Amazon Web Services ブログ
Amazon SageMaker でセルフサービス分析ソリューションを構築するリファレンスガイド
本記事は 2025 年 12 月 16 日 に公開された「Reference guide for building a self-service analytics solution with Amazon SageMaker」を翻訳したものです。
今日の組織は、データレイク、データウェアハウス、SaaS アプリケーション、レガシーシステムなど、複数のサイロに分散したデータという重大な課題に直面しています。データの分断により、顧客の全体像の把握、業務の最適化、リアルタイムなデータドリブンの意思決定が困難になっています。競争力を維持するため、企業はセルフサービス分析に注目しています。ビジネスユーザーと技術ユーザーの両方が、IT チームに依存せずにデータへすばやくアクセスし、探索・分析できる環境です。
しかし、セルフサービス分析の実装には大きな課題が伴います。多様なソースからのデータ統合によるシームレスなアクセスの実現、データの発見性を高めるビジネスカタログと技術カタログの作成、信頼性を確保するためのデータリネージと品質管理、セキュリティとコンプライアンスのためのきめ細かなアクセス制御、データエンジニア・アナリスト・AI/ML チーム向けのロール別ツールの提供、そしてポリシーや規制要件を適用するガバナンスフレームワークの確立が必要です。
本記事では、Amazon SageMaker Catalog を使用して、Amazon S3、Amazon Redshift、Snowflake など複数のソースからデータを公開する方法を紹介します。Amazon SageMaker Catalog により、データガバナンスとメタデータ管理を確保しながらセルフサービスアクセスを実現できます。メタデータを一元管理することで、データの発見性、リネージ追跡、コンプライアンスが向上し、アナリスト、データエンジニア、データサイエンティストが AI ドリブンのインサイトを効率的かつ安全に導き出せるようになります。サンプルの小売ユースケースを使ってソリューションをデモし、実際のシナリオへの適用方法をわかりやすく説明します。
Amazon SageMaker: セルフサービス分析の実現
Amazon SageMaker は AWS の AI/ML と分析機能を統合し、統一されたデータアクセスによる分析と AI の統合エクスペリエンスを提供します。チームは以下が可能です。
- Lakehouse アーキテクチャを通じて、Amazon S3、Amazon Redshift、その他のサードパーティソースに保存されたデータを検索・アクセスする。
- データ分析、処理、モデルトレーニング、生成 AI アプリ開発など、使い慣れた AWS サービスで AI と分析のワークフローを完結させる。
- 高度な生成 AI アシスタント Amazon Q Developer でソフトウェア開発を加速する。
- Amazon SageMaker Catalog による組み込みのガバナンス、きめ細かなアクセス制御、安全なアーティファクト共有でエンタープライズグレードのセキュリティを確保する。
- 共有プロジェクトでコラボレーションし、コンプライアンスとガバナンスを維持しながらチームが効率的に連携する。
小売ユースケースの概要
以下の例では、小売組織が複数の事業部門にまたがって運営されており、各部門が異なるプラットフォームにデータを保存しているため、データアクセス、一貫性、ガバナンスに課題が生じています。
