AWS 기술 블로그
RIMAN KOREA의 Amazon Bedrock Knowledge Bases를 활용한 자연어 기반 상품 검색 시스템 구축기
RIMAN KOREA 소개

RIMAN KOREA는 2018년 설립된 K-뷰티 글로벌 다이렉트 셀링 기업입니다. 자이언트 병풀, 제주 용암해수 등 독자 원료를 기반으로 고기능성 스킨케어(ICD), 비건 뷰티(보타랩), 건강기능식품(라이프닝)을 주력 제품으로 합니다.
리만코리아의 E-Commerce 팀은 운영 중인 온라인 자사몰(이하 리만몰)을 고도화하기 위해 사용자로부터 접수된 문의 내역을 분석하였습니다. 그 결과 상품 검색이 어렵다는 문제를 발견하였습니다. 기존 시스템은 상품명 기반의 키워드 매칭 검색만을 제공하였기 때문입니다. 실제 사용자들의 검색 행태를 분석한 결과, “래디언솜™100 마이크로플루다이저 토너”와 같은 정확한 상품명을 입력하기보다 “병풀 크림”, “비타민C 세럼” 등 원료명이나 제형으로 검색하는 경향이 높다는 것을 확인하였습니다. 사용자들의 잦은 검색 실패 경험은 구매 포기로 이어져 매출에도 영향을 끼치고 있었습니다.
이 글에서는 이러한 문제를 해결하기 위해 Amazon Bedrock Knowledge Bases를 활용하여 자연어 기반 상품 검색 시스템을 구축한 과정을 소개합니다. AWS의 EBA(Experience-Based Acceleration) 프로그램을 통해 AI/Agent 경험이 없는 5인 팀이 약 5주 만에 MVP를 완성하였으며, 검색 정확도 95%와 평균 응답 시간 2.5초 이내를 달성하였습니다. RAG 아키텍처 설계, 청킹 전략, 하이브리드 검색, 병렬 처리 구조 등 주요 기술적 의사결정과 아키텍처 설계를 공유합니다.
프로젝트 진행 방식
이 프로젝트는 AWS의 EBA(Experience-Based Acceleration) 프로그램으로 진행 되었습니다. EBA는 AWS가 고객과 원팀을 구성하여 실제 워크로드를 함께 구축하는 프로그램으로 고객이 프로그램 종료 후에도 독립적으로 시스템을 운영할 수 있는 역량 확보를 목표로 합니다.
이번 프로젝트는 AI/Agent 관련 경험이 없는 리만코리아 5인 팀과 AWS 기술팀이 5주간 주 1회 스프린트 리뷰를 진행하며 총 5회 스프린트로 MVP를 완성하였습니다. 각 스프린트의 주요 작업과 핵심 성과는 다음과 같습니다.
| Sprint | 주요 작업 | 핵심 성과 |
|---|---|---|
| #0 인에이블먼트 | – RAG/Amazon Bedrock Knowledge Bases/Kiro-CLI 인에이블먼트 세션
– 기존 자사몰 검색 아키텍처 분석 및 범위 확정을 위한 디스커버리 미팅 |
– Amazon Bedrock, Amazon OpenSearch Serverless, RAG 파이프라인 설계에 대한 고객 역량 강화
– Kiro-CLI 활용 교육 – 서비스 정의 확정: 상품 메타데이터 및 시맨틱 설명 기반 RAG 자연어 검색 |
| #1 데이터 기반 구축 및 KB 프로토타입 | – 상품 대상 확정
– HTML 기반 비정형 데이터 추출 (상품 상세 페이지) – Claude Vision OCR 파이프라인 설계 – 초기 Amazon Bedrock Knowledge Bases 생성 및 시나리오 테스트 |
– 하이브리드 데이터 전략 확정: 정형(메타데이터) + 비정형(상세 페이지)
– 정량 평가를 위한 시나리오 데이터셋(130개 쿼리) 구축 |
| #2 데이터 전처리 및 임베딩 전략 | – 최종 데이터 셋 (정형 + 비정형) 도출
– JSON 문서 생성 및 S3 업로드 – KB 청킹 전략 평가 – AI 기반 테스트 시나리오 확장 (494개 테스트 케이스) |
– 데이터 손실 방지를 위한 No-Chunking 임베딩 전략 채택
