Amazon Web Services 한국 블로그
AQUA(Advanced Query Accelerator) 정식 출시 – Amazon Redshift 쿼리 속도 향상
Amazon Redshift는 이미 다른 클라우드 데이터 웨어하우스보다 규모에 관계없이 최대 3배 향상된 가성비를 제공합니다. 우리는 자체 하드웨어를 설계하고 기계 학습(ML)을 사용하여 이를 수행합니다.
예를 들어 2019년 말에 Amazon Redshift용 SSD 기반 RA3 노드를 시작했으며(Amazon Redshift 업데이트 – 차세대 컴퓨팅 인스턴스 및 관리형 분석 최적화 스토리지), 지난 4월(Amazon Redshift 업데이트 – ra3.4xlarge 노드) 및 지난 12월(Amazon Redshift가 관리형 스토리지로 RA3.xLPlus 노드를 시작)에 노드 크기를 추가했습니다. RA3 노드에는 고대역폭 네트워킹 외에도 정교한 데이터 관리 모델이 통합되어 있습니다.
각 인스턴스에서 S3로 지원되는 대용량 캐시의 고성능 SSD 기반 스토리지를 사용하여 확장성, 성능 및 내구성을 개선할 수 있습니다. 이 스토리지 시스템은 데이터 블록 사용 빈도, 데이터 블록 수명 및 워크로드 패턴을 비롯한 다수의 신호를 사용하여 캐시를 관리함으로써 고성능을 보장합니다. 적절한 계층으로 데이터가 자동 배치되므로 캐싱 또는 기타 최적화를 직접 수행할 필요가 없습니다.
AWS 고객은 RA3 노드를 사용하여 대용량 데이터 세트를 유지 관리하며 훌륭한 결과를 얻고 있습니다. 디지털 대화형 엔터테인먼트부터 미디어 구매에 대한 노출 수 및 성능 추적에 이르기까지 Amazon Redshift 및 RA3 노드는 고객이 단일 데이터 웨어하우스에 최대 32PB의 데이터를 사용하여 세계 규모로 데이터를 저장하고 쿼리할 수 있도록 지원합니다.
단점은 데이터 웨어하우스가 계속 증가함에 따라 스토리지 성능 향상이 CPU 성능보다 훨씬 뛰어나다는 것입니다. 대량의 데이터(대개 전체 검색을 수행하는 쿼리에서 액세스함)와 네트워크 트래픽 제한을 결합하면 네트워크 및 CPU 대역폭이 제한적인 요소가 되는 상황이 발생할 수 있습니다.
AQUA 소개
 이제 AQUA (Advanced Query Accelerator) 를 추가하여 ra3.4xl 및 ra3.16xl 노드를 더욱 강력하게 만들 수 있습니다. 앞서 말씀드린 캐시를 기반으로 AWS Nitro System과 사용자 지정 FPGA 기반 가속을 활용하여 AQUA 는 감소 및 집계 쿼리를 데이터에 더 가깝게 처리하는 데 필요한 계산을 처리합니다.
이제 AQUA (Advanced Query Accelerator) 를 추가하여 ra3.4xl 및 ra3.16xl 노드를 더욱 강력하게 만들 수 있습니다. 앞서 말씀드린 캐시를 기반으로 AWS Nitro System과 사용자 지정 FPGA 기반 가속을 활용하여 AQUA 는 감소 및 집계 쿼리를 데이터에 더 가깝게 처리하는 데 필요한 계산을 처리합니다.
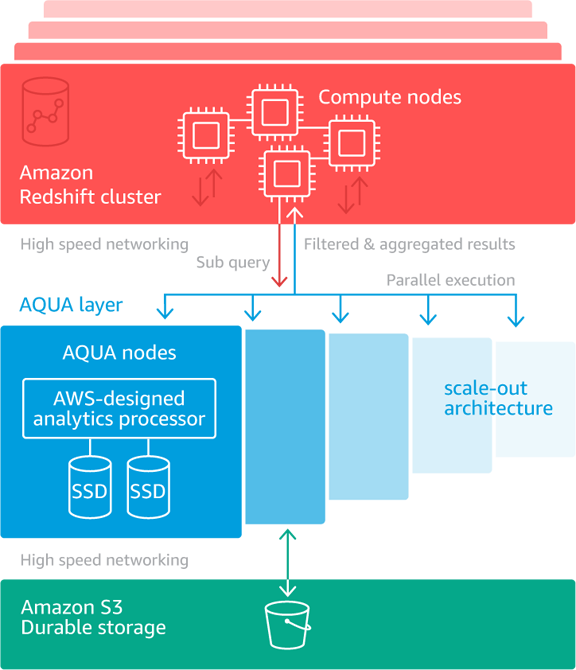
이렇게 하면 네트워크 트래픽이 줄어들고 RA3 노드의 CPU에서 작업이 오프로드되며 AQUA가 추가 비용 없이 코드 변경 없이 해당 쿼리의 성능을 최대 10배까지 향상시킬 수 있습니다. 또한 AQUA는 Amazon Simple Storage Service (S3)에 대한 고속 고대역폭 연결을 사용합니다.
