AWS 기술 블로그
지능형 Physical AI 구축: Strands Agents, Bedrock AgentCore, Claude 4.6, NVIDIA GR00T, Hugging Face LeRobot으로 엣지에서 클라우드까지
이 글은 AWS Open Source Blog의 “Building intelligent physical AI: From edge to cloud with Strands Agents, Bedrock AgentCore, Claude 4.5, NVIDIA GR00T, and Hugging Face LeRobot by Arron Bailiss” 게시글을 번역한 글 입니다.
에이전틱 AI 시스템은 디지털 세계를 넘어 물리적 세계로 빠르게 확장되고 있으며, AI 에이전트가 실제 환경에서 인지하고, 추론하고, 행동합니다. AI 시스템이 로봇공학, 자율주행 차량, 스마트 인프라를 통해 물리적 세계와 점점 더 많이 상호작용함에 따라 근본적인 질문이 떠오릅니다: 복잡한 추론을 위해 대규모 클라우드 컴퓨팅을 활용하면서도 물리적 감지와 작동을 위한 밀리초 수준의 응답성을 유지하는 에이전트를 어떻게 구축할 수 있을까요?
2025년은 AWS의 에이전틱 AI에 있어 혁신적인 한 해였습니다. 2025년 5월에 Strands Agents를 출시하여 에이전트 개발에 간단한 개발자 경험과 모델 중심 접근 방식을 제공했습니다. 7월에는 멀티 에이전트 오케스트레이션 기능을 갖춘 버전 1.0을 출시하고, AI 에이전트를 대규모 프로덕션으로 가속화하기 위한 Amazon Bedrock AgentCore를 소개했습니다. re:Invent 2025에서는 TypeScript SDK, 평가 도구, 음성 에이전트를 위한 양방향 스트리밍, 에이전트를 경계 내에서 안내하는 스티어링으로 Strands를 확장했습니다. 오늘은 이러한 역량이 엣지 및 Physical AI로 어떻게 확장되는지 살펴보겠습니다. 이 영역에서 에이전트는 단순히 정보를 처리하는 것을 넘어, 물리적 세계에서 우리와 함께 일하게 됩니다.

전체 데모 코드는 여기에서 찾을 수 있습니다:
이 시연에서 Physical AI 에이전트는 Strands Agents라는 통합 인터페이스를 통해 AI 에이전트를 물리적 센서 및 하드웨어에 연결하며, 이를 기반으로 서로 전혀 다른 두 종류의 로봇을 제어합니다. 3D 프린팅으로 제작된 SO-101 로봇 팔은 NVIDIA GR00T 비전-언어-행동 모델(VLA)을 활용해 물체 조작을 수행합니다. 예를 들어 “과일을 집어서 바구니에 넣어”라고 명령하면, 로봇 팔이 사과를 인식하고 잡은 뒤 바구니에 옮겨 놓는 작업을 완료합니다. Boston Dynamics의 사족보행 로봇 Spot은 이동 및 전신 제어를 담당합니다. “센서를 점검해”라고 명령하면, Spot은 센서가 몸체 하부에 있다는 것을 스스로 추론한 뒤 자율적으로 앉아서 옆으로 몸을 뒤집어 센서에 접근합니다. 두 시연 모두 NVIDIA Jetson 엣지 하드웨어에서 구동되며, 고도화된 AI 기능이 임베디드 시스템에서도 직접 실행될 수 있음을 보여줍니다.
엣지-클라우드 연속체
Physical AI 애플리케이션은 지능형 시스템의 아키텍처 설계 방식을 좌우하는 근본적인 긴장 관계를 드러냅니다. 공을 잡는 로봇 팔을 생각해 보겠습니다. 공을 인식한 순간부터 그리퍼 위치를 조정하기까지 밀리초 단위로 이루어져야 합니다. 아무리 빠른 연결을 사용하더라도 클라우드 서비스까지의 네트워크 지연 시간으로는 이를 실현할 수 없습니다. 추론은 물리적 현실이 요구하는 거의 즉각적인 응답 시간에 맞춰, 엣지, 즉 디바이스 자체에서 이루어져야 합니다.
그러나 동일한 로봇 시스템이 클라우드의 역량으로부터 얻는 이점 또한 막대합니다. 다단계 조립 작업을 계획하거나, 다른 로봇과 협업하거나, 수천 대의 유사한 로봇이 축적한 경험을 학습하려면 클라우드만이 제공할 수 있는 대규모 연산 능력이 필요합니다. Anthropic의 Claude Sonnet 4.6와 같은 모델은 로봇이 복잡한 작업을 이해하고 실행하는 방식을 혁신하는 추론 능력을 제공하지만, 엣지 하드웨어에서 실행하기에는 너무 큽니다.
