Amazon Web Services 한국 블로그
Amazon Kendra, AI기반 기업형 사내 검색 서비스 정식 출시
AWS는 2019년 말에 정확도가 높고 사용이 용이한 기계 학습 기반 엔터프라이즈 검색 서비스인 Amazon Kendra 평가판 버전을 출시했습니다. 오늘 Amazon Kendra 정식 버전의 출시를 발표합니다!
과거 몇십 년 동안 이룩한 놀라운 성과에도 불구하고 아직도 정보 기술 분야는 필요한 정보를 빠르고 쉽게 찾아야 하는 문제를 여전히 가지고 있습니다. 특히, 사내에 많이 흩어져 있는 자료 중에서 최신 회사 출장 정책을 찾거나, 기술적인 질문은 정확한 답변을 즉시에 받기 어렵습니다.
IDC 연구에 따르면 비효율적인 검색에 드는 비용이 직원당 연간 5,700 USD가 넘습니다. 직원이 1,000명인 회사라면 매년 570만 USD가 낭비되게 됩니다. 정확도가 낮은 검색으로 인한 법적 책임 및 규정 준수 위험도 따릅니다.
여기에는 몇 가지 원인이 있습니다. 첫째, 대부분의 기업 내 데이터는 구조화되어 있지 않아 필요한 정보를 정확하게 찾아내기가 어렵습니다. 둘째, 대부분의 경우 데이터가 조직의 여러 저장소에 분산되고 네트워크 공유, 관계형 데이터베이스, 타사 애플리케이션 등 이질적인 백엔드에 저장됩니다. 마지막으로, 키워드 기반 검색 시스템은 올바른 키워드 조합을 알아내야 하며 일반적으로 다수의 맞춤 항목을 반환하지만 그중 대부분이 원래 검색 키워드와 관련이 없는 것이 대부분입니다.
AWS는 이러한 문제점을 고려하여 고객이 원하는 사내 검색 기능을 구축하도록 지원하기로 하고, Amazon Kendra를 개발했습니다.
Amazon Kendra 소개
Amazon Kendra를 사용하면 단 몇 번의 클릭으로 파일 시스템, 애플리케이션, 인트라넷, 관계형 데이터베이스와 같은 다양한 백엔드에 조직이 구조화된/구조화되지 않은 데이터를 인덱싱할 수 있습니다. 모든 데이터는 HTTPS를 사용하여 즉석에서 암호화되며 저장된 데이터는 AWS Key Management Service(KMS)를 사용하여 암호화할 수 있습니다.
Amazon Kendra는 IT(예: “VPN을 설정하려면 어떻게 해야 합니까?”), 의료 및 생명 과학(예: “ALS의 유전적 표지는 무엇입니까?”) 같은 영역과 그 외 다양한 영역의 복잡한 언어를 이해하도록 최적화되었습니다. 여러 영역을 아우르는 전문 지식을 통해 Kendra는 더 정확한 답변을 찾습니다. 또한, 개발자는 권위 있는 데이터 원본 또는 문서 최신성과 같은 기준을 사용하여 결과의 관련성을 명시적으로 조정할 수 있습니다.
Kendra 검색은 AWC 콘솔에서 제공하는 코드 샘플 또는 API를 통해 모든 애플리케이션(검색 페이지, 채팅 앱, Chatbot 등)에 빠르게 배포할 수 있습니다. Kendra의 탁월한 시맨틱 검색을 사용하면 단 몇 분 이내에 검색을 시작하여 실행할 수 있습니다.
