Amazon Web Services 한국 블로그
Amazon S3의 20년 역사와 차세대 서비스 방향
20년 전 오늘, 2006년 3월 14일에 Amazon Simple Storage Service(Amazon S3)는 새로운 소식 페이지에 게시된 한 단락의 간단한 발표와 함께 조용히 출범했습니다.
Amazon S3는 개발자가 웹 스케일 컴퓨팅을 쉽게 구현할 수 있도록 설계된 인터넷용 스토리지입니다. Amazon S3는 언제 어디서든, 웹에 원하는 양의 데이터를 저장하고 검색하는 데 사용할 수 있는 간단한 웹 서비스 인터페이스를 제공합니다. 이를 통해 개발자는 Amazon이 자체 글로벌 웹 사이트 네트워크를 운영하는 데 사용하는 것과 같은 수준의 확장성과 신뢰성을 갖춘 빠르고 저렴한 데이터 스토리지 인프라에 액세스할 수 있습니다.
Jeff Barr의 블로그 게시물도 캘리포니아에서 열린 개발자 이벤트로 향하는 비행기를 타기 전 몇 단락 급하게 작성한 글이었습니다. 코드 예도 없고 데모도 없었습니다. 매우 조용한 시작이었습니다. 이 출시가 전체 산업을 바꾸어놓을 것이라는 사실을 당시에는 아무도 몰랐습니다.
초창기: 제대로 작동하는 빌딩 블록
핵심적으로, S3에는 두 가지 간단한 프리미티브가 도입되었습니다. 객체를 저장하는 PUT과 후에 객체를 가져오는 GET입니다. 하지만 진정한 혁신은 그 이면에 숨겨진 철학이었습니다. 바로 개발자들이 더 높은 수준의 작업에 집중할 수 있도록 획일적이고 번거로운 작업을 처리하는 빌딩 블록을 만드는 것이었습니다.
S3는 처음부터 지금까지 변함없는 다섯 가지 기본 원칙에 따라 발전해왔습니다.
기본적으로 데이터를 보호하는 보안이 적용됩니다. 99.999999999%의 내구성을 보장하도록 설계되었으며, S3는 무손실로 운영됩니다. 장애가 항상 존재하며 반드시 처리되어야 한다는 가정 하에 모든 계층에 가용성이 설계되었습니다. 성능 저하 없이 거의 모든 양의 데이터를 저장할 수 있도록 성능이 최적화되었습니다. 데이터를 추가하고 제거할 때 수동 개입 없이 시스템이 자동으로 확장 및 축소되는 탄력성을 제공합니다.
이러한 요소를 제대로 구현하면 서비스가 매우 단순해져서 대부분의 사용자는 이러한 개념이 얼마나 복잡한지 전혀 신경 쓸 필요가 없게 됩니다.
오늘날의 S3: 상상을 초월하는 확장성
20년 동안 S3는 상상하기 어려울 정도의 규모로 성장했음에도 불구하고 핵심 기본 원칙을 계속 지켜 왔습니다.