이는 Daniel Kahneman의 시스템 1과 시스템 2 사고를 반영합니다 – 엣지는 빠르고 본능적인 반응을 제공하고, 클라우드는 신중한 추론, 장기 계획, 지속적 학습을 가능하게 합니다. 가장 뛰어난 Physical AI 시스템은 이 두 가지를 매끄럽게 결합하여 활용합니다.
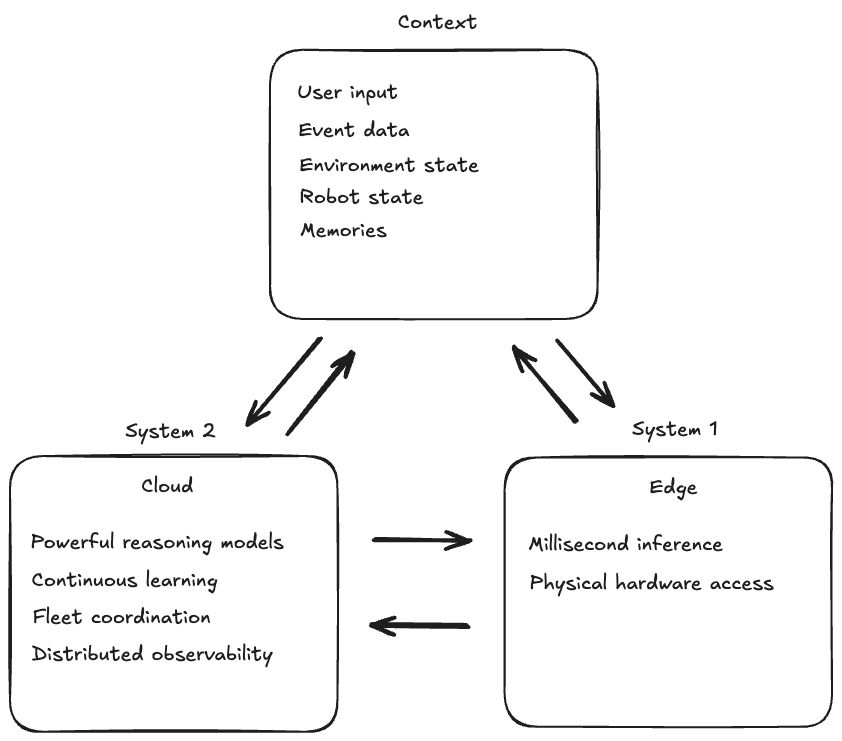
클라우드는 엣지에서는 실현하기 어려운 추가적인 역량을 제공합니다. AgentCore Memory는 수 시간 또는 수일에 걸친 공간적·시간적 맥락을 유지하며, 단순히 무슨 일이 일어났는지뿐만 아니라 어디서, 언제 발생했는지까지 기억할 수 있습니다. 학습 결과를 개별 디바이스에 한정하지 않고 전체 플릿에 걸쳐 수집하고 적용할 수 있습니다. 한 로봇이 더 나은 방법을 발견하면, 그 지식은 공유 메모리를 통해 모든 로봇에 제공됩니다. 전체 플릿에 대한 분산 관측성은 AI 에이전트와 로봇이 대규모로 배포되었을 때 무엇을 하고 있는지 파악할 수 있는 능력을 제공하며, 단일 디바이스로는 얻을 수 없는 인사이트를 도출합니다. Amazon SageMaker는 대규모 병렬 시뮬레이션과 모델 학습을 지원하여, 실제 환경 및 시뮬레이션 배포에서 얻은 학습 결과를 개선된 모델에 반영하고 이를 전체 플릿에 적용할 수 있게 합니다.
