] を選択し、[Python のバージョン] はデフォルトの [Python 3] のままにしておいて、[このジョブ実行] には [ユーザーが提供する既存のスクリプト] を選択します。
- [スクリプトが保存されている S3 パス] には、AWS CloudFormation テンプレートが作成したスクリプトバケット ([リソース] で [ScriptBucket] を探してください) に移動してから、python/py ファイルを選択します。
- [セキュリティ設定、スクリプトライブラリおよびジョブパラメータ (任意)] セクションを展開して、Amazon Redshift 接続ライブラリがある Python .egg ファイルを [Python ライブラリパス] に追加します。これも、python /redshift_module-0.1-py3.6.egg のスクリプトバケットにあります。
すべてが完了したら、以下のスクリーンショットのようになるはずです。

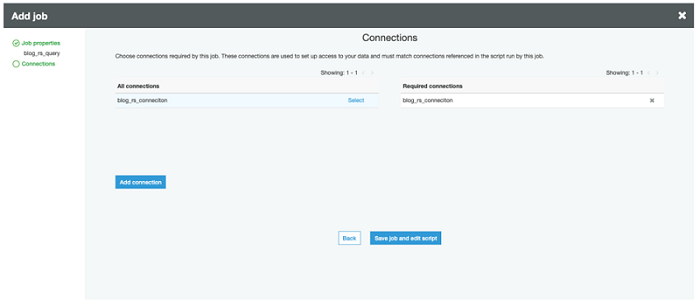
[次へ] を選択します。作成した接続の [選択] を選んで、[要求される接続] に移動させることで接続を追加します。(「接続の実行」セクションで説明したように、これが VPC とやり取りできる機能をジョブに提供します。) 以下のスクリーンショットにあるように、[ジョブを保存してスクリプトを編集する] を選択して終了します。
Python Shell ジョブのテスト実行
ジョブを作成したら、AWS Glue Python Shell の IDE が表示されます。すべてが上手く運んでいれば、rs_query.py コードが表示されるはずです。現在、Amazon Redshift クラスターは空のままなので、Python コードを使用して以下の SQL ステートメントを実行し、テーブルを投入します。
- 外部データベース (amzreviews) を作成します。
- Amazon Redshift Spectrum が S3 にあるソースデータ (パブリックレビューデータセット) から読み込むことができる外部テーブル (reviews) を作成します。テーブルは product_category でパーティション化されています。これは、ソースファイルがカテゴリごとに分類されているからですが、通常は、頻繁にフィルタリングされる列にパーティション化する必要があります (セクション 4 を参照)。
- 外部テーブルにパーティションを追加します。
- Amazon Redshift クラスターにとってローカルの内部テーブル (reviews) を作成します。product_id は、カーディナリティが高く、分散が均等であり、他のテーブルとの結合に使用される可能性が最も高い (明確にはこのブログのシナリオの一部ではありませんが) 列であるため、DISTKEY に適しています。ターゲットクエリ (2015 年以降) の一部ではないレビューデータを効率的に排除するため、review_date を SORTKEY として選択します。テーブルの設計ドキュメントを読んで、パフォーマンスの最適化のために DISTKEY/SORTKEY、および追加のテーブル設計パラメータを選択する最も良い方法について学んでください。
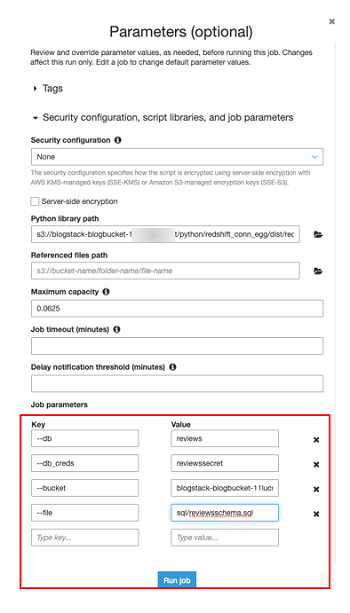
この最初のジョブ実行は、これまでに説明したすべての要素がどこで機能するかを確認できるように、手動で行ってください。IDE 画面の最上部で [ジョブの実行] を選択します。[セキュリティ設定、スクリプトライブラリおよびジョブパラメータ (省略可能)] セクションを展開します。以下のスクリーンショットにあるように、ここでパラメータをキー/値ペアとして追加します。
| キー | 値 |
| –db | reviews |
| –db_creds | reviewssecret |
| –bucket | <name of s3 script bucket> |
| –file | sql/reviewsschema.sql |
[ジョブの実行] を選択して開始します。ジョブの完了には数秒かかります。IDE でコードの下にあるログ出力を探して、ジョブの進捗状況を監視できます。
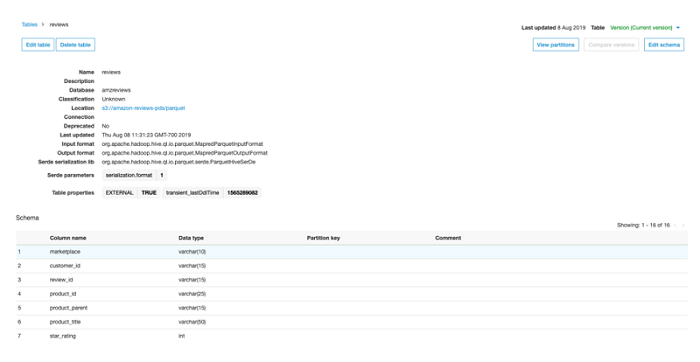
ジョブが完了したら、AWS Glue コンソールの [データベース] に移動して、以下のスクリーンショットにあるように、amzreviews データベースと reviews テーブルを探します。それらがそこにあれば、すべてが計画通りに行われたことになります! Redshift クエリエディタ を使用、または独自の SQL クライアントツール を使って Amazon Redshift クラスターに接続し、ローカルの reviews テーブルを探すこともできます。
Step Functions オーケストレーション
ジョブを手動で実行することができたところで、Step Functions によってオーケストレーションされる、よりプログラム的な部分に進みます。
テンプレートの起動
このプロセスを開始するために、3 つ目の AWS CloudFormation テンプレートをご用意しました。これは、この記事の最初で説明した 2 つのタスクを完了するために、先ほど作成したの AWS Glue Python Shell ジョブの 2 つのインスタンスを呼び出す Step Functions ステートマシンを作成します。
![]()
[BucketName] には、2 つ目の AWS CloudFormation スタックで作成されたスクリプトバケットの名前を貼り付けます。[GlueJobName] には、先ほど作成したジョブの名前を入力します。他の情報は、以下のスクリーンショットにあるように、デフォルトのままにしておきます。スタックを起動して、[Create Complete] が表示されるまで待ちます (これには 2、3 分しかかからないはずです)。その後、次のセクションに進みます。