오늘날 대부분의 조직은 Amazon Kendra를 이미 사용하고 있습니다. 예를 들어, Allen Institute는 뇌, 인간 세포 및 면역 체계에서 인간 생물학의 미지 분야를 연구하면서 생명 과학의 가장 큰 미스터리를 해결하기 위해 노력하고 있습니다. Allen Institute for AI의 최고 경영자인 Dr. Oren Etzioni 씨는 다음과 같이 전합니다. “Amazon Kendra와 같은 AI가 지금 당장 할 수 있는 가장 영향력 있는 일 중 하나는 과학자, 학자 및 기술자가 방대한 과학 문헌에서 올바른 정보를 신속하게 찾고 중요한 연구를 더 빨리 진행하도록 돕는 것입니다. Allen Institute for AI의 Semantic Scholar 팀은 우리의 파트너와 함께 CORD-19를 대비하고 이 막중한 문제에 맞서기 위해 이러한 리소스를 활용할 수 있도록 커뮤니티가 구축하고 있는 AI 리소스를 지원하는 것을 자랑스럽게 생각합니다.”
Amazon Kendra의 새로운 기능 소개
AWS는 평가판 단계에서 수집한 고객 피드백을 기반으로 Amazon Kendra에 다음 기능을 추가했습니다.
- 엔터프라이즈 에디션 및 새로 소개된 개발자 에디션의 조정 옵션(아래 자세한 내용 참조).
- 3개의 새 클라우드 커넥터: OneDrive, Salesforce 및 ServiceNow(기존의 S3, RDS 및 SharePoint Online에 더해 추가됨)
- 8개 새로운 영역에 대한 전문 지식: 자동차, 의료, HR, 법, 미디어 및 엔터테인먼트, 뉴스, 전기 통신, 여행 및 레저(기존의 화학, 에너지, 금융, 보험, IT 및 제약에 더해 추가됨)
- 빨라진 인덱싱과 개선된 정확성
Amazon Kendra를 사용하여 데이터 인덱싱
이 데모를 위해 Wikipedia의 일부(약 50,000페이지)를 다운로드했습니다. HTML 형식의 개별 파일을 Amazon Simple Storage Service(S3) 버킷에 업로드했습니다.
Kendra 콘솔로 이동하여 새 인덱스를 생성하고 이름과 설명을 지정합니다. 클릭 한 번으로 AWS Key Management Service(KMS)를 사용한 암호화를 활성화합니다.
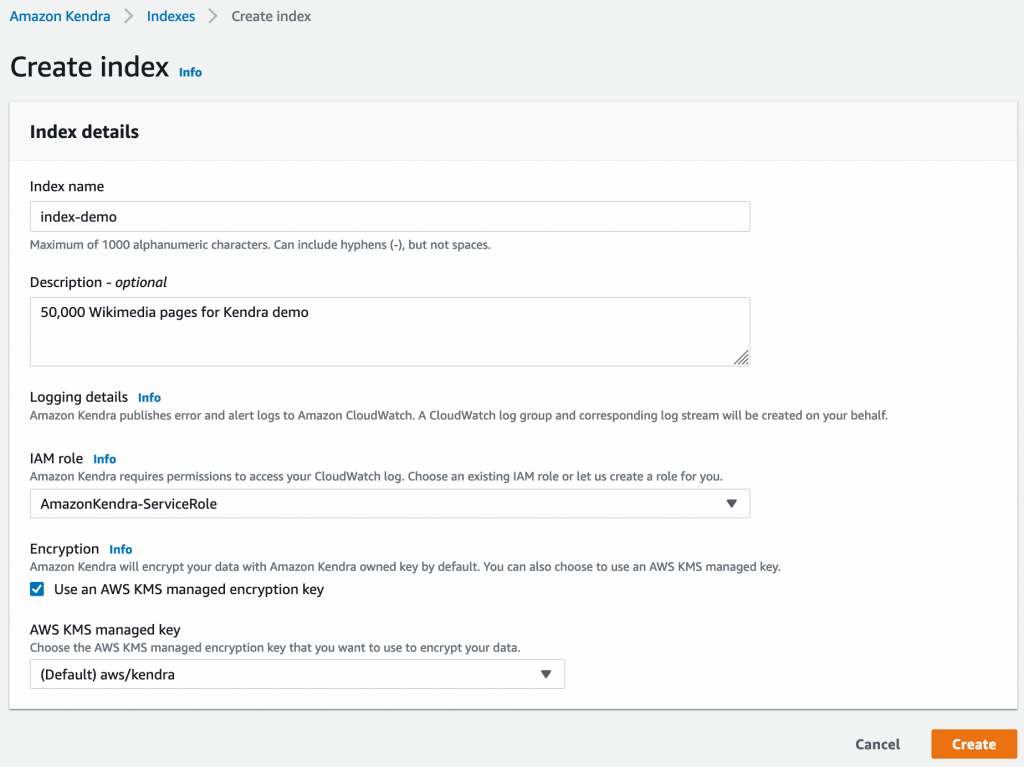
30분가량 지나면 인덱스를 사용할 수 있습니다. 이제 인덱스에 데이터 원본을 추가할 수 있습니다.

