Pocket Bundle シリーズ : Amazon Aurora MySQL・PostgreSQL 互換のクラウドネイティブなリレーショナルデータベース
2026-06-02 | Author : 米倉 裕基 (監修 : 伊勢田 氷琴、三浦 晟太郎)

Pocket Bundle シリーズとは ?
AWS サービスの要点を「ポケットに入れて持ち歩ける」コンパクトさで解説するシリーズです。図解とポイント解説を中心に、短時間で要点を把握できる構成になっています。基礎概念から実践的な設計知識まで、現場で役立つ情報を凝縮しています。
Amazon Aurora とは
Amazon Aurora は、Amazon RDS 上で動作するクラウドネイティブなリレーショナルデータベースエンジンです。MySQL と PostgreSQL の両方に互換性があり、既存のコード・ツール・アプリケーションをほぼそのまま利用できます。
「クラウドネイティブ」とは、クラウド環境の特性を最大限に活かすよう設計されていることを意味します。Aurora はストレージとコンピュートを分離したアーキテクチャを採用しており、従来のデータベースでは難しかった「高性能」「高可用性」「運用の自動化」を同時に実現しています。
Aurora は Amazon RDS の一部として提供されるため、RDS コンソールから作成・管理します。RDS が提供するパッチ適用、バックアップ、モニタリングなどのマネージド機能をそのまま活用しつつ、Aurora 独自の高性能ストレージサブシステムの恩恵を受けられます。
なお、Aurora は MySQL と PostgreSQL の「互換」であり、完全な同一ではありません。一部のネイティブ機能やプラグインは利用できない場合があります。移行前に互換性の詳細 (Aurora MySQL / Aurora PostgreSQL) を確認してください。
詳しくは、公式ドキュメントの「Amazon Aurora とは」をご覧ください。
X ポスト » | Facebook シェア » | はてブ »

builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
主な特徴
Aurora には 3 つの主要な特徴があります。商用 DB を超える高性能、高可用性・高耐久性、そして運用の自動化です。
パフォーマンスについて、Aurora は MySQL 比最大 5 倍、PostgreSQL 比最大 3 倍のスループットを実現するとされています。ただし、この数値は特定のベンチマーク条件下での結果であり、実際のパフォーマンスはワークロードの特性によって異なります。この性能差は、Aurora 独自のストレージエンジンに起因します。従来のデータベースではトランザクションログをストレージに書き込んでからデータページを更新しますが、Aurora はログレコードのみをストレージ層に送信し、データページの生成はストレージ側で非同期に行います。この「ログ構造化ストレージ」により、書き込み I/O が大幅に削減されます。
高可用性については、データを 3 つの Availability Zone (AZ) にまたがる 6 つのストレージノードに同期的にレプリケートします。6 つのコピーのうち、書き込みは 4 つ、読み取りは 3 つのコピーが応答すれば処理が完了するクォーラムモデルを採用しており、一部のノードに障害が発生してもサービスを継続できます。Multi-AZ 構成の SLA は 99.99%、Single-AZ 構成では 99.9% です。
運用面では、自動バックアップ、自動パッチ適用、ストレージの自動拡張 (最大 128 TiB、特定バージョン以降は 256 TiB) が標準で提供されます。データベース管理者が手動で行っていた多くの作業が自動化されるため、アプリケーション開発に集中できます。
詳しくは、公式ドキュメントの「Amazon Aurora の特徴」をご覧ください。

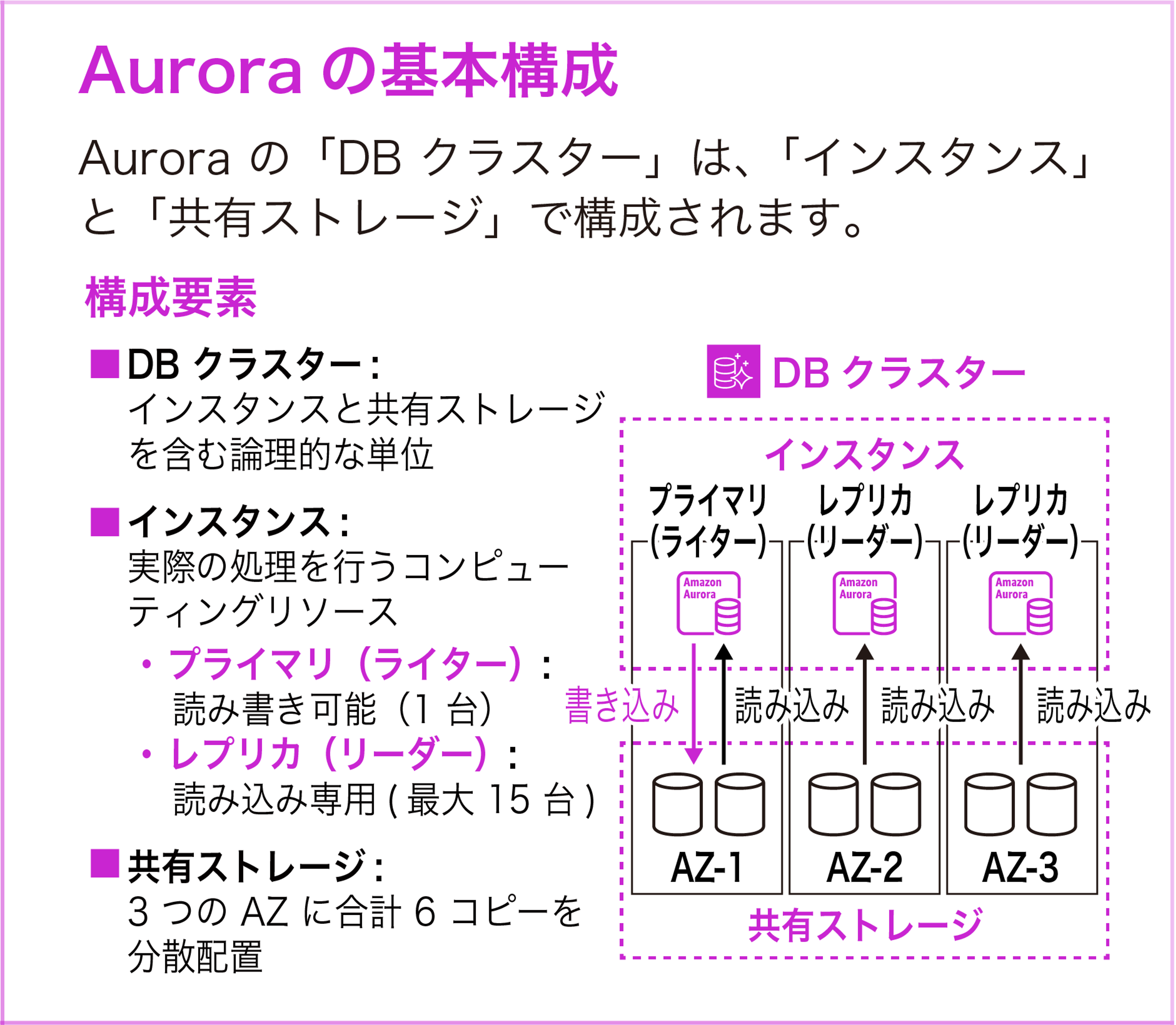
Aurora の基本構成
Aurora は「DB クラスター」という単位で構成されます。DB クラスターは「インスタンス」と「共有ストレージ (クラスターボリューム)」の 2 つの要素で成り立っています。
