AWS JAPAN APN ブログ
AWS 上の Palantir HyperAuto による拡張可能で迅速な ERP 分析
本記事は、Tom Pearson, Lead Architect – Palantir、および Mehmet Bakkaloglu, Sr. Solutions Architect – AWS、Francesco Polimeni, Sr. Solutions Architect – AWS による共著です。
 |
| Palantir |
 |
現代の企業が利用できるリソースの中で、データが最も重要なものであることは周知の事実です。例を挙げると、構造化、非構造化、トランザクション、地理空間など、多くの企業が様々な種類のデータを保有しています。
課題は、必ずしもデータの生成、カタログ化、保存ではなく、データを運用可能なものにすることです。Palantir Foundry は、既存のデータシステムと分析ツールを活用して、よりスマートな意思決定を可能にする運用プラットフォームです。分析と運用を融合し、ライトバックと学習ループを活用して、時間の経過とともに複合的な価値を生み出します。
差し迫った課題に対し、データを運用可能なものにするための最初のステップは、統合です。データの統合は一般的に時間がかかり、手作業が多く、基盤となるデータ構造に関する専門知識が必要になることがよくあります。
Palantir HyperAuto は、Palantir の Software-Defined Data Integration (SDDI) 技術を利用してこの課題を解決し、エンジニアが新しいコードを一行も書く必要なく、ソースシステムからパイプラインを構築します。
大規模な組織で一般的に見られるそのようなソースシステムの一つは、エンタープライズリソースプランニング (ERP) システムです。組織は多くの場合、合併や買収により、様々なバージョンで稼働する複数の ERP システムを保有しています。
Palantir HyperAuto は、SDDI を利用して、データの取り込み、変換、モデリングを自動化します。これにより、売上原価 (COGS)、在庫、工場、倉庫、製品など、主要なビジネステーマの 360 度ビューを即座に提供します。また、動的な “what-if” シナリオテストが可能になり、売り上げを増やし、製品構成を最適化し、コストを削減する機会を特定できます。この後、Foundry が継続的な学習のためにソースシステムにライトバックします。
2021 年 3 月、Palantir は、Amazon Web Services (AWS) のお客様にコスト削減を提供する Foundry ERP Suite を発表 (現在は HyperAuto にパッケージ化) しました。このブログ記事では、SAP に焦点を当てたソリューションの概要と、AWS で稼働する Foundry がどのような拡張性を実現しているのかを説明します。
Palantir と AWS
AWS 認定ソフトウェア製品を提供する AWS パートナーである Palantir は、組織がデータ、意思決定、運用を統合するためのソフトウェアを構築しています。
