Amazon Web Services ブログ
プレビュー – 基盤モデルでタスクを完了させるための Agents for Amazon Bedrock
今年 4 月、AWS の Data and Machine Learning の Vice President である Swami Sivasubramanian は、AWS 上で生成系 AI を使用して構築するための新しいツールの一部として Amazon Bedrock モデルと Amazon Titan モデルを発表しました。現在プレビュー段階にある Amazon Bedrock は、Amazon や主要な AI スタートアップ (AI21 Labs、Anthropic、Cohere、Stability AI) の基盤モデル (FM) を API を通じて利用できるようにするフルマネージドサービスです。
本日、Agents for Amazon Bedrock のプレビューを発表できることを嬉しく思います。これは、開発者が数回クリックするだけでフルマネージドエージェントを作成できる新しい機能です。Agents for Amazon Bedrock によって、 API 経由でタスクを管理および実行できるような生成系 AI アプリケーションを、企業のシステムに導入することを加速します。エージェントは FM を拡張して、ユーザーのリクエストを理解し、複雑なタスクを複数のステップに分解し、会話を継続して追加情報を収集し、リクエストを満たすためのアクションを実行します。
Agents for Amazon Bedrock を使用すると、小売注文の管理や保険金請求の処理など、社内外の顧客のタスクを自動化できます。例えば、エージェントを利用した生成系 AI の e コマースアプリケーションは、「この青いジャケットはありますか?」という質問に簡単な回答で応答できるだけではなく、注文の更新や交換の管理に役立たせることもできます。
これを機能させるには、まずエージェントに外部データソースへのアクセスを許可し、それを他のアプリケーションの既存の API に接続する必要があります。これにより、エージェントを利用する FM は、より広い世界と対話し、その有用性を単なる言語処理タスク以外にも広げることができます。次に FM は、どのようなアクションを取るか、どの情報を使用するか、またどの順序でこれらのアクションを実行するかを把握する必要があります。これが可能になったのは、FM の優れた推論能力 (ability to reason) のおかげです。定義と指示を含むプロンプトを作成することで、そのようなやりとりの処理方法やタスクを通して推論する方法を FM に示すことができます。モデルを目的の出力に導くプロンプトを設計するプロセスは、プロンプトエンジニアリングと呼ばれます。
Agents for Amazon Bedrock の紹介
Agents for Amazon Bedrock は、ユーザーがリクエストしたタスクのプロンプトエンジニアリングとオーケストレーションを自動化します。設定が完了すると、エージェントはプロンプトを自動的に作成し、会社固有の情報を安全に追加して、ユーザーに自然言語で応答します。エージェントは、ユーザーがリクエストしたタスクを自動的に処理するために、必要なアクションを割り出すことができます。タスクを複数のステップに分割し、一連の API 呼び出しとデータ検索をオーケストレーションし、ユーザーのアクションを完了するためのメモリを維持します。