S3는 처음 출시되었을 때 3개의 데이터 센터에 설치된 15개 랙의 약 400개 스토리지 노드에 걸쳐 총 15Gbps의 대역폭으로 약 1페타바이트의 총 스토리지 용량을 제공했습니다. 최대 객체 크기가 5GB인 수백억 개의 객체를 저장할 수 있도록 시스템을 설계했습니다. 초기 가격은 기가바이트당 15센트였습니다.
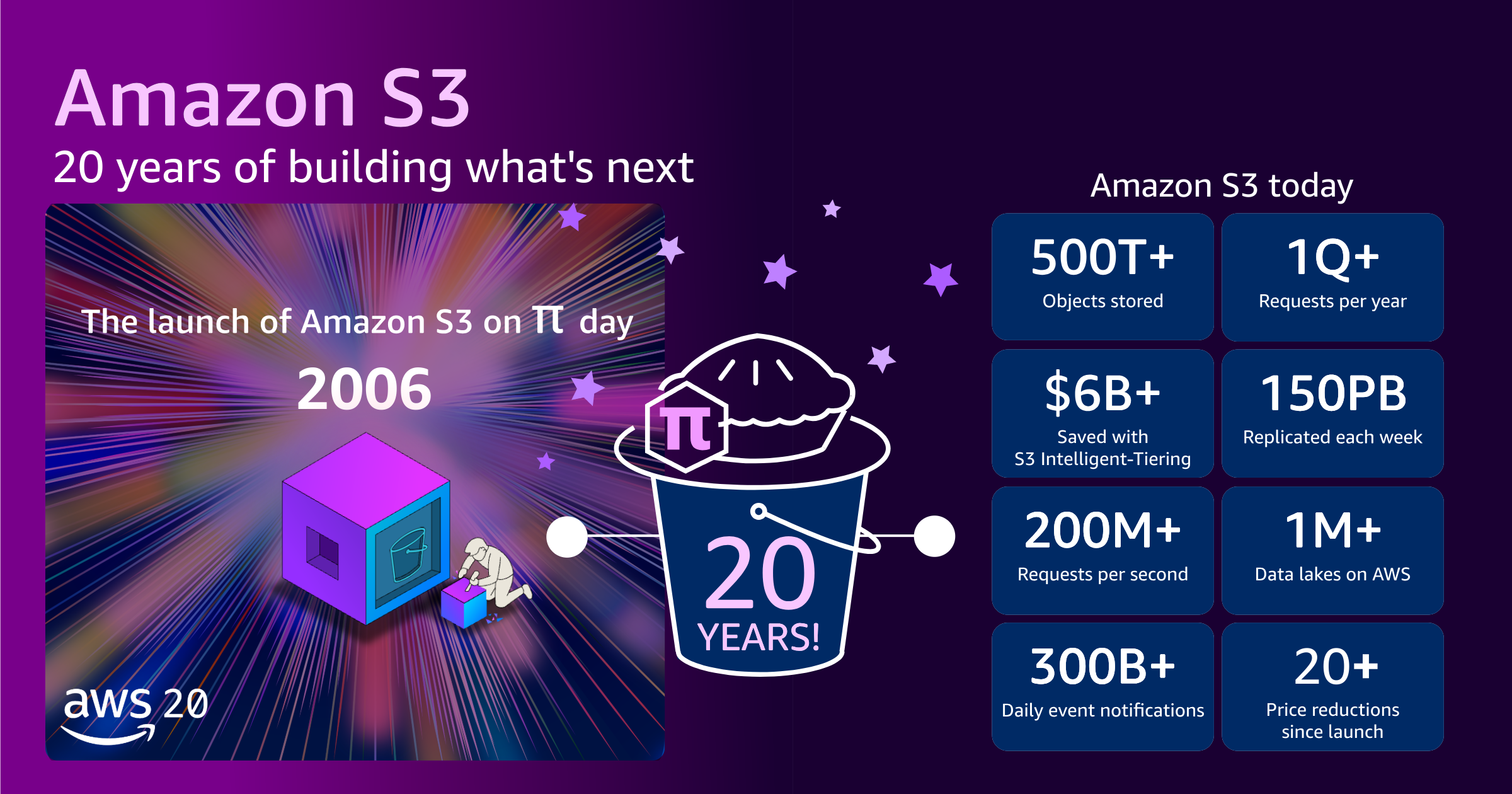
현재 S3는 500조 개 이상의 객체를 저장하고, 전 세계적으로 수백만 고객이 39개 AWS 리전의 123개 가용 영역에 있는 수백 엑사바이트 규모의 데이터에 대해 전송하는 초당 2억 건 이상의 요청을 처리합니다. 최대 객체 크기가 5GB에서 50TB로, 1만 배 증가했습니다. 수천만 개의 S3 하드 드라이브를 모두 겹쳐 놓으면 국제 우주 정거장에 도착했다가 거의 돌아올 수 있는 거리가 됩니다.
S3가 이 놀라운 규모를 지원할 수 있도록 성장했음에도 불구하고 고객이 지불하는 가격은 오히려 떨어졌습니다. 현재 AWS의 요금은 기가바이트당 2센트가 약간 넘습니다. 이는 2006년 출시된 이래 약 85%의 인하된 가격입니다. 그와 동시에, 스토리지 티어를 활용해 스토리지 지출을 더욱 최적화할 수 있는 방법을 지속적으로 도입해 왔습니다. 일례로, Amazon S3 Intelligent Tiering을 사용한 고객들은 Amazon S3 Standard에 비해 총 60억 USD 이상의 스토리지 비용을 절감할 수 있었습니다.
지난 20년 동안 S3 API는 스토리지 업계 전반에 걸쳐 기준점으로 채택되어 사용되었습니다. 이제 여러 공급업체가 동일한 API 패턴과 규칙을 구현하는 S3 호환 스토리지 도구와 시스템을 제공합니다. 즉, S3용으로 개발된 기술과 도구가 다른 스토리지 시스템으로 이전되는 경우가 많기 때문에 광범위한 스토리지 환경에 더 쉽게 접근할 수 있게 되었습니다.
이러한 성장과 업계 전반에 채택되었다는 사실보다 더 놀라운 점은 2006년에 S3용으로 작성한 코드가 지금도 수정 없이 잘 작동한다는 것입니다. 데이터는 20년 동안 혁신과 기술 발전을 거쳤습니다. 우리는 여러 세대의 디스크와 스토리지 시스템을 거치면서 인프라를 마이그레이션했습니다. 요청을 처리하는 코드도 모두 다시 작성되었습니다. 하지만 20년 전에 저장한 데이터를 지금도 여전히 사용할 수 있으며. 이전 버전 API와의 완벽한 호환성도 유지하고 있습니다. 이것이 바로 꾸준히 ‘제대로 작동하는’ 서비스를 제공하겠다는 우리의 약속입니다.