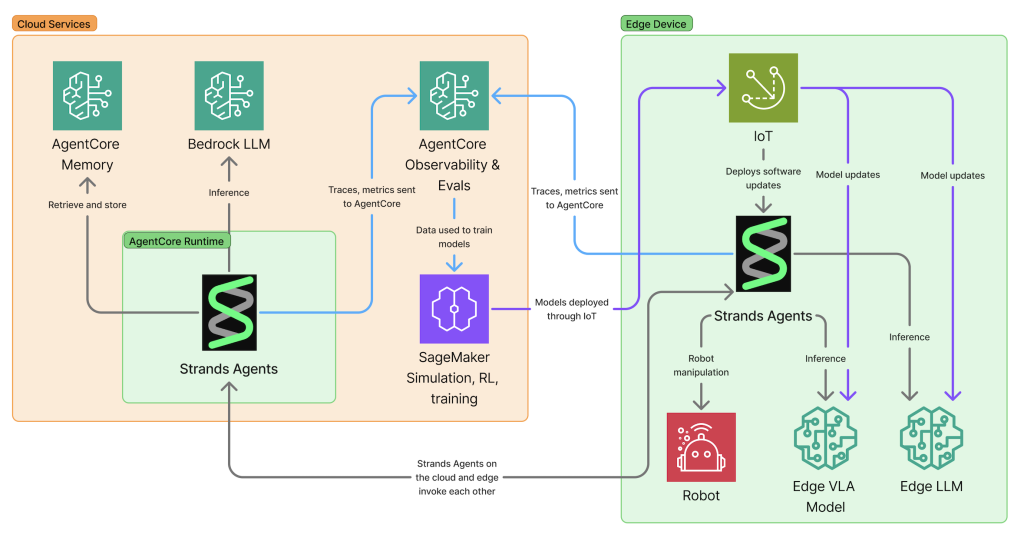
이러한 하이브리드 아키텍처는 완전히 새로운 범주의 지능형 시스템을 가능하게 합니다. 휴머노이드 로봇은 클라우드 기반 추론을 활용해 다단계 작업을 계획하는 동시에, 엣지 기반 비전-언어-행동(VLA) 모델로 정밀한 물리적 동작을 수행합니다. 클라우드 에이전트는 “아침 식사 준비”를 계획하며 이를 세부 단계로 나누고 사용자의 식사 선호를 기억하는 반면, 엣지 VLA 모델은 딸기를 으깨지 않고 집어 올리는 밀리초 단위의 정밀 제어를 담당합니다.
자율주행차는 클라우드 지능을 활용해 경로 최적화와 교통 예측을 수행하면서, 엣지에서는 실시간 장애물 회피를 유지합니다. 보행자를 피하기 위해 클라우드의 응답을 기다릴 수는 없지만, 도시 전체의 교통 패턴에 대한 클라우드 기반 분석의 혜택은 충분히 누릴 수 있습니다.
코드를 통한 단계적 여정
엣지 및 Physical AI 시스템을 구축하기 위해 처음부터 엣지-클라우드 오케스트레이션의 모든 복잡성을 다룰 필요는 없습니다. 나아가야 할 방향은 점진적 반복, 즉 단순하게 시작하여 필요에 따라 정교함을 더해가는 것입니다.
엣지에서 시작하기
먼저 엣지 디바이스에 Ollama와 함께 Strands Agents Python SDK를 설치하고 Qwen3-VL 모델을 가져옵니다. Ollama를 설치한 후 다음 명령을 실행합니다.
Bash
ollama pull qwen3-vl:2b
pip install 'strands-agents[ollama]'간단한 출발점은 엣지 디바이스에서 모델을 로컬로 실행하는 것입니다. Strands의 Ollama 프로바이더를 사용하면 Qwen3-VL과 같은 오픈소스 모델을 엣지 하드웨어에서 직접 실행할 수 있습니다. Strands는 양자화된 모델을 사용한 고성능 추론을 위한 llama.cpp와 Apple Silicon에서 모델을 실행하기 위한 MLX도 지원합니다.
Python
from strands import Agent
from strands.models.ollama import OllamaModel
edge_model = OllamaModel(
host="http://localhost:11434",
model_id="qwen3-vl:2b"
)
agent = Agent(
model=edge_model,
system_prompt="당신은 엣지 하드웨어에서 실행되는 유용한 어시스턴트입니다."
)
result = agent("안녕!")Physical AI는 단순히 텍스트를 처리하는 것을 넘어, 물리적 세계를 이해하는 능력이 필요한 경우가 많습니다. 카메라 입력을 통해 시각적 이해를 추가하는 것은 간단합니다. 텍스트를 처리하던 동일한 에이전트가 이제 이미지도 처리할 수 있어, 주변의 물리적 환경을 시각적으로 인식할 수 있게 됩니다.