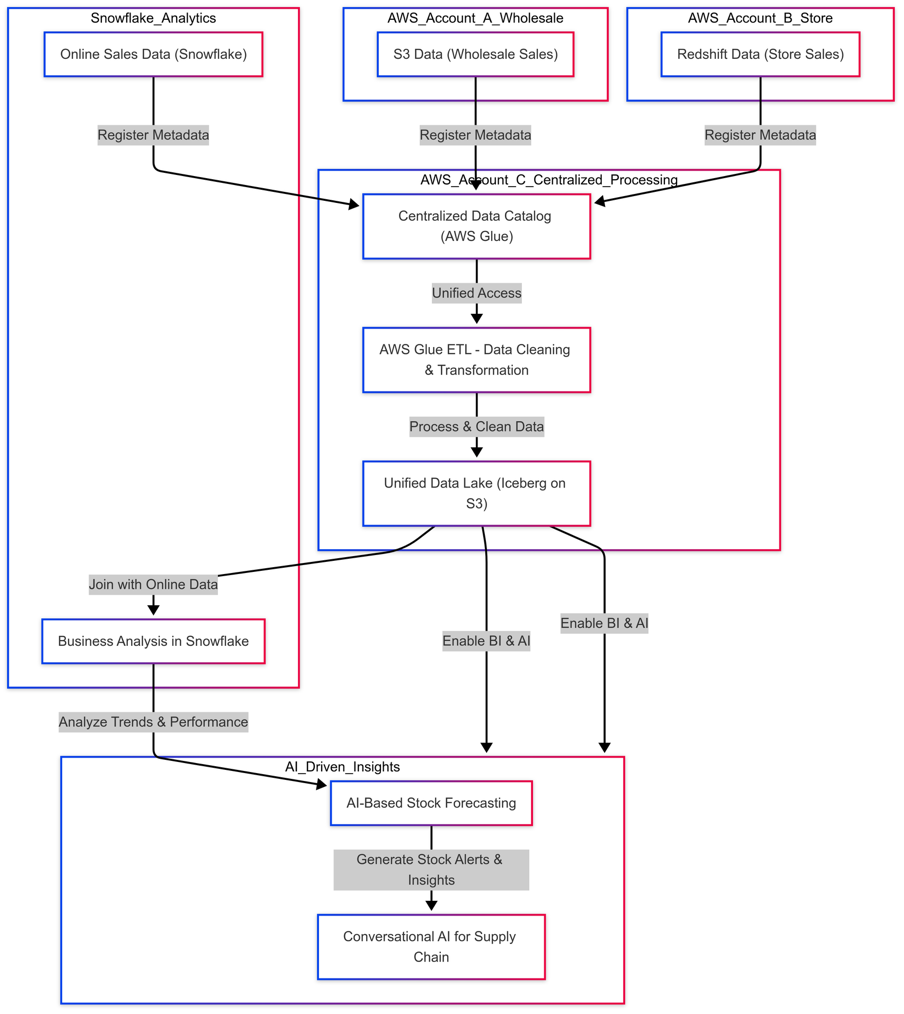
図 1: 複数システム間のデータフローを示す小売ユースケースの全体アーキテクチャ
小売組織は事業部門間でデータの分断に直面しています。
- 卸売事業部門は Amazon S3 にデータを保存しています。
- 店舗販売事業部門は Amazon Redshift でトランザクションデータを管理しています。
- オンライン販売データは Snowflake に保存されています。
データソースが分散しているため、データサイロ、スキーマの不整合、重複、欠損値が発生し、アナリストや AI ソリューションが有意義なインサイトを導き出しにくくなっています。
データモデル
以下の ER (Entity-Relationship) 図は、卸売、小売、オンライン販売データにおけるデータセット構造とエンティティ間の関係を表しています。
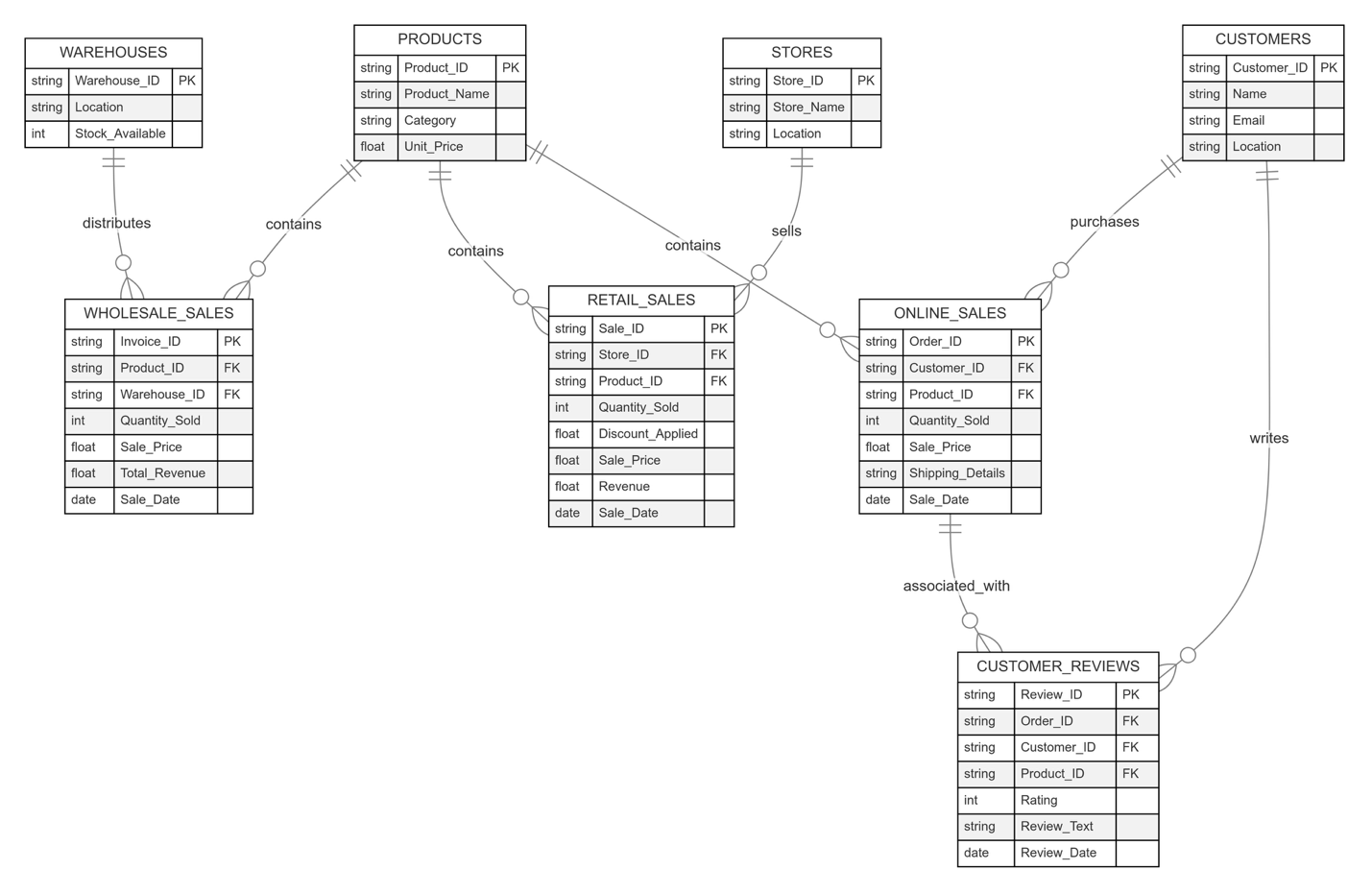
図 2: データエンティティ間の関係を示す ER 図
データモデルの主要エンティティ
サンプルデータセットは、商品、販売チャネル、顧客、拠点を表すエンティティが相互に接続されたマルチチャネル小売ビジネスをモデル化しています。
- PRODUCTS は WHOLESALE_SALES、RETAIL_SALES、ONLINE_SALES にリンクする中心的なエンティティで、異なる販売チャネルにおける商品取引を表します。
- WHOLESALE_SALES は、WAREHOUSES が小売業者に商品を配送する大量取引を記録します。各販売は PRODUCT と WAREHOUSE に関連付けられています。
- RETAIL_SALES は実店舗 (STORES) での個別購入を記録します。各取引には PRODUCT と STORE が関連付けられ、販売数量、適用割引、売上などの詳細が含まれます。
- ONLINE_SALES は顧客がオンラインで商品を購入する EC 取引を追跡します。各レコードは CUSTOMER と PRODUCT にリンクし、数量、価格、配送情報などの詳細が含まれます。
- CUSTOMERS はシステム内の購入者を表し、ONLINE_SALES (購入) と CUSTOMER_REVIEWS (商品レビュー) にリンクしています。
- CUSTOMER_REVIEWS は、顧客がオンラインで購入した商品に対するフィードバックを保存します。各レビューは ONLINE_SALES の注文、CUSTOMER、PRODUCT にリンクしています。
- STORES は商品が販売される実店舗を表します。RETAIL_SALES に関連付けられ、店舗での商品購入を示します。
- WAREHOUSES は商品の在庫管理と WHOLESALE_SALES 取引を通じた小売業者への大量販売を担当します。在庫レベルを管理し、小売業者への一括販売を促進します。
システム間のデータ分散
実際のエンタープライズシナリオをシミュレートするため、データは以下のように複数のシステムと AWS アカウントに分散されています。
| アカウント | 保存場所 | テーブル |
| 卸売 | Amazon S3 | WHOLESALE_SALES, PRODUCT, WAREHOUSE |
| 店舗 | Amazon Redshift | RETAIL_SALES, STORE, PRODUCT |
| オンライン販売 | Snowflake | ONLINE_SALES, CUSTOMER, CUSTOMER_REVIEWS, PRODUCT |
