Amazon Web Services 한국 블로그
AWS Fargate, Fluentd 및 Amazon Kinesis Data Firehose를 사용한 확장형 로그 솔루션 집계기 구축하기
최신 분산 애플리케이션들은 매일 기가바이트 수준의 로그 데이터를 생산해 낼 수 있는데, Amazon S3에서 Elasticsearch에 이르는 수많은 솔루션을 활용하면 이에 대한 분석과 스토리지 처리는 비교적 어렵지 않게 구현할 수 있지만 로그를 안정적으로 집계하고 최종 대상까지 전송하는 것은 여전히 어려운 영역에 속합니다.
이 게시물에서는 AWS Fargate, Amazon Kinesis Data Firehose 및 Fluentd를 사용하여 로그 집계기를 구축하는 방법을 설명합니다.본 아키텍처에서 중요한 로그 집계기 솔루션의 핵심을 구성하게 될 Fluentd는 로그 수집, 필터링, 버퍼링 및 라우팅을 처리하여 통합된 로깅 계층을 제공하는 것을 목표로 하는 오픈 소스 프로젝트입니다. Fluentd는 여러 클라우드 플랫폼에서 널리 사용되고 있으며 2016년 CNCF( Cloud Native Computing Foundation)에 채택된 솔루션입니다.
AWS Fargate는 Fluentd 집계기를 위한 간단한 컴퓨팅 환경을 제공합니다. 로그를 최종 대상으로 스트리밍하는 Kinesis Data Firehose는 로그를 로드하기 전 데이터를 배치로 만들고 압축, 변환 및 암호화합니다. Kinesis는 대상에서 사용하는 스토리지 양을 최소화하고 보안을 강화해 줍니다.
이 게시물에서 설명하는 로그 집계기는 일반 구성으로서 어떤 유형의 애플리케이션에도 사용할 수 있습니다. 그러나 간결한 설명을 위해 여기에서는 Amazon ECS(Elastic Container Service) 작업 및 서비스에 집계기를 사용하는 방법에 초점을 맞추도록 하겠습니다.
아키텍처 개요

이 다이어그램은 지금 구현하려는 아키텍처를 설명하고 있습니다. Fluentd 집계기는 Network Load Balancer 뒤에 있는 Fargate에서 서비스 형태로 실행됩니다. 이 서비스는 애플리케이션 Auto Scaling을 사용하여 로드의 변경에 따라 동적으로 조정됩니다.
로드 밸런서 DNS는 VPC에서만 해석될 수 있으므로 집계기는 VPC 내에 있는 어떤 애플리케이션의 로그도 수락할 수 있는 프라이빗 로그 수집기가 됩니다. Fluentd는 로그를 Kinesis Data Firehose로 스트리밍하고, Kinesis Data Firehose는 이를 S3 및 Amazon ES(Amazon ElasticSearch Service)에 덤프합니다.
모든 로그가 같은 중요성을 가지는 것은 아닙니다. 일부 로그는 실시간 분석이 필요하지만, 일부 로그는 필요할 때 분석할 수 있도록 장기 보관만으로도 충분합니다. 이 게시물에서는 Fluentd에 로깅하는 애플리케이션을 프런트엔드와 백엔드로 분리합니다.
프런트엔드 애플리케이션은 사용자를 대면하는 애플리케이션으로서 사용자에 대한 통찰력을 얻기 위해 로그에 있는 데이터를 쿼리 및 분석할 수 있는 풍부한 기능을 필요로 합니다. 그러므로 프런트엔드 애플리케이션 로그는 Amazon ES로 전송됩니다.
이와 대조적으로 백엔드 서비스는 동일한 수준의 분석을 필요로 하지 않으므로 해당 로그는 S3로 전송됩니다. 이러한 로그는 Amazon Athena를 사용하여 쿼리하거나, 필요에 따라 다운로드한 후 다른 분석 도구에서 수집할 수 있습니다.