Python
def get_camera_frame() -> bytes:
# 현재 카메라 프레임을 반환하는 예제 함수
with open("camera_frame.jpg", "rb") as f:
return f.read()
result = agent([
{"text": "어떤 물체가 보이나요?"},
{"image": {"source": {"bytes": get_camera_frame()}}}
])시각 기능 외에도, 에이전트는 다른 센서에 접근하여 자신의 상태를 파악할 수 있습니다. 센서 데이터를 도구로 래핑하면, 에이전트가 필요할 때 이를 동적으로 호출하여 정보에 기반한 의사결정을 내릴 수 있습니다. 배터리 잔량을 읽어 작업을 계속할지 충전을 위해 복귀할지를 판단하는 것이 그 예입니다.
Python
@tool
def get_battery_level() -> str:
"""현재 배터리 수준 백분율과 남은 시간을 가져옵니다."""
percentage = robot.get_battery_percentage()
duration = robot.get_battery_duration_minutes()
return f"배터리 수준: {percentage}%, 약 {duration}분 남음"
agent = Agent(
model=edge_model,
tools=[get_battery_level],
system_prompt="당신은 로봇 어시스턴트입니다. 사용 가능한 도구를 활용하여 질문에 답하세요."
)
result = agent("충전이 필요할 때까지 얼마나 남았나요?")물리적 세계에서의 행동
Physical AI 시스템은 환경을 감지하고, 무엇을 할지 추론하며, 목표 달성을 위해 세계를 변화시키는 행동을 취하는 연속적인 순환을 따릅니다. 앞서 카메라와 센서를 통한 감지를 다루었으니, 이제 에이전트가 의사결정을 물리적 행동으로 어떻게 전환하는지 살펴보겠습니다.
물리적 세계에서 행동한다는 것은 하드웨어를 제어하는 것을 의미합니다. 로봇 관절을 회전시키는 모터, 열고 닫히는 그리퍼, 이동 플랫폼을 구동하는 바퀴가 그 대상입니다. 로봇 팔에는 6개의 관절이 있을 수 있으며, 각 관절은 특정 각도로 회전할 수 있는 모터로 제어됩니다. 물체를 집어 올리려면 로봇은 6개의 관절을 동시에 조율하여, 현재 위치에서 물체에 도달하는 위치로 이동하고, 그리퍼 각도를 조정하며, 그리퍼를 닫고, 들어 올려야 합니다. 이러한 조율은 모터에 목표 관절 위치를 전송하여 로봇의 물리적 구조를 움직이는 방식으로 이루어집니다. 이를 구현하는 방법에는 두 가지가 있습니다: 로봇 동작을 직접 출력하는 비전-언어-행동(VLA) 모델을 사용하는 방법과, AI가 상위 수준의 명령을 제공하고 기존 로봇 SDK를 활용하는 방법입니다.
NVIDIA GR00T와 같은 비전-언어-행동(VLA) 모델은 시각 인식, 언어 이해, 행동 예측을 하나의 모델로 통합합니다. 카메라 이미지, 로봇 관절 위치, 언어 지시를 입력으로 받아 새로운 목표 관절 위치를 직접 출력합니다.
“너와 같은 색의 과일을 집어서 바구니에 넣어”라는 지시를 생각해 보겠습니다. VLA 모델의 비전-언어 백본은 먼저 지시 내용과 카메라 이미지에서 보이는 것을 추론하여, 어떤 물체가 사과이고 어떤 것이 바구니인지를 식별합니다. 로봇의 현재 상태(관절 위치)를 함께 반영하여, 모델은 로봇이 사과에 다가가고, 그리퍼로 사과를 감싸 잡고, 바구니로 이동한 뒤, 놓아주는 일련의 새로운 관절 위치를 생성합니다. 모델은 이를 액션 청크, 즉 장면을 지속적으로 관찰하면서 로봇이 실행하는 짧은 관절 움직임 시퀀스로 수행합니다. 작업 도중 누군가 사과를 옮기면, VLA 모델은 다음 카메라 프레임에서 이를 감지하고 사과의 새로운 위치에 도달하기 위한 수정된 관절 움직임을 생성합니다.