フルマネージドエージェントがあれば、インフラストラクチャのプロビジョニングや管理について心配する必要はありません。カスタムコードを記述しなくても、モニタリング、暗号化、ユーザーのアクセス許可、API 呼び出し管理がシームレスにサポートされます。開発者として、あなたは Bedrock コンソールまたは SDK を使用して API スキーマをアップロードできます。次に、エージェントは FM の力を借りてタスクをオーケストレーションし、AWS Lambda 関数を使用して API 呼び出しを実行します。
高度な推論と ReAct の入門
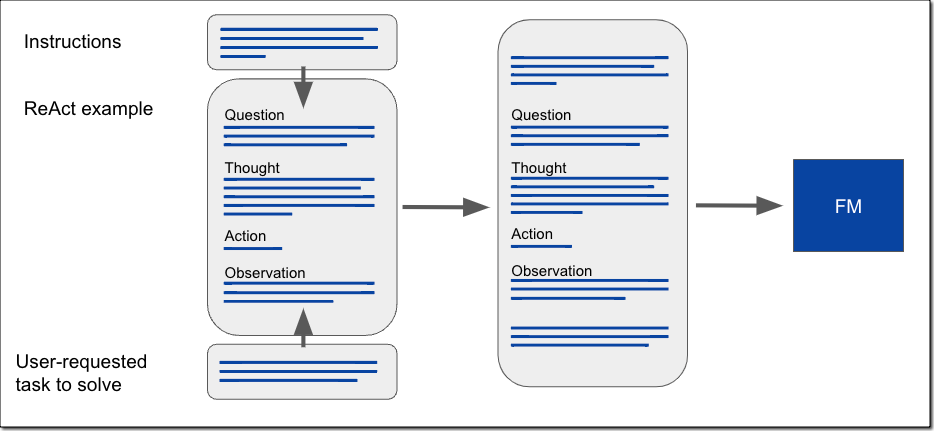
ReAct (推論と行動の相乗効果) と呼ばれる推論手法を使用すると、FM が推論し、ユーザーがリクエストしたタスクを解決する方法を見つけ出すのに役立ちます。ReAct を使用すると、タスクに対してどのように推論し、解決策を導くためのアクションをどのように決定するかを、FM に示すようにプロンプトを構築できます。 構築されたプロンプトには、質問 (Question)、思考 (Thought)、行動 (Action)、観察 (Observation) の一連の例が含まれています。
質問は、ユーザーがリクエストしたタスクまたは解決すべき課題です。思考は、課題に取り組み、取るべき行動を特定する方法を FM に示すのに役立つ推論のステップです。行動は、許可された API のセットからモデルが呼び出すことができる API です。観察はアクションを実行した結果です。FM が選択できるアクションは、プロンプトテキストの例の前に付随する一連の指示によって定義されます。以下は ReAct プロンプトを作成する方法の図です。
嬉しいことに、Bedrock がユーザーに代わって大変な仕事を行ってくれます。 その裏では、Agents for Amazon Bedrock が、入力された情報とアクションに基づいてプロンプトを作成します。
それでは、Agents for Amazon Bedrock の使用を開始する方法を紹介します。
Agents for Amazon Bedrock を作成する
あなたは保険会社の開発者で、保険代理店のオーナーが繰り返しの多いタスクを自動化するのに役立つ生成系 AI アプリケーションを提供したいと考えていると仮定します。Bedrock でエージェントを作成し、それをアプリケーションに統合します。
エージェントの使用を開始するには、Bedrock コンソールを開き、左側のナビゲーションパネルで [Agents(エージェント)] を選択してから、[Create Agent (エージェントの作成)] を選択します。
これにより、エージェントの作成ワークフローが開始されます。
- エージェント名、説明 (任意)、エージェントが追加のユーザー入力をリクエストできるかどうか、Amazon Simple Storage Service (Amazon S3) や AWS Lambda などの他の必要なサービスにエージェントがアクセスできるようにする AWS Identity and Access Management (IAM) サービスロール など、[Provide Agent details (エージェントの詳細)] を入力します。