규모를 가능케 하는 엔지니어링
어떻게 이 같은 규모로 S3를 구축할 수 있게 된 것일까요? 바로 엔지니어링의 지속적인 혁신 덕분입니다.
이어지는 글은 대부분 AWS의 Data and Analytics 부문 VP, Mai-Lan Tomsen Bukovec과 The Pragmatic Engineer의 Gergely Orosz가 나눈 대화에서 발췌한 내용입니다. 이 심층 인터뷰에서는 더 자세히 알아보고자 하는 분들을 위해 기술적 세부 사항을 더 자세히 설명합니다. 이어지는 단락에서는 몇 가지 예를 공유합니다.
S3 내구성을 보장하는 핵심 구성 요소는 전체 플릿의 모든 단일 바이트를 지속적으로 검사하는 마이크로서비스 시스템입니다. 이 감사 서비스는 데이터를 검사하고 성능 저하 징후를 감지하는 즉시 복구 시스템을 자동으로 작동시킵니다. S3는 데이터 손실이 없도록 설계되었습니다. 99.999999999%라는 설계 목표는 복제 요소 및 재복제 플릿의 크기를 반영한 것으로, 실제 시스템은 객체가 손실되지 않도록 설계되었습니다.
S3 엔지니어들은 프로덕션 환경에서 정형 기법과 자동화된 추론을 사용하여 정확성을 수학적으로 증명합니다. 엔지니어가 코드를 인덱스 서브시스템에 체크인하면 자동화된 검증을 통해 일관성이 저하되지 않았는지 확인합니다. 리전 간 복제 또는 액세스 정책의 정확성을 검증하는 데에도 동일한 기법이 사용됩니다.
지난 8년 동안 AWS는 S3 요청 경로에서 성능에 중요한 코드를 Rust로 점진적으로 다시 작성해 왔습니다. Blob 이동과 디스크 스토리지 부분은 이미 다시 작성되었고, 다른 구성 요소에서도 작업이 활발히 진행되고 있습니다. 원시 성능 향상을 넘어, Rust의 타입 시스템과 메모리 안전 보장은 컴파일 단계에서 모든 종류의 버그를 완전히 없앱니다. 이는 S3에 요구되는 규모와 정확성으로 시스템을 운영할 때 필수적인 속성입니다.
S3는 ‘규모가 클수록 유리하도록 한다’는 설계 철학을 바탕으로 구축되었습니다. 엔지니어들은 규모가 커질수록 모든 사용자에게 제공되는 특성이 향상되도록 시스템을 설계합니다. S3의 규모가 커질수록 워크로드 간의 상관관계가 줄어들어, 결과적으로 모든 사용자에게 더 높은 신뢰성이 보장됩니다.
향후 전망
S3의 비전은 단순한 스토리지 서비스를 넘어, 모든 데이터와 AI 워크로드의 범용 기반이 되는 것입니다. 우리의 비전은 간단합니다. 모든 유형의 데이터를 S3에 한 번 저장하면 전문화된 여러 시스템 간에 데이터를 이동할 필요 없이 바로 작업할 수 있도록 하는 것입니다. 이 접근 방식을 사용하면 비용이 절감되고 복잡성이 해소되며 동일한 데이터의 복제본을 여러 개 만들 필요할 없습니다.
다음은 최근 몇 년간 출시된 몇 가지 주요 기능입니다.
- S3 Tables – 쿼리 효율성을 최적화하고 장기적으로 스토리지 비용을 절감하는 자동 유지 관리 기능을 갖춘 완전관리형 Apache Iceberg 테이블입니다.
- S3 Vectors – 100ms 미만의 쿼리 지연 시간으로 인덱스당 최대 20억 개의 벡터를 지원하는 시맨틱 검색 및 RAG용 네이티브 벡터 스토리지입니다. 고객들은 단 5개월(2025년 7월~12월) 만에 25만 개 이상의 인덱스를 생성하고, 400억 개 이상의 벡터를 수집하고, 10억 개 이상의 쿼리를 수행했습니다.
- S3 Metadata – 즉각적인 데이터 검색을 위한 중앙 집중식 메타데이터로, 카탈로그 작성을 위해 대규모 버킷을 재귀적으로 나열할 필요가 없으며 대규모 데이터 레이크에 대한 분석 시간이 크게 단축됩니다.
이러한 각 기능은 S3 비용 구조에 따라 운영됩니다. 기존에는 값비싼 데이터베이스나 전문화된 시스템이 필요했던 다양한 데이터 유형을 이제는 대규모 환경에서도 경제적으로 처리할 수 있습니다.
1페타바이트에서 수백 엑사바이트로. 기가바이트당 15센트에서 2센트로. 단순한 객체 스토리지에서 AI와 분석을 위한 기반으로. 이 모든 변화 속에서도 다섯 가지 핵심 원칙, 즉 보안, 내구성, 가용성, 성능, 확장성은 변함없이 유지되고 있으며, 2006년에 작성한 코드도 지금까지 잘 작동합니다.
Amazon S3와 함께할 앞으로 20년간의 혁신도 기대됩니다.