– 정확도 향상을 위한 하이브리드 검색(시맨틱 + 키워드) 채택 |
| #3 백엔드 + 프론트엔드 개발 및 정확도 튜닝 | – 백엔드/프론트엔드 리포지토리 + CI/CD 구축
– VPC, DB 네트워킹 – KB 호출 API, AI 오버뷰 + 상품 추천 UI – RAG KB 정확도 개선 (72% → 95%) – RAG 수집 파이프라인 자동화 |
– 쿼리 확장 + 메타데이터 필터 추출을 위한 LLM 분류기 레이어 추가
– 동기화 후 검증 테스트가 포함된 자동화 Bedrock KB 동기화 파이프라인 구축 – 494개 질문 테스트 세트에서 95% 정확도 달성 |
| #4 최적화 및 데모 준비 | – KB 응답 속도 최적화
– SSE(Server-Sent Events) 백엔드 + 프론트엔드 적용 – 대상 사용자 데모 테스트 + 심층 인터뷰(FGI) |
– 스트리밍 응답 UX 구현 완료
– 내부 데모 테스트 + FGI를 통한 검색 경험 검증 – 전사 베타 테스트를 위한 MVP 준비 완료 확인 |
솔루션 개요
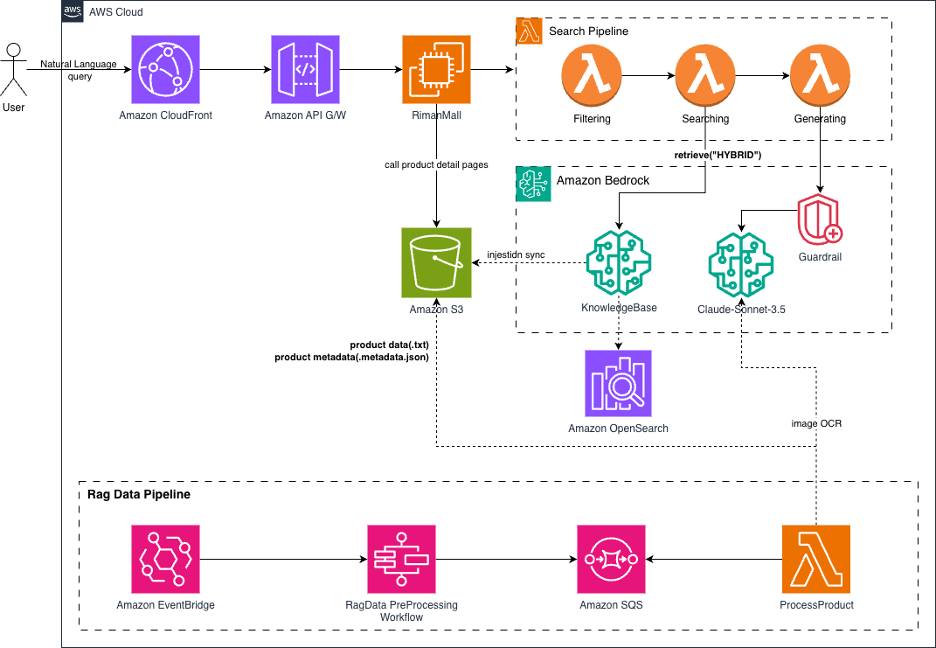
<그림 1. 솔루션 아키택처>
자연어 검색 시스템은 크게 두 부분으로 구성됩니다. 사용자의 자연어 쿼리를 처리하는 Search Pipeline과, 검색 대상이 되는 RAG 데이터를 생성하는 RAG Data Pipeline입니다.
Search Pipeline — 사용자 요청 처리
리만몰에서 발생한 사용자의 검색 요청을 받아 의도를 분석하고, 하이브리드 검색과 응답 생성을 수행하는 실시간 처리 흐름입니다. 사용자의 요청은 Amazon CloudFront와 Amazon API Gateway를 거쳐 리만몰 애플리케이션에 도달한 뒤, Search Pipeline으로 전달됩니다.
| 구성 요소 | 역할 |
|---|---|
| Amazon CloudFront + Amazon API Gateway | 사용자 요청 수신 및 라우팅 |
| Filtering Lambda | 쿼리에서 브랜드, 가격대 등 필터 조건 추출 |
| Searching Lambda | Amazon Bedrock Knowledge Bases의 Retrieve(“HYBRID”) API 호출 |
| Amazon OpenSearch Serverless | 벡터 인덱스 저장소 |
| Generating Lambda | Anthropic Claude 3.5 Sonnet 기반 자연어 응답 생성 |
| Amazon Bedrock Guardrails | 부적절한 응답 필터링 |
RAG Data Pipeline — 검색 데이터 준비
상품 데이터를 수집, 정제, 구조화하여 Amazon Bedrock Knowledge Bases에 임베딩 가능한 형태로 준비하는 배치 처리 흐름입니다. Amazon EventBridge의 이벤트 트리거로 파이프라인이 시작되며, 여러 AWS Lambda 함수를 순차적으로 실행합니다.
| 단계 | 역할 |
|---|---|
| Amazon EventBridge | 파이프라인 트리거 (수동 또는 증분 동기화) |
| Collect Lambda | RIMAN Database와 Amazon S3(Product Detail Pages)에서 상품 메타데이터 및
상세페이지 이미지 수집 |
| Transform Lambda | 이미지에서 텍스트 추출 및 데이터 변환 |
| Validate Lambda | 변환 데이터의 품질 검증 |
| Generate Lambda | 최종 RAG 데이터를 생성하여 Amazon S3에 업로드 |
| Amazon Bedrock Knowledge Bases 동기화 | 업로드된 데이터를 Amazon OpenSearch Serverless에
인덱싱 |
각각의 부분을 조금 더 자세히 알아보겠습니다.