前提条件
この実装では以下を前提としています。
- 3 つの AWS アカウント: 卸売アカウント、店舗アカウント、集中処理アカウント。
- オンライン販売用の Snowflake アカウント。
- データモデルセクションで指定した通り、このサンプルスクリプトを使用して各アカウントに分散データを作成。
- クロスアカウントリソースのセットアップに必要な権限を持つ AWS Identity and Access Management (IAM) ロールを作成。
SageMaker Catalog の構築
Amazon SageMaker Unified Studio を使用して複数のソースから SageMaker Catalog を作成する手順を説明します。
ステップ 1: SageMaker Unified Studio 環境のセットアップ
データカタログの構築を始める前に、SageMaker Unified Studio の用語を確認します。
ドメイン: Amazon SageMaker Unified Studio のドメインは、すべてのデータアセット、ユーザー、リソースを管理する論理的な境界で、データを効率的に整理・管理できます。
ドメインユニット: ドメインユニットはドメイン内のサブコンポーネントで、関連するプロジェクトとリソースをまとめて整理し、データ管理を階層的に構造化できます。
ブループリント: Amazon SageMaker Unified Studio のブループリントは、プロビジョニングされるリソース、適用されるツールやパラメータなど、プロジェクトの標準化された設定を定義するテンプレートです。
プロジェクトプロファイル: プロジェクトプロファイルは、プロジェクトの作成に使用されるブループリントの集合です。プロジェクトプロファイルでは、プロジェクト作成時に特定のブループリントを有効にするか、プロジェクトユーザーがオンデマンドで有効にできるようにするかを定義できます。
プロジェクト: Amazon SageMaker Unified Studio のプロジェクトは、ドメイン内の境界で、ユーザーがビジネスユースケースに取り組むために他のメンバーとコラボレーションできます。プロジェクト内でデータやリソースを作成・共有できます。
では、Amazon SageMaker Unified Studio 環境をセットアップしましょう。
SageMaker ドメインの作成
- 集中処理アカウントで Amazon SageMaker マネジメントコンソールを開き、上部のナビゲーションバーのリージョンセレクターで適切な AWS リージョンを選択します。
- Create a Unified Studio domain を選択します。
- Amazon SageMaker Unified Studio ドメインの作成 – クイックセットアップの説明に従い、Quick setup を選択します。
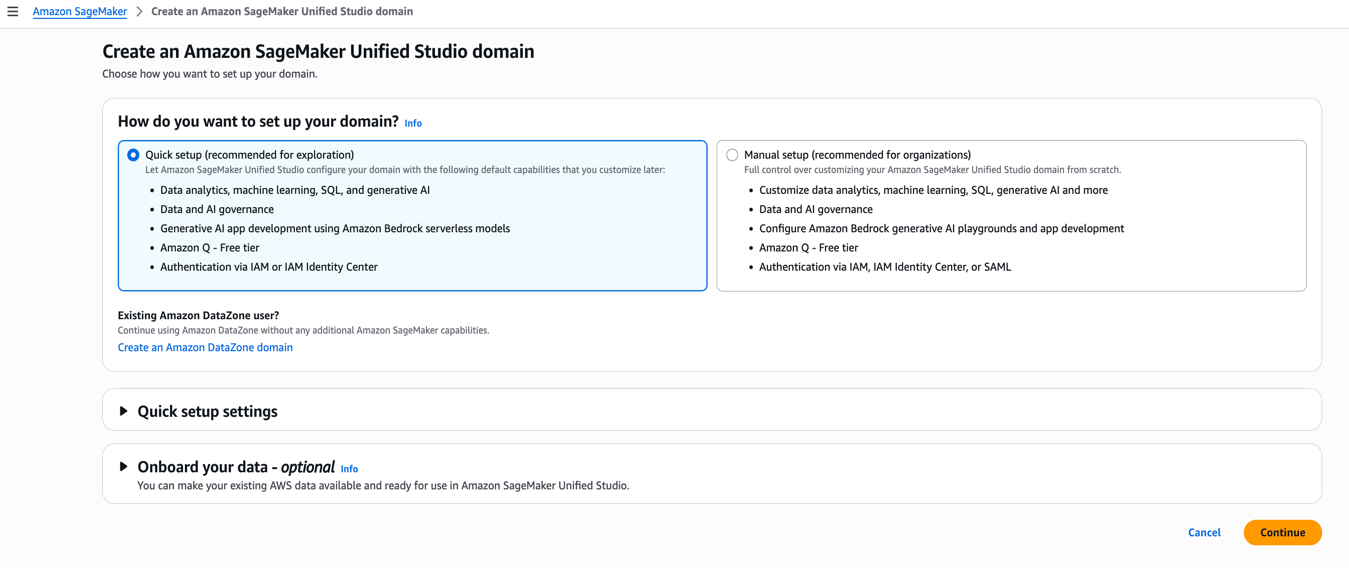
- Create IAM Identity Center User で、メールアドレスから SSO ユーザーを検索します。Amazon IAM Identity Center インスタンスがない場合は、メールアドレスの後に名前を入力するプロンプトが表示されます。新しいローカル IAM Identity Center インスタンスが作成されます。
- Create domain を選択します。