Hugging Face의 LeRobot은 로보틱스 하드웨어 작업을 쉽게 할 수 있도록 데이터 및 하드웨어 인터페이스를 제공합니다. 원격 조작이나 시뮬레이션을 통해 시연을 녹화하고, 해당 데이터로 모델을 학습시킨 뒤, 다시 로봇에 배포합니다. LeRobot과 같은 하드웨어 추상화와 NVIDIA GR00T와 같은 VLA 모델을 결합하면, 물리적 세계에서 인지하고, 추론하고, 행동하는 엣지 AI 애플리케이션을 만들 수 있습니다:
Python
@tool
def execute_manipulation(instruction: str) -> str:
"""로봇 하드웨어를 사용하여 조작 작업을 실행합니다."""
while not task_complete:
observation = robot.get_observation() # 카메라 + 관절 위치
action = vla.get_action(observation, instruction) # VLA 모델에서 추론
robot.apply_action(action) # 관절 움직임 실행
return f"완료: {instruction}"
robot_agent = Agent(
model=edge_model,
tools=[execute_manipulation],
system_prompt="당신은 로봇 팔을 제어합니다. 조작 도구를 사용하여 물리적 작업을 수행하세요."
)
result = robot_agent("사과를 바구니에 넣어.")이를 통해 자연스러운 역할 분담이 이루어집니다. Strands가 상위 수준의 작업 분해를 담당하고, GR00T는 실시간 자기 보정과 함께 밀리초 단위의 감각운동 제어를 처리합니다.
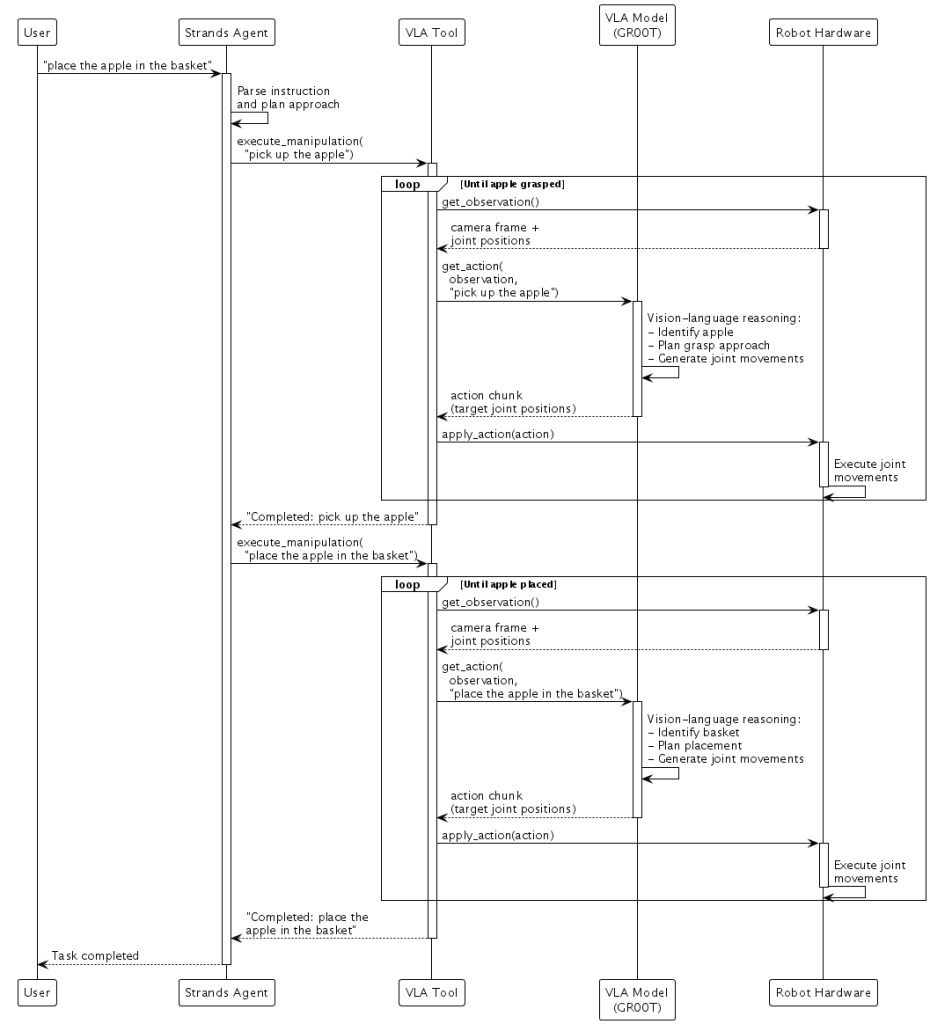
빌더들이 더 쉽게 사용할 수 있도록, 하드웨어와 NVIDIA GR00T과 같은 VLA 모델을 연결하는 간단한 인터페이스를 가진 실험적 로봇 클래스를 공개했습니다.
