Amazon Web Services ブログ
TROCCO の CDC 機能をつかった RDB と Apache Iceberg on AWS の連携
はじめに
こんにちは。AWS Analytics Specialist ソリューションアーキテクトの深見 です。
データベースの変更をリアルタイムに分析基盤へ反映したいというニーズに高まりを感じています。実際に多くのお客様から相談をいただいております。またデータベースの差分をもとに連携することが望まれる場面も多くあります。そういう場合の選択肢の一つが CDC(Change Data Capture)と呼ばれる MySQL の binlogなどの変更履歴をもとにデータを連携する手法になります。しかし、CDC での実装は、データ取得・キャッシュレイヤー・コンシューマーの実装とコンポーネントが多くなる場合も多く技術的なハードルが高く、ソースデータベースのスキーマの変更をターゲットの分析基盤に滞りなく連携する必要があるなど運用負荷も大きいワークロードになります。
CDC のターゲットの選択肢の1つとして、Iceberg を利用することで多様なエンジンから利用することができ、ソーススキーマの変更にも柔軟に対応ができるコスト効率の良い、DB のデータをソースにしたデータレイクハウスを構築することができます。
本記事では、AWS パートナーである primeNumber 社が提供するデータ統合プラットフォーム「TROCCO」の CDC 機能を使って、MySQL から AWS 上の Apache Iceberg テーブルへのリアルタイムレプリケーションを実現する方法をご紹介します。実際に検証した内容をもとに、セットアップから運用まで詳しく解説していきます。
RDB から Apache Iceberg テーブルへのデータ連携のユースケース
RDB をソースに Apache Iceberg へデータを連携したい場面はどのようなケースがあるでしょうか?いくつかの例をみてみましょう。
OLTP と OLAP の分離
RDB にあるデータを分析に使いたい場合でも、様々な理由で直接 RDB に分析クエリを実行することがためらわれる場面はよくあるかと思います。その中でも多く上がる理由としては、ソース DB のトランザクショナルなワークロードのパフォーマンスに影響を与えたくないといった理由です。インタラクティブに分析されるケースでは、そのためだけにリードレプリカなどで分析用のリソースを用意することもコスト増加につながってしまいます。そのため、OLTP (Online Transaction Processing) と OLAP(Online Analytical Processing) を分離することでリソース管理・効率の向上やコスト最適化を狙った分離を行うことがあります。