SageMaker Unified Studio へのログイン
SageMaker Unified Studio ドメインを作成したら、以下の手順で Amazon SageMaker Unified Studio にアクセスします。
- SageMaker プラットフォームコンソールで、ドメインの詳細ページを開きます。
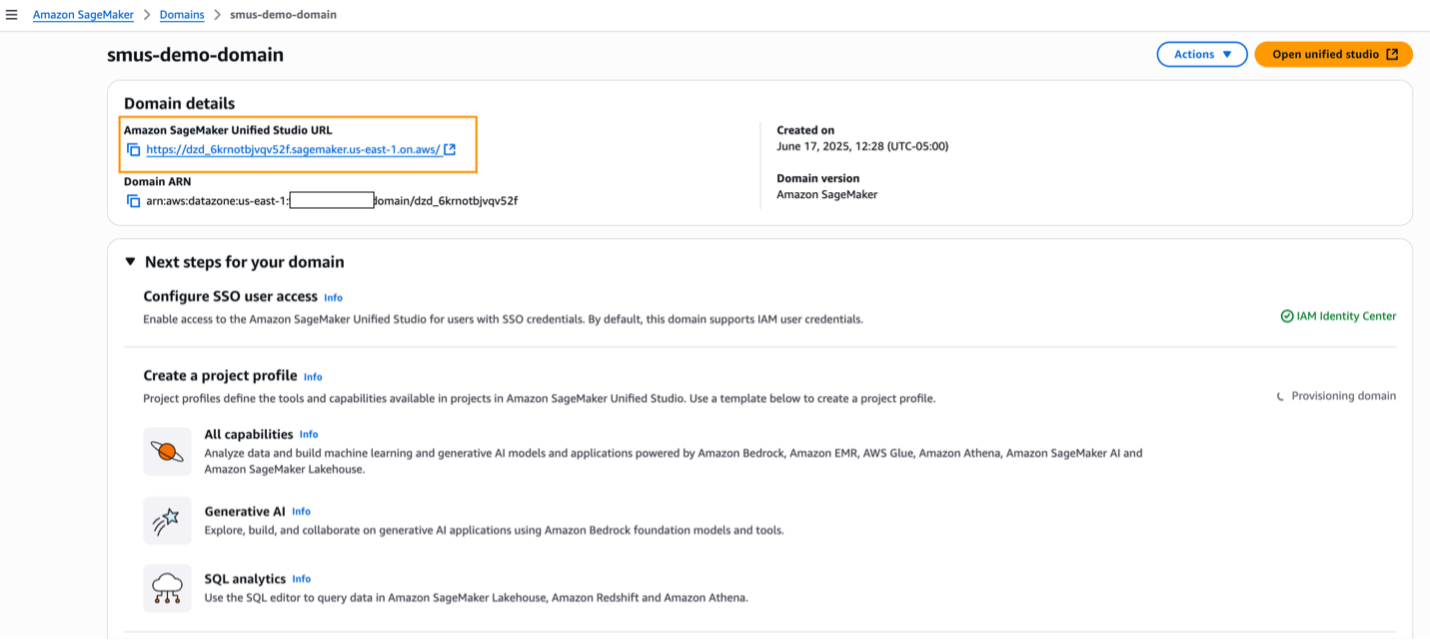
- Amazon SageMaker Unified Studio URL のリンクを選択します。
- SSO 認証情報でログインします。
これで SageMaker Unified Studio にサインインできました。
プロジェクトの作成
次のステップはプロジェクトの作成です。以下の手順を実行します。
- SageMaker Unified Studio で、上部メニューの Select a project を選択し、Create project を選択します。
- Project name に名前 (例: AnyCompanyDataPlatform) を入力します。
- Project profile で All capabilities を選択します。
- Continue を選択します。
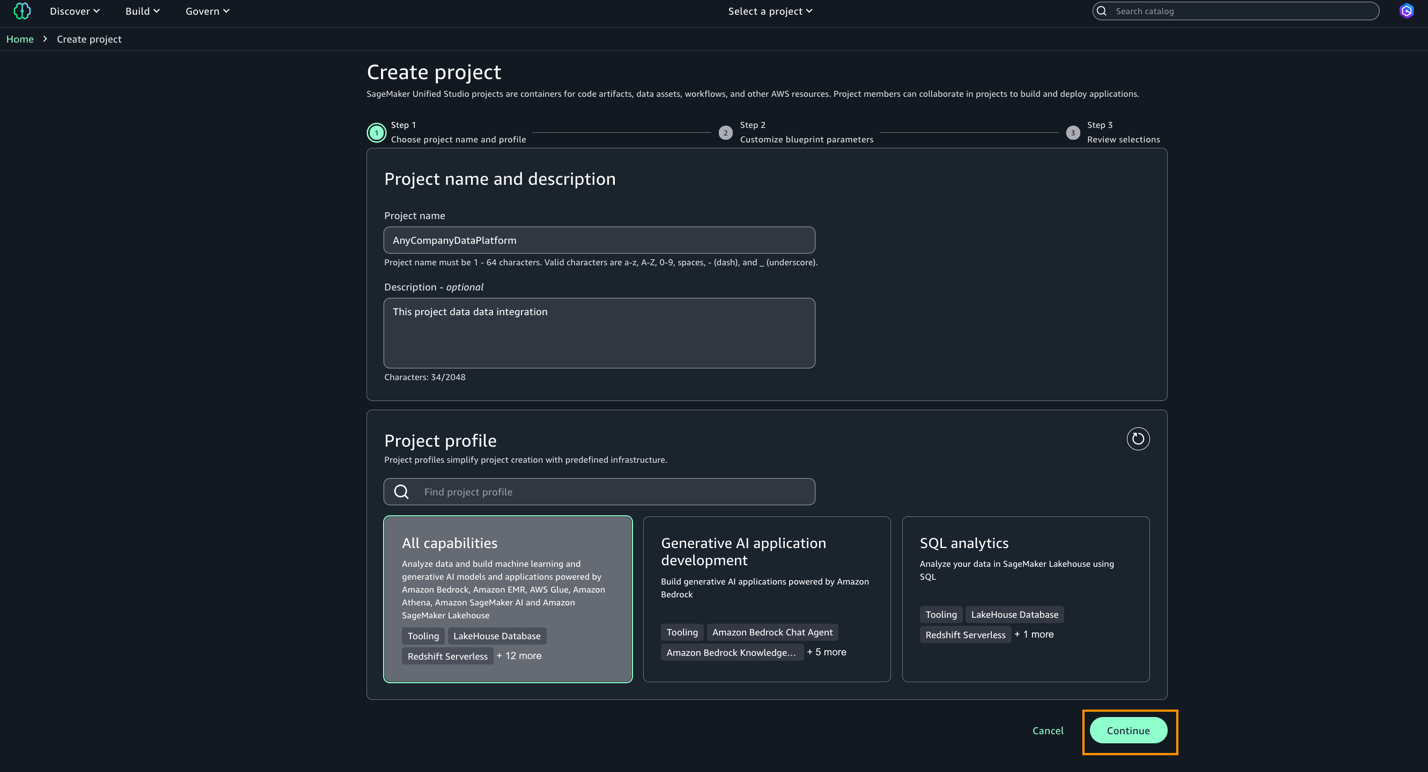
- 入力内容を確認し、Create project を選択します。作成したプロジェクトがデータ統合のコラボレーションワークスペースになります。
プロジェクトが作成されるまで待ちます。プロジェクトの作成には約 5 分かかります。完了すると、SageMaker Unified Studio コンソールがプロジェクトのホームページに遷移します。
ステップ 2: データソースへの接続
次に、さまざまなデータソースに接続してデータカタログに取り込みます。
既存の AWS Glue Data Catalog のインポート (卸売販売データ)
まず、卸売アカウントの Amazon S3 にある卸売販売データを Amazon SageMaker Unified Studio にインポートします。
クロスアカウントアクセスの設定
- 集中処理アカウントにログインし、AWSGlueServiceRole と卸売アカウントへのクロスアカウント S3 アクセスポリシーを持つ Glue Crawler ロール (glue-cross-s3-access) を作成します。クロスアカウント S3 アクセスポリシーの例:
- 卸売アカウントにログインし、集中処理アカウントで作成した glue-cross-s3-access ロールに S3 データファイルへのアクセスを許可する S3 バケットポリシーを作成します。
- 集中処理アカウントにログインし、AWS Glue から anycompanydatacatlog という名前のデータベースを作成します。
- AWS Lake Formation で anycompanydatacatalog データベースに対する glue-cross-s3-access ロールの権限を付与します。
- glue-cross-s3-access ロールを使用して Glue Crawler を実行し、卸売アカウントの S3 バケットをスキャンします。詳細は、Glue Crawler を使用した S3 データのカタログ化のチュートリアルを参照してください。
anycompanydatacatlogデータベースと対応するテーブルを確認します。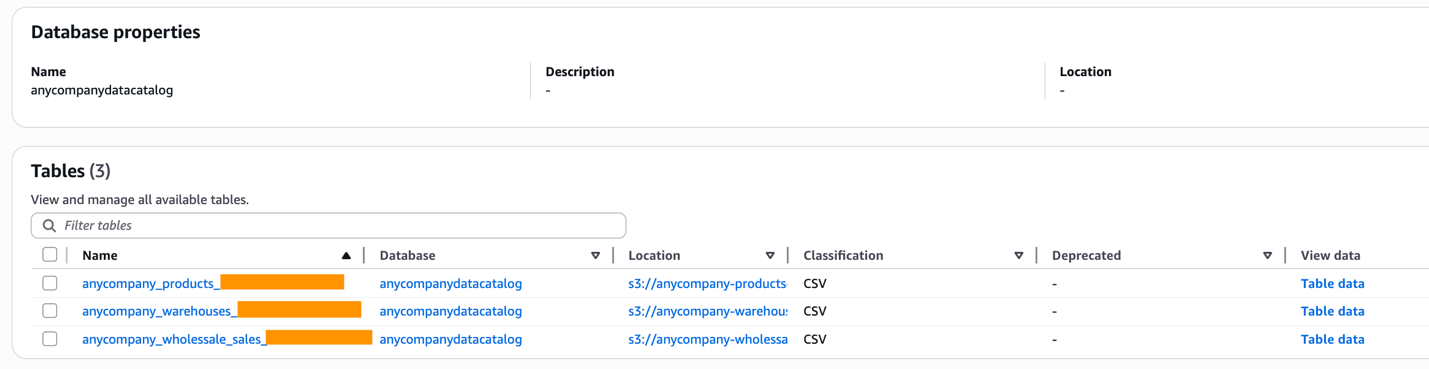