AWS 上にデプロイされる Palantir Foundry は、拡張性と費用対効果の高いプラットフォームを提供するために、コアサービスとして Amazon Simple Storage Service (Amazon S3)、Amazon Elastic Compute Cloud (Amazon EC2)、Amazon EC2 Auto Scaling、Elastic Load Balancing (ELB)、Amazon Relational Database Service (Amazon RDS)、AWS Key Management Service (AWS KMS) などを活用しています。
また、AWS は、5,000 を超える SAP のお客様と数百のパートナーに選ばれている革新的なプラットフォームです。Foundry ERP Suite は、SAP ERP Central Component と SAP S/4HANA の両方のほとんどのバージョンをサポートしています。SAP ワークロードを AWS で実行しているお客様は、Foundry にデータを取り込む際のレイテンシーが改善されるというメリットがあります。
Palantir HyperAuto の概要
Palantir HyperAuto は、ソースシステムコネクター、ソースデータエクスプローラー、自動パイプラインジェネレーターという 3 つのコアコンポーネントで構成されます。具体的な例として、SAP データを扱うという切り口で、これらの各コンポーネントを見ていきましょう。
Diskover Limited とのパートナーシップで開発した SAP 認定コネクター は、SAINT (SAP Add-on Installation Tool) を使用してインストールします。セットアップが完了すると、ユーザーは “syncs” を構成して、SAP ECC や SAP S/4HANA、SAP BW (Business Warehouse)、SLT (SAP Landscape Transformation Replication Server) からデータを安全に取り込むことができます。
SAP システムへのライトバック機能は、SAP のリモート汎用モジュール、通常は BAPI (Business Application Programming Interface) 機能を利用して実現します。
Palantir HyperAuto Source Explorer for SAP ERP は、直感的なインターフェースを提供し、SAP システムの中身を調査し、数回クリックするだけで特定のユースケースやワークフローのデータ抽出を一括作成します。ソースシステムのメタデータを活用するため、SAP の専門知識は必要ありません。
インターフェースの中で、ユーザーは次のことができます:
- SAP モジュール (在庫購買管理や販売管理など) をシームレスに参照し、ドリルダウンして関連するすべての共通オブジェクト (在庫、ベンダー、注文書など) と ERP テーブルを検出します
- 規定のテーブルのスキーマを検査し、一連のレコードをプレビューして、抽出する前にデータをよりよく理解します
- 包括的な検索機能を使用して、事前定義されたモジュール以外の他の SAP テーブルを見つけることができます

図 1 – Palantir HyperAuto Source Explorer for SAP ERP