Step Functions ステートマシンでの作業
ステートマシンは一連のステップで構成されており、サービスを堅牢な ETL ワークフローにつなぎ合わせることを可能にします。実行の各ステップは、実行されるのをそのまま監視することができます。つまり、ETL ワークフローの問題をすばやく識別して修正し、それらを自動で行うこともできます。
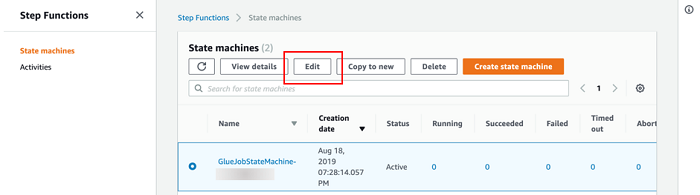
より良く理解するために、先ほど起動したステートマシンを見てみましょう。AWS コンソールの Step Functions に移動して、GlueJobStateMachine-###### といった名前のステートマシンを探します。 以下のスクリーンショットにあるように、[編集] を選択してステートマシンの設定を表示します。
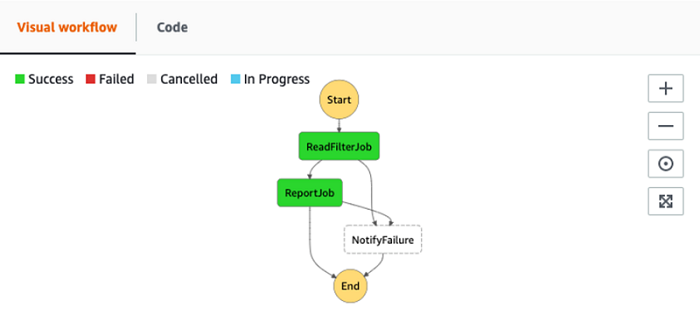
これは、以下のスクリーンショットのようになるはずです。