Search Pipeline 구성
팀원 중 RAG나 Agent 기술 경험이 있는 사람은 없었습니다. 빠르게 MVP를 구축하기 위해 Amazon Bedrock Knowledge Bases(이하 Bedrock KB)를 선택하였습니다. RAG 프로세스를 위한 Vector DB, Embedding Model 등을 직접 구성하지 않아도 임베딩, 청킹, 검색(Retrieval)의 전체 단계를 서비스 내에서 선택하는 방식으로 구현할 수 있기 때문입니다. 콘솔에서 Amazon Bedrock Knowledge Bases 생성이 완료되면, 제공되는 API를 통해 간편하게 호출 할 수 있습니다.
검색 정확도가 가장 높은 설정값을 찾기 위해, EBA Sprint 2에서는 각 팀원들이 생성한 Amazon Bedrock Knowledge Bases의 경진대회로 진행 되었습니다. 사용자가 실제로 입력하는 질문과, 검색 결과를 정의한 494개의 테스트케이스를 바탕으로 가장 정확도가 높은 Amazon Bedrock Knowledge Bases를 선정하였습니다.
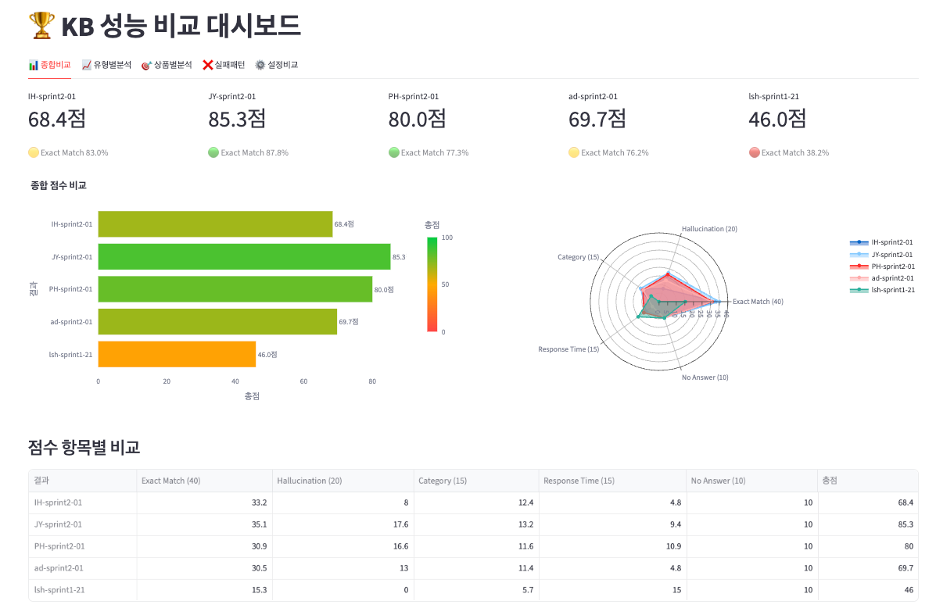
<그림 2. KB 성능 비교 대시보드>
최종적으로 선정된 Amazon Bedrock Knowledge Bases의 구성은 다음과 같습니다.
- LLM 모델: Anthropic Claude 3.5 Sonnet v2
- Embedding 모델: Amazon Titan Embeddings V2
- 청킹 전략: No Chunking
- 벡터 저장소: Amazon OpenSearch Serverless
청킹 전략
수차례 실험 결과, 모델의 응답 정확도와 가장 연관이 깊은 속성은 청킹 전략 이었습니다. 청킹 전략은 임베딩 데이터셋 과 밀접하게 관계되어 있기 때문에, 리만코리아가 관리하는 상품 데이터 셋의 특성을 명확하게 이해하는 것이 중요하였습니다.
리만코리아의 상품 데이터는 하나의 상품이 하나의 문서로 구성되어 있습니다. 일반적인 RAG 시나리오에서는 긴 문서를 여러 청크로 분할하여 검색 정밀도를 높이지만, 상품 검색의 경우 하나의 상품 정보가 여러 청크로 나뉘면 검색 시 맥락이 손실되었습니다. 예를 들어 “병풀 크림”으로 검색했을 때, 성분 정보가 담긴 청크와 제품명이 담긴 청크가 분리되어 관련 상품을 올바르게 매칭하지 못하는 문제가 발생하였습니다. 상품 단위의 원자성을 유지하는 No Chunking 전략을 적용하자 이 문제가 해결되었습니다.