Apache Iceberg を利用することで高いコスト効率で OLAP 環境を用意することが可能になります。また、Apache Iceberg のオープンなフォーマットである特徴から分析ユーザーの好みのクエリエンジンを利用することが非常に簡単になります。例えば AWS のエンジンであれば Athena や Redshift、OSS のエンジンであれば Spark や Trino、DuckDB や PyIceberg から同じテーブルを参照することができるようになります。これにより、広い活用の幅をもったデータレイクを構築することが可能になります。
タイムトラベル機能を利用した過去断面の参照
データベーステーブルの過去の断面を再現する必要のある場面は度々見受けられます。例えば、テーブルのデータに不整合が発生した際のロールバック、もしくは ML や AI のモデル開発時のモデル変更による影響を過去のテーブルを使って確認するバックテストといったユースケースがあげられます。
これに関連する Iceberg の大きな特徴として、スナップショットを利用した過去のテーブルの断面を指定してクエリを実行するタイムトラベル機能があります。RDB から Iceberg テーブルにデータを差分で連携することで過去のテーブルの状態を容易に確認することが可能です。従来変更差分をバックアップとして保持しようとすると、定期的にフルスナップショットを取得しそれを保管しておくといったコストのかかる方法が必要でした。しかし、Iceberg では差分データを効率的に保持することが可能なため高いコスト効率でテーブルの断面を保持することが可能です。
他にも様々な場面で RDB から Iceberg テーブルへのデータ連携が有効なソリューションになりえます。これを実装や管理・運用の手間を低く抑えて実現することができる 1 つの手段が TROCCO の CDC 機能になります。
TROCCO とは
TROCCO は、データの収集・加工・転送を簡単に実現できるデータ基盤構築・運用の支援 SaaS です。ノーコード/ローコードでデータパイプラインを構築でき、多様なデータソースとデスティネーションに対応しています。
今回ご紹介する TROCCO の CDC 機能は、ソーステーブルの変更(INSERT/UPDATE/DELETE)やカラムの追加といったスキーマの変更をリアルタイムに検知し、ターゲットシステムへ自動的に反映することをインフラの管理なく実現することができる機能です。ソース DB としては、2025 年 12 月時点で MySQL と PostgreSQL に対応しています。(CDC 機能は Professional プランの契約が前提となります。)
今回はその中の、ソースの MySQL から ターゲットの AWS 上の Glue Data Catalog に登録された Iceberg テーブルにデータ連携する方法をご紹介します。