각 애플리케이션은 해당 로그에 태그를 지정하며 Fluentd는 태그에 따라 로그를 서로 다른 대상으로 전송합니다. 따라서, 집계기는 로그 메시지가 백엔드 애플리케이션에서 온 것인지 또는 프런트엔드 애플리케이션에서 온 것인지 파악할 수 있습니다. 각 로그 메시지는 다음 두 가지의 Kinesis Data Firehose 스트림 중 하나로 전송됩니다.
- S3로 가는 스트림
- Amazon ES 클러스터로 가는 스트림
Fargate에서 집계기를 실행하면 이 서비스의 유지 관리가 쉬워지며 인스턴스 프로비저닝 또는 관리에 대해 신경을 쓰지 않아도 됩니다. 이는 집계기의 규모 조정도 간소화해 줍니다. 인스턴스를 위한 추가적인 Auto Scaling 그룹을 관리할 필요가 없습니다.
집계기의 성능 및 처리량
VPC에 Fluentd 집계기를 배포하는 방법을 안내하기 전에 이 집계기의 성능에 대해 알아둘 필요가 있습니다.
이 집계기의 제약사항을 테스트하기 위해 설치 환경에 대해 방대한 실제 테스트를 수행해 보았습니다. 집계기 서비스의 각 작업은 적어도 9MB/s의 로그 트래픽과 초당 10,000개의 로그 메시지를 처리할 수 있습니다. 이는 집계기 성능의 낮은 범위에 수준에 해당하는 수치입니다. 집계기 서비스를 프로비저닝할 때에는 이러한 수치를 사용하여 예상 로그 트래픽 처리량을 기반으로 프로비저닝할 것을 권장합니다.
이 집계기 설치 환경은 동적 조정을 포함하고 있지만, Fluentd의 동적 조정 기능이 복잡하기 때문에 서비스의 최소 크기는 신중하게 선택할 필요가 있습니다.
Fluentd 집계기는 TCP 연결을 통해 로그를 수락하며 이 연결들은 Network Load Balancer에 의해 서비스 인스턴스 전체에 걸쳐 밸런싱됩니다. 그러나 이러한 TCP 연결은 긴 수명을 갖고, 로드 밸런서는 새 TCP 연결만 분산시키기 때문에 집계기가 로드 증가에 대한 응답으로 확장될 때 새 Fargate 작업은 기존 로드에 도움이 되지는 않습니다. 새 작업은 새 TCP 연결만 사용할 수 있습니다. 이는 또한 시간이 흐름에 따라 집계기의 이전 작업들이 연결을 누적하는 경향이 있음을 의미하며, 이는 반드시 인지해야하는 중요한 제약 사항입니다.
ECS 작업이 집계기에 로그를 전송할 때 사용 가능한 Fluentd용 Docker 로깅 드라이버의 경우, 각 컨테이너가 시작할 때 단일 TCP 연결이 설정됩니다. 이 연결은 가능한 오래 동안 열린 상태로 유지됩니다. TCP 연결은 데이터가 전송되고 있으며 네트워크 연결 문제가 없는 한 열린 상태를 유지할 수 있습니다. 새 TCP 연결을 보장하는 유일한 방법은 새 컨테이너를 시작하는 것입니다.
동적 조정은 로그 트래픽이 급증하고 새 TCP 연결이 있을 때에만 도움이 됩니다. ECS 작업과 함께 집계기를 사용하는 경우 동적 조정은 로그 트래픽 급증이 새 컨테이너의 시작으로 인해 발생한 경우에만 유용합니다. 한편, 로그 트래픽 급증이 주기적인 기존 컨테이너의 로그 출력 증가에서 오는 경우에는 동적 조정이 도움이 되지 않습니다.
그러므로, 안정적인 컨테이너 수를 통해 기대할 수 있는 최대 처리량을 기준으로 집계기의 최소 작업 수를 구성하십시오. 예를 들어, 45MB/s의 로그 트래픽을 예상하는 경우 집계기 서비스의 최소 크기를 5개의 작업으로 설정하여 각 작업이 9MB/s의 트래픽을 가져가도록 할 것이 권장됩니다.