Python
from strands import Agent
from strands_robots import Robot
# 카메라가 있는 로봇 생성
robot = Robot(
tool_name="my_arm",
robot="so101_follower",
cameras={
"front": {"type": "opencv", "index_or_path": "/dev/video0", "fps": 30},
"wrist": {"type": "opencv", "index_or_path": "/dev/video2", "fps": 30}
},
port="/dev/ttyACM0",
data_config="so100_dualcam"
)
# 로봇 도구로 에이전트 생성
agent = Agent(tools=[robot])
agent("사과를 바구니에 넣어")SDK 기반 제어는 로봇 제조사가 견고한 모션 프리미티브를 제공하고, 이미 검증된 제어 시스템을 활용하고자 할 때 효과적입니다. Boston Dynamics Spot의 경우, SDK 명령을 Strands 도구로 래핑합니다.
Python
from bosdyn.client.robot_command import RobotCommandBuilder, blocking_command, blocking_stand, blocking_sit
@tool
def stand() -> str:
"""로봇에게 일어서라고 명령합니다."""
blocking_stand(command_client, timeout_sec=10)
return "로봇이 서 있습니다"
@tool
def sit() -> str:
"""로봇에게 앉으라고 명령합니다."""
blocking_sit(command_client, timeout_sec=10)
return "로봇이 앉아 있습니다"
@tool
def battery_change_pose(direction: str = "right") -> str:
"""배터리 접근을 위해 로봇을 옆으로 눕힙니다."""
cmd = RobotCommandBuilder.battery_change_pose_command(
dir_hint=1 if direction == "right" else 2
)
blocking_command(command_client, cmd, timeout_sec=20)
return f"배터리 접근을 위해 로봇 위치 조정 완료"
spot_agent = Agent(
model=edge_model,
tools=[stand, sit, battery_change_pose],
system_prompt="당신은 Boston Dynamics Spot 로봇을 제어합니다."
)
result = spot_agent("센서를 점검해야 합니다")“센서를 점검해야 합니다”라는 요청을 받으면, 에이전트는 센서가 로봇 하부에 있다는 것을 추론한 뒤, Spot에게 앉기 및 배터리 교체 자세를 실행하도록 명령합니다. SDK는 로봇을 안전하게 옆으로 눕히는 데 필요한 복잡한 균형 유지와 모터 제어를 처리합니다.
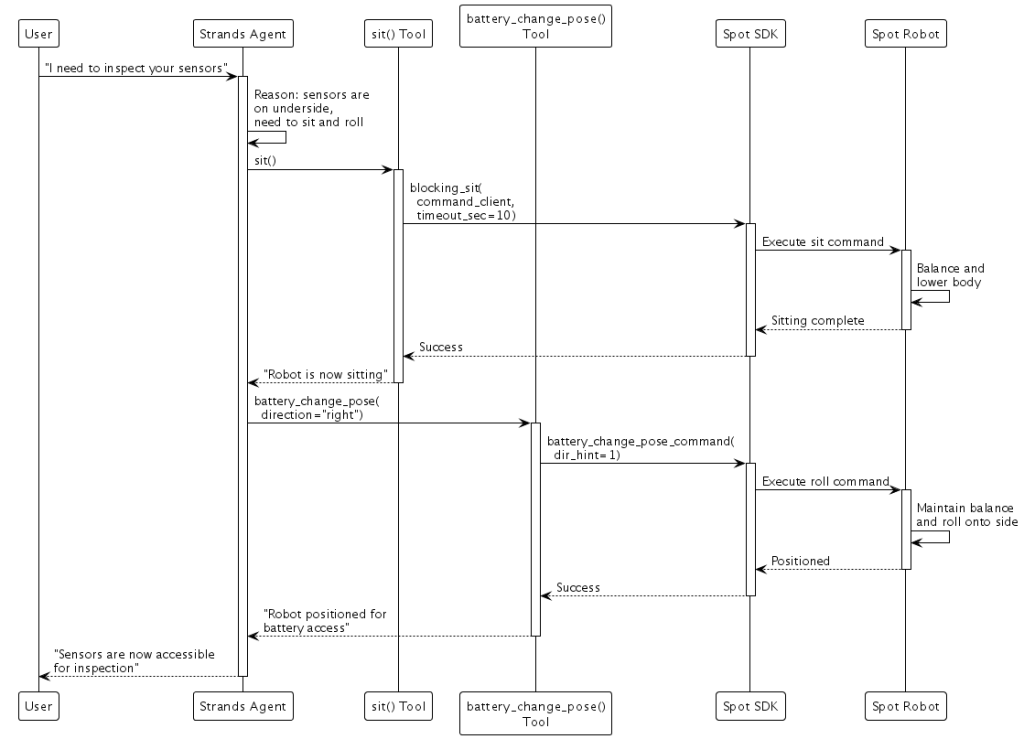
엣지와 클라우드 연결하기
엣지 에이전트는 필요할 때 복잡한 추론을 클라우드에 위임할 수 있습니다. VLA 모델은 물리적 동작에 대해 밀리초 단위의 제어를 제공하지만, 다단계 작업 계획이나 과거 패턴에 기반한 의사결정처럼 더 깊은 추론이 필요한 상황에 직면하면, 에이전트를 도구로 활용하는 패턴을 통해 더 강력한 클라우드 기반 에이전트에 자문을 구할 수 있습니다.