ご覧いただけるように、ステートマシンはタスク定義とワークフローロジックで構成された JSON テンプレートを使って作成されています。Parallel タスクを実行する、エラーを見つける、そしてワークフローを一時停止して、手動のコールバックまで続行せずに待機することもできます。ここで提供する例には、記事の最初で説明した目的を達成する SQL ステートメントを実行するための 2 つのタスクが含まれています。
- Redshift Spectrum を使用して S3 からデータをロードする
- データを変換して S3 に書き込む
各タスクには基本的なエラーハンドリングが含まれており、エラーが発見されると、ワークフローをエラー通知タスクにルーティングします。この例は、基本的なワークフローを構築する方法を紹介するためのシンプルな例ですが、Step Functions ドキュメントでより複雑なワークフローの例を参照して、堅牢な ETL パイプラインを構築するために役立てることができます。Step Functions は、ネストされたワークフローでのモジュラーコンポーネントの再利用もサポートします。
SQL レビュー
ステートマシンは、以下の SQL ステートメントを取得して実行します。
前述したように、Amazon Redshift Spectrum は INSERT INTO ステートメントを使用して ETL を実行するための優れた方法です。この例は、データが S3 にあることからシンプルなデータのロードですが、ロードする前に、データを変換するより複雑な SQL ステートメントを追加できることも念頭に置いておいてください。
このステートメントはレビューを製品別に、役に立ったという投票数順に並べてグループ化し、UNLOAD コマンドを使用して Amazon S3 に書き込みます。
ステートマシンの実行
すべての準備が整ったところで、実行を開始しましょう。ステートマシンのメインページから、[実行の開始] を選択します。

デフォルトをそのまま使用し、[開始] を選択して実行を始めます。実行が開始されると、以下のスクリーンショットにあるように、実行の進捗状況を把握できるビジュアルワークフローインターフェイスが表示されます。

各クエリは実行に数分かかります。その間、Amazon Redshift クエリログを監視して、クエリの進捗状況をリアルタイムで追跡できます。これらは、以下のスクリーンショットにあるように、AWS コンソールの Amazon Redshift に移動して、Amazon Redshift クラスターを選択し、[クエリ] タブを選択することで見つけることができます。

両方のクエリに COMPLETED が表示されたら、ステートマシンの実行に戻ります。以下のスクリーンショットにあるように、ステートそれぞれが成功しているはずです。
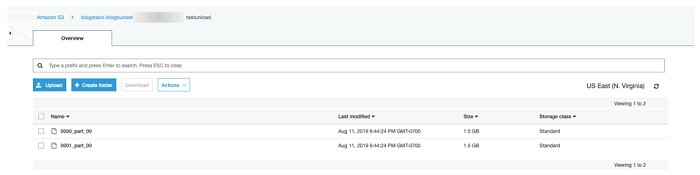
次に、S3 AWS コンソールページのデータバケットに移動します (CloudFormation [リソース] タブの DataBucket を参照)。すべてが計画通りに進んでいれば、以下のスクリーンショットにあるように、アンロードされたデータが含まれるバケットに testunload という名前のフォルダがあるはずです。
Step Functions ステートマシンへの障害の投入
次に、意図的にエラーを発生させてステートマシンのエラーハンドリングコンポーネントをテストします。これを簡単に行う方法は、以下のスクリーンショットにあるように、ステートマシンを編集して、ReadFilterJob タスクの Secrets Manager シークレットの名前を間違った綴りにすることです。
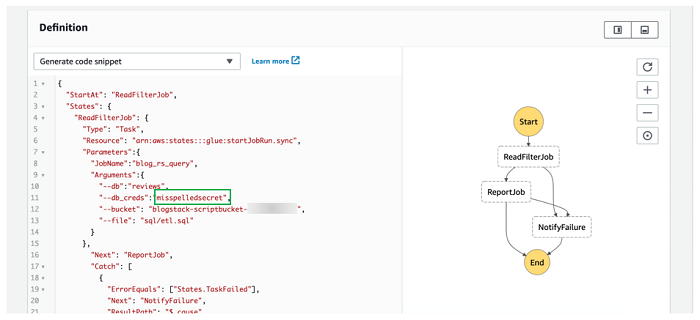
エラー出力を自分宛てに送信したい場合は、オプションでエラー通知 SNS トピックにサブスクライブします。前回と同様に、別のステートマシンの実行を開始します。以下のスクリーンショットにあるように、今回はワークフローが NotifyFailure タスクに進むはずです。それに関連付けられた SNS トピックにサブスクライブしている場合は、その後まもなくメッセージを受け取るはずです。

ステートマシンのログには、以下のスクリーンショットにあるように、エラーがより詳細に表示されます。

まとめ
この記事では、サーバーレスの AWS Step Functions と AWS Glue Python Shells ジョブを使用して Amazon Redshift ベースの ETL をオーケストレーションする方法を説明しました。冒頭でお話ししたように、このコンセプトは他の SQL ベースの ETL にも一般的に適用できるので、これらを使用して今すぐ独自の SQL ベースの ETL パイプラインの構築を始めてください!
著者について
 Ben Romano は AWS の Data Lab ソリューションアーキテクトです。Ben は、お客様が AWS Data Lab を使って、たった 4 日間でデータと分析のプロトタイプを設計し、構築するお手伝いをしています。
Ben Romano は AWS の Data Lab ソリューションアーキテクトです。Ben は、お客様が AWS Data Lab を使って、たった 4 日間でデータと分析のプロトタイプを設計し、構築するお手伝いをしています。