다만 No Chunking 전략에는 제약이 있습니다. 선택한 임베딩 모델의 최대 입력 토큰 수에 따라 처리할 수 있는 문서 크기가 제한됩니다. Amazon Titan Text Embeddings V2의 경우 최대 8,192 토큰을 지원하므로, 전처리 단계에서 상품별 텍스트 문서의 크기를 이 한도 이내로 유지해야 합니다. 이를 위해 뒤에서 설명할 데이터 파이프라인의 정제 단계에서 검색에 불필요한 텍스트를 충분히 제거하는 것이 중요하였습니다.
RAG 기반 검색 기능의 한계
Amazon Bedrock Knowledge Bases의 RetrieveAndGenerate() API를 사용하면 검색과 LLM 응답 생성을 한 번의 호출로 처리할 수 있습니다. 초기에는 이 API를 사용하여 빠르게 프로토타입을 구성하였습니다.
그러나 두 가지 문제가 발생하였습니다.
첫째, 속도 문제입니다. 목표 응답 시간은 3초 이내였으나 실제 응답 시간은 약 10초가 소요되었습니다. RetrieveAndGenerate()는 검색과 응답 생성을 순차적으로 처리하기 때문에 지연이
누적되었습니다.
둘째, 답변 정확도의 편차가 심하였습니다. 특히 키워드가 명확한 질문에 대해 응답 품질이 일정하지 않다는 문제가 있었습니다. 모든 답변이 에이전트의 자율적 판단에 의존하였기 때문이었습니다. 정답이 명확한 키워드 질문(예를 들어 특정 상품명만 입력시 답변이 매번 다르게 나옴)에 대해 일관된 답변이 나올 수 있도록 하기 위해 다른 접근이 필요했습니다.
해결 1: 하이브리드 검색 구현
벡터 유사도 기반의 시맨틱 검색 만으로는 키워드 검색시 답변의 일관성 문제를 해결할 수 없었기 때문에, Amazon Bedrock KB에서 제공하는 HYBRID 검색 타입을 사용하였습니다. 하이브리드 방식은 Vector Embedding 기반의 Semantic Search와 원본 텍스트 기반의 Lexical Search를 결합한 방식입니다. Amazon Bedrock KB에서는 Retrieve() API 호출만으로 위 2개의 검색을 수행하고, 그 결과를 결합하여 최종 랭킹 순으로 결과를 반환합니다. 다만, 시맨틱 검색과 키워드 검색의 가중치가 50:50으로 고정되어 있어 튜닝이 불가능 하였습니다. 또한, OpenSearch에서 제공하는 다양한 쿼리 API를 직접 사용할 수 없어 “ICD 브랜드 중 병풀이 함유된 크림”과 같이 범위 제약이 명확한 요청을 직접 처리하기 어려웠습니다.
이러한 한계는 메타데이터 필터링으로 보완 하였습니다. 브랜드, 세트 여부, 가격대 등의 조건으로 검색 범위를 축소하여 검색 정확도와 응답 속도를 개선하였습니다. retrieve API 호출 시 filter parameter를 추가하여 간단하게 구현할 수 있었습니다.
다음 코드는 메타데이터 필터를 적용한 하이브리드 검색 API 호출 예시입니다.
위 호출은 브랜드가 “ICD”인 상품만 필터링한 뒤, 하이브리드 검색으로 상위 5건을 반환합니다. 필터링을 통해 검색 범위가 축소되어 응답 속도가 빨라지고, 관련성이 낮은 결과가 사전에 제외되어 정확도도 함께 개선됩니다.
해결 2: 검색 에이전트 구현
RetrieveAndGenerate()의 속도와 정확도 문제를 근본적으로 해결하기 위해 검색 흐름을 직접 설계 하였습니다. 사용자 쿼리를 받아 의도를 분류하고, 적절한 검색 전략을 선택하여 응답을 생성하는 에이전트를 구현하였습니다.
1단계: 쿼리 의도 분류
사용자 쿼리를 4가지 카테고리로 분류하였습니다. 상품 검색, 성분 문의, 가격 비교, 기타입니다. Amazon Bedrock의 Claude Sonnet을 활용하여 의도를 분류하고, 동시에 필터 조건(가격, 브랜드, 세트 여부)을 추출하였습니다. 사용자의 자연어 입력은 검색에 최적화된 형태로 재작성 하였습니다.