Glue Data Catalog アセットの設定
- Bring Your Own Glue Data Catalog Assets リポジトリからスクリプトをダウンロードします。
- プロジェクト概要セクションから Amazon SageMaker Unified Studio プロジェクトロール ARN をコピーします。
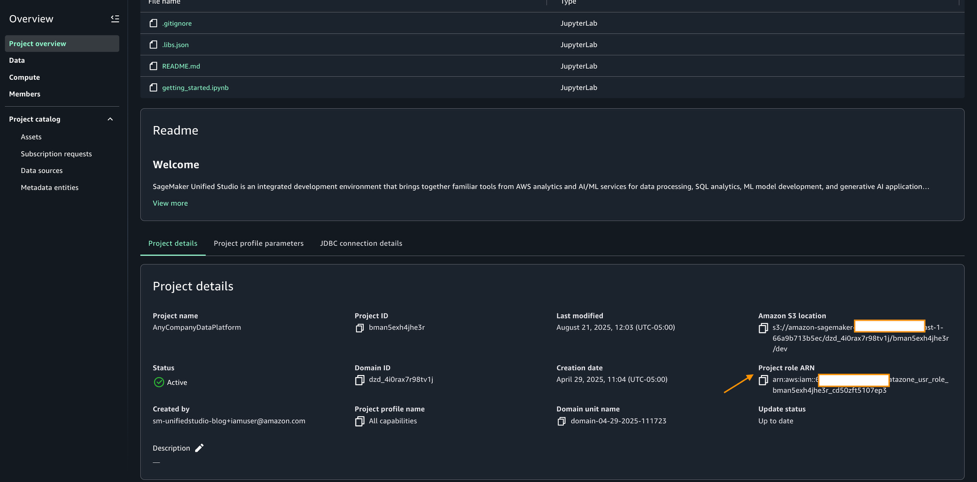
- 同じ Amazon SageMaker Unified Studio プロジェクトロールを Lake Formation のデータレイク管理者として追加します。
Amazon SageMaker Unified Studio へのアセットのインポート
- 集中処理アカウントのコンソールで AWS CloudShell を開きます。
- 先ほどダウンロードした bring_your_own_gdc_assets.py ファイルを AWS CloudShell にアップロードします。
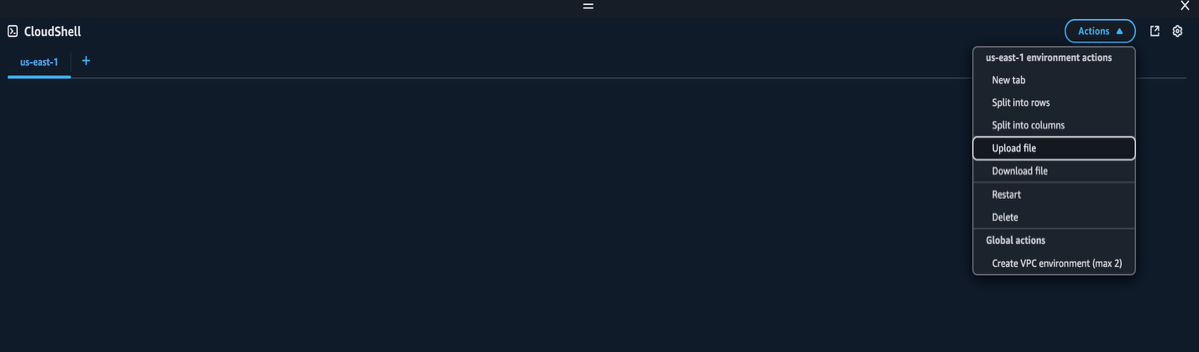
- 以下のパラメータを指定して AWS CloudShell でインポートスクリプトを実行します。
- project-role-arn: SageMaker Unified Studio のプロジェクトロール ARN を入力します。
- database-name: Glue Catalog のデータベース名 (例:
anycompanydatacatalog) を入力します。 - region: SageMaker Unified Studio のリージョン (例:
us-east-1) を入力します。
インポートした卸売販売データの確認
- 集中処理アカウントで SageMaker Unified Studio コンソールに移動し、プロジェクトを選択します。
- ナビゲーションペインで Data を選択します。
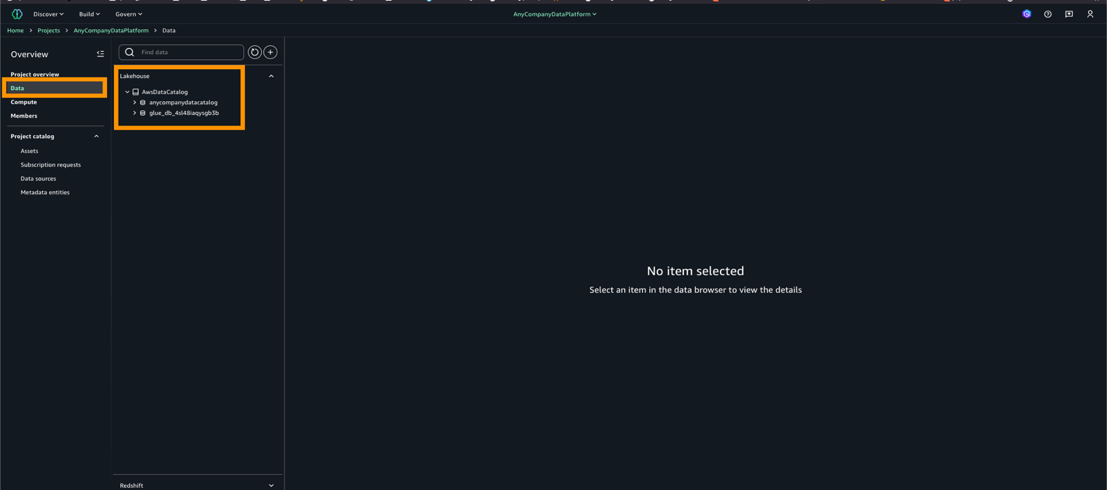
anycompanydatacatalogの下に wholesale_db データベースとそのテーブル (WHOLESALE_SALES, PRODUCT, WAREHOUSE) が表示されていることを確認します。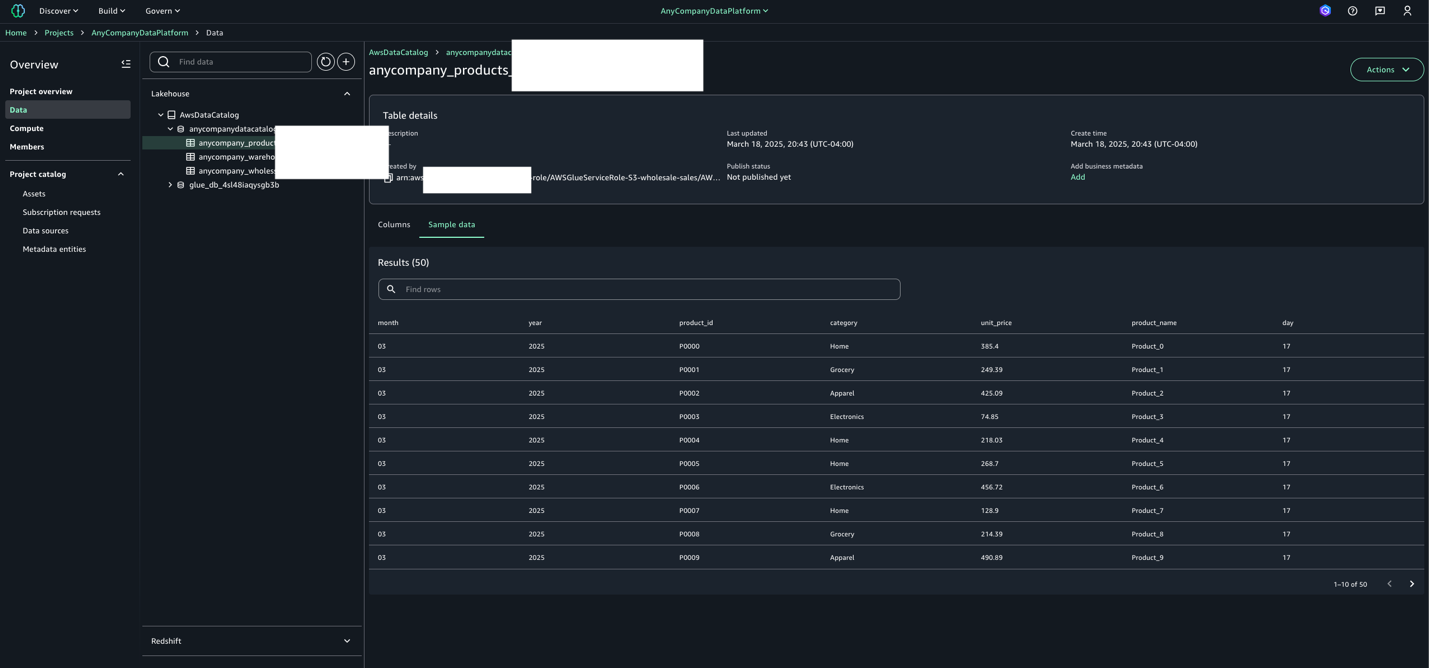
Amazon Redshift への接続 (店舗販売データ)
店舗アカウントの Amazon Redshift にある店舗販売データを Amazon SageMaker Unified Studio に取り込みます。
クロスアカウントアクセスの設定
- 店舗アカウントにログインし、Amazon SageMaker Unified Studio をホストする集中処理アカウントとの間に VPC ピアリング接続を作成し、ドキュメントに従ってルートテーブルを設定します。
- Redshift VPC セキュリティグループのルールを更新し、集中処理アカウントの IPv4 CIDR 範囲を含めます。ネットワーク接続が有効になり、集中処理アカウントから店舗アカウントのリソースへのリクエストが許可されます。
Amazon Redshift のフェデレーテッド接続の作成
- 集中処理アカウントで SageMaker Unified Studio コンソールに移動し、プロジェクトを選択します。
- ナビゲーションペインで Data を選択します。
- データエクスプローラーでプラス記号を選択してデータソースを追加します。