참고로, 다음은 다양한 로드에서 단일 집계기에서 확인된 리소스 사용률입니다. 집계기의 작업 크기는 4개의 vCPU 및 8GB의 메모리로 구성되어 있습니다. 보시는 바와 같이 CPU 사용률은 로드에 따라 선형으로 조정되므로 동적 조정은 CPU 사용률을 기반으로 구성됩니다.
단일 집계기 작업의 성능
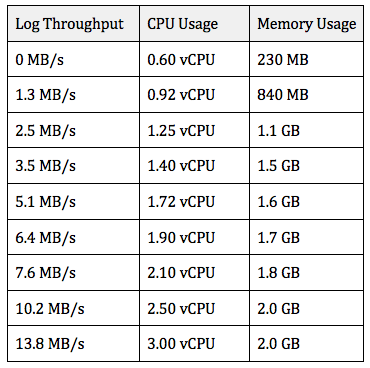
실제 성능은 다를 수 있으므로 이 데이터의 성능이 보장되는 것은 아님에 유의하십시오. 특정 요건에 맞게 Fluentd를 튜닝할 수 있도록 자체 애플리케이션이 제공하는 로그를 사용하여 실제 테스트를 수행할 것을 권장합니다.
주의해야 할 사항 한 가지는 Fluentd 로그에서 재시도 횟수를 언급하는 메시지입니다.
2018-10-24 19:26:54 +0000 [warn]: #0 [output_kinesis_frontend] Retrying to request batch. Retry count: 1, Retry records: 250, Wait seconds 0.35
2018-10-24 19:26:54 +0000 [warn]: #0 [output_kinesis_frontend] Retrying to request batch. Retry count: 2, Retry records: 125, Wait seconds 0.27
2018-10-24 19:26:57 +0000 [warn]: #0 [output_kinesis_frontend] Retrying to request batch. Retry count: 1, Retry records: 250, Wait seconds 0.30
제 경험에 따르면 Kinesis Data Firehose API 한도에 도달할 때마다 이러한 경고가 표시되었습니다. Fluentd는 많은 분량의 로그 데이터를 수락할 수 있지만 Kinesis Data Firehose 한도에 도달하는 경우 데이터가 메모리로 버퍼링됩니다.
이 상태가 장시간 지속되는 경우 버퍼가 최대 크기에 도달할 때 데이터가 결국 손실됩니다. 이 문제를 방지하려면 사용 중인 Kinesis Data Firehose 전송 스트림 수를 늘리거나 Kinesis Data Firehose 한도 증가를 요청합니다.
집계기의 안정성
정상 사용 시에는 로그 메시지의 드롭 또는 중복된 로그 메시지를 볼 수 없었습니다. 서비스의 작업을 중지할 때 작은 양의 로그 데이터 손실이 발생했고, 또한 서비스의 규모가 축소 되었을 때와 Fluentd 구성 업데이트를 위한 배포 작업 시에도 발생했습니다.
작업이 중지되면 SIGTERM이 전송되고 30초 제한 시간 후 SIGKILL이 전송됩니다. Fluentd에서 SIGTERM을 수신하면 인-메모리 버퍼에 보유하고 있는 모든 로그를 전송 대상으로 발송하는 작업을 1회 시도합니다. 이 단일 시도가 실패하면 로그는 손실되므로, 집계기의 초과 프로비저닝을 통해 각 집계기 작업이 버퍼링하는 데이터의 양을 감소시켜 로그 손실을 최소화할 수 있습니다.
또한, Kinesis Data Firehose API 한도 범위 내에 안전하게 유지하는 것이 중요합니다. 이렇게 하면 Fluentd가 이 단일 시도 중에 Kinesis Data Firehose에 모든 데이터를 전송할 수 있는 가능성이 가장 높아집니다.