アーキテクチャ概要
今回構築するシステムのアーキテクチャは以下の通りです:
- ソース: MySQL データベース(8.x 以降推奨)
- CDC 処理: TROCCO CDC 機能
- ターゲット: Amazon S3 + AWS Glue Data Catalog(Apache Iceberg 形式)
- クエリエンジン: Amazon Athena
TROCCO が MySQL のバイナリログを監視し、変更を検知すると、その変更を Iceberg 形式で Amazon S3 に書き込みます。Glue Data Catalog にメタデータが登録されるため、Athena から即座にクエリ可能になります。

セットアップ手順
1. ネットワーク設定
TROCCO から MySQL へ接続するため、セキュリティグループの設定が必要です。TROCCO の固定 IP アドレスからの接続を許可します。
TROCCO の固定 IP アドレスは公式ドキュメントで確認できます。また、エフェメラルポートとして 1024-65535 を使用するため、セキュリティグループでこの範囲を開放する必要があります。
2. IAM ロールの作成
TROCCO が S3 と Glue Data Catalog にアクセスするため、適切な権限を持つ IAM ロールを作成します。CDC 機能では IAM ロールのみがサポートされています(IAM ユーザーは使用できません)。
TROCCO のドキュメント にある必要な IAM ポリシーの例はこのようなものになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::<bucket_name>"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::<bucket_name>/*"
},
{
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:UpdateDatabase",
"glue:CreateDatabase"
],
"Resource": [
"arn:aws:glue:<aws_region>:<account_id>:catalog",
"arn:aws:glue:<aws_region>:<account_id>:database/<database_name>"
]
},
{
"Effect": "Allow",
"Action": [
"glue:GetTable",
"glue:UpdateTable",
"glue:CreateTable",
"glue:DeleteTable"
],
"Resource": [