Python
from strands import Agent, tool
from strands.models import BedrockModel
from strands.models.ollama import OllamaModel
# 강력한 추론 능력을 가진 클라우드 에이전트
cloud_agent = Agent(
model=BedrockModel(model_id="global.anthropic.claude-sonnet-4-6"),
system_prompt="엣지 로봇을 위한 작업을 단계별로 계획하세요."
)
# 에이전트-애즈-툴 패턴을 사용하여 위임할 수 있도록
# 클라우드 에이전트를 도구로 노출
@tool
def plan_task(task: str) -> str:
"""복잡한 계획을 클라우드 기반 추론에 위임합니다."""
return str(cloud_agent(task))
# 로컬 모델을 사용하는 엣지 에이전트
edge_agent = Agent(
model=OllamaModel(
host="http://localhost:11434",
model_id="qwen3-vl:2b"
),
tools=[plan_task],
system_prompt="작업을 수행하세요. 복잡한 계획이 필요하면 클라우드에 자문을 구하세요."
)
result = edge_agent("음료를 가져다 줘")반대 패턴 역시 강력합니다. 클라우드 기반 오케스트레이터가 여러 엣지 디바이스를 조율할 수 있으며, 각 디바이스가 자체적으로 실시간 제어를 처리하는 동안 클라우드 에이전트가 전체 워크플로를 관리합니다.
Python
@tool
def control_robot_arm(command: str) -> str:
"""조작 작업을 위해 로봇 팔을 제어합니다."""
return str(robot_arm_agent(command))
@tool
def control_mobile_robot(command: str) -> str:
"""탐색 및 운송을 위해 이동 로봇을 제어합니다."""
return str(mobile_robot_agent(command))
warehouse_orchestrator = Agent(
model=BedrockModel(model_id="global.anthropic.claude-sonnet-4-6"),
tools=[control_robot_arm, control_mobile_robot],
system_prompt="당신은 창고 환경에서 여러 로봇을 조율합니다."
)
result = warehouse_orchestrator(
"재고 점검 조율: 선반 스캔, 물품 회수, 분류"
)창고 환경에서 이는 로봇 팔, 이동 로봇, 검사 드론을 조율하여 복잡한 재고 작업을 완수하는 것을 의미할 수 있습니다. 각 디바이스는 즉각적인 대응을 위한 자체 엣지 지능을 유지하면서도, 클라우드 오케스트레이션 하에 함께 협력합니다.
플릿 전반의 학습과 개선
앞서 클라우드 에이전트가 여러 엣지 디바이스를 조율하는 방법을 살펴보았습니다. Physical AI 시스템은 여기서 한 걸음 더 나아가, 집단적 경험으로부터 학습하고 관찰과 피드백을 통해 지속적으로 개선될 때 훨씬 더 강력한 역량을 발휘합니다.
수십 대의 이동 로봇이 운영되는 창고를 생각해 보겠습니다. 여러 로봇이 동일한 문제에 직면하면, 단일 로봇으로는 감지할 수 없는 패턴이 드러나게 됩니다. AgentCore Memory는 이러한 집단 지능을 가능하게 합니다. 각 로봇은 운영 중에 관찰한 내용을 공유 메모리에 저장합니다.