2단계: 병렬 처리를 통한 응답 시간 최적화
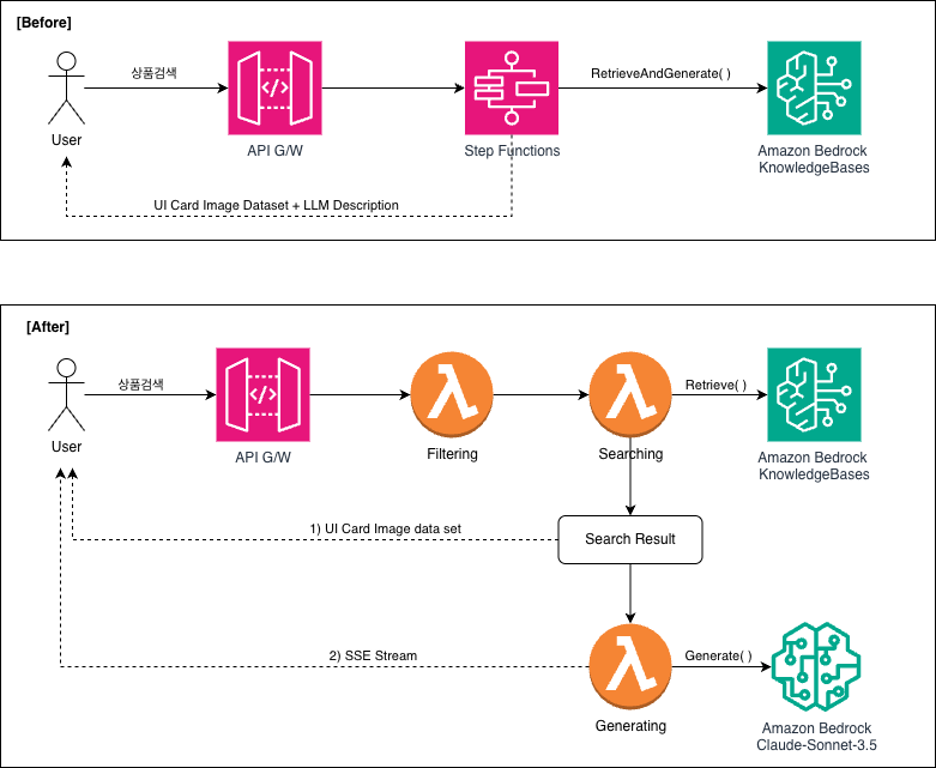
<그림 3. 병렬처리 개선 아키택처>
응답 속도를 높이기 위해 검색(Retrieve)과 응답 생성(Response Generation)을 순차 처리하던 구조를 병렬 처리 구조로 변경하였습니다. 기존 RetrieveAndGenerate() API는 내부 검색이 완료된 후, LLM이 응답을 생성하기 시작하는 방식이어서, 두 단계의 처리 시간이 그대로 누적되는 한계가 있었습니다.
초기 설계에서는 AWS Step Functions로 워크플로를 구성하여 두 작업을 병렬로 호출하고자 하였으나, 실제 구현 과정에서 두 가지 제약이 확인되었습니다.
- 첫째, Step Functions는 병렬 분기(Parallel State)의 결과를 모두 취합한 후 반환하는 방식이어서, 먼저 끝난 작업의 결과를 즉시 사용자에게 전달하는 스트리밍 구조와 맞지 않았습니다.
- 둘째, Step Functions 자체가 SSE(Server-Sent Events) 기반의 실시간 응답 전송을 지원하지 않아, 사용자가 LLM의 응답을 한 글자씩 받아보는 타이핑 효과를 구현할 수 없었습니다.
이러한 제약을 해소하기 위해 워크플로 오케스트레이션을 거치지 않고, 검색과 응답 생성을 각각 독립된 AWS Lambda 함수로 분리하여 동시에 호출하는 구조로 변환 하였습니다. Lambda는 요청이 들어올 때만 실행되는 서버리스 방식이므로, 상시 실행되는 컨테이너를 운영할 때보다 인프라 비용을 크게 절감할 수 있습니다.
이렇게 분리된 구조에서는 검색 결과가 준비되는 즉시 상품 카드 형태의 UI로 사용자에게 전달되고, 이와 병렬로 수행되는 LLM의 응답은 생성되는 순서대로 SSE 스트리밍을 통해 화면에 점진적으로 표시됩니다. 사용자는 전체 응답이 완성될 때까지 기다릴 필요 없이 결과를 먼저 확인할 수 있게 되었으며, 그 결과 목표였던 3초 이내 응답 시간을 안정적으로 달성할 수 있었습니다.
데이터 소스 연결 및 동기화
Amazon Bedrock Knowledge Bases의 데이터 소스는 전처리 파이프라인이 결과물을 업로드하는 S3 버킷의 특정 프리픽스를 지정하여 연결합니다. 파이프라인이 상품별 .txt 파일과 .metadata.json파일을 S3에 업로드하면, 데이터 파이프라인의 eba-kb-sync Lambda가 Amazon Bedrock Knowledge Bases의 start_ingestion_job() API를 호출하여 동기화를 트리거합니다.