S3 버킷을 추가하기는 매우 쉽습니다. 먼저 데이터 원본의 이름을 입력합니다.
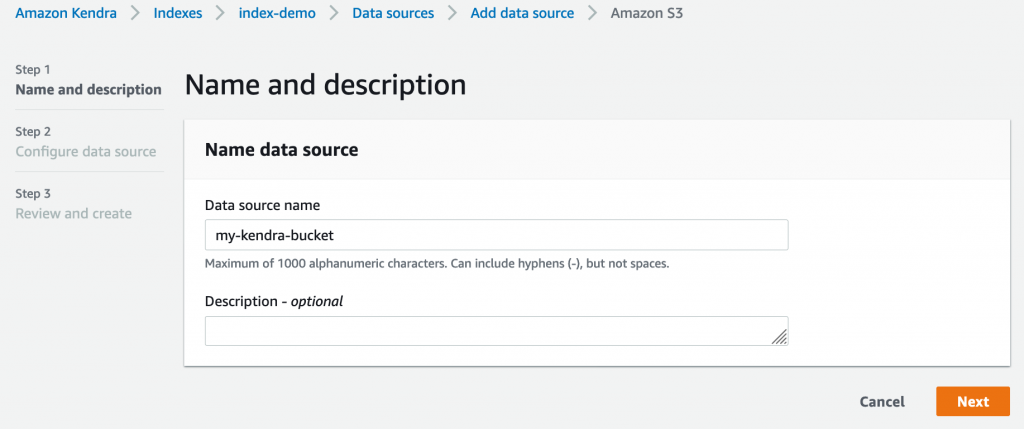
그런 다음, S3 버킷의 이름을 정의합니다. 기존 역할을 선택하거나 새 역할을 생성하여 Kendra에서 사용할 IAM 역할의 이름도 지정해야 합니다.
데이터 원본에 추가된 새 데이터로 인덱스를 새로 고침하기 위해 정기적 간격으로 동기화가 수행되도록 예약하는 옵션이 있습니다. 매일 자정에 새로 고침이 실행되도록 설정합니다.

다음 화면에서는 모든 파라미터를 검토하고 데이터 원본을 생성할 수 있습니다. 화면이 활성화되면 “지금 동기화” 버튼을 클릭하여 최초 동기화를 시작합니다.
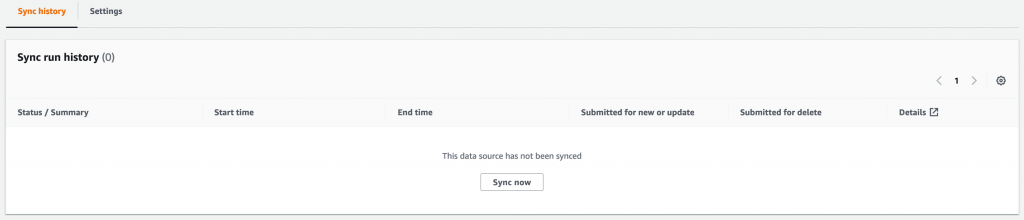
잠시 후 동기화가 완료됩니다. 이제 테스트 창으로 이동하여 인덱스에 대해 쿼리를 실행할 수 있습니다.