"arn:aws:glue:<aws_region>:<account_id>:catalog",
"arn:aws:glue:<aws_region>:<account_id>:database/<database_name>",
"arn:aws:glue:<aws_region>:<account_id>:table/<database_name>/*"
]
}
]
}
ターゲットの Iceberg テーブルの Location である S3 と 該当の Glue Data Catalogへのアクセス権限が必要になります。
3. TROCCO 接続情報の設定
TROCCO の管理画面から、以下の接続情報を登録します。
- Amazon S3 の接続情報: IAM Role の ARN、S3 バケット名、リージョン
- MySQL の接続情報: ホスト名、ポート、データベース名、ユーザー名、パスワード
まずは Amazon S3 への接続情報を設定する必要があります。 AWS アカウント ID、先ほど 2 番で作成した IAM Role を設定します。

また、下部に表示される TROCCO の AWS アカウントと外部 ID を先ほど作成した IAM Role に設定します。
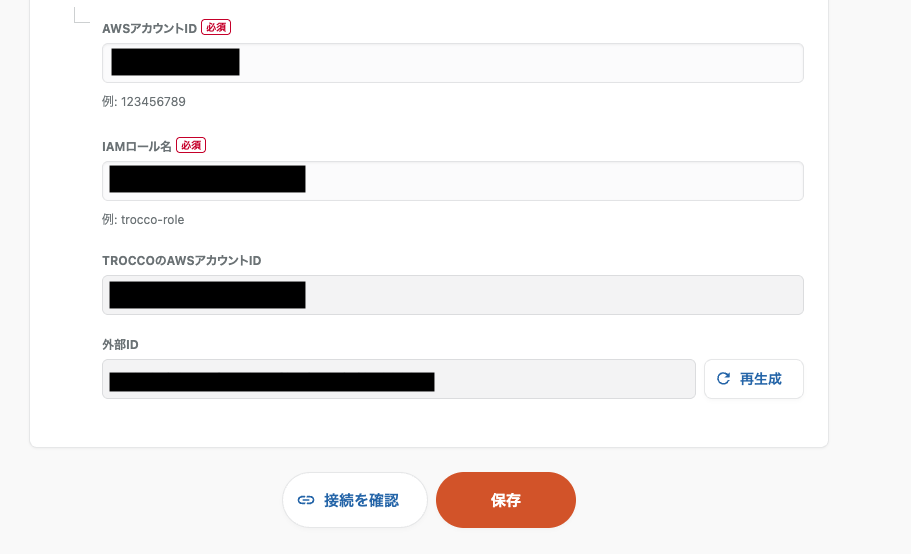
IAM Role の 信頼ポリシーは以下のようになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::{TROCCO AWS Account ID}:root"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": {External ID}"
}
}
}
]
}次に、MySQL 接続情報を設定します。接続先 DB のホスト、ポート、ユーザー名、パスワードが必要になります。この設定をする前に ソース DB 側で binlogの設定が必要になることに注意してください。

4. CDC 転送設定の作成
今作成した接続情報を元に、TROCCO の管理画面から新しい CDC 転送設定を作成します。
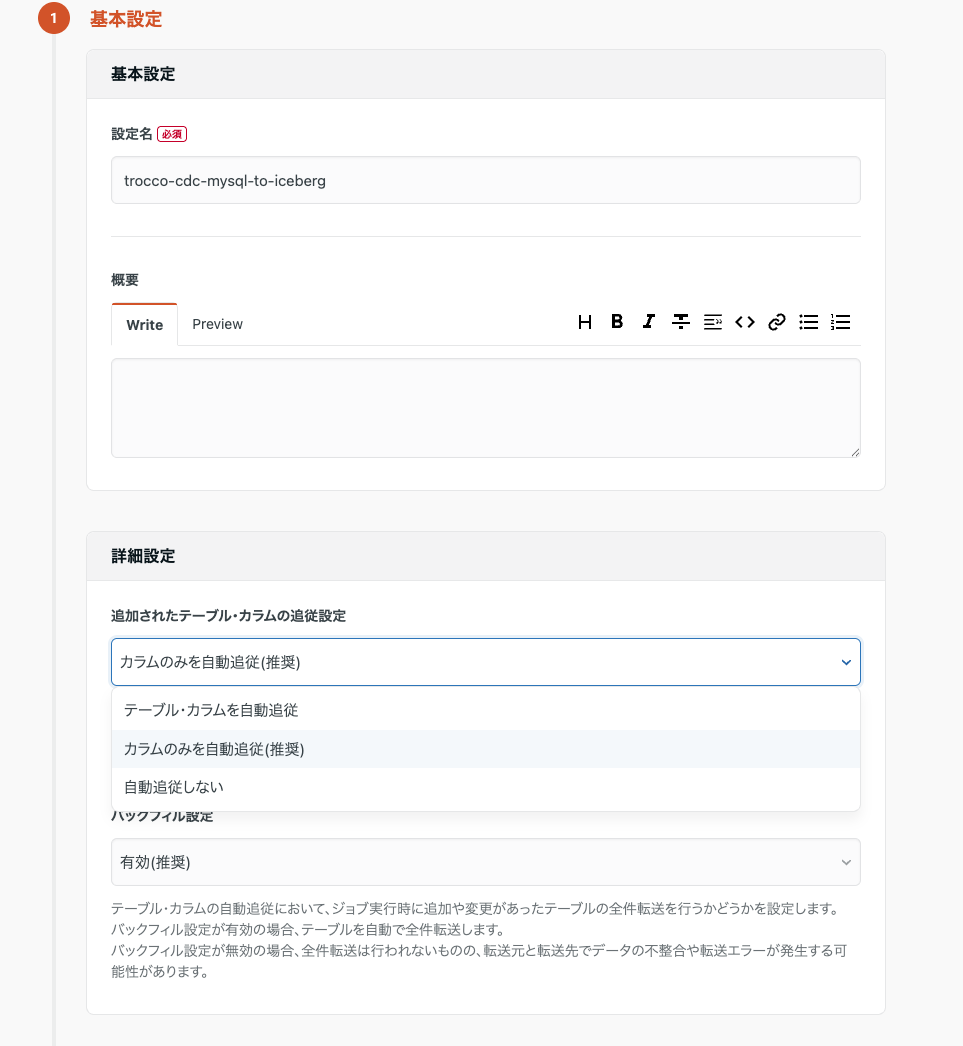
ここで、この CDC データ転送機能の特徴であるテーブルやカラムの自動追従に関する設定が可能です。テーブル・カラムどちらも追従する、カラムのみ追従する、追従しないの 3 パターンが選択できます。

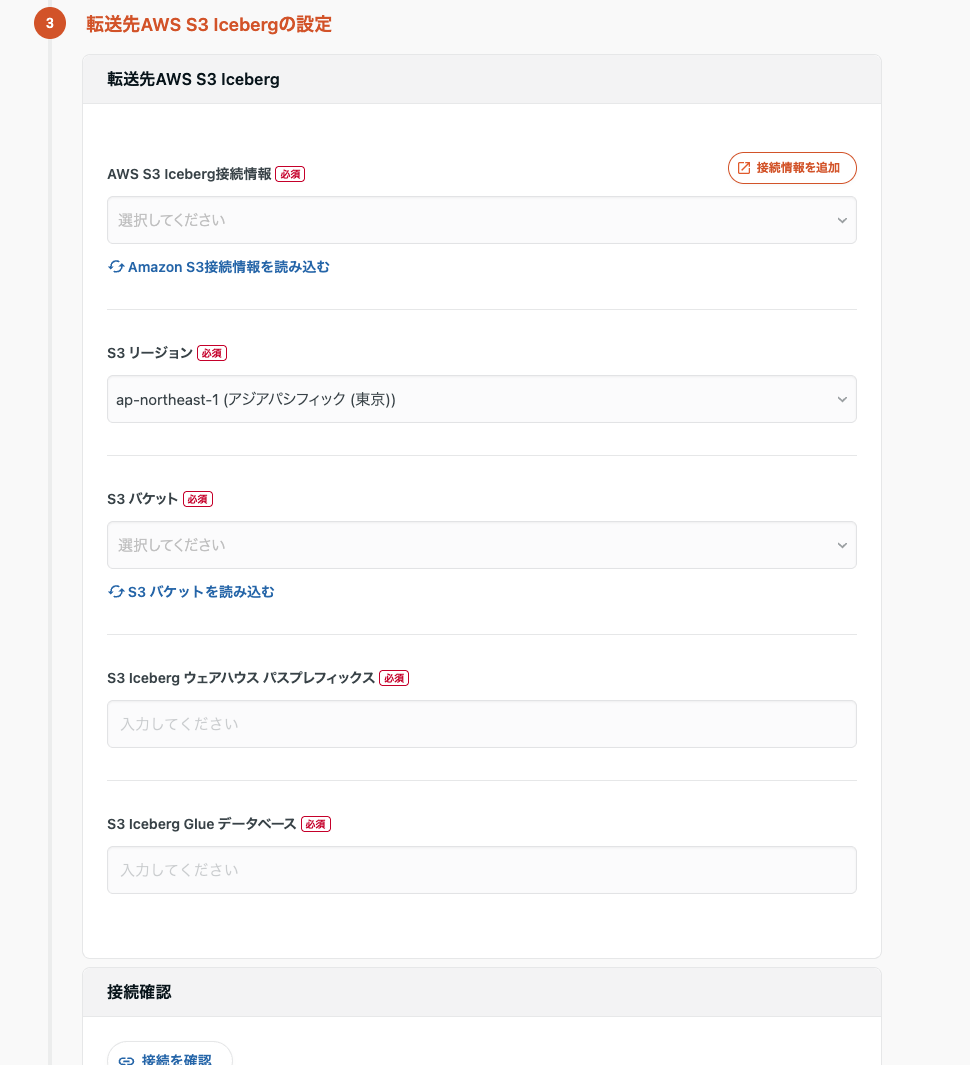
先ほど設定した MySQL と S3 の接続情報をここで選択します。S3 の設定については Iceberg のプレフィックスやターゲットテーブルの Glue データベースも選択する必要があります。
設定はなんとこれだけで完了です!