다음 코드는 동기화를 트리거하는 eba-kb-sync Lambda 함수의 핵심 로직입니다.
동기화가 완료되면 시스템이 데이터 파이프라인의 검증 Lambda를 자동으로 실행합니다. 검증은 동기화된 상품의 메타데이터를 기반으로 테스트 쿼리를 동적으로 생성하고, 실제 검색을 수행하여 해당 상품이 결과에 포함되는지 확인합니다. 상품별로 다음과 같이 3가지 유형의 테스트 쿼리를 생성합니다.
전체 동기화 시에는 브랜드별로 3개 상품을 샘플링하여 검증하고, 증분 동기화 시에는 해당 상품 전체를 검증합니다. 시스템이 검증 결과를 S3에 상세 JSON으로 저장하고, SNS를 통해 팀 Slack 채널에 요약 알림을 전송합니다. 검증 실패 시에는 실패한 상품명과 테스트 쿼리, 실제 검색 결과 상위 3건을 함께 표시하여 원인을 빠르게 파악할 수 있습니다.
RAG Data Pipeline 구현
RAG 기반의 자연어 검색을 구현하려면 상품에 대한 정보를 수집하고 구조화하는 과정이 필요합니다. 특히 사용자가 주로 입력하는 정보를 포함하기 위하여 데이터를 수집하고 처리한 후 Embedding 하기 위한 파이프라인을 구성하였습니다.
데이터 준비 및 전처리
리만코리아가 보유한 화장품 상품 데이터에는 특수성이 있었습니다. 제형, 사용법, 성분, 효능 등 사용자의 관심사와 관련된 정보가 이미지 파일로 관리된다는 점이었습니다. 반면 상품명, 상품 가격, 브랜드, 카테고리 등의 메타정보는 DB에서 관리되고 있었습니다. 데이터 준비의 첫 단계는 두 개의 데이터 소스를 결합하여 검색에 적합한 형태로 변환하는 것에서부터 시작하였습니다.
전처리 파이프라인 설계
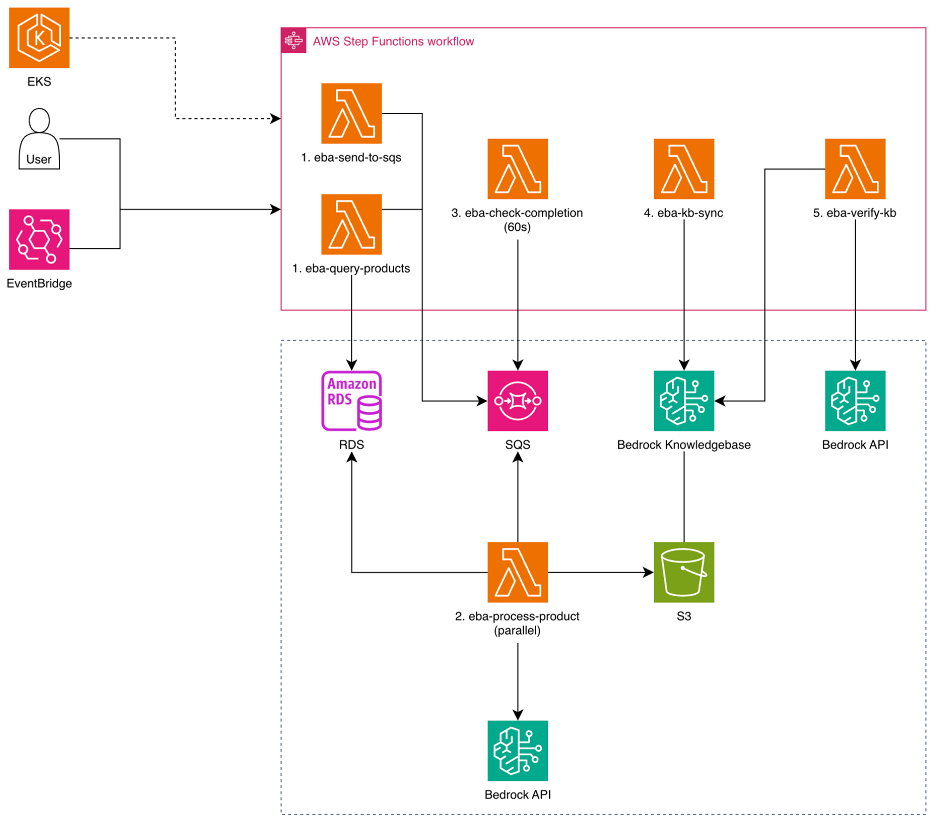
<그림 4. 병렬처리 개선 아키택처>
데이터 전처리는 AWS Step Functions로 오케스트레이션되는 서버리스 파이프라인으로 구성하였습니다. 전체 파이프라인은 5단계로 동작합니다.