Palantir HyperAuto Automatic Pipeline Generator は、SAP データを処理し、利用可能な形式に変換するための完全で効率的なパイプラインをすぐに生成します。また、事前定義されたプロパティと関係を持つ一連のオブジェクトタイプ (在庫、顧客、受注伝票などの現実世界の概念にマッピングされたもの) を動的に生成します。
以下の図 2 で示す Foundry Data Lineage モジュールでは、ソースから宛先までの変換の表示を確認できます。左側の茶色のボックスは、SAP データ抽出です。中央の緑色のボックスは、自動的に構築されたデータパイプラインです。右側の黒と黄色のボックスは、オブジェクトタイプです。
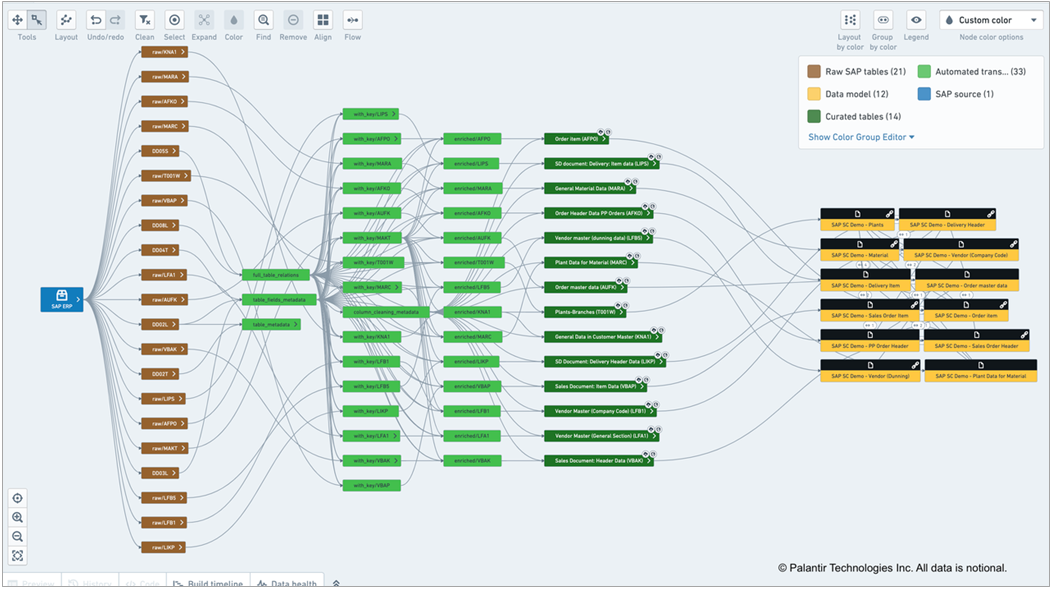
図 2 – 自動生成されたデータパイプラインの系統
アーキテクチャと拡張性
大企業は、通常、数百万から数十億のレコードを持つ複数の ERP システムを保有しています。このようなデータを分析用に処理するためには、非正規化、マッピング、重複排除などの操作が必要ですが、これには高度な拡張性がある計算能力が求められます。
そのうえ、企業はサプライチェーンの可視性を向上させるために、サプライヤーや顧客からのデータにますます依存するようになり、データの規模はさらに拡大しています。
これらすべてに対応するには、拡張可能なアーキテクチャが必要です。AWS で稼働する Foundry を利用した Palantir HyperAuto は、このために設計されています。
2017 年、Palantir は、Spark やその他の分散コンピューティングフレームワークのための安全で、拡張可能で、インテリジェントなスケジューリングと実行エンジンを作成するために Rubix project を開始しました。Rubix は、Spark-on-Kubernetes の仕様に従って実装され、(1) ユーザーが作成したコードが存在する場合のマルチテナントセキュリティ、(2) 予測可能なパフォーマンスという二つの重要な要件を満たしています。
複数の AWS リージョンにデプロイされる Rubix は、様々なサイズと規模 (数十から数千ノード) のクラスターを管理し、各 Amazon EC2 インスタンスが 48~72 時間ごとにリサイクルされるエフェメラルインフラストラクチャで稼働するように設計されています。
Rubix エンジンの設計により、次の利点を提供します:
- 新たにパッチを適用した Amazon Machine Images (AMIs) が 48~72 時間のリサイクルで自動的にデプロイされ、長時間のマルウェア攻撃が定期的に破棄される EC2 インスタンスに依存できないため、セキュリティ体制が改善されます
- 複数のインスタンスタイプを使用する Auto Scaling グループ採用により、EC2 インスタンスのキャパシティを最適化できます
Rubix project の詳細な説明については、次のリソースを参照してください:
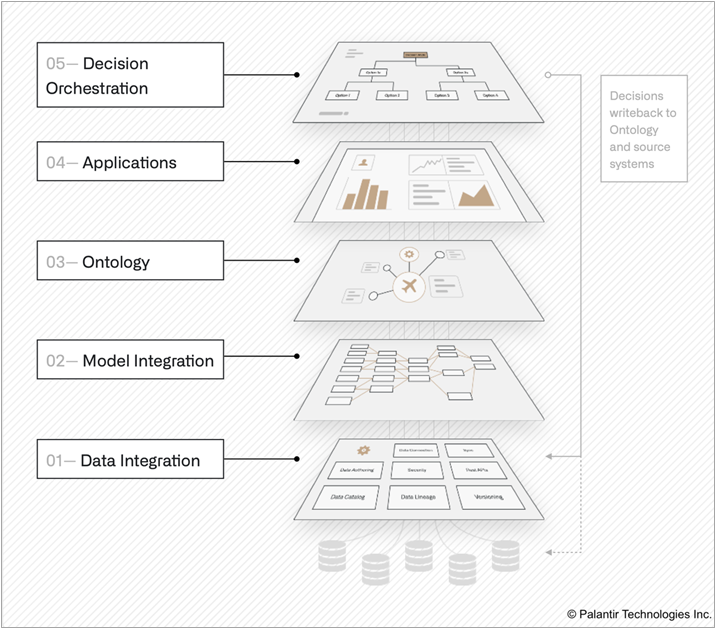
図 3 – Palantir Foundry のアーキテクチャ
他データとの統合