インスタンスには 2 つの役割があります。プライマリインスタンス (ライター) は読み書き両方を処理し、クラスターに 1 台だけ存在します。Aurora レプリカ (リーダー) は読み取り専用で、最大 15 台まで追加できます。
Aurora の最大の特徴は「ストレージとコンピュートの分離」です。従来のデータベースではインスタンスごとにストレージが紐付いていましたが、Aurora ではすべてのインスタンスが 1 つの共有ストレージ (クラスターボリューム) にアクセスします。このため、レプリカの追加時にデータのコピーが不要で、数分で新しいリーダーを追加できます。
クラスターボリュームは SSD ベースで、3 つの AZ に合計 6 コピーのデータを分散配置します。この 6 コピーの仕組みにより、2 つのコピーが同時に失われてもデータの書き込みが可能で、3 つのコピーが失われても読み取りが可能です。
レプリカを削除してもデータは失われません。データはクラスターボリュームに保持されるため、クラスター全体を削除しない限りデータは安全です。
詳しくは、公式ドキュメントの「Amazon Aurora DB クラスター」をご覧ください。
基本的な使い方
Aurora データベースの作成から利用開始まで、RDS コンソール上で完結します。「エクスプレス設定」を選択すると、事前設定済みの Aurora PostgreSQL Serverless (負荷に応じてキャパシティが自動で調整されるサーバーレス構成。詳細は本記事の「スケーリング」のセクション を参照) を数秒で作成を開始できます (クラスターが完全に利用可能になるまでは数分かかる場合があります)。
「フル設定」では、エンジンのタイプ (Aurora MySQL または Aurora PostgreSQL)、DB クラスター識別子、マスターユーザー情報、インスタンスクラス、VPC、セキュリティグループなどを細かく指定できます。

選択のポイントと接続方法
Aurora MySQL と Aurora PostgreSQL のどちらを選ぶかは、既存のスキルセットやアプリケーションの要件で判断します。既存の MySQL アプリケーションを移行する場合は Aurora MySQL、PostgreSQL の高度な機能 (JSONB、配列型、CTE など) が必要な場合は Aurora PostgreSQL が適しています。新規開発で特にこだわりがなければ、PostgreSQL エコシステムの拡張性から Aurora PostgreSQL を選択するケースが増えています。
作成後は、RDS コンソールに表示されるエンドポイント (接続先 URL) を使ってアプリケーションや DB クライアントから接続します。書き込みにはクラスターエンドポイント、読み取りにはリーダーエンドポイントを使い分けるのが基本です (詳細は本記事の「接続エンドポイント」のセクションを参照)。
初めて Aurora を試す場合は、AWS 無料利用枠 を活用できます。新規の AWS アカウントでは、サインアップ時に $100 のクレジットが付与され、Aurora などのサービス利用で追加 $100 を獲得できます。
詳しくは、公式ドキュメントの「Amazon Aurora の開始方法」をご覧ください。
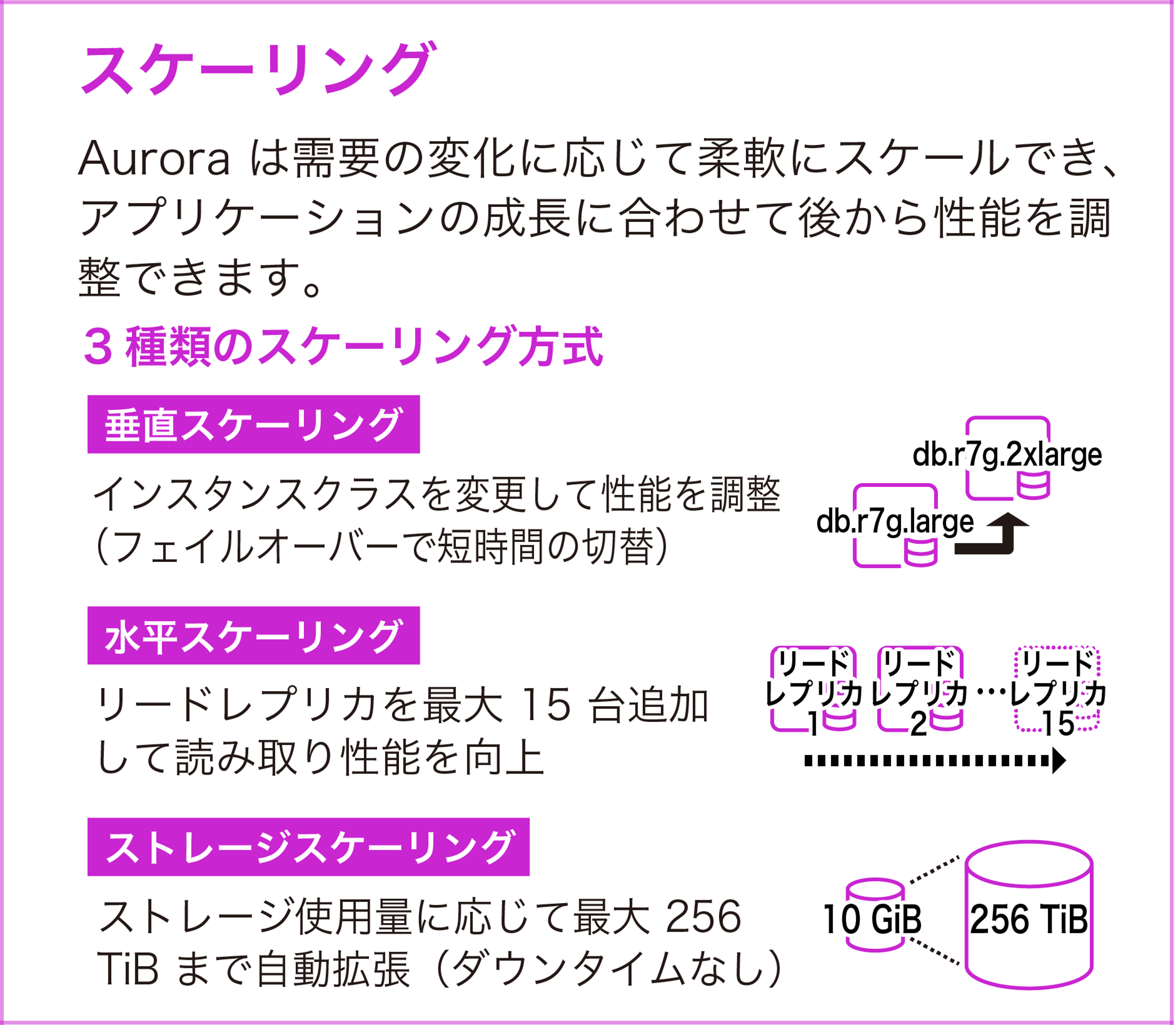
スケーリング
Aurora は需要の変化に応じて柔軟にスケールでき、アプリケーションの成長に合わせて後から性能を調整できます。垂直スケーリング、水平スケーリング、ストレージスケーリングの 3 種類があります。
スケーリングの種類
インスタンスクラスを変更して性能を調整します (例:db.r7g.large → db.r7g.2xlarge)。変更時にはフェイルオーバーが発生しますが、通常 60 秒未満で完了します (多くの場合 30 秒未満)。本番環境ではメンテナンスウィンドウ中に実施するか、ブルー/グリーンデプロイ を使って安全に切り替えることを推奨します。
手動でのインスタンスクラス変更が煩雑な場合は、Aurora Serverless v2 を検討してください。0 ~ 256 ACU (Aurora Capacity Unit) の範囲で自動的にスケールし、負荷に応じてリアルタイムにキャパシティが調整されます。1 ACU は約 2 GiB のメモリに相当します。さらに、最小キャパシティを 0 ACU に設定すると、アイドル時に自動で一時停止し、接続リクエストが来ると自動で再開する「オートポーズ」機能も利用できます (デフォルトのアイドル時間は 5 分)。開発・テスト環境のコスト削減に有効です。