AQUA 노드에서 사용자 지정 설계된 하드웨어를 사용하여 쿼리를 가속화하는 방법에 대해 자세히 알아보려면 비디오를 시청할 수 있습니다. 이 혜택은 여러 가지 방법으로 제공됩니다. 각 노드는 다른 노드와 병렬로 축소 및 집계 작업을 수행합니다. 병렬 처리로 인해 n 배의 속도 향상을 얻는 것 외에도 컴퓨팅 노드로 보내고 처리해야 하는 데이터의 양은 일반적으로 훨씬 작습니다(종종 원본의 5% 에 불과함). 다음은 쿼리를 가속화하기 위해 모든 요소가 어떻게 결합되는지 보여주는 다이어그램입니다.
이미 ra3.4xl 또는 ra3.16xl 노드를 사용하여 데이터웨어 하우스를 호스팅하는 경우 몇 분만에 AQUA 사용을 시작할 수 있습니다. 클러스터에 AQUA 기능을 활성화하고 다시 시작하면 감소 및 집계 쿼리에 대해 크게 향상된 성능을 활용할 수 있습니다. RA3 및 AQUA의 새로운 기능을 사용할 준비가 된 경우 기존 클러스터의 스냅샷에서 새 RA3 기반 클러스터를 만들거나 Classic 크기 조정을 사용하여 현재 위치 업그레이드를 수행할 수 있습니다.
AQUA 사용해 보기
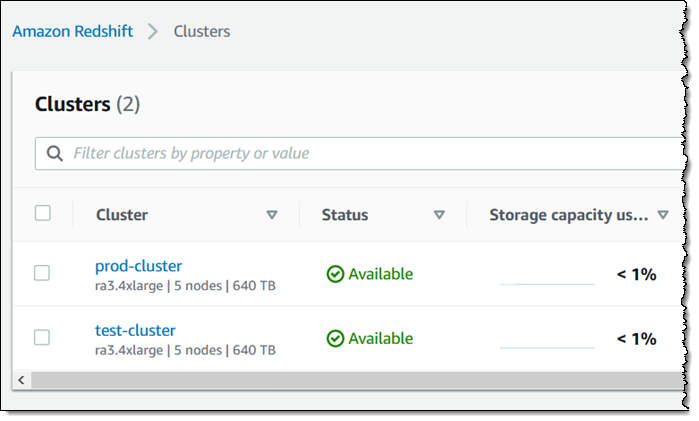
저는 Redshift 팀에서 제공하는 스냅샷을 사용하여 한 쌍의 클러스터를 만들었습니다. 첫 번째 클러스터(prod-cluster)에는 AQUA가 활성화되어 있지 않고 두 번째 클러스터(test-cluster)는 다음을 수행합니다.
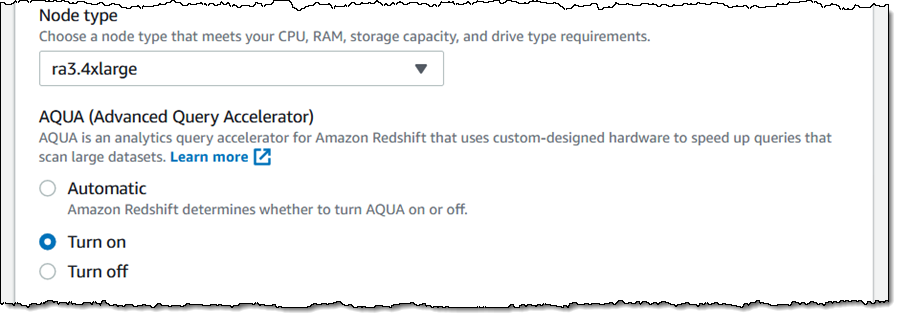
AQUA 사용 클러스터를 만들려면 클러스터 구성 페이지에서 켜기를 선택하면 됩니다.
본 쿼리는 18억 개 이상의 행을 가진 lineitem 테이블을 사용합니다.
각 클러스터에 세션을 만들고 Redshift 결과 캐시를 비활성화합니다.
그런 다음 두 클러스터 모두에서 동일한 쿼리를 실행합니다.
위의 다이어그램을 살펴보고 비디오를 시청하면 AQUA가 이 유형의 쿼리를 매우 효율적으로 처리할 수 있는 이유를 알 수 있습니다. AQUA는 계산 노드에서 18억 개 이상의 행을 순차적으로 검색하는 대신 similar to 표현식의 컬렉션을 여러 AQUA 노드에 배포하여 병렬로 실행됩니다.