집계기의 안정성을 테스트하기 위해 ECS에 호스팅된 애플리케이션을 사용하여 초당 수메가바이트 수준의 로그 트래픽을 생성하여 특별한 ‘트레이서’ 메시지를 정상 로그 출력에 삽입했습니다. 로그 스토리지 대상에서 이러한 트레이서 메시지를 쿼리하여 얼마나 많은 메시지가 손실 또는 중복되었는지 확인할 수 있었습니다.
이러한 트레이서 로그는 초당 18개의 메시지 비율로 생성되었습니다. 집계기 서비스를 배포하는 동안(새 서비스를 시작한 후 기존 작업이 모두 중지됨) 평균 2.67개의 트레이서 메시지가 손실되었으며 11.7개의 메시지가 중복되었습니다.
이 데이터에 대해 여러 방식으로 생각해볼 수 있습니다. 1시간 동안 하나의 배포를 실행하면 해당 기간에 로그 데이터의 0.004%가 손실될 것이고, 이는 집계기의 안정성이 99.996%임을 의미합니다. 제 경험에 따르면 작업을 중지하는 것은 약 10초의 짧은 시간 동안 로그 손실만 유발할 뿐입니다.
이를 또다른 시각으로 본다면, 배포 작업 또는 서비스 규모 조정으로 인해 서비스의 작업이 중지될 때마다 평균적으로 해당 작업이 10초 기간에 수신한 로그의 1.5%가 손실됩니다.
위의 사례처럼 집계기가 완벽하지는 않지만 상당히 안정적이라고 볼 수 있습니다. 로그는 집계기 작업을 중지했을 때에만 드롭된다는 점을 명심하시기 바랍니다. 다른 어떤 경우에도 로그 손실이 목격되지 않았습니다. 그러므로, 이 집계기는 많은 프로덕션 워크로드의 로그를 처리를 믿고 맡기기에 충분한 안정성을 보장합니다.
집계기의 배포
다음은 VPC에 로그 집계기를 배포하는 방법입니다.
1. Kinesis Data Firehose 전송 스트림을 생성합니다.
2. VPC 및 네트워크 리소스를 생성합니다.
3. Fluentd를 구성합니다.
4. Fluentd Docker 이미지를 작성합니다.
5. Fargate에 Fluentd 집계기를 배포합니다.
6. 집계기에 로그를 전송하는 ECS 작업을 구성합니다.
Kinesis Data Firehose 전송 스트림 생성
이 게시물에서는 Elasticsearch 도메인과 대상으로 사용 가능한 S3 버킷을 이미 생성했다고 가정합니다.
Amazon ES로 전송하는 전송 스트림을 다음과 같은 옵션과 함께 생성합니다.
- [Delivery stream name]에 “elasticsearch-delivery-stream”을 입력합니다.
- [Source]에 대해 [Direct Put or other sources]를 선택합니다.
- [Record transformation] 및 [Record format conversion]에서는 로그 데이터를 Amazon ES에 전송하기 전에 형식을 변경하도록 활성화합니다.
- [Destination]에 대해 [Amazon Elasticsearch Service]를 선택합니다.
- 필요한 경우 레코드의 S3 백업을 활성화합니다.
- [IAM Role]에 대해 [Create new]를 선택하거나 Kinesis Data Firehose IAM 역할 생성 마법사로 이동합니다.
- IAM 정책에서는 전송 스트림에 적용되지 않는 모든 선언을 제거합니다.
이 스트림을 통해 전송되는 모든 레코드는 동일한 Elasticsearch 유형 아래에 인덱싱되므로 모든 로그 레코드가 동일한 형식을 가지는 것이 중요합니다. 다행히도 Fluentd가 이 작업을 간소화해 줍니다. 자세한 내용은 이 게시물의 Fluentd 구성 섹션을 참조하십시오.