- 1단계:
eba-query-products— RDS에서 전처리 대상 상품 ID 목록을 조회합니다. - 1단계(계속):
eba-send-to-sqs - 2단계:
eba-process-product— SQS에서 상품 ID를 수신하여 OCR + HTML 추출 + S3 업로드를 수행합니다 (병렬 5개). - 3단계:
eba-check-completion— SQS 큐의 잔여 메시지 수를 확인하여 전체 처리 완료 여부를 판정합니다. - 4단계:
eba-kb-sync— Amazon Bedrock Knowledge Bases의 데이터 소스 동기화(ingestion)를 트리거합니다. - 5단계:
eba-verify-kb— 동기화된 상품이 실제로 검색 가능한지 테스트 쿼리로 검증합니다.
AWS Step Functions는 두 가지 실행 모드를 지원합니다. 전체 동기화(full sync)는 입력 파라미터 없이 실행하면 RDS의 전체 상품을 대상으로 처리합니다. 증분 동기화(incremental)는 {"product_ids": ["상품ID1", "상품ID2"]} 형태로 특정 상품만 지정하여 실행할 수 있습니다. 이 구조 덕분에 신규 상품 등록이나 기존 상품 정보 수정 시에도 전체를 재처리하지 않고 해당 상품만 빠르게 반영할 수 있습니다.
멀티모달 OCR: 이미지에서 텍스트 추출
파이프라인의 핵심은 2단계의 eba-process-product Lambda입니다. 이 함수는 상품별로 다음 작업을 수행합니다.
- Amazon RDS에서 상품 상세 데이터 조회: 상품명, 브랜드, 가격, 카테고리, 상세 이미지 HTML, 제품설명 HTML 등 12개 이상의 필드를 가져옵니다.
- 상세 이미지 HTML에서 이미지 URL 추출:
<img>태그의src속성을 파싱합니다. GIF, MP4 등 비이미지 파일은 제외합니다. - 이미지 다운로드 및 전처리: 긴 이미지의 경우 자동 분할 처리를 적용합니다.
- Amazon Bedrock Claude Sonnet 3.5 v2로 OCR 수행: 이미지를 텍스트로 변환합니다.
- HTML 텍스트 추출 및 정제: 제품설명 탭의 HTML에서 순수 텍스트를 추출합니다.
- S3 업로드: 상품 정보 텍스트(
.txt)와 메타데이터(.metadata.json)를 생성하여 업로드합니다.
OCR에 일반적인 텍스트 인식 서비스 대신 Claude Sonnet 3.5 v2 멀티모달 모델을 선택한 이유는 화장품 상세페이지의 특성 때문이었습니다. 상세페이지 이미지는 표준화된 레이아웃이 아닌 브랜드별로 다양한 디자인이 적용되어 있었고, 텍스트가 배경 이미지 위에 겹쳐져 있거나 곡선형 배치를 사용하는 경우가 많았습니다. 기존 OCR 서비스로는 이러한 이미지에서 의미 단위로 텍스트를 묶어 추출하는 것이 어려웠습니다. 반면 Claude Sonnet은 이미지의 시각적 맥락을 이해하여 “성분 설명”, “사용법”, “효능” 등의 의미 단위로 텍스트를 그룹핑하여 추출할 수 있었습니다.
긴 이미지 분할 처리
화장품 상세페이지는 세로로 매우 긴 이미지(높이 5,000px 이상)로 제작되는 경우가 많습니다. 멀티모달 모델의 입력 이미지 크기에는 제한이 있으므로, 긴 이미지를 자동으로 분할하여 처리하는 로직을 구현하였습니다.
다음 코드는 긴 이미지를 자동으로 분할하는 함수의 구현 예시입니다. 이미지 경계에서 텍스트가 잘리는 문제를 방지하기 위해 분할 시 400px의 겹침 영역(overlap)을 두었습니다. 또한 Bedrock API의 호출 효율을 위해 최대 5장의 이미지를 하나의 요청으로 묶어 배치 처리하였습니다.
OCR 프롬프트 엔지니어링
화장품 도메인에 특화된 OCR 정확도를 확보하기 위해 시스템 프롬프트를 정교하게 설계하였습니다. 주요 지침은 다음과 같습니다.
- 한글 자모 구분: ㅈ/ㅊ, ㅂ/ㅍ, ㄱ/ㅋ 등 유사 자모의 정확한 인식
- 화장품 전문 용어 우선: “차전자피”, “셀레늄”, “항산화” 등 성분명을 일반 단어보다 우선 적용
- 한약재 성분명 인식: “용안육”, “오미자”, “맥문동” 등 전통 원료명 인식
- 유사 글자 혼동 방지: “피부”→”찌푸”, “항산화”→”양산화” 등의 오인식 사전 차단
프롬프트는 S3에 JSON 파일로 관리하여, Lambda 코드를 재배포하지 않고도 프롬프트를 수정할 수 있도록 하였습니다. 또한 OCR 결과에 대해 도메인별 사전 기반의 후처리 교정 단계를 추가하여 반복적으로 발생하는 오인식 패턴을 자동 보정하였습니다.