リードレプリカを最大 15 台まで追加して読み取り性能を向上させます。Aurora の共有ストレージアーキテクチャにより、レプリカ追加時にデータのコピーが不要なため、数分で新しいリーダーが利用可能になります。Aurora Auto Scaling を設定すると、CPU 使用率や接続数に基づいてレプリカの台数を自動調整できます。
さらに大規模なスケーリングが必要な場合は、Aurora PostgreSQL Limitless Database が選択肢になります。自動シャーディングにより、単一インスタンスの限界を超えてペタバイト規模のデータと数百万トランザクション/秒を処理できます。
クラスターボリュームはデータ量に応じて自動的に拡張され、最大 128 TiB (特定のエンジンバージョンでは 256 TiB、詳細は本記事の「制限事項・注意点」を参照) まで成長します。ダウンタイムは発生しません。データを削除すると使用領域も自動的に縮小されるため、不要なテーブルを DROP すればストレージ料金を削減できます。
詳しくは、公式ドキュメントの「Aurora Serverless v2 の使用」をご覧ください。
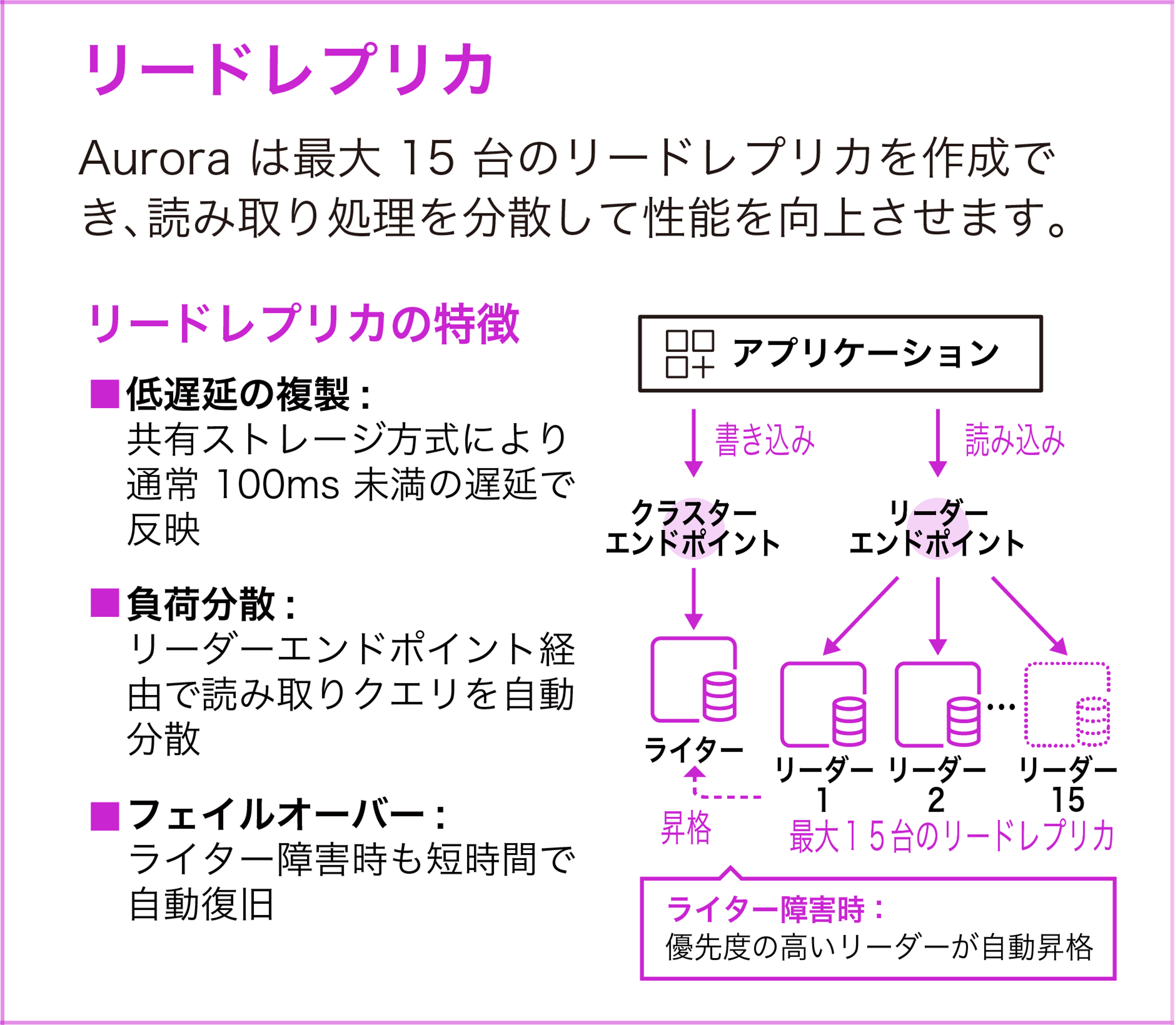
リードレプリカ
Aurora は最大 15 台のリードレプリカを作成でき、読み取り処理を分散して性能を向上させます。
リードレプリカの詳細
一般的な MySQL/PostgreSQL のレプリケーションでは、プライマリからレプリカへデータを転送するため、レプリカが増えるほどプライマリの負荷が増加します。Aurora は共有ストレージ方式を採用しているため、レプリカの追加がプライマリの書き込み性能に影響しません。レプリケーション遅延も極めて低く (多くの場合 1 桁ミリ秒)、ほぼリアルタイムのデータ参照が可能です。
アプリケーションからはリーダーエンドポイントに接続するだけで、Aurora が自動的に複数のリーダーインスタンスに接続を分散します。書き込みはクラスターエンドポイントに接続します。アプリケーション側でロードバランシングのロジックを実装する必要はありません。
ライターインスタンスに障害が発生すると、Aurora は自動的に優先度の高いリーダーをライターに昇格させます。レプリカが存在する場合、フェイルオーバーは通常 60 秒未満で完了し、多くの場合 30 秒未満で完了します。レプリカがない場合は新しいプライマリインスタンスが作成されますが、最大 10 分程度かかるため、本番環境では最低 1 台のレプリカを別の AZ に配置することを強く推奨します。
フェイルオーバーの優先度は 0 (最高) ~ 15 (最低) で設定でき、同じ優先度のレプリカが複数ある場合はインスタンスサイズが大きいものが優先されます。
Amazon RDS Proxy を併用すると、フェイルオーバー時間を最大 66% 短縮できます。RDS Proxy はアプリケーションとデータベースの間に入り、接続プーリングとフェイルオーバーの自動ルーティングを提供します。
詳しくは、公式ドキュメントの「Amazon Aurora の高可用性」をご覧ください。
継続的バックアップ
Aurora は継続的なバックアップにより、データ保護を自動化します。バックアップは Amazon S3 に保存され、Aurora のストレージと同様に 3 つの AZ に分散されます。

バックアップの種類
Aurora は DB クラスターのデータを継続的に Amazon S3 にバックアップします。保持期間は 1 ~ 35 日で設定でき、デフォルトは 1 日です。バックアップはインクリメンタル (増分) 方式で行われるため、バックアップ中のパフォーマンスへの影響はありません。自動バックアップのストレージは、クラスターボリュームと同容量まで無料です。
手動スナップショットは保持期間の制限がなく、明示的に削除するまで保持されます。大規模なスキーマ変更やバージョンアップグレードの前に取得しておくと、問題発生時に迅速にロールバックできます。
スナップショットを別のリージョンにコピーすることで、災害復旧 (DR) や地理的なデータ分散に対応できます。より高度な DR が必要な場合は、後述の Aurora Global Database を検討してください。