主要な機能
それでは先ほど作成した CDC データ転送設定を実行してみます。

データ連携
初回実行時にはフルロードが実行され、ソーステーブルの既存データがすべて Iceberg テーブルに転送されます。なお、スキーマ設定より連携するテーブルは選択することができます。
初回のフルロード完了後は、スケジュール設定に従って MySQL のバイナリログを監視して差分更新を継続的に実行します。スケジュールは最短 5 分間隔で設定可能です。
スキーマ変更の自動追従
TROCCO の CDC 機能は、ソースデータベースのスキーマ変更を自動的に検知し、Iceberg テーブルに反映します。
カラム追加の場合、新しいカラムが Iceberg テーブルに自動的に追加されます。既存レコードの新規カラムは NULL になります。バックフィル機能を有効にすると、全レコードを再転送できますが、Iceberg のスナップショット履歴が失われる点に注意が必要です。詳細はこちらをご覧ください。
カラム削除の場合、TROCCO 側では該当カラムのデータ転送が停止されますが、Iceberg テーブルからカラムは削除されません。必要に応じて手動での削除が必要です。
連携するテーブル・カラムの選択
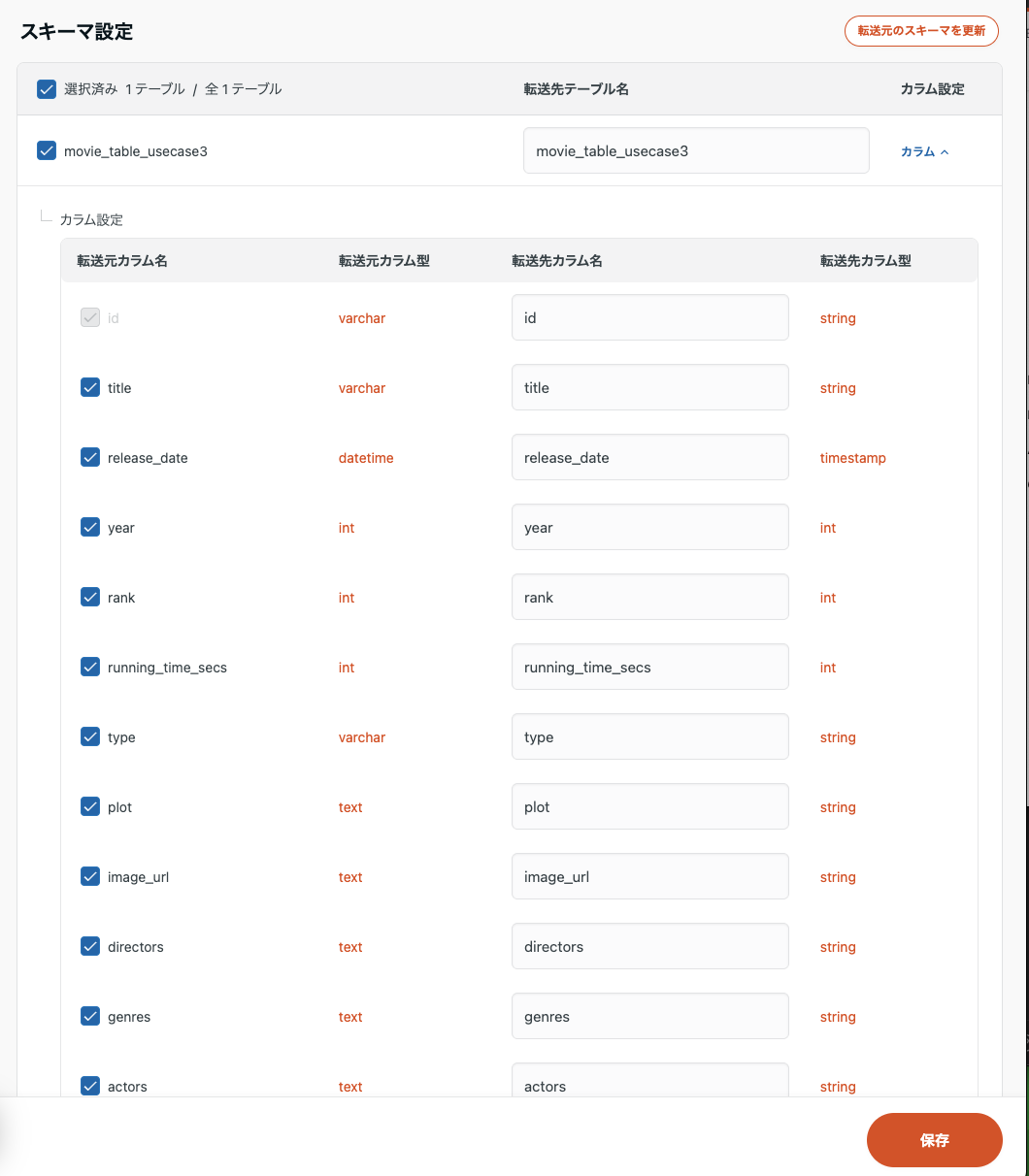
転送するテーブルやその中のカラムを選択できるため、機密情報を含むカラムを除外したり、不要なカラムを転送しないことでコストを最適化することも簡単にできます。
その他にも、事前に通知先を設定しておくことで、ジョブの実行結果やスキーマ変更の通知を E-mail や Slack に行うことも可能です。また、ジョブの履歴やそれぞれのログについても UI 上で確認が可能になっています。
連携した Iceberg テーブルへのクエリ