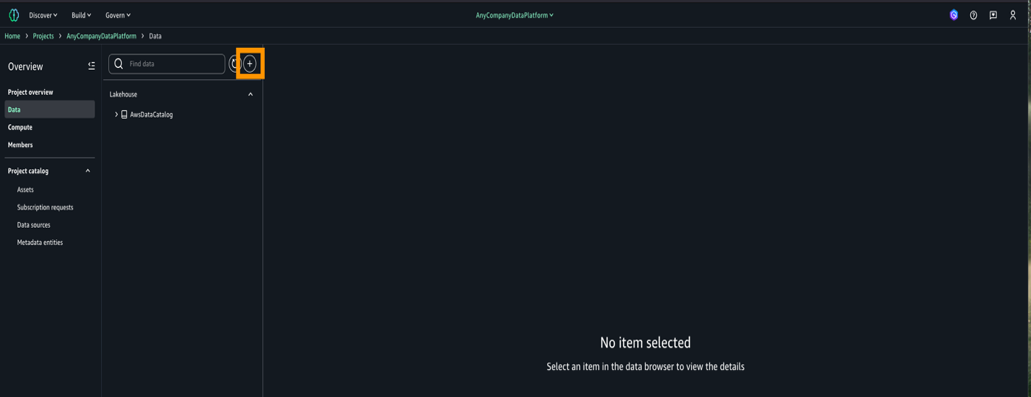
- データソースの追加で Add connection を選択し、Amazon Redshift を選択します。
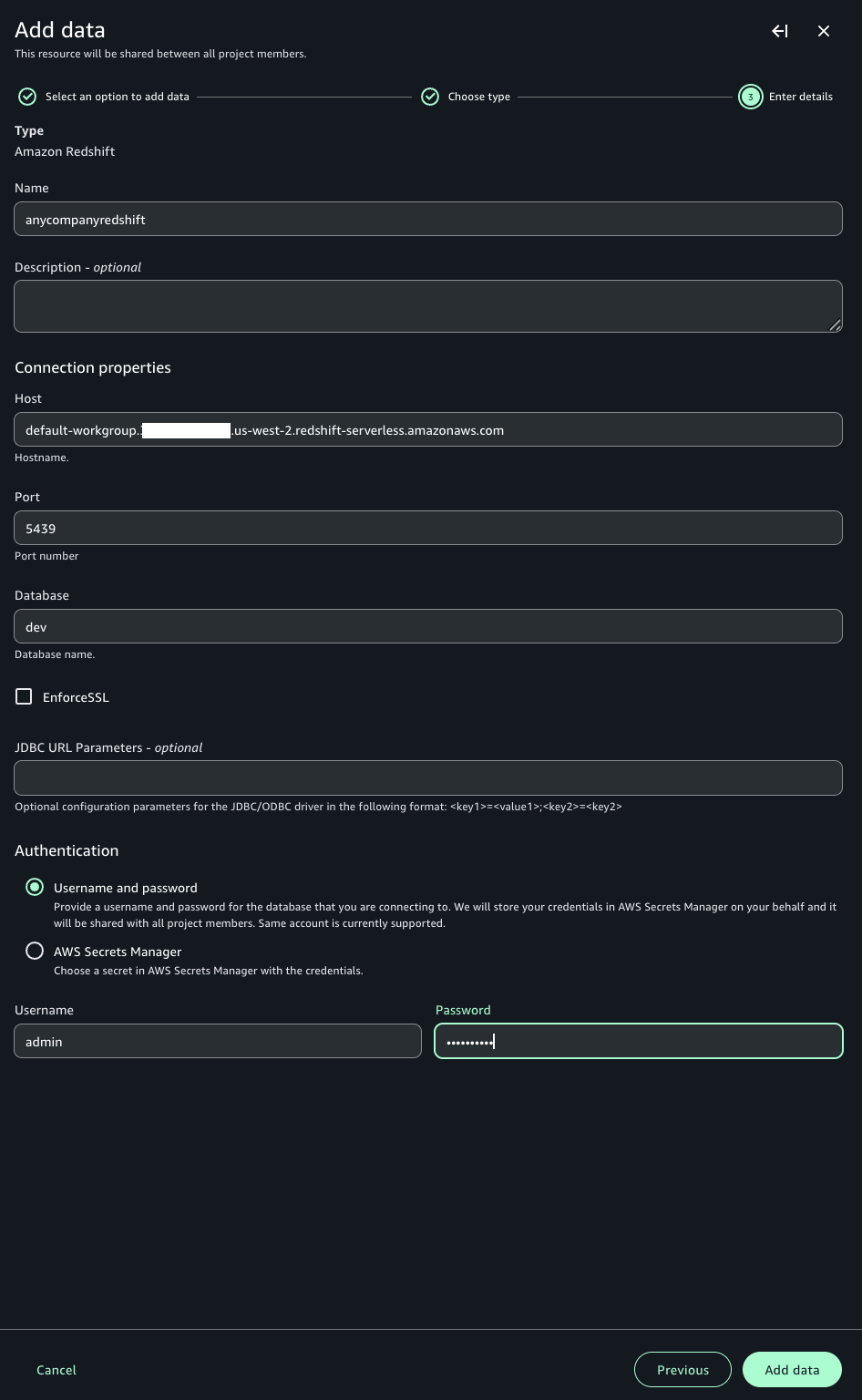
- 接続の詳細に以下のパラメータを入力し、Add data を選択します。
- Name: 接続名 (例:
anycompanyredshift) を入力します。 - Host: Amazon Redshift クラスターのエンドポイントを入力します。
- Port: ポート番号を入力します (Amazon Redshift のデフォルトポートは 5439)。
- Database: データベース名を入力します。
- Authentication: データベースのユーザー名とパスワード、または AWS Secrets Manager を選択します。AWS Secrets Manager の使用を推奨します。
- Name: 接続名 (例:
接続が確立されると、以下のスクリーンショットのようにフェデレーテッドカタログが作成されます。フェデレーテッドカタログは Amazon Redshift への AWS Glue 接続を使用します。データベース、テーブル、ビューは自動的にカタログセクションにカタログ化され、Lake Formation に登録されます。
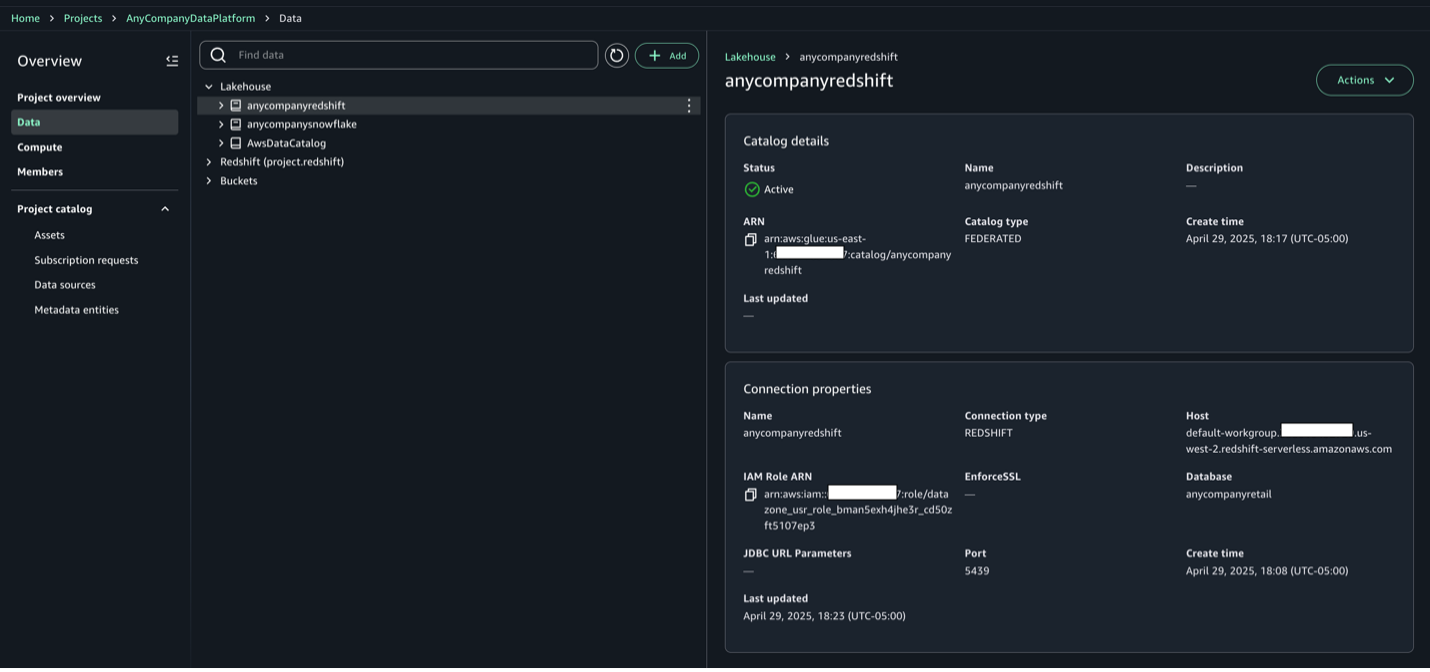
店舗販売データの確認
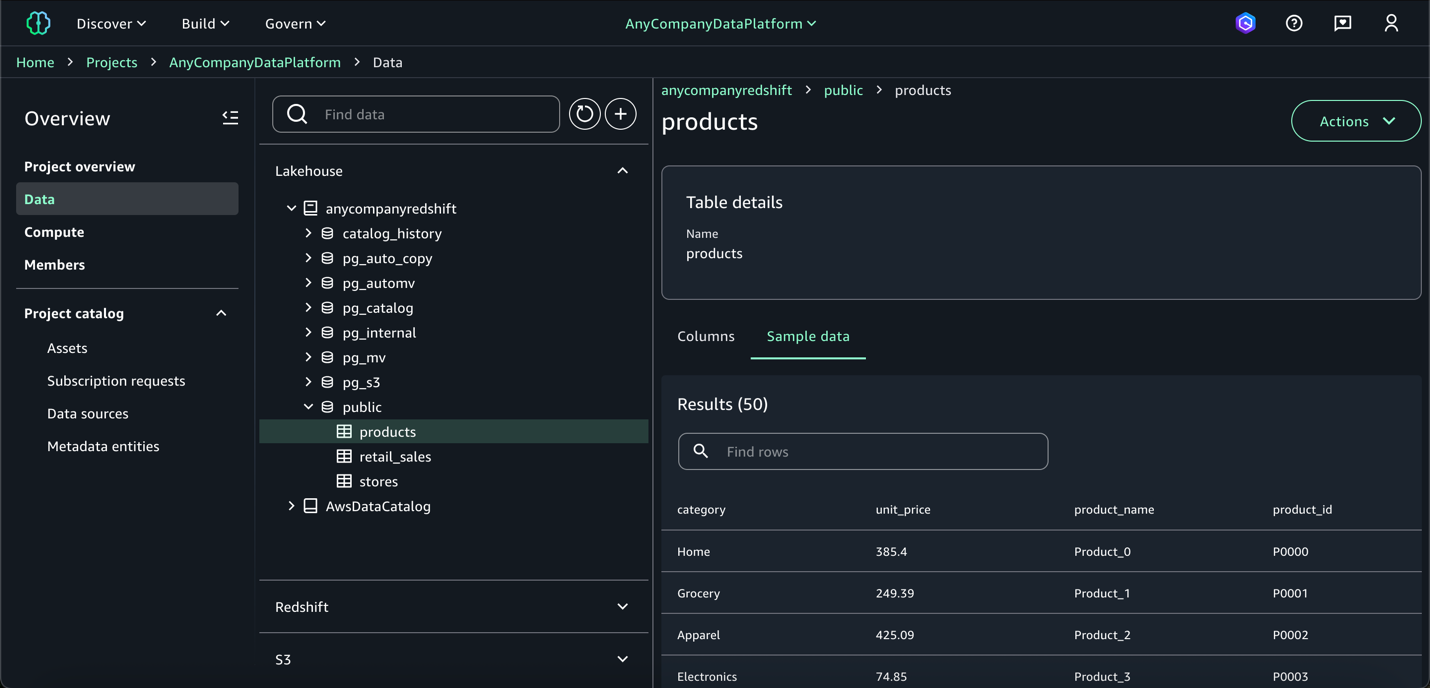
- SageMaker Unified Studio の Catalog セクションにアクセスします。
- 小売販売の public データベースとそのテーブル (RETAIL_SALES, STORE, PRODUCT) が表示されていることを確認します。
Snowflake への接続 (オンライン販売データ)
Snowflake のオンライン販売データを Amazon SageMaker Unified Studio に取り込みます。
Snowflake のフェデレーテッド接続の作成
- 集中処理アカウントで SageMaker Unified Studio コンソールに移動し、プロジェクトを選択します。
- ナビゲーションペインで Data を選択します。
- データエクスプローラーでプラス記号 (+) を選択してデータソースを追加します。
- Add a data source で Add connection を選択し、Snowflake を選択します。
- 接続の詳細に以下のパラメータを入力し、Add data を選択します。
- Name: 接続名 (例:
anycompanysnowflake) を入力します。 - Host: Snowflake クラスターのエンドポイントを入力します。
- Port: ポート番号を入力します (Snowflake のデフォルトポートは 443)。
- Database: データベース名 (例:
anycompanyonlinesales) を入力します。 - Warehouse: ウェアハウス名 (例: COMPUTE_WH) を入力します。
- Authentication: データベースのユーザー名とパスワード、または Secrets Manager を選択します。
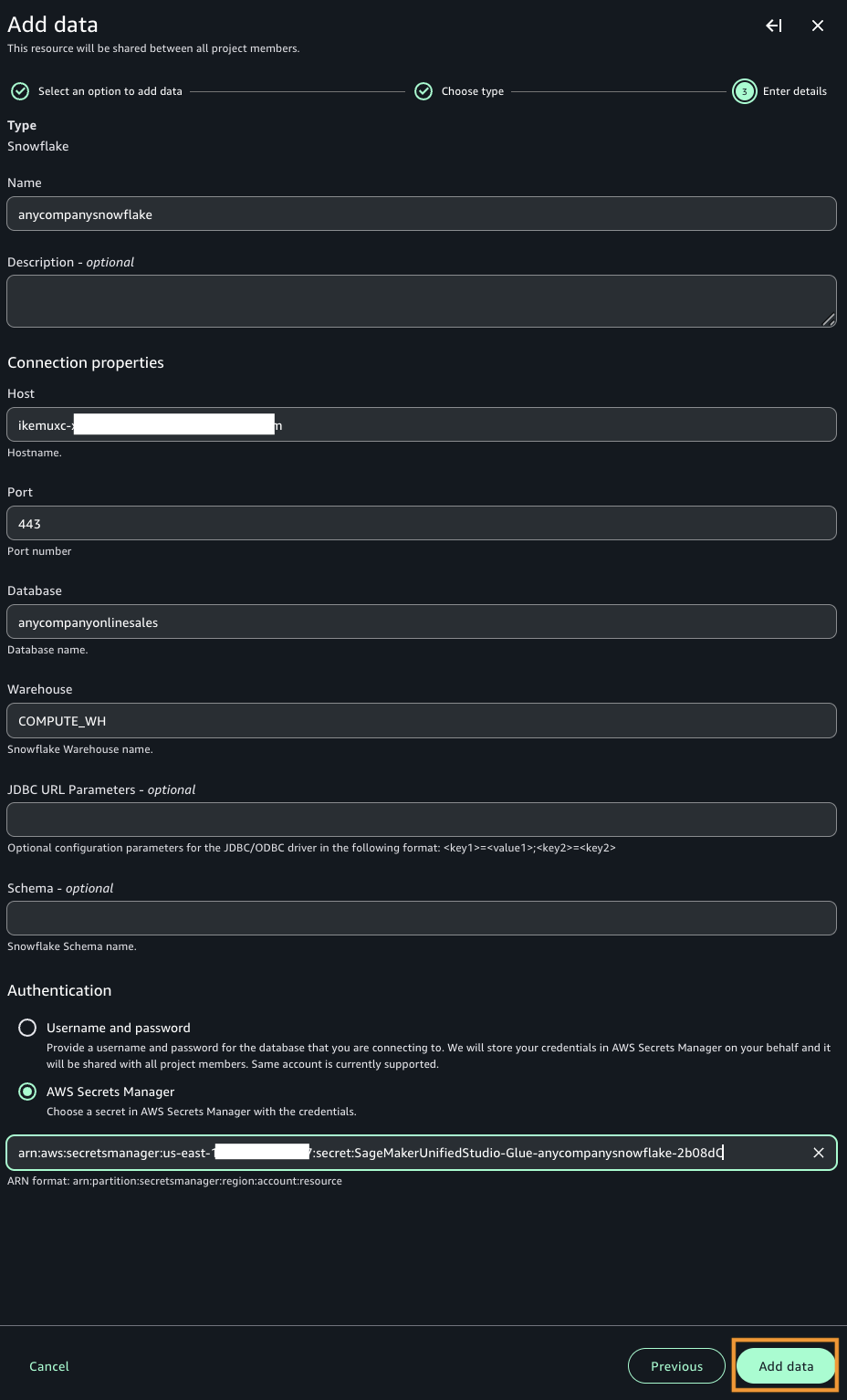
- Name: 接続名 (例:
接続が確立されると、Snowflake 用のフェデレーテッドカタログが作成されます。フェデレーテッドカタログは Snowflake への AWS Glue 接続を使用します。データベース、テーブル、ビューは自動的に Data Catalog にカタログ化され、Lake Formation に登録されます。
オンライン販売データの確認
- SageMaker Unified Studio の Catalog セクションに移動します。
- オンライン販売の public データベースとそのテーブル (CUSTOMER_REVIEWS, CUSTOMER, ONLINE_SALES, PRODUCT) が表示されていることを確認します。
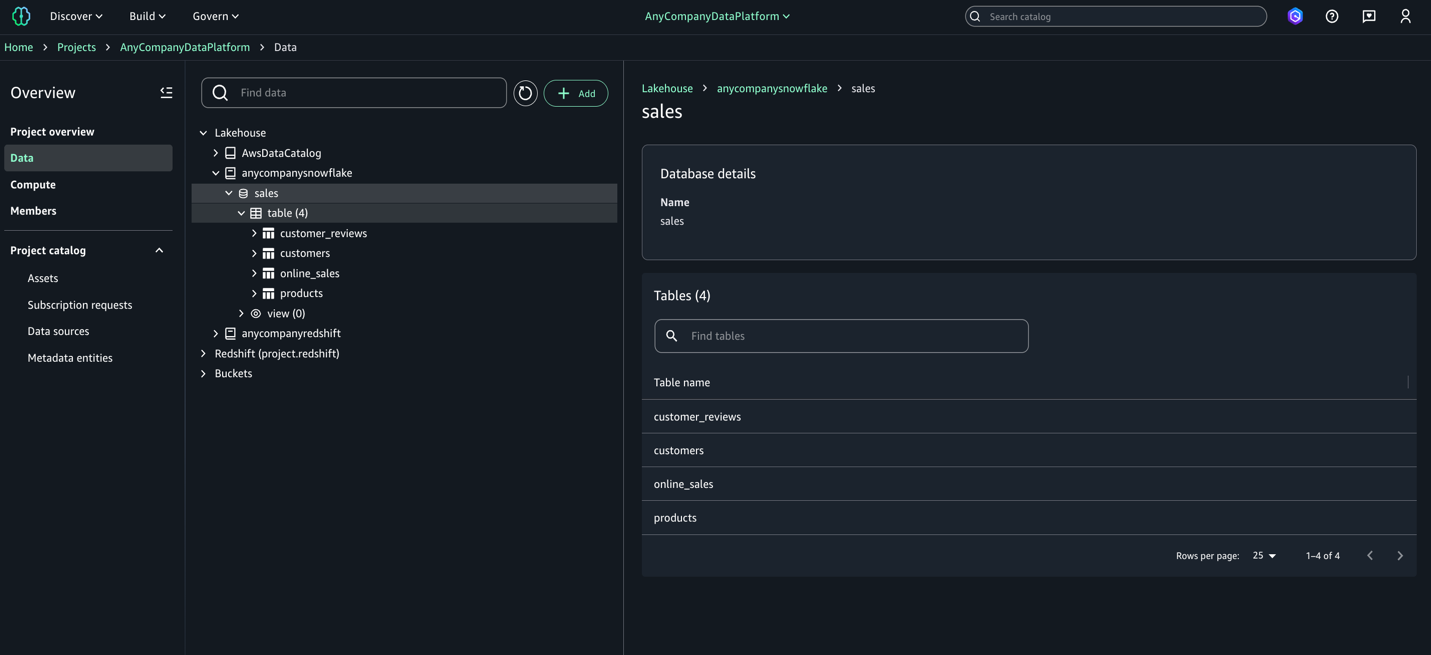
ステップ 3: データの統合分析
すべてのデータソースからのデータがカタログ化されたら、Amazon SageMaker Unified Studio から Amazon Athena クエリエンジンを使用して分析できます。
- 集中処理アカウントで SageMaker Unified Studio コンソールに移動し、プロジェクトを選択します。
- Build セクションから Query Editor を選択します。
- 接続として Athena (Lakehouse) を選択します。
- 複数のデータソースカタログを結合するクエリを実行してデータを分析します。
例: 各商品の卸売、小売、オンライン販売の合計売上はいくらか?
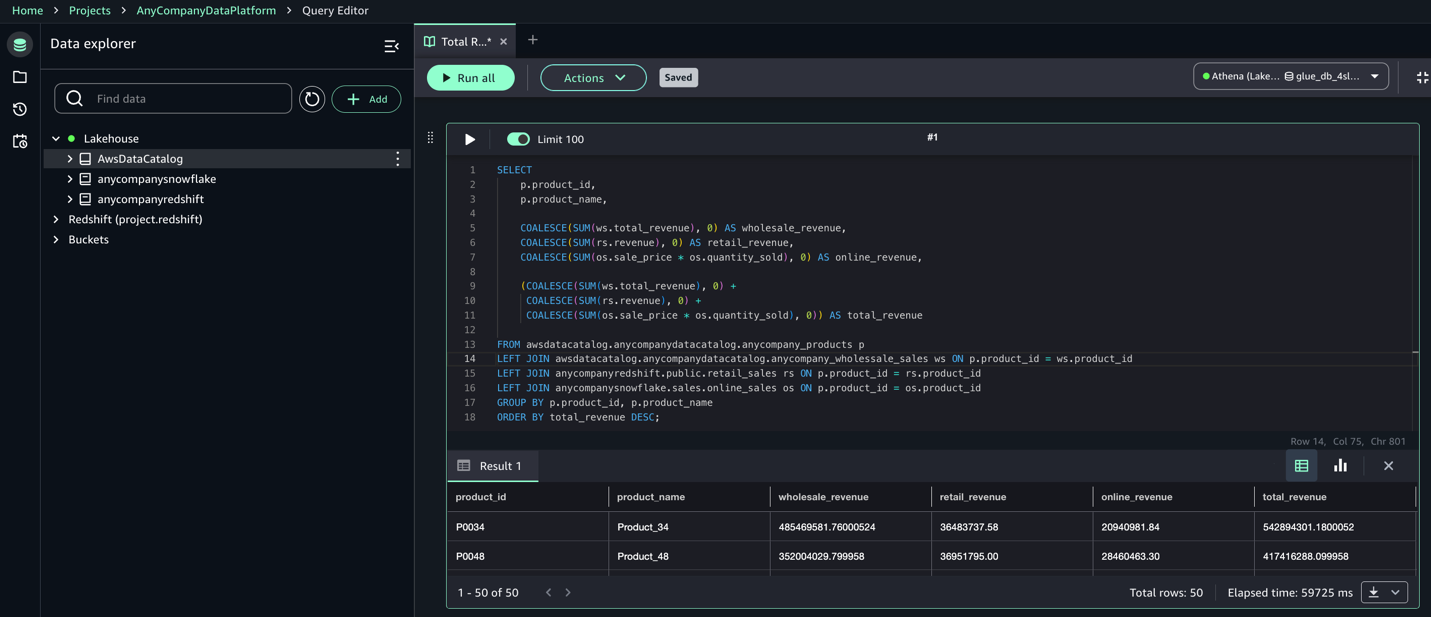
同様に、カタログ間でクエリを実行することで、さまざまな分析の観点から有益なビジネスインサイトを得られます。
ステップ 4: ビジネス用語集の作成
ビジネス用語集は、組織全体で用語を標準化し、データの発見性を高めます。ここでは、卸売データの PRODUCT に対するビジネス用語集を作成します。
- ナビゲーションペインで Data を選択し、卸売データの PRODUCT テーブルの Publish to Catalog を選択します。
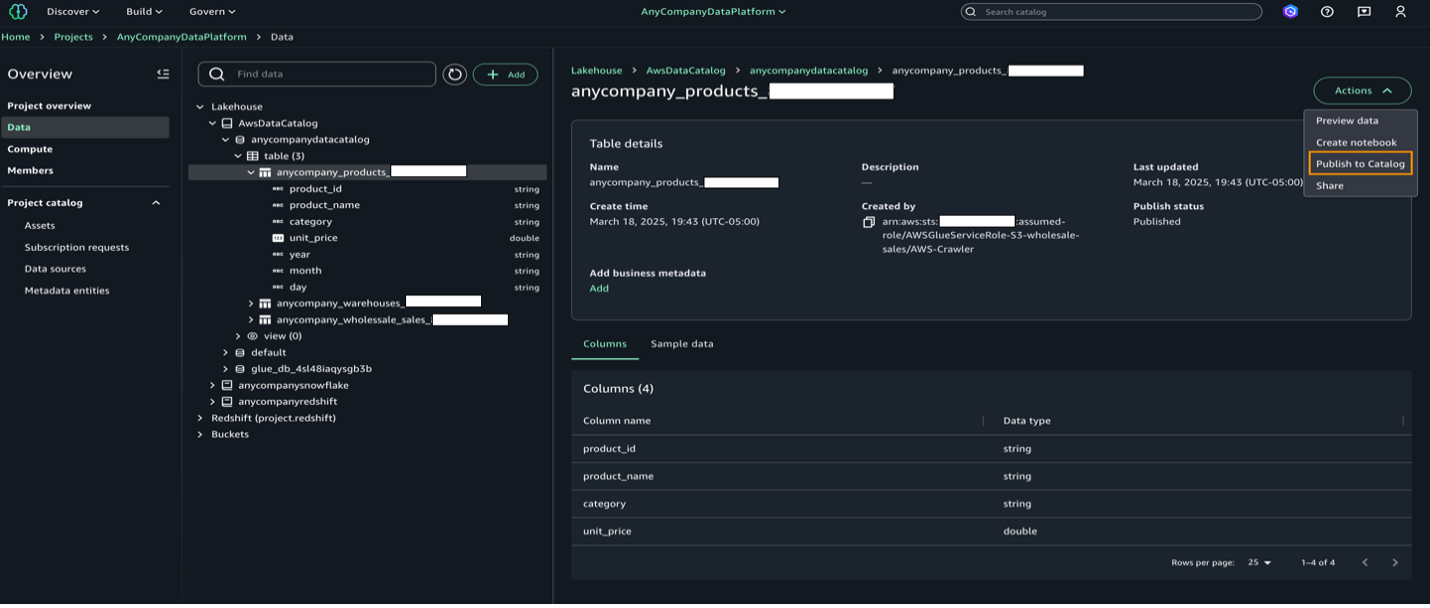
- Assets を選択し、products テーブルを選択します。
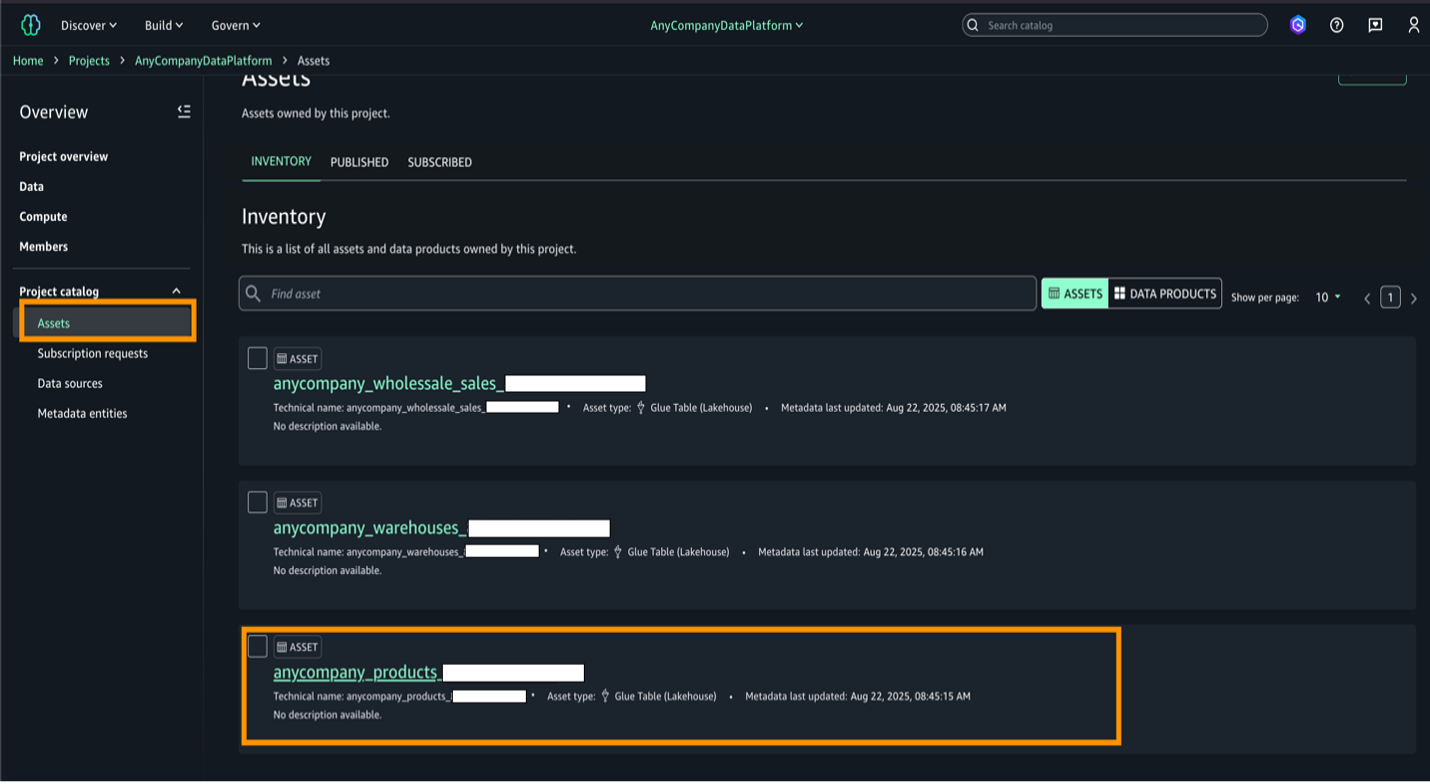
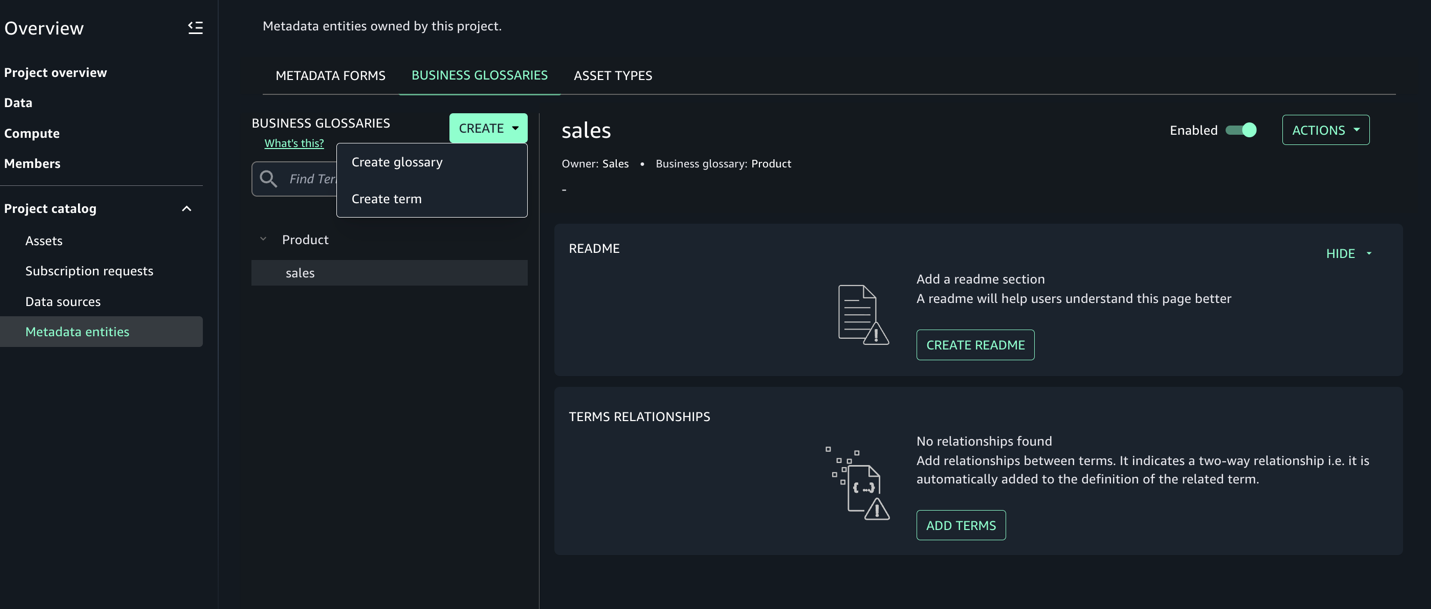
- Metadata entities から「Product」という名前の用語集と「Sales」という名前の用語を作成します。
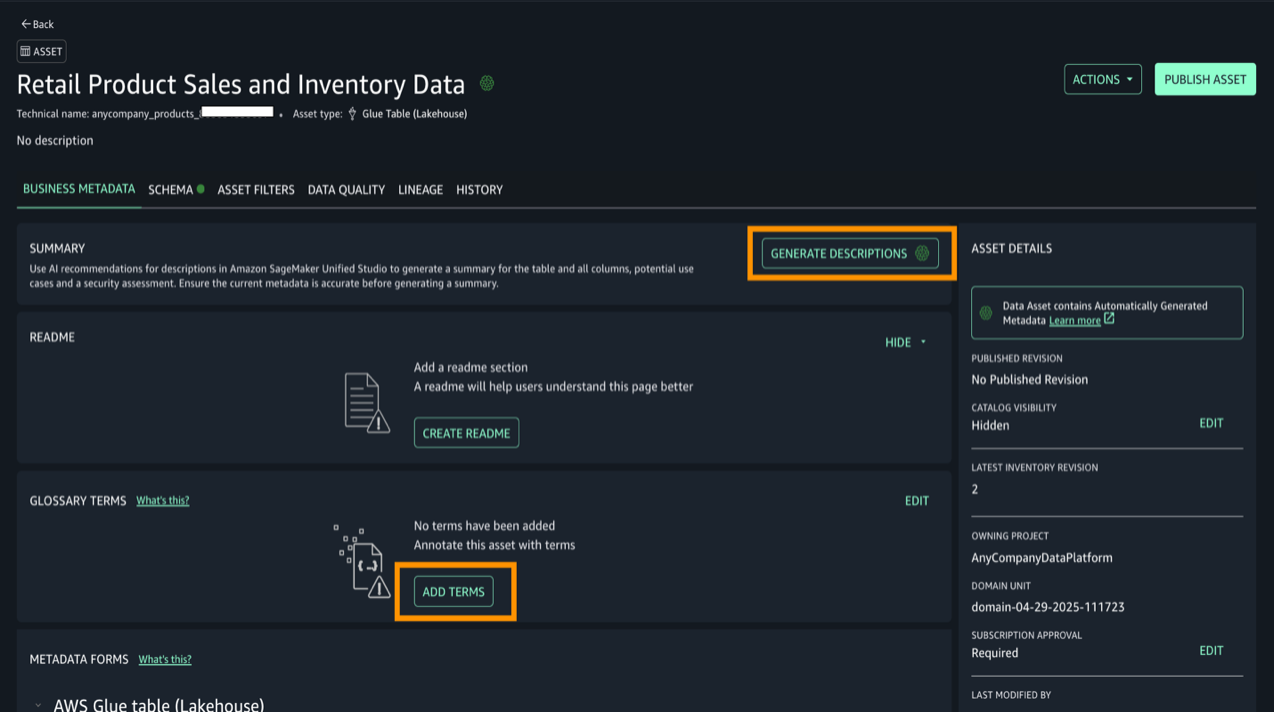
- Generate Descriptions を選択して、AI でデータの概要を自動生成します。Add Terms を選択します。
- 自動メタデータ生成で ACCEPT ALL を選択します。

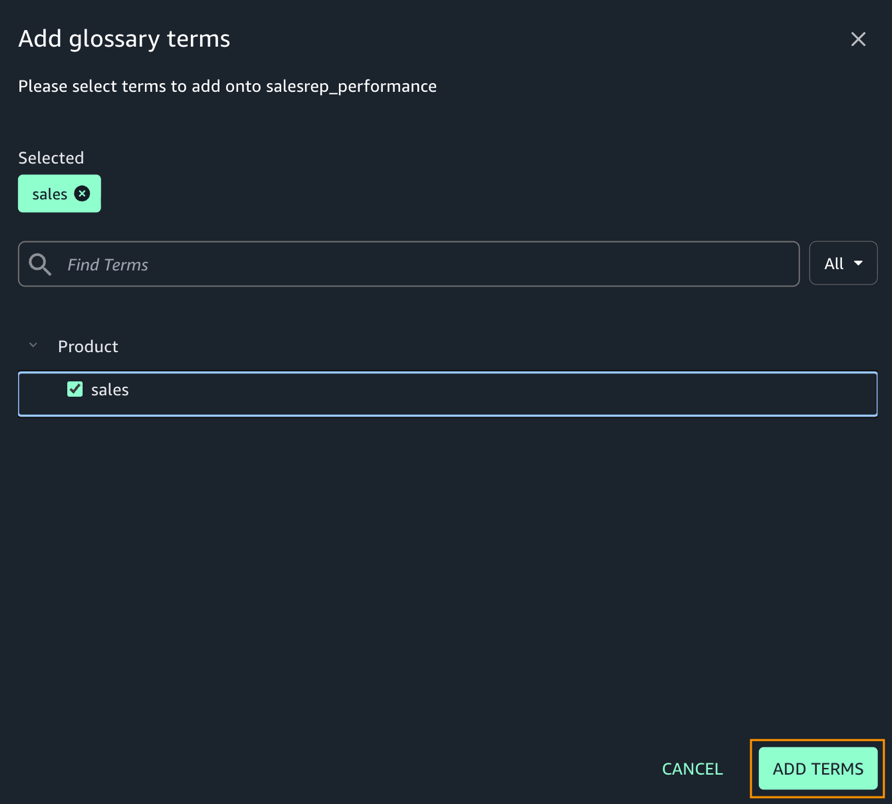
- sales 用語を選択し、Add Terms を選択します。
- Publish Asset を選択します。
- Assets を選択し、Published を選択します。検索可能でサブスクリプションリクエストが可能な公開アセットが表示されます。
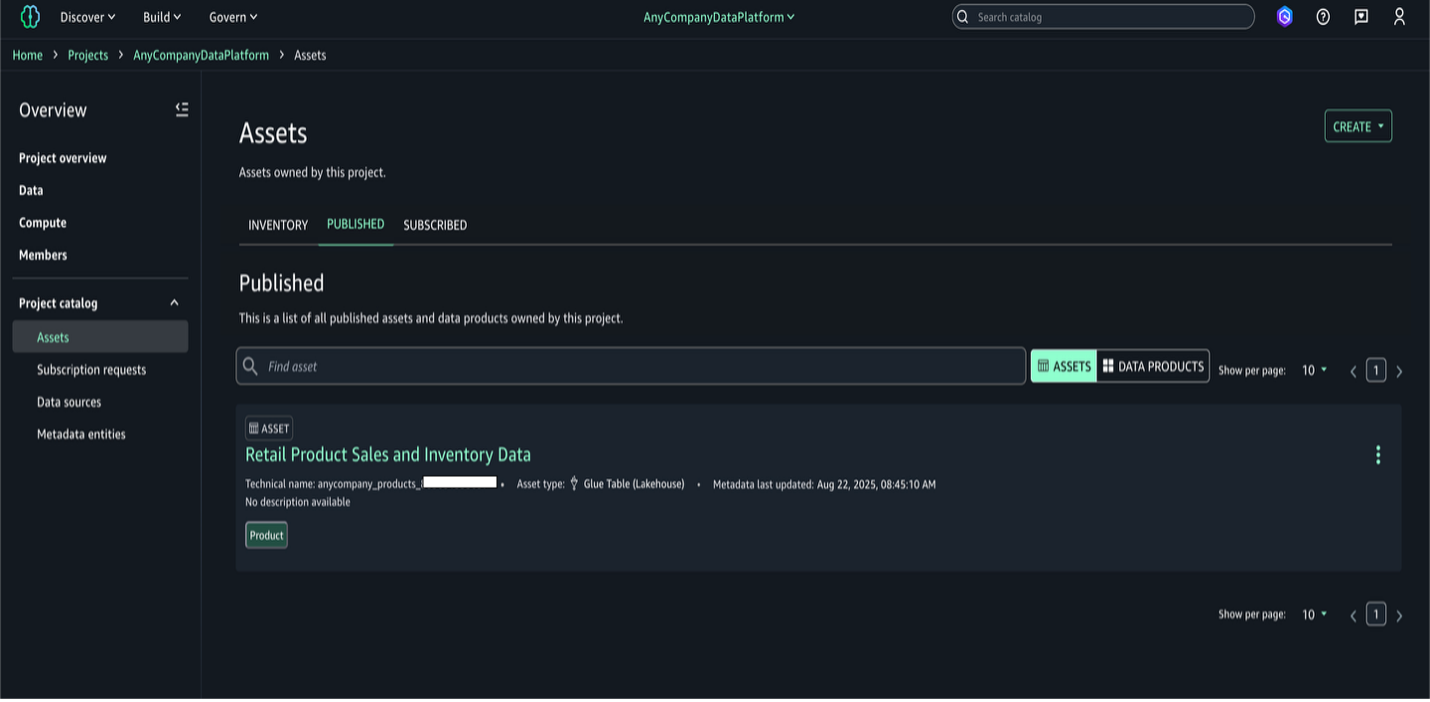
同様の手順で、他のデータプロダクトのビジネス用語集も作成できます。
ステップ 5: アクセス制御の設定