なお、DB クラスターを削除する際に「最終スナップショットの作成」を選択しないと、自動バックアップも含めてすべてのデータが失われます。削除時には必ず最終スナップショットを作成するか、自動バックアップの保持 を有効にしてください。
⚠ Aurora の「削除保護」を有効にしておくと、誤ってクラスターを削除することを防止できます。本番環境では必ず有効にしてください。
詳しくは、公式ドキュメントの「Aurora DB クラスターのバックアップと復元の概要」をご覧ください。
ポイントインタイムリカバリ
Aurora では、ポイントインタイムリカバリ (PITR) 機能により、自動バックアップ保持期間内 (1 ~ 35 日間) の任意の時点に秒単位で復旧できます。
PITR の最大の特徴は、復旧先が新しい DB クラスターとして作成される点です。元のクラスターはそのまま稼働を継続するため、本番環境に影響を与えずにデータを復旧できます。例えば、誤って DELETE や DROP TABLE を実行してしまった場合、その直前の時点に復旧した新しいクラスターからデータを取り出し、元のクラスターに戻すことができます。
Aurora MySQL のバックトラック
Aurora MySQL には、PITR に加えて「バックトラック」という独自機能があります。バックトラックは新しいクラスターを作成せずに、既存のクラスターを指定した時点まで「巻き戻す」機能です。PITR より高速に復旧できますが、最大 72 時間前までしか遡れず、バックトラック用の変更レコードを保存するための追加料金が発生します。また、クラスター作成時にバックトラックを有効にしておく必要があります (後から有効化はできません)。
PITR とバックトラックの使い分けとしては、数時間以内の誤操作からの迅速な復旧にはバックトラック、それ以前のデータ復旧や Aurora PostgreSQL 環境では PITR を使用します。
⚠ PITR で復旧可能な最新の時点は、通常、現在時刻の約 5 分前です。直近 5 分間のデータは復旧できない可能性があります。
詳しくは、公式ドキュメントの「DB クラスターを指定の時点の状態に復元する」をご覧ください。

接続エンドポイント
Aurora は用途に応じた接続エンドポイントを提供し、書き込みと読み取りを適切に振り分けます。エンドポイントは Aurora 固有の URL で、ホストアドレスとポート番号で構成されます。

エンドポイントの種類
|
エンドポイントの種類
|
用途
|
接続先
|
特徴
|
|---|---|---|---|
|
クラスターエンドポイント
|
書き込み / 読み取り |
ライター |
自動フェイルオーバー |
|
リーダーエンドポイント
|
読み取り専用 |
リーダー |
接続の自動負荷分散 |
|
カスタムエンドポイント
|
特定インスタンス指定 |
任意のインスタンスグループ |
用途別の細かい制御 |
通常はクラスターエンドポイント (書き込み) とリーダーエンドポイント (読み取り) の 2 つを使い分ければ十分です。
カスタムエンドポイントは、異なるインスタンスクラスが混在するクラスターで有効です。例えば、大きなインスタンスクラスのレプリカをレポート用、小さなインスタンスクラスのレプリカを通常の読み取り用に分けるといった使い方ができます。
フェイルオーバーが発生すると、クラスターエンドポイントは自動的に新しいライターを指すように更新されます。ただし、DNS キャッシュの影響で切り替えに時間がかかる場合があります。アプリケーション側で DNS キャッシュの TTL を短く設定するか、Amazon RDS Proxy を使用することで、フェイルオーバー時の接続切り替えを高速化できます。
また、Aurora Global Database を使用している場合は、Global Database ライターエンドポイントという特別なエンドポイントが提供されます。リージョン間のスイッチオーバーやフェイルオーバー時に、自動的に新しいプライマリクラスターを指すように切り替わるため、アプリケーションの接続文字列を変更する必要がありません。
⚠ インスタンスエンドポイント (個別のインスタンスに直接接続する URL) は診断やチューニング目的で使用します。通常のアプリケーション接続には使用しないでください。フェイルオーバー時に自動切り替えが行われません。