- Bedrock から、ユースケースに合った基盤モデルを選択します。ここでは、エージェントに自然言語で指示を提供します。この指示は、エージェントに実行すべきタスクと引き受けるべきペルソナを伝えます。例えば、「You are an agent designed to help with processing insurance claims and managing pending paperwork. (あなたは保険金請求の処理と保留中の書類の管理を手助けするように設計されたエージェントです)」のように指定します。

- アクショングループを追加します。アクションとは、エージェントが会社のシステムに API 呼び出しを行うことで自動的に実行できるタスクです。アクションのセットは、アクショングループで定義されます。ここでは、グループ内のすべてのアクションの API を定義する API スキーマを指定します。また、各 API のビジネスロジックを表す Lambda 関数も指定する必要があります。例えば、ClaimManagementActionGroup というアクショングループを定義してみましょう。これは、未処理の保険金請求のリストを取得し、各請求について未処理の書類を特定し、保険契約者にリマインダーを送信することで保険金請求を管理します。アクショングループの説明にこの情報を必ず取り込んでください。FM はこの情報を使用して推論し、取るべきアクションを決定します。
 アクショングループのビジネスロジックは、InsuranceClaimsLambda という Lambda 関数に取り込まれています。この AWS Lambda 関数は、
アクショングループのビジネスロジックは、InsuranceClaimsLambda という Lambda 関数に取り込まれています。この AWS Lambda 関数は、open-claims、identify-missing-documents、send-remindersの API 呼び出しのメソッドを実装しています。以下は、OrderManagementLambda からの抜粋です。import json import time def open_claims(): ... def identify_missing_documents(parameters): ... def send_reminders(): ... def lambda_handler(event, context): responses = [] for prediction in event['actionGroups']: response_code = ... action = prediction['actionGroup'] api_path = prediction['apiPath'] if api_path == '/claims': body = open_claims() elif api_path == '/claims/{claimId}/identify-missing-documents': parameters = prediction['parameters'] body = identify_missing_documents(parameters) elif api_path == '/send-reminders': body = send_reminders() else: body = {"{}::{} is not a valid api, try another one.".format(action, api_path)} response_body = { 'application/json': { 'body': str(body) } } action_response = { 'actionGroup': prediction['actionGroup'], 'apiPath': prediction['apiPath'], 'httpMethod': prediction['httpMethod'], 'responseCode': response_code, 'responseBody': response_body } responses.append(action_response) api_response = {'response': responses} return api_responseまた、API スキーマを OpenAPI スキーマ JSON 形式で提供する必要があることにも注意してください。API スキーマファイルの
insurance_claim_schema.jsonは以下のようになっています。{"openapi": "3.0.0", "info": { "title": "Insurance Claims Automation API", "version": "1.0.0", "description": "APIs for managing insurance claims by pulling a list of open claims, identifying outstanding paperwork for each claim, and sending reminders to policy holders." }, "paths": { "/claims": { "get": { "summary": "Get a list of all open claims", "description": "Get the list of all open insurance claims.Return all the open claimIds.", "operationId": "getAllOpenClaims", "responses": { "200": { "description": "Gets the list of all open insurance claims for policy holders", "content": { "application/json": { "schema": { "type": "array", "items": { "type": "object", "properties": { "claimId": { "type": "string", "description": "Unique ID of the claim." }, "policyHolderId": { "type": "string", "description": "Unique ID of the policy holder who has filed the claim." }, "claimStatus": { "type": "string", "description": "The status of the claim.Claim can be in Open or Closed state" } } } } } } } } } }, "/claims/{claimId}/identify-missing-documents": { "get": { "summary": "Identify missing documents for a specific claim", "description": "Get the list of pending documents that need to be uploaded by policy holder before the claim can be processed.The API takes in only one claim id and returns the list of documents that are pending to be uploaded by policy holder for that claim.This API should be called for each claim id", "operationId": "identifyMissingDocuments", "parameters": [{ "name": "claimId", "in": "path", "description": "Unique ID of the open insurance claim", "required": true, "schema": { "type": "string" } }], "responses": { "200": { "description": "List of documents that are pending to be uploaded by policy holder for insurance claim", "content": { "application/json": { "schema": { "type": "object", "properties": { "pendingDocuments": { "type": "string", "description": "The list of pending documents for the claim." } } } } } } } } }, "/send-reminders": { "post": { "summary": "API to send reminder to the customer about pending documents for open claim", "description": "Send reminder to the customer about pending documents for open claim.The API takes in only one claim id and its pending documents at a time, sends the reminder and returns the tracking details for the reminder.This API should be called for each claim id you want to send reminders for.", "operationId": "sendReminders", "requestBody": { "required": true, "content": { "application/json": { "schema": { "type": "object", "properties": { "claimId": { "type": "string", "description": "Unique ID of open claims to send reminders for." }, "pendingDocuments": { "type": "string", "description": "The list of pending documents for the claim." } }, "required": [ "claimId", "pendingDocuments" ] } } } }, "responses": { "200": { "description": "Reminders sent successfully", "content": { "application/json": { "schema": { "type": "object", "properties": { "sendReminderTrackingId": { "type": "string", "description": "Unique Id to track the status of the send reminder Call" }, "sendReminderStatus": { "type": "string", "description": "Status of send reminder notifications" } } } } } }, "400": { "description": "Bad request.One or more required fields are missing or invalid." } } } } } }ユーザーがエージェントにタスクを完了するように依頼すると、Bedrock はエージェントのために設定した FM を使用してアクションのシーケンスを特定し、対応する Lambda 関数を正しい順序で呼び出してユーザーがリクエストしたタスクを解決します。
- 最後のステップでは、エージェントの設定を確認し、[Create Agent (エージェントの作成)] を選択します。