Python
from bedrock_agentcore.memory import MemoryClient
memory_client = MemoryClient(region_name="us-east-1")
# 로봇이 내비게이션 문제 후 관찰 내용 저장
memory_client.create_event(
memory_id=FLEET_MEMORY_ID,
actor_id=robot_id,
session_id=f"robot-{robot_id}",
messages=[
("북쪽 복도에서 내비게이션 실패 - 시각적 위치 추정 신뢰도 낮음. "
"위치: north_corridor, 조도: high_contrast", "ASSISTANT")
]
)플릿 코디네이터는 이 공유 메모리를 조회하여, 북쪽 복도에서 발생하는 내비게이션 장애의 87%가 오후 2시에서 4시 사이에 집중되며, 이는 채광창을 통해 들어오는 오후 햇빛이 비전 시스템을 혼란시키기 때문이라는 사실을 발견할 수 있습니다. 이러한 인사이트는 즉각적인 운영 변경으로 이어지고, 모델 개선에도 반영됩니다.
AgentCore Observability는 추론 → 시뮬레이션/행동 → 관찰 → 평가 → 최적화로 이어지는 완전한 피드백 루프를 통해 지속적 개선의 기반을 제공합니다. CloudWatch의 GenAI Observability 대시보드는 엣지 디바이스로부터 엔드투엔드 트레이스를 수집하여, 에이전트 실행 경로, 메모리 검색 작업, 전체 시스템의 지연 시간 분석을 보여줍니다. 이 관측성 데이터는 강화 학습의 학습 신호로 활용되어, 성공적인 행동은 강화하고 실패는 교정에 반영됩니다.
Amazon SageMaker는 이러한 학습 결과를 적용하기 위한 대규모 병렬 시뮬레이션과 학습을 지원합니다. NVIDIA Isaac Sim이나 MuJoCo와 같은 물리 시뮬레이터는 사실적인 물리 환경을 제공하여, 로봇이 배포 전에 수백만 가지 시나리오를 안전하게 연습할 수 있게 합니다. LLM 기반 사용자 시뮬레이터를 포함한 디지털 시뮬레이터는 다양한 상호작용 패턴을 생성하여 에이전트가 예외적인 상황에 대응할 수 있도록 돕습니다. 이 순환은 반복됩니다: 실제 로봇에 배포하고, 행동을 관찰하고, 대규모로 개선 사항을 시뮬레이션하고, 업데이트된 모델을 학습시킨 뒤, 다시 플릿에 배포합니다. 매 반복마다 전체 플릿의 역량이 향상됩니다. Isaac GR00T 파인튜닝을 활용한 확장 가능한 로봇 학습 파이프라인을 AWS에서 구축하는 방법에 대한 자세한 안내는, AWS Batch에서 로봇 학습을 시작하는 방법을 다룬 Embodied AI 블로그 시리즈를 참고하시기 바랍니다.
미래의 지능형 시스템 구축
지금 이 시점이 흥미로운 이유는 여러 분야에서 동시에 융합이 일어나고 있기 때문입니다. 강력한 멀티모달 추론 모델이 물리적 작업을 이해하고 계획할 수 있게 되었고, 엣지 하드웨어는 물리적 시스템이 요구하는 낮은 지연 시간으로 VLA 모델을 로컬에서 실행할 수 있게 해주며, 오픈소스 로보틱스 하드웨어는 Physical AI 개발을 더 넓은 개발자 커뮤니티에 개방하고 있습니다. 로봇이 밀리초 단위의 제어로 동적 환경에서 감지하고 행동할 수 있게 하는 VLA 모델이 등장했으며, 시뮬레이션과 실제 물리적 배포를 통해 에이전트가 개선되는 지속적 학습 루프가 클라우드 위에서 대규모로 실현 가능해졌습니다.
AWS의 목표 중 하나는 AI 에이전트 개발을 누구나 쉽게 할 수 있도록 만드는 것입니다. 이번 작업은 그 목표를 물리적 세계로 확장합니다. David Silver와 Richard S. Sutton이 「경험의 시대에 오신 것을 환영합니다(Welcome to the Era of Experience)」에서 설명한 것처럼, AI 에이전트는 점점 더 자신의 환경에서 경험을 통해 학습하며, 모델 학습, 튜닝, 장기 기억, 컨텍스트 최적화를 통해 발전하고 있습니다. 이러한 시스템이 물리적 세계에 대해 더 깊이 추론하는 능력을 갖추게 되면, 행동하기 전에 미래의 세계 상태를 시뮬레이션하고, 자신의 결정이 가져올 결과를 예측하며, 더 큰 시스템의 일부로서 안정적으로 협업할 수 있게 됩니다.
빠르게 성장하는 이 분야에서 앞으로 몇 달간 여러분이 무엇을 만들어 나갈지 기대하겠습니다.
지금 시작하세요.