동일한 단계를 다라 S3로 전송하는 전송 스트림을 생성합니다. 이 스트림의 이름을 “s3-delivery-stream”이라고 지정하고 대상으로 S3 버킷을 선택합니다.
VPC 및 네트워크 리소스 생성
ecs-refarch-cloudformation/infrastructure/vpc.yamlGitHub의 AWS CloudFormation 템플릿을 다운로드합니다. 이 템플릿은 두 개의 가용 영역에 걸쳐 분산된 퍼블릭 서브넷 2개 및 프라이빗 서브넷 2개를 가진 VPC를 지정합니다. Fluentd 집계기는 VPC 외부에서 액세스되지 않아야 할 다른 모든 서비스와 함께 프라이빗 서브넷에서 실행됩니다. 백엔드 서비스도 여기에서 실행될 것입니다.
이 템플릿은 프라이빗 서브넷의 서비스가 인터넷의 엔드포인트를 호출할 수 있도록 해 주는 NAT 게이트웨이를 구성합니다. 이는 VPC에서 외부로 가는 일방 통신을 허용하지만 수신 트래픽은 차단합니다. 이 점이 중요합니다. 집계기 서비스는 VPC에서만 액세스 가능해야 하지만 VPC 외부에 상주하는 Kinesis Data Firehose API 엔드포인트를 호출할 수 있어야 합니다.
다음 명령으로 템플릿을 배포합니다.
Fluentd 구성
Fluentd 집계기는 VPC 내의 다른 서비스로부터 로그를 수집합니다. 이러한 서비스가 모두 Fluentd docker 로그 드라이버를 사용하는 Docker 컨테이너에서 실행된다고 가정했을 때, 집계기가 수집하는 각 로그 이벤트는 다음 예와 같은 형식을 가집니다.
이 로그 이벤트는 ECS의 컨테이너에서 실행되는 Apache 서버의 로그 이벤트입니다. 서버가 로깅한 줄은 로그 필드에 캡처되며 [source], [container_id] 및 [container_name]은 Fluentd Docker 로깅 드라이버에서 추가하는 메타데이터입니다.
앞에서 언급되었듯이, 전송 스트림에서 Amazon ES로 전송하는 모든 로그 이벤트는 동일한 형식이어야 하며, 로그 이벤트는 Elasticsearch 유형으로 변환될 수 있도록 JSON 형식이어야 합니다. Fluentd Docker 로깅 드라이버는 이 두 가지 요구 사항을 모두 충족합니다.
Fluentd 로그를 다른 형식으로 배출하는 애플리케이션이 있는 경우에는 전송 스트림에 Lambda 함수를 사용하여 모든 로그 레코드를 일반 형식으로 변환할 수 있습니다.
또는, 각 애플리케이션 유형 및 로그 형식에 서로 다른 전송 스트림을 사용하여 각 로그 형식이 Amazon ES 도메인의 서로 다른 유형과 일치하도록 설정할 수 있습니다. 간결한 설명을 위해 이 게시물에서는 모든 프런트엔드 및 백엔드 서비스가 ECS에서 실행되며 Fluentd Docker 로깅 드라이버를 사용한다고 가정합니다.
이제 Fluentd 구성 파일인 fluent.conf를 생성합니다.
이 파일은 이 게시물을 위한 모든 코드와 함께 여기에서 찾을 수 있습니다. 첫 번째 세 줄은 Fluentd가 4개의 작업자를 사용할 것을 지시합니다. 이는 최대 4개의 CPU 코어를 사용할 수 있음을 의미합니다. 나중에 각 Fargate 작업이 4개의 vCPU를 가지도록 구성합니다. 나머지 구성은 집계기가 처리하는 로그의 소스와 대상을 정의합니다.
나열된 첫 번째 소스는 기본 소스입니다. VPC의 모든 애플리케이션은 이 소스 정의를 사용하여 Fluentd에 로그를 전달합니다. 이 소스는 Fluentd에 포트 24224의 로그를 수신할 것을 지시합니다. 로그는 이 포트에서 TCP 연결을 통해 스트리밍됩니다.