詳しくは、公式ドキュメントの「Amazon Aurora エンドポイント接続」をご覧ください。
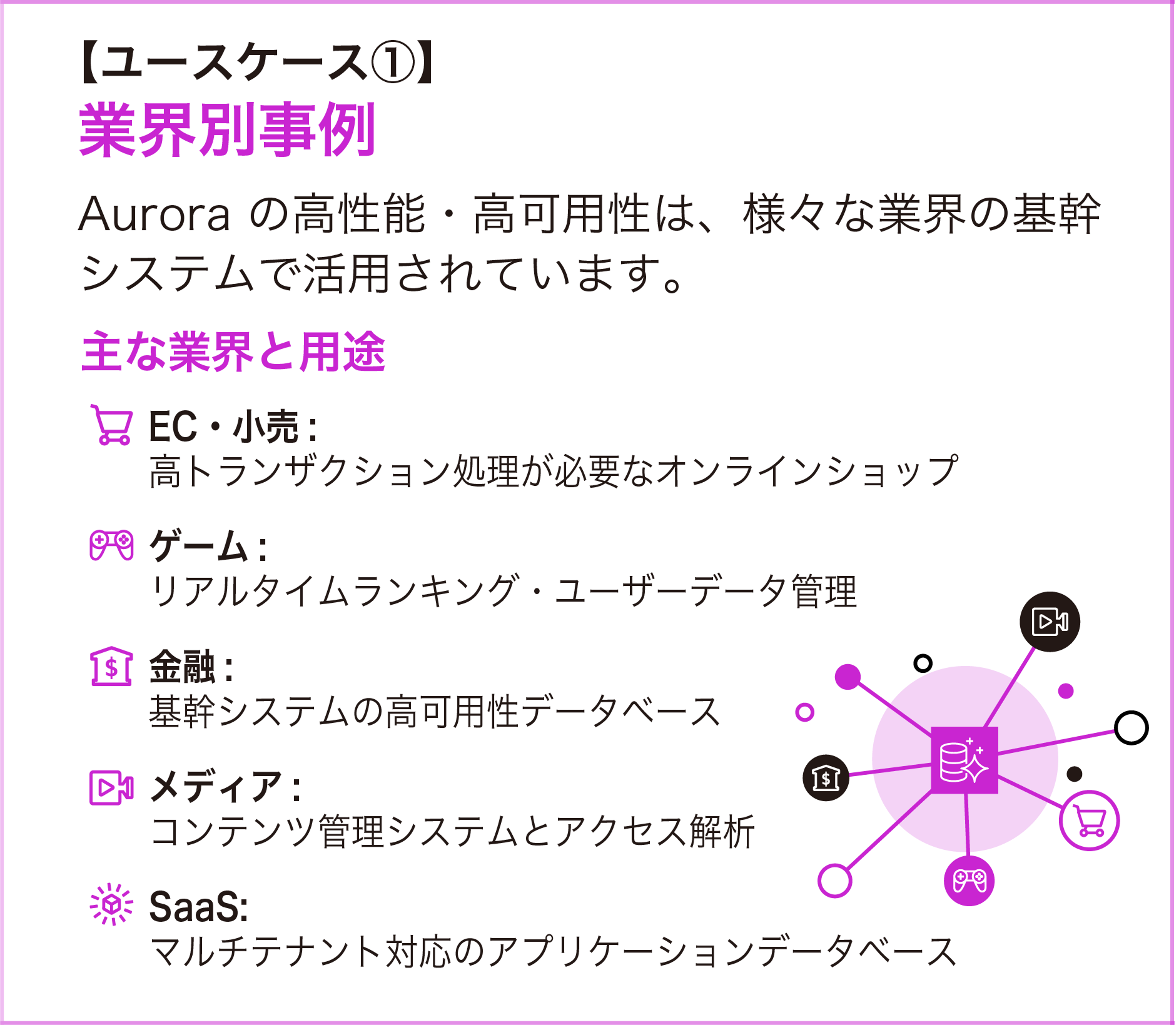
ユースケース① : 業界別事例
Aurora の高性能・高可用性は、様々な業界の基幹システムで活用されています。
詳しくは、公式ドキュメントの「Amazon Aurora のお客様」をご覧ください。
主な業界と用途
セール時のアクセス急増に対応するため、Aurora Serverless v2 の自動スケーリングが活用されています。通常時は最小キャパシティで運用し、セール開始と同時に自動でスケールアップすることで、プロビジョニングの手間なく高トランザクション処理を実現します。
リアルタイムランキングやユーザーデータ管理では、Aurora の低レイテンシな読み取りと最大 15 台のリードレプリカによる水平スケーリングが強みです。ゲームのリリース直後にユーザーが急増するケースでも、Aurora Auto Scaling でレプリカを自動追加できます。
金融機関の基幹システムでは、99.99% の可用性と 3 AZ × 6 コピーの耐久性が求められる厳格なデータ保護要件を満たします。Aurora Global Database を使えば、リージョン障害時にも 1 分未満で別リージョンにフェイルオーバーでき、RPO (目標復旧時点) 1 秒以内を実現します。
コンテンツ管理システム (CMS) では、記事の読み取りが大半を占めるため、リードレプリカで読み取り負荷を分散しつつ、ライターで編集・公開処理を行う構成が一般的です。
マルチテナント SaaS アプリケーションでは、テナントごとにスキーマやデータベースを分離しつつ、1 つの Aurora クラスターで管理するパターンが採用されています。Aurora PostgreSQL Limitless Database を使えば、テナント数の増加に伴うシャーディングも自動化できます。
ユースケース② : 課題別事例
従来のデータベースが抱えていたさまざまな課題を Aurora の機能で解決できます。
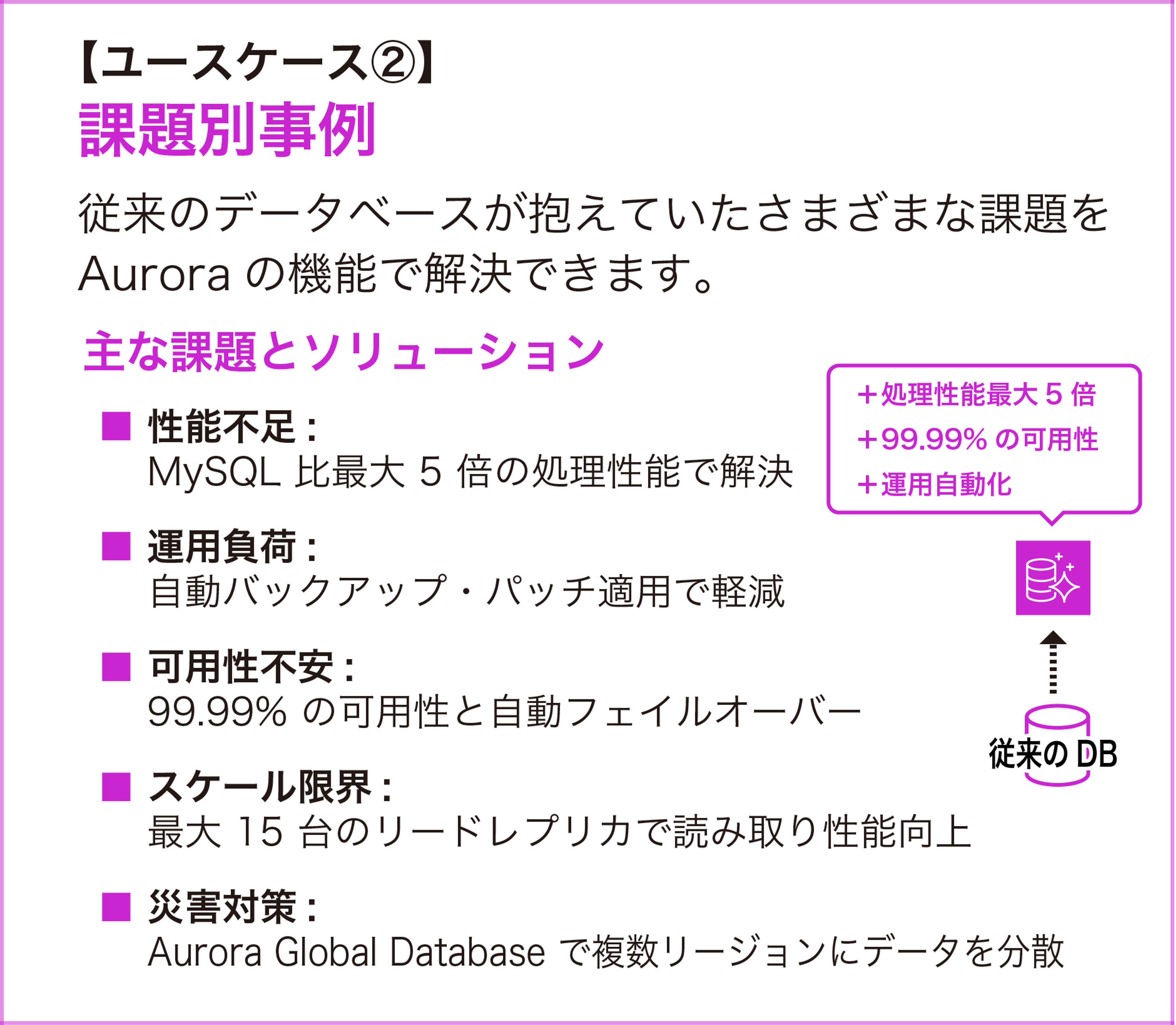
主な課題とソリューション
オンプレミスや EC2 上の MySQL/PostgreSQL で性能限界に達している場合、Aurora への移行で大幅な改善が期待できます。Aurora のストレージエンジンは書き込み I/O を最小化する設計のため、特にトランザクション処理の多いワークロードで効果を発揮します。Aurora MySQL Parallel Query を有効にすると、分析クエリの処理をストレージ層に分散でき、OLTP と OLAP の混在ワークロードにも対応できます (db.r* インスタンスクラス限定、Aurora I/O-Optimized 構成とは非互換など一部制約あり)。
OS パッチ適用、マイナーバージョンアップグレード、バックアップ、モニタリングが自動化されます。ブルー/グリーンデプロイ を使えば、メジャーバージョンアップグレードやパラメータ変更もダウンタイムを最小限に抑えて実施できます。
従来のデータベースでは、レプリケーションの設定やフェイルオーバーの仕組みを自前で構築する必要がありました。Aurora では 3 AZ への自動レプリケーションと自動フェイルオーバーが標準で組み込まれています。
読み取り負荷には最大 15 台のリードレプリカ、書き込み負荷には Aurora PostgreSQL Limitless Database の自動シャーディングで対応できます。
Aurora Global Database は、プライマリリージョンから最大 10 のセカンダリリージョンにストレージベースのレプリケーションを行います。レプリケーション遅延は通常 1 秒未満で、セカンダリリージョンでの読み取りも可能です。リージョン障害時には、セカンダリリージョンを 1 分未満でプライマリに昇格できます。
詳しくは、公式ドキュメントの「Amazon Aurora Global Database の使用」をご覧ください。
制限事項・注意点
Aurora には、利用時に把握しておくべき制限事項や注意点があります。
|
カテゴリー
|
制限・注意点
|
|---|---|
|
インスタンス数
|
クラスター当たり最大 16 台 (ライター 1 台 + リーダー最大 15 台) |