適切なガバナンスを確保するため、きめ細かなアクセス制御を設定します。
- 各ユーザーに対して新しいシングルサインオン (SSO) ユーザーを作成します。
- 以下のロールと権限を作成し、SSO ユーザーに割り当てます。
| ロール | 説明 | アクセスレベル |
|---|---|---|
| Data Steward | データカタログと用語集を管理 | カタログと用語集へのフルアクセス |
| ETL Developer | データ統合パイプラインを開発 | データソースと AWS Glue への読み取り/書き込みアクセス |
| Data Analyst | 販売データを分析 | すべての販売データへの読み取り専用アクセス |
| AI Engineer | 予測モデルを構築 | 販売データへの読み取りアクセス、SageMaker 機能へのフルアクセス |
SageMaker Catalog のメリット
Amazon SageMaker Unified Studio を使用してセルフサービスビジネスデータカタログを実装することで、小売組織は以下の主要なメリットを得られます。
- 統一されたデータアクセス: 単一のインターフェースから Amazon S3、Redshift、Snowflake のデータを検索・アクセスできます。
- 標準化されたメタデータ: ビジネス用語集により、組織全体で一貫した用語を使用できます。
- ガバナンスとコンプライアンス: きめ細かなアクセス制御により、ユーザーは許可されたデータのみにアクセスできます。
- コラボレーション: ETL 開発者、データアナリスト、AI エンジニアなど、異なるチームが共有環境でコラボレーションできます。
クリーンアップ
本記事で作成したリソースに関連する追加料金が発生しないよう、AWS アカウントから以下の項目を削除してください。
- Amazon SageMaker ドメイン。
- Amazon SageMaker ドメインに関連付けられた Amazon S3 バケット。
- VPC ピアリング接続、セキュリティグループ、ルートテーブル、AWS Glue Data Catalog エントリ、関連する IAM ロールなどのクロスアカウントリソース。本記事で作成したテーブルとデータベース。
まとめ
本記事では、Amazon SageMaker Catalog が複数のデータソースにまたがるデータの公開、検索、分析に対して統一されたアプローチを提供する方法を紹介しました。小売シナリオを使用して、Amazon S3、Amazon Redshift、Snowflake からのデータを Amazon SageMaker Unified Studio にインポートし、複数のソースからのデータを結合・分析して有意義なビジネスインサイトを導き出す方法を示しました。
メタデータを一元管理しクロスソースのデータ統合を可能にすることで、組織全体でデータを容易に検索でき、データの移動や複製なしに複数のデータソースを結合して包括的な分析を実行できます。統一されたアプローチにより、すべてのデータソースにわたって一貫したポリシー、セキュリティ、コンプライアンスによる強力なガバナンスを維持しながら、チームのインサイト獲得までの時間を短縮するセルフサービス分析を実現できます。
Amazon SageMaker の詳細と開始方法については、Amazon SageMaker ユーザーガイドを参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Woosuk Choi がレビューしました。