두 번째 소스는 포트 8888을 수신하는 http Fluentd 플러그인입니다. 이 플러그인은 http를 통해 로그를 수락하지만 이는 컨테이너 상태 확인에만 사용됩니다. Fluentd는 상태 확인 기능이 내장되어 있지 않기 때문에 여기에서는 curl을 통해 http 플러그인에 로그 메시지를 전송하는 컨테이너 상태 확인 기능을 생성했습니다. 이는 Fluentd가 로그 메시지를 수락할 수 있다면 상태가 정상일 것이라는 논리에 기반합니다. 다음은 컨테이너 상태 확인에 상용된 명령입니다.
URL의 쿼리 파라미터는 다음과 같은 형태의 URL 인코딩된 JSON 객체를 정의합니다.
컨테이너 상태 확인은 “health check”라는 로그 메시지를 입력합니다. URL의 쿼리 파라미터가 로그 메시지를 정의하는 반면, 경로(/healthcheck)는 로그 메시지에 대한 태그를 설정합니다. Fluentd에서는 로그 메시지에 태그가 지정되어 서로 다른 대상으로 메시지가 라우팅될 수 있도록 합니다.
여기에서는 태그가 healthcheck입니다. 구성 파일에서 볼 수 있듯이, 첫 번째 <match> 정의는 health* 패턴과 일치하는 태그를 가진 로그를 처리합니다. 각 <match> 요소는 태그 패턴을 정의하고 해당 패턴과 일치하는 태그를 가진 로그의 대상을 정의합니다. 상태 확인 로그의 경우에는 이러한 더미 로그를 어디에도 저장하지 않을 것이므로 대상은 null입니다.
이 게시물의 집계기에 로그를 전송하는 ECS 작업 구성 섹션은 Fluentd docker 로깅 드라이버에 로그 태그가 정의되는 방식을 설명하고 있습니다. 다른 <match> 요소는 VPC 내의 애플리케이션에 대한 로그를 처리하고 이를 Kinesis Data Firehose에 전송합니다.
이 중 하나는 “frontend”로 시작하는 모든 로그 태그와의 일치를 찾으며 다른 하나는 “backend”로 시작하는 모든 태그와의 일치를 찾습니다. 각 요소는 서로 다른 전송 스트림으로 로그를 전송합니다. 프런트엔드 서비스와 백엔드 서비스는 자체 로그에 태그를 지정하고 서로 다른 대상으로 이를 전송할 수 있습니다.
Fluentd는 Kinesis Data Firehose 지원 기능을 내장하고 있지 않으므로 AWS에서 유지 관리하는 오픈 소스 플러그인(awslabs/aws-fluent-plugin-kinesis)을 사용하도록 합니다.
마지막으로, 각 Kinesis Data Firehose <match> 태그는 <buffer> 요소를 사용하여 버퍼 설정을 정의합니다. Kinesis 출력 플러그인은 필요한 경우 데이터를 인-메모리에 버퍼링합니다. 이러한 설정은 처리량을 늘리고 데이터 손실의 가능성을 최소화하도록 조정되어 있지만, 자체 테스트를 기반으로 필요에 따라 수정해야 합니다. 이 설치 환경의 처리량 및 성능에 대한 논의는 이 게시물의 집계기 성능 및 처리량 섹션을 참조하십시오.
Fluentd Docker 이미지 작성
Dockerfile을 다운로드하여 앞에서 설명한 fluentd.conf 파일과 같은 디렉터리에 배치합니다. Dockerfile은 Alpine 기반의 최신 Fluentd 이미지와 함께 시작하며 awslabs/aws-fluent-plugin-kinesis 및 curl을 설치합니다(앞에서 논의한 컨테이너 상태 확인용)
같은 디렉터리에서 /plugins라는 이름의 빈 디렉터리를 생성합니다. 이 디렉터리는 비워 두지만 Fluentd Docker 이미지를 작성할 때 필요합니다. 사용자 지정 Fluentd Docker 이미지의 작성에 대한 자세한 내용은 DockerHub의 Fluentd 페이지를 참조하십시오.