- おめでとうございます。これで Amazon Bedrock に最初のエージェントが作成されました。

Agent for Amazon Bedrock をデプロイする
アプリケーションにエージェントをデプロイするには、エイリアスを作成する必要があります。その後、Bedrock はそのエイリアスのバージョンを自動的に作成します。
- Bedrock コンソールで、エージェントを選択してから、[Deploy (デプロイ)] を選択し、[Create (作成)] を選択してエイリアスを作成します。

- エイリアス名と説明を入力して、新しいバージョンを作成するか、既存のバージョンのエージェントを使用してこのエイリアスに関連付けるかを選択します。

- これにより、エージェントのコードと設定のスナップショットが保存され、エイリアスがこのスナップショットまたはバージョンに関連付けられます。エイリアスを使用してエージェントをアプリケーションに統合できます。

それでは、保険のエージェントをテストしてみましょう。 これは Bedrock コンソールで直接行うことができます。
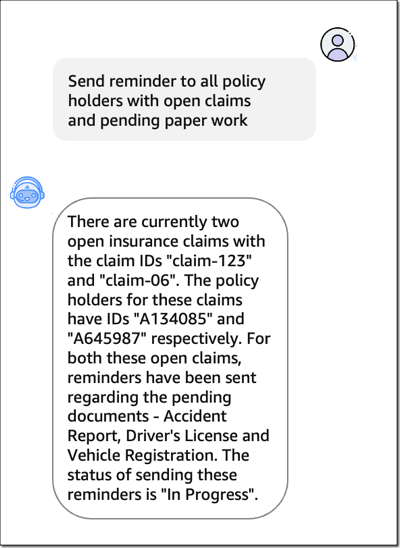
エージェントに「Send reminder to all policy holders with open claims and pending paper work. (未処理の請求があり、書類作成が保留になっているすべての保険契約者にリマインダーを送信する)」ように依頼しましょう。 FM を利用したエージェントがどのようにしてユーザーのリクエストを理解し、タスクをステップ (未解決の保険金請求の収集、請求 ID の検索、リマインダーの送信) に分解して、対応するアクションを実行できるかを確認できます。
Agents for Amazon Bedrock は、生産性の向上、カスタマーサービスエクスペリエンスの向上、DevOps タスクの自動化に役立ちます。どのようなユースケースを実装するのか楽しみです。
 生成系 AI の基礎を学ぶ
生成系 AI の基礎を学ぶ
生成系 AI の基礎と、高度なプロンプト技術やエージェントなどの FM の使用方法に興味がある場合は、AWS の同僚や業界の専門家とともに DeepLearning.AI とのコラボレーションで開発したこの新しいハンズオンコースをご覧ください。
大規模言語モデル (LLM) を使用した生成系 AI は、LLM を使用して生成系 AI アプリケーションを構築する方法を学びたいデータサイエンティストとエンジニアを対象とした 3 週間のオンデマンドコースです。Amazon Bedrock で構築を始めるのに最適な基礎コースです。LLM を使用した 生成系AIのコースに今すぐ登録しましょう。
サインアップして、Amazon Bedrock (プレビュー) についての詳細を学ぶ
Amazon Bedrock は現在プレビューで利用可能です。プレビューの一環として Agents for Amazon Bedrock へのアクセスを希望する場合は、当社までお問い合わせください。私たちは定期的に新しいお客様へのアクセスを提供しています。Amazon Bedrock の機能ページにアクセスし、サインアップして Amazon Bedrock の詳細を学んでください。
— Antje
P.S.私たちは、より良いカスタマーエクスペリエンスを提供するためにコンテンツの改善に注力しており、そのためにはお客様からのフィードバックが必要です。この短いアンケートにご回答いただき、AWS ブログに関するご感想をいただけますと幸いです。なお、このアンケートは外部企業によって実施されているため、リンク先は当社のウェブサイトではありません。AWS は、AWS プライバシー通知に記載されているとおりにお客様の情報を取り扱います。