ジョブの実行後に AWS コンソールからGlue カタログを確認してみると、TROCCO で設定したテーブルが適切に連携されていることがわかります。
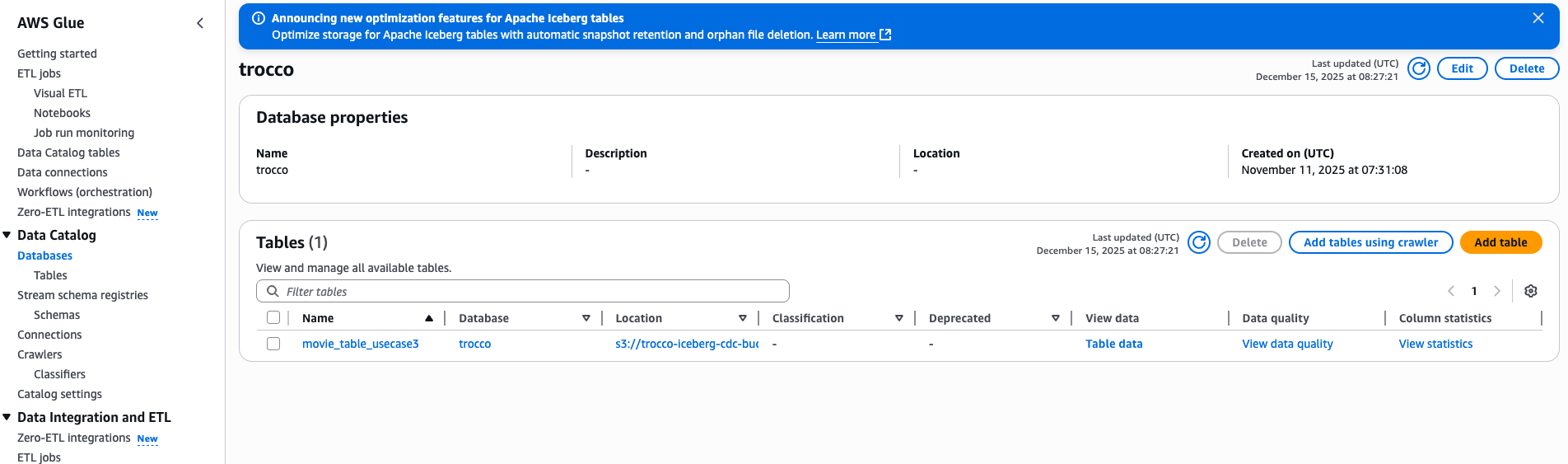

連携先の Iceberg テーブルは Athena や Glue、Redshift などさまざまなエンジンからクエリすることが可能です。Iceberg テーブルへのクエリに対応している 3rd party の製品からのクエリももちろん可能です。(ただし、Equality Delete File の読み取りに対応している必要があります。詳細は Apache Iceberg のdocument をご参照下さい。)
今回は、SageMaker Unified Studio の AI エージェントが組み込まれたノートブックからクエリを行ってみました。下のスクリーンショットのように、連携された Iceberg テーブルを簡単にクエリすることができました。

また、AI エージェントに対して連携した Iceberg テーブルへのクエリを指示することで、クエリ文を作らせて実行することも可能です。今回は、Iceberg の特徴の一つであるスナップショットの履歴を確認したい旨を指示してみました。
`Show me snapshots history of spark_catalog.trocco.movie_table_usecase.`
実際に生成されたクエリが以下の画像です。Iceberg 特有の概念ではありますが、適切なクエリを生成して実行してくれました。結果をみるとこのテーブルには2つのスナップショットがあるようです。この ID を指定することで、過去のテーブル断面をクエリすることができます。このように、Iceberg とくゆうの機能の操作に慣れていない場合でも AI エージェントを使いながら利用することが可能です。