데이터 정제 및 구조화
OCR로 추출한 텍스트와 HTML에서 파싱한 텍스트는 검색 품질에 직접적인 영향을 미치므로, 불필요한 정보를 제거하는 정제 과정을 거칩니다. 주문취소 안내, 배송 정보, 반품/교환 기준, 임상시험 데이터, 제조원/판매원 정보 등 검색에 불필요한 내용은 패턴 매칭을 통해 제거하였습니다.
최종적으로 상품별 두 가지 파일을 생성합니다.
상품 정보 텍스트 (.txt):
메타데이터 (.metadata.json):
이후 Amazon Bedrock Knowledge Bases의 메타데이터 필터링에 이 메타데이터 파일을 활용합니다. 브랜드, 세트 여부, 가격대 등의 조건으로 검색 범위를 축소하여 정확도를 높이는 데 핵심적인 역할을 합니다. Bedrock KB의 제약으로 빈 문자열(“”)은 메타데이터 속성값으로 허용되지 않으므로, 값이 비어 있는 필드는 자동으로 제외하도록 처리하였습니다.
파이프라인 자동화
상품 정보는 수시로 추가되거나 업데이트될 수 있으므로, 두 가지 트리거를 구성하였습니다.
- 첫째, Amazon EventBridge를 통한 수동 트리거입니다. 관리자의 실행을 통해 전체 동기화를 실행할 수 있습니다.
- 둘째, 상품 관리 시스템과 연동한 자동 트리거입니다. 향후 시스템 연계를 통해 상품 등록 또는 수정 이벤트 발생 시 해당 상품의 ID만 전달하여 증분 동기화가 자동으로 실행되도록 확장할 계획입니다.
SQS 기반의 메시지 분배와 Lambda의 동시 실행(최대 5개)을 활용하여 병렬 처리를 구현하였으며, 처리 실패 시에는 시스템이 메시지를 Dead Letter Queue(DLQ)로 이동하여 최대 3회까지 재시도합니다. Step Functions는 SQS 큐의 잔여 메시지 수를 60초 간격으로 폴링하여 전체 처리 완료를 판정하고, 완료 후 자동으로 Amazon Bedrock Knowledge Bases 동기화 단계로 진행합니다.
결론 및 향후 계획
팀이 이번 개발을 통해 얻은 교훈은 다음과 같습니다.
- 청킹 전략이 검색 정확도를 결정합니다. 화장품 상품 데이터는 일반적인 문서와 성격이 다릅니다. 하나의 상품 정보가 여러 청크로 분리되면 검색 시 맥락이 손실됩니다. 상품 단위의 원자성을 유지하는 No Chunking 전략이 가장 효과적이었습니다.
- 임베딩 모델보다 데이터 품질이 중요합니다. 전처리 단계에서 데이터 품질을 높이는 것이 임베딩 모델을 교체하는 것보다 검색 품질 개선에 효과적이었습니다. 상품 이미지에서 텍스트를 정확하게 추출하고, 검색에 적합한 형태로 구조화하는 과정에 가장 많은 시간을 투자하였습니다.
- 하이브리드 검색의 가중치는 쿼리 패턴에 따라 달라야 합니다. 자연어 쿼리는 벡터 검색의 비중을 높이고, 상품명을 직접 입력한 경우에는 키워드 검색의 비중을 높이는 것이 이상적입니다. Amazon Bedrock Knowledge Bases의
Retrieve()API는 현재 가중치 조정을 지원하지 않으므로, 향후 고도화 시 Amazon OpenSearch Service를 직접 호출하는 방식으로 전환을 검토하고 있습니다. - 피드백 루프가 검색 품질을 지속적으로 개선합니다. 검색 결과가 없는 쿼리를 수집하고, 해당 쿼리에 대응하는 상품 데이터를 강화한 뒤 재 임베딩하는 순환 구조를 구성 하였습니다. 이 루프를 통해 시간이 지날수록 검색 품질이 개선되는 구조를 만들었습니다.
- EBA 프로그램은 기술 격차를 빠르게 해소합니다. AI/ML 개발 경험이 없는 5인 팀이 5주 만에 운영 가능한 자연어 검색 시스템을 구축하였습니다. AWS가 One-Team으로 함께 구축하면서 기술을 전수하는 EBA의 구조가 이를 가능하게 하였습니다.
이 경험이 AI에 대한 지식과 경험이 없어도 빠르게 서비스 도입을 원하는 팀에게 도움이 되길 바랍니다.