|
ストレージ
|
最大 128 TiB まで自動拡張 (Aurora MySQL 3.10 以降 / Aurora PostgreSQL 15.13・16.9・17.5 以降は 256 TiB) |
|
互換性
|
Aurora MySQL は 8.0 系 (バージョン 2 系の 5.7 互換は Extended Support)、Aurora PostgreSQL は 13 ~ 17 系に対応 (対応バージョンは随時更新) |
|
コスト
|
構成によっては従来の Amazon RDS より割高になる場合あり |
制限事項・注意点の解説
- ストレージ構成の選択
Aurora には Aurora Standard と Aurora I/O-Optimized の 2 つのストレージ構成があります。Aurora Standard は I/O リクエストごとに課金されるため、I/O 使用量が少ないワークロードに適しています。Aurora I/O-Optimized は I/O 料金が無料になる代わりにインスタンスとストレージの単価が高くなりますが、I/O コストが総コストの 25% 以上を占める場合は最大 40% のコスト削減が見込めます。
Aurora I/O-Optimized から Standard への切り替えはいつでも可能ですが、Aurora Standard から I/O-Optimized への切り替えは 30 日に 1 回のみです。まずは Aurora Standard で運用を開始し、Amazon Aurora のモニタリングツール で I/O コストの割合を確認してから切り替えを検討するのが安全です。
- コストに関する注意
Aurora は同等のインスタンスサイズの Amazon RDS for MySQL/PostgreSQL と比較してインスタンス単価が高めに設定されています。ただし、Aurora の高性能ストレージにより、同等のパフォーマンスを得るために必要なインスタンスサイズが小さくなるケースも多く、総コストでは Aurora の方が安くなることもあります。AWS 料金見積りツール で事前に試算することを推奨します。 - RDS Extended Support
Aurora のメジャーバージョンがコミュニティのサポート終了 (EOL) を迎えた後も、Amazon RDS 延長サポート を利用すれば最大 3 年間の延長サポートを受けられます。ただし、追加料金が発生し、EOL 後の経過期間に応じて段階的に料金が上がります。計画的なバージョンアップグレードを推奨します。 - 暗号化
2026 年 2 月 18 日以降に作成されたすべての新規 DB クラスター は、デフォルトで保管時の暗号化 (AES-256) が有効になっています。暗号化を無効にすることはできません。既存の暗号化されていないクラスターには影響しませんが、暗号化されたクラスターの暗号化を後から解除することもできません。暗号化キーは AWS 所有キー (SSE-RDS) がデフォルトですが、カスタマーマネージドキー (CMK) も選択できます。
詳しくは、公式ドキュメントの「Amazon Aurora のクォータと制約」をご覧ください。

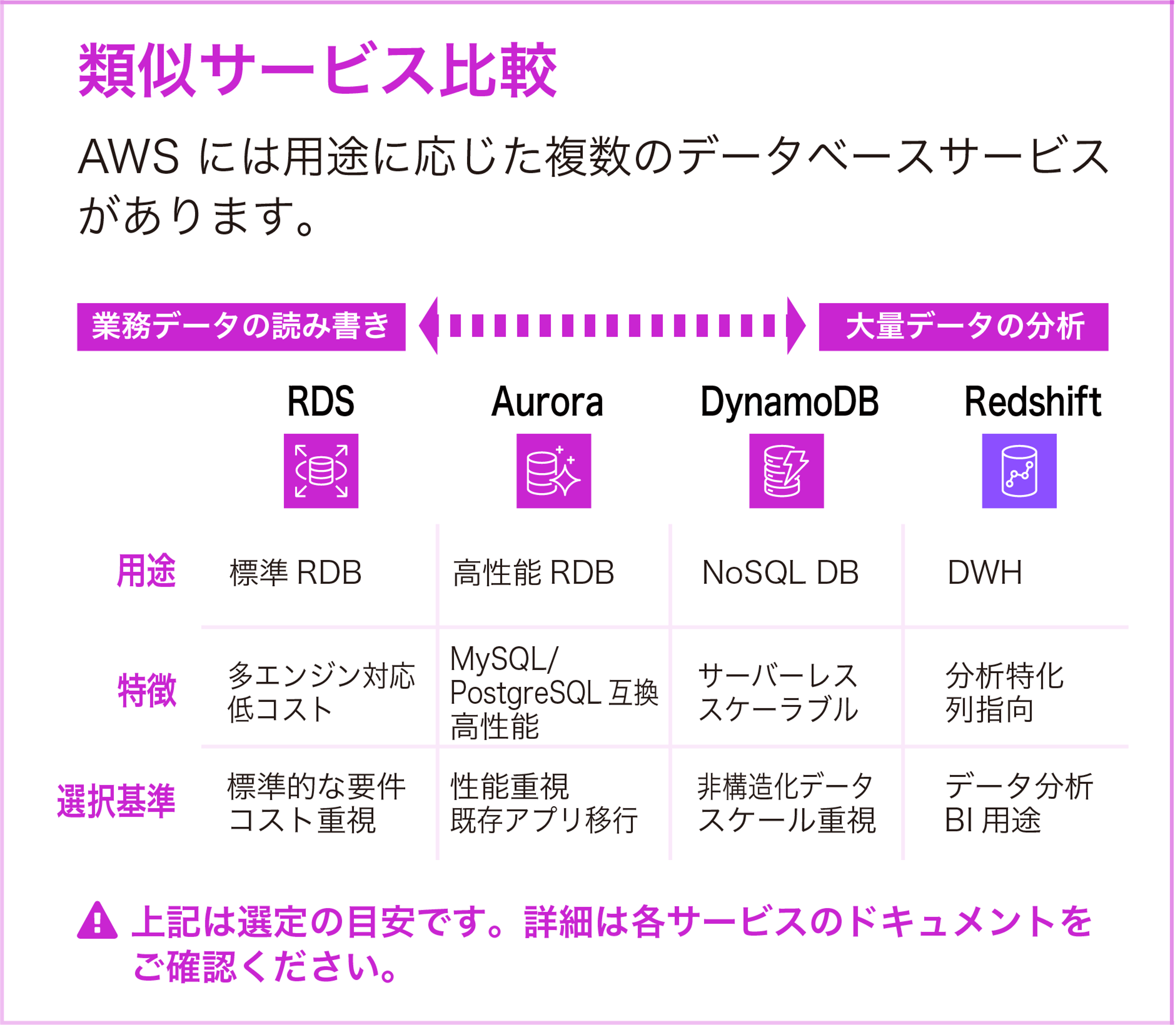
類似サービス比較
AWS には用途に応じた複数のデータベースサービスがあります。業務データの読み書きから大量データの分析まで、ワークロードに最適なサービスを選択することが重要です。
|
サービス
|
用途
|
特徴
|
選択基準
|
|---|---|---|---|
|
Amazon RDS
|
標準 RDB |
多エンジン対応・低コスト |
標準的な要件・コスト重視 |
|
Amazon Aurora
|
高性能 RDB |
MySQL/PostgreSQL 互換・高性能 |
性能重視・既存アプリ移行 |
|
Amazon DynamoDB
|
NoSQL DB |
サーバーレス・スケーラブル |
非構造化データ・スケール重視 |
|
Amazon Redshift
|
DWH |
分析特化・列指向 |
データ分析・BI 用途 |
使い分け方
- Amazon RDS と Aurora の使い分け