Amazon Kendra를 사용한 데이터 질의
일전에 제 게시물 중 하나로 작업하는 동안 Thad Jones라는 뮤지션이 연주하는 재즈 곡을 들었습니다. 재즈 연주자에 대해 아무것도 모르기 때문에 연주자에 대해 자세히 알아보는 데 Kendra가 도움을 줄 수 있는지 궁금합니다.

당연히 이 쿼리는 다수의 문서와 일치합니다. 그러나 Kendra는 제 쿼리에 대해 신뢰도가 높은 제안 답변을 제공합니다. 제안 답변은 인덱싱된 페이지 중 하나에 있는 특정 단락을 가리킵니다. 편리하게도 관련 콘텐츠가 강조 표시되며 제 쿼리에 대한 올바른 답변임을 바로 알 수 있습니다. 더 이상 검색할 필요가 없습니다. 정말로 좋은 답변이라는 것을 알 수 있도록 Amazon Kendra에 ‘좋아요’ 표시를 합니다.
Thad Jones에 대해 더 알아보려고 두 번째 질문을 합니다.

이번에도 제안 답변을 받습니다. 이번에는 Kendra가 한 단계 더 나아가 단지 문서 자체를 반환하는 대신 문서에서 정확한 답변을 반환합니다. 이는 Kendra가 컨텍스트를 이해하고 관계(여기서는 개인과 개인의 출생 도시 간의 연결)를 추출할 수 있다는 것을 보여줍니다.
여전히 궁금한 점이 있어 세 번째 질문을 합니다.

또 다른 제안 답변을 받았으며 이번에도 목표를 정확히 맞춥니다. 제가 검색하려는 정보는 첫 번째 문장에 있습니다. ‘Thad Jones는 Count Basie와 함께 연주했습니다.’ 보시다시피 위 단락에는 “연주”라는 단어조차 포함되어 있지 않습니다. 하지만 Amazon Kendra는 제 질문을 정확하게 해석했습니다. Thad Jones는 뮤지션입니다. 다른 누군가와 함께 연주하는 Thad Jones에 대해 질문한다면 그 다른 누군가는 스포츠 파트너가 아니라 다른 뮤지션일 가능성이 매우 높습니다. 자연어 쿼리를 이해하고 영역에 관한 깊이 있는 지식을 추출할 수 있다는 점이 Amazon Kendra를 정확하게 만드는 요인입니다.
정식 출시
Amazon Kendra는 오늘부터 미국 동부(버지니아 북부), 미국 서부(오레곤) 및 유럽(아일랜드)에서 사용할 수 있습니다. (현재는 영어 자료 검색만 지원합니다.) 그리고, 두 버전 중 하나를 선택할 수 있습니다.
엔터프라이즈 에디션을 사용하면 시간당 7 USD로 하루 최대 500,000개의 문서를 검색하고 최대 40,000개의 쿼리를 실행할 수 있습니다. 또한 검색된 문서당 0.000001 USD와 동기화할 때 커넥터별로 시간당 0.35 USD가 청구됩니다. 인덱싱 용량이나 쿼리 용량이 더 필요한 경우 이제 둘을 각각 독립적으로 조정할 수 있습니다(예를 들어, 추가 쿼리 40,000개에 대해 시간당 3.5 USD 및 검색 가능한 추가 문서 500,000개에 대해 시간당 3.5 USD).
개발자 에디션에는 엔터프라이즈 에디션과 동일한 기능이 있습니다. 그러나 하루 4,000개의 쿼리와 5개 데이터 원본에서 10,000개의 검색 가능한 문서로 제한됩니다. 또한 조정 옵션을 사용할 수 없습니다. 개발자 에디션은 단일 가용 영역에서 실행되며 그렇기 때문에 프로덕션 용도로 사용하지 않아야 합니다.
Amazon Kendra를 사용해 보십시오. 평소에 이용하는 AWS Support 연락처나 Kendra에 대한 AWS 포럼을 통해 피드백을 보내주시기 바랍니다.