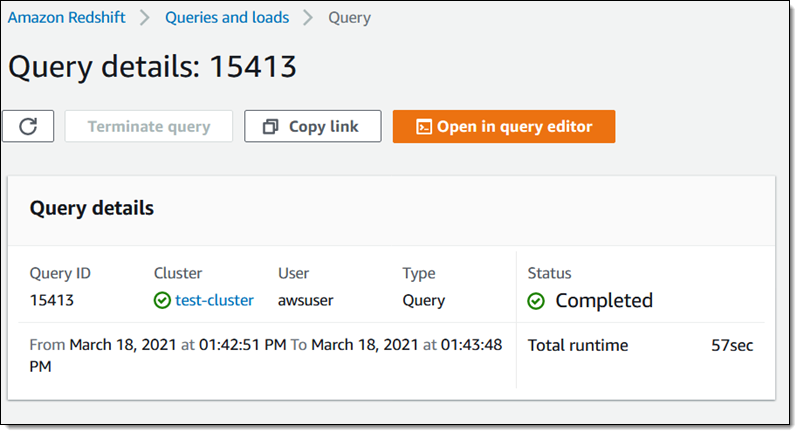
AQUA가 활성화된 클러스터의 쿼리가 1분 이내에 완료됩니다.
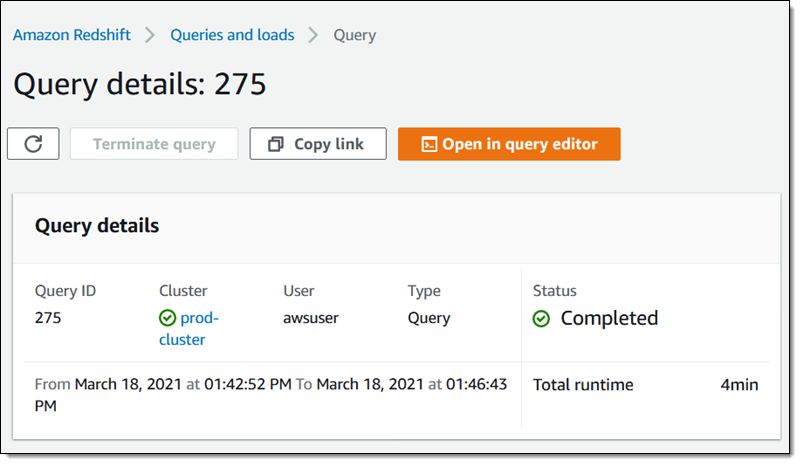
AQUA가 활성화되지 않은 클러스터의 쿼리는 4분 이내에 완료됩니다.
데이터베이스, 복잡한 데이터 및 똑같이 복잡한 쿼리의 경우와 마찬가지로 마일리지는 다양합니다. 예를 들어, 여러 테이블에서 선택(SELECT)된 행의 복잡한 JOIN을 수행한 쿼리를 상상할 수 있습니다. 각 SELECT가 AQUA의 이점을 누릴 수 있으며 전반적인 속도 향상이 훨씬 클 수 있습니다. 이 게시물에 사용한 간단한 쿼리에서 알 수 있듯이 AQUA는 쿼리 시간을 크게 단축시킬 수 있으며 과거에는 불가능하거나 실용적이지 않은 새로운 유형의 실시간 쿼리를 사용할 수도 있습니다.
주요 사항
다음은 AQUA에 대한 몇 가지 흥미로운 사실입니다.
클러스터 버전 — AQUA 를 사용하려면 클러스터가 Redshift 버전 1.0.24421 이상을 실행해야 합니다. AQUA 활성화 및 비활성화 방법에 대한 자세한 내용은 AQUA 클러스터 관리를 참조하십시오.
관련 쿼리 – AQUA는 LIKE 및 SIMILAR_TO 조건자를 사용하여 대규모 검색, 집계 및 필터링을 수행하는 쿼리에 대해 최대 10배의 성능을 제공하도록 설계되었습니다. 시간이 지남에 따라 추가 쿼리에 대한 지원이 추가될 것으로 예상됩니다.
보안– AQUA에서 캐시한 모든 데이터는 키를 사용하여 암호화됩니다. 필터링 또는 집계 작업을 수행한 후 AQUA는 결과를 압축하고 암호화한 다음 Redshift로 반환합니다.
리전 – AQUA는 현재 미국 동부(버지니아 북부), 미국 서부(오레곤), 미국 동부(오하이오), 유럽(아일랜드) 및 아시아 태평양(도쿄) 리전에서 사용 가능하며 2021년 상반기에는 유럽(프랑크푸르트), 아시아 태평양(시드니) 및 아시아 태평양(싱가포르) 리전에서도 사용 가능합니다.
요금 – 앞서 언급했듯이 AQUA에 대한 추가 요금은 없습니다.
AQUA 사용해 보기
ra3.4xl 또는 ra3.16xl 노드를 사용하여 Redshift 클러스터를 활용하는 경우 AQUA 를 활성화하고 클러스터를 다시 시작하고 몇 분 이내에 일부 테스트 쿼리를 실행할 수 있습니다. AQUA를 체험하신 후에 어떤 느낌이신지 알려주세요!
— Jeff;
Update – 2021년 9월 30일 아시아 태평양(서울) 리전에서도 사용 가능합니다.