Amazon RDS は MySQL、PostgreSQL、MariaDB、Oracle、SQL Server、Db2 の 6 つのエンジンに対応する汎用的なマネージドデータベースサービスです。Aurora は MySQL と PostgreSQL のみですが、独自のストレージエンジンにより高い性能と可用性を提供します。
小 ~ 中規模のワークロードでコストを重視する場合は Amazon RDS、高い性能・可用性・スケーラビリティが求められる場合は Aurora が適しています。Amazon RDS から Aurora への移行は、スナップショットの復元やレプリケーションを使って比較的容易に行えます。 - Aurora と Amazon DynamoDB の使い分け
Amazon DynamoDB はキーバリュー型の NoSQL データベースで、テーブル間の JOIN が不要なワークロードに適しています。複雑なリレーションや SQL による柔軟なクエリが必要な場合は Aurora、単純なキーベースのアクセスパターンで極めて高いスケーラビリティが必要な場合は DynamoDB を選択します。 - Aurora と Amazon Redshift の使い分け
Amazon Redshift は列指向のデータウェアハウスで、大量データの集計・分析に最適化されています。OLTP (トランザクション処理) には Aurora、OLAP (分析処理) には Amazon Redshift が適しています。Aurora の ゼロ ETL 統合を使えば、Aurora のデータを Amazon Redshift にほぼリアルタイムで自動連携でき、ETL パイプラインの構築が不要になります。 - Aurora DSQL
2025 年 5 月に GA となった Amazon Aurora DSQL は、サーバーレスの分散 SQL データベースです。PostgreSQL 互換で、マルチリージョンでの強整合性のある読み書きを実現します。インフラ管理が不要で、単一リージョンで 99.99%、マルチリージョンで 99.999% の可用性を提供します。常時稼働が求められるグローバルアプリケーションに適しています。
詳しくは、公式ドキュメントの「AWS でのデータベースの選択」をご覧ください。
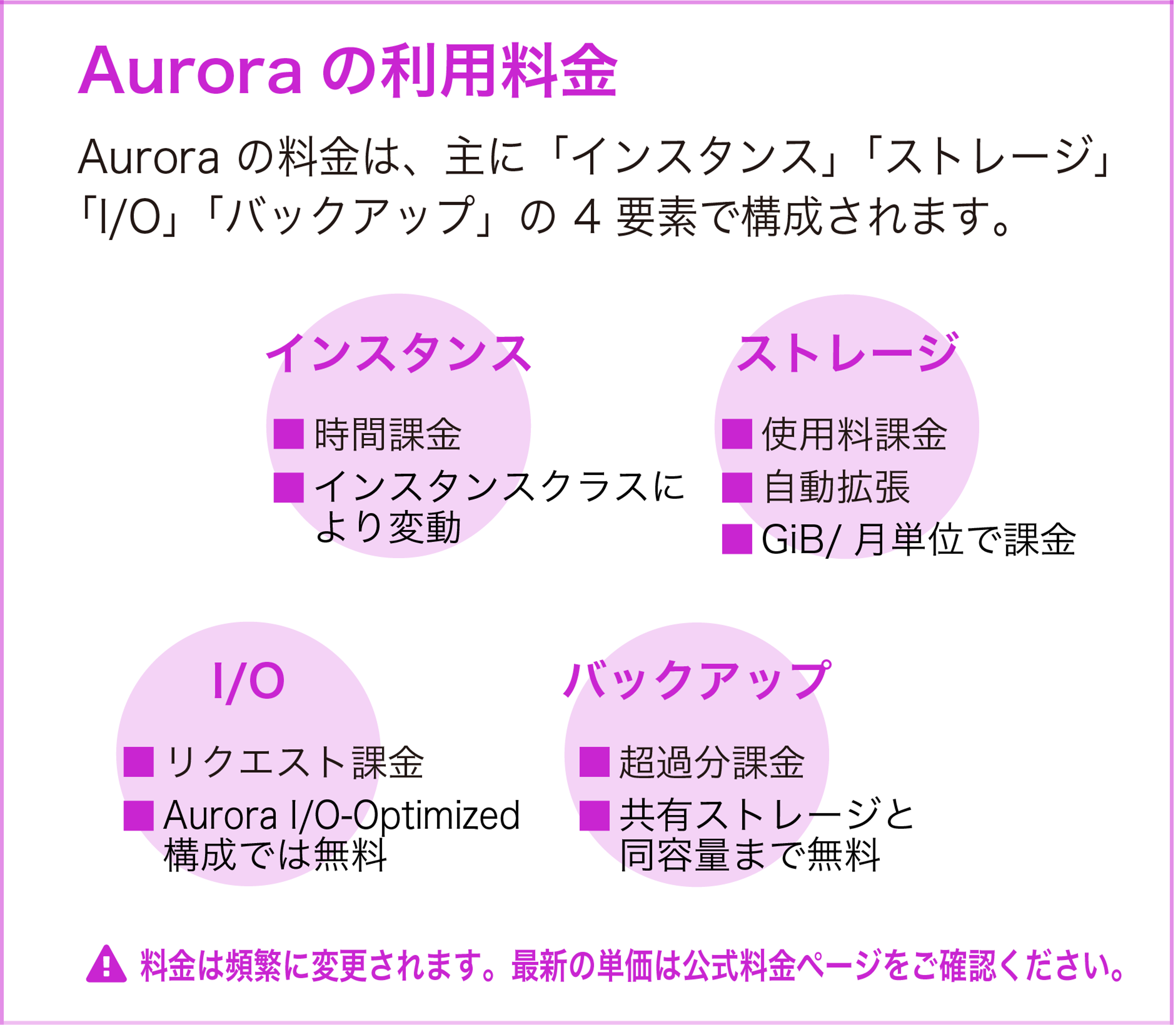
Aurora の利用料金
Aurora の料金は、主に「インスタンス」「ストレージ」「I/O」「バックアップ」の 4 要素で構成されます。
インスタンス料金
DB インスタンスの稼働時間に対して課金されます。料金はインスタンスクラスによって異なり、秒単位 (最低 10 分) で計算されます。Aurora Serverless v2 の場合は ACU 時間単位で課金されます。コスト削減には リザーブドインスタンス (1 年または 3 年の前払い) や Database Savings Plans (Aurora、Amazon RDS、Amazon DynamoDB などを横断して適用可能) が有効です。詳細は 公式料金ページ をご確認ください。
ストレージ料金
使用したストレージ容量に対して GiB/月単位で課金されます。ストレージは自動拡張されるため、事前のプロビジョニングは不要です。データを削除すると使用領域が縮小し、料金も減少します。
I/O 料金
Aurora Standard 構成では、100 万リクエストあたりの料金が発生します。Aurora I/O-Optimized 構成では I/O 料金が無料になります。I/O コストが総コストの 25% 以上を占める場合は I/O-Optimized への切り替えを検討してください。
バックアップ料金
自動バックアップのストレージは、クラスターボリュームの合計サイズと同容量まで無料です。それを超える分と手動スナップショットは GiB/月単位で課金されます。
見落としがちなコスト
- データ転送料金 : 同一リージョン内の AZ 間転送は無料ですが、クロスリージョン転送は有料です。Aurora Global Database のレプリケーションにもクロスリージョン転送料金が発生します。
- RDS Proxy 料金 : RDS Proxy は vCPU 単位で別途課金されます。
- 停止中のクラスター : DB クラスターを停止しても、ストレージとバックアップの料金は引き続き発生します。また、停止状態は最大 7 日間で、その後自動的に再起動されます。
⚠ 料金は頻繁に変更されます。最新の単価は 公式料金ページ をご確認ください。