이미지 작성하고 태그를 지정합니다.
Fargate 서비스에서 사용할 수 있도록 이미지를 ECR 리포지토리로 푸시합니다.
Fargate에 Fluentd 집계기 배포
집계기 서비스에 필요한 모든 리소스를 정의하는 CloudFormation 템플릿을 다운로드합니다. 여기에는 Network Load Balancer, 대상 그룹, 보안 그룹 및 작업 정의가 포함됩니다.
먼저 클러스터를 생성합니다.
두 번째로 Amazon ECS 작업 실행 IAM 역할을 생성합니다. 이렇게 하면 Fargate 작업이 ECR에서 Fluentd 컨테이너 이미지를 가져올 수 있습니다. 또한 이렇게 하면 Fluentd 집계기 작업이 Amazon CloudWatch에 로그를 생성할 수 있는데 Fluentd는 순환 의존성으로 인해 자체 로그를 관리할 수 없기 때문에 이 부분이 중요합니다
그런 다음 템플릿을 VPC 및 앞에서 생성한 프라이빗 서브넷으로 시작할 수 있습니다. 필수 정보는 파라미터로 추가합니다.
MinTasks는 2로 설정되고 MaxTasks는 4로 설정됩니다. 이는 집계기가 적어도 2개의 작업을 항상 가져야 함을 의미합니다.
로드가 증가하면 동적으로 최대 4개의 작업까지 확장될 수 있습니다. 집계기 성능 및 처리량에 대한 논의를 상기하면서 자체적으로 예상하는 로그 처리량을 기반으로 이러한 값을 설정하십시오.
집계기에 로그를 전송하는 ECS 작업 구성
먼저, CloudFormation 템플릿의 의해 생성된 로드 밸런서의 DNS 이름을 가져옵니다. EC2 콘솔에서 [로드 밸런서]를 선택합니다. 로드 밸런서는 EnvironmentName 파라미터와 동일한 값을 가집니다. 여기에서 이 값은 fluentd-aggregator-service입니다.
logConfiguration에 대한 적절한 값을 추가하여 Fluentd 집계기에 로그를 전송하는 컨테이너에 대한 컨테이너 정의를 생성합니다. 다음 예에서 fluentd-address 값을 자체 로드 밸런서에 대한 DNS 이름으로 대체하십시오. 집계기는 TCP 포트 24224를 수신하므로 DNS 이름 뒤에 :24224를 추가했는지 확인합니다.
태그 값이 frontend-apache인 것에 유의하십시오. 이것이 앞에서 논의한 태그가 설정되는 방식입니다. 이 태그는 Fluentd 집계기가 “frontend” 로그를 전송 스트림에 전송할 수 있도록 패턴 frontend*과 일치하는 로그를 찾습니다.
마지막으로, 컨테이너 인스턴스는 ECS 에이전트에서 Fluentd 로그 드라이버를 활성화하기 위해 다음과 같은 사용자 데이터가 필요합니다.
결론
이 게시물에서는 AWS Fargate, Amazon Kinesis Data Firehose 및 Fluentd를 사용하여 로그 집계기를 구축하는 방법을 보여드렸습니다.
ECS에서 실행되지 않는 애플리케이션과 함께 집계기를 사용하는 방법을 배우려면 Fluentd 관리자인 Kiyoto Tamura의 All Data Are Belong to AWS: Streaming upload via Fluentd를 읽어 보시기 바랍니다.
– Wesley Pettit, AWS ECS CLI 소프트웨어 엔지니어
이 글은 AWS Compute 블로그의 Building a scalable log solution aggregator with AWS Fargate, Fluentd, and Amazon Kinesis Data Firehose 한국어 번역입니다.