Palantir は、2004 年の会社設立以来、ソースシステムからのデータを統合するソフトウェアを開発してきました。最初は Gotham で、次が Foundry です。
現在、Palantir Foundry には、Software-as-a-Service (SaaS) アプリケーション、オンプレミスアプリケーション、その他の AWS サービスを含む 200 を超える異なるソースシステムとのコネクターがあります。例えば、Foundry は、AWS IoT サービス、Amazon Kinesis、Amazon S3、Amazon RDS などからのデータを取り込むことができます。
これらのコネクターを Foundry ERP Suite と組み合わせることで、Palantir は組織のすべてのデータ資産の全体像を迅速に構築できます。例えば、SAP データと IoT データを統合した幅広いユースケースをサポートできます。
ビジネスユースケース
重機製造の世界的業界リーダーである Doosan Infracore は、Palantir Foundry を使用して、製品開発から生産、販売から品質管理までのバリューチェーン全体でデータを統合することで、データ基盤を構築しています。
このデータ基盤は、新製品開発、サプライチェーン管理、アフターマーケットや製品サポートなどの分野におけるワークフローを強化します。
アプリケーション
Foundry で統合されたデータモデルにより、お客様は Amazon SageMaker などの AWS サービスを利用して機械学習モデルを構築し、それらのモデルを Foundry に統合できます。
また、Foundry では、サプライチェーンの回復力、二酸化炭素排出量の監視、製造における品質、マネーロンダリング対策、公益事業のためのアセット 360 などの特定のビジネスユースケース向けに、データモデルを利用した事前構築済みのテンプレートである Archetypes を迅速にデプロイすることもできます。
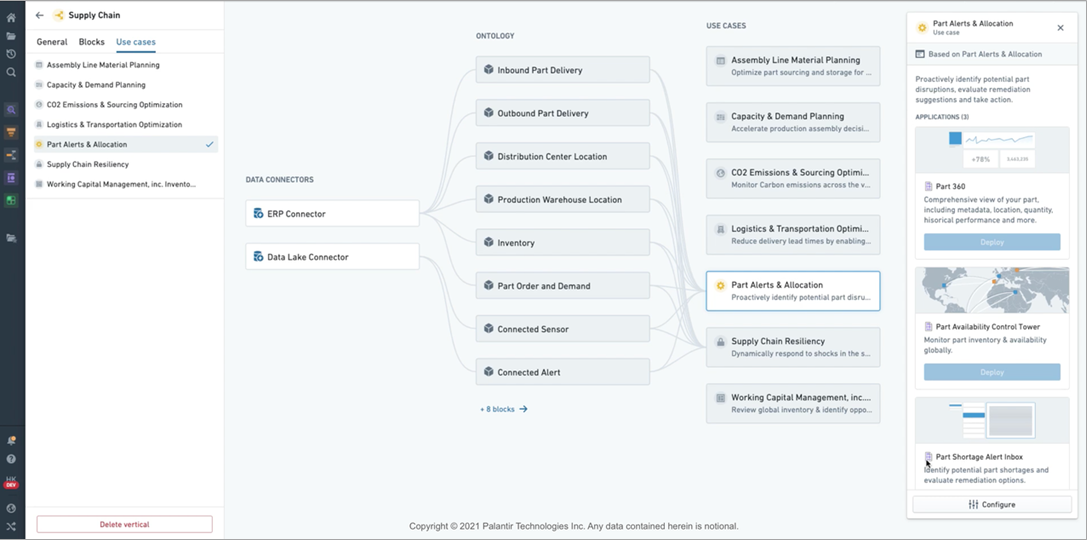
図 4 – Palantir Foundry の Archetypes
結論
この記事では、拡張性の高いアーキテクチャを提供する AWS で稼働する Foundry を利用した Palantir HyperAuto が、ERP システムからのデータを迅速に統合し、差し迫ったビジネス課題に対して既存のデータを運用可能なものにする方法を探究しました。
HyperAuto はソフトウェアで定義された方法でデータを統合するため、従来のデータ分析への参入に対する技術的な障壁を取り除き、ビジネスユーザー、IT、オペレーターが協力して信頼できる情報源に基づいて作業できるようにします。
最も重要なことは、企業が数か月や数年ではなく、数時間や数日で運用を改善できることです。
.

.
Palantir – AWS パートナースポットライト
Palantir は、組織がデータ、意思決定、運用を統合するためのソフトウェアを構築する AWS パートナーです。
*既に Palantir と連携されていますか?パートナーを評価してください。
*AWS パートナーを評価するには、その AWS パートナーとプロジェクトで直接関わったことのあるお客様でなければなりません。
翻訳は、Partner SA 河原が担当しました。原文はこちらです。