参考資料
Aurora についてさらに学ぶための公式リソースです。QR コードから各リソースにアクセスできます。
各リソースの使い分け:
- 公式ドキュメント : Aurora の全機能・API・ベストプラクティスを学べる公式リファレンス
- 料金ページ : インスタンス、ストレージ、I/O 料金の詳細。複数リージョンでの料金比較も可能
- AWS ブログ : Aurora のベストプラクティスと最新機能
なお、英語版の公式ドキュメントは日本語版より更新が早い場合があります。最新の仕様確認には英語版も参照することをおすすめします。
⚠ 本記事の内容は作成時点の情報です。料金や仕様は変更される場合があるため、最新情報は公式ドキュメントをご確認ください。
まとめ
最後に、本記事で解説した Aurora の主要な機能とポイントを一枚にまとめた図をご覧ください。ぜひ保存してご活用ください。 Aurora の本質は「MySQL・PostgreSQL 互換のクラウドネイティブなリレーショナルデータベース」です。ストレージとコンピュートの分離アーキテクチャにより、商用データベースを超える高性能、3 AZ × 6 コピーの高耐久性、そして運用の自動化を同時に実現しています。
設計時に押さえておきたいポイント
- インスタンス構成はワークロードに合わせて選択 : 負荷が予測しにくい場合は Aurora Serverless v2 を選択することで、0 ~ 256 ACU の範囲で自動スケーリングが行われます。安定した負荷のワークロードでは、プロビジョンドインスタンスとリザーブドインスタンスの組み合わせがコスト効率に優れます。
- 高可用性はレプリカ配置で確保 : 本番環境では最低 1 台のリードレプリカを別の AZ に配置し、フェイルオーバー時間を最小化してください。RDS Proxy の併用でさらに短縮できます。
- バックアップと復旧戦略を事前に設計 : 自動バックアップの保持期間を適切に設定し、重要な変更前には手動スナップショットを取得してください。Aurora MySQL ではバックトラックも活用できます。
- ストレージ構成とコストの最適化 : Aurora Standard と I/O-Optimized の選択は、I/O コストの割合で判断します。AWS 料金見積りツール で事前に試算することを推奨します。
本記事で紹介した内容
本記事では、Aurora の基本概念 (DB クラスター・インスタンス・共有ストレージ) から、スケーリング方式、リードレプリカとフェイルオーバー、継続的バックアップと PITR、接続エンドポイント、業界別・課題別のユースケース、制限事項、類似サービスとの比較、料金体系までを解説しました。
Aurora は MySQL、PostgreSQL の使い慣れたインターフェースで始められる一方、ストレージ構成の選択やレプリカ設計、コスト最適化など、本番運用では多くの設計判断が求められます。本記事が、その判断の土台となれば幸いです。
筆者プロフィール
米倉 裕基
アマゾン ウェブ サービス ジャパン合同会社
テクニカルライター・イラストレーター
日英テクニカルライター・イラストレーター・ドキュメントエンジニアとして、各種エンジニア向け技術文書の制作を行ってきました。趣味は娘に隠れてホラーゲームをプレイすることと、暗号通貨自動取引ボットの開発です。現在、AWS や機械学習、ブロックチェーン関連の資格取得に向け勉強中です。

監修者プロフィール

伊勢田 氷琴
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
普段は業種業界問わず幅広いお客様の技術支援に携わっています。最近は Strands Agents や Amazon Bedrock AgentCore など AI エージェントの実装技術やビジネスとしての生成 AI 活用に関心を持ち、ブログや講演で積極的に情報発信を行なっています。

三浦 晟太郎
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
普段はエンタープライズのEC業界のお客様を中心に技術支援をしています。学生時代からハッカソンでWebアプリばかり作っていたのでWeb系の技術が得意です。好きなサービスはKiroとAWS CDKです。最近のマイブームは映画をレイトショーで見に行くことです。