まとめ
TROCCO の CDC 機能を使うことで、複雑な CDC パイプラインを構築することなく低い実装コストで RDB と Apache Iceberg のデータ連携を実現することが可能になります。本ブログで説明したように GUI のみで非常に簡単に設定できる上に、ジョブやソーステーブルの監視と通知の機能も UI 上で利用が可能であり、運用する上でもその負荷を下げてくれる機能が揃っています。
これによって、簡単に RDB のデータをソースとした OLAP 基盤を構築したり、タイムトラベルによるバックアップの役割を持つデータレイクへの連携パイプライン構築することが可能になります。
連携した Iceberg テーブルについて、最適なパフォーマンスが出せるようにデータファイルサイズのコンパクションや期限切れスナップショットの処理などテーブルのメンテナンスが重要です。そのため、Glue Data Catalog の Iceberg テーブルの自動メンテナンス機能をはじめとして、メンテナンスジョブの実行についてもご検討いただくことをおすすめします。
ぜひ AWS と そのパートナーである primeNumber 社の TROCCO を利用して効果的なデータ基盤を構築していきましょう。
著者について
 Shuhei Fukami : AWS Japan で Analytics Specialist Solutions Architect としてデータ分析や検索などデータにまつわるワークロードのご支援をしています。趣味でピザ作りにはまっています。
Shuhei Fukami : AWS Japan で Analytics Specialist Solutions Architect としてデータ分析や検索などデータにまつわるワークロードのご支援をしています。趣味でピザ作りにはまっています。