AWS 기술 블로그
Amazon EC2 G5/G6 인스턴스에서 GPU Tensor Parallelism으로 비용 효과적으로 LLM 서빙하기
최근 많은 기업들이 자체 LLM을 구축하거나, 오픈소스 sLLM(Small Large Language Model)을 활용하여 설치형 LLM서비스를 구성하려는 수요가 크게 증가하고 있습니다. 그런데 실제로 배포하려는 모델을 살펴보면, Llama 3 70B, Qwen 72B, EXAONE 3.5 32B 등 모델을 GPU에 로드할 때 필요한 메모리가 40GB에서 최대 150GB에 달하는 경우가 많아, GPU 메모리가 80GB인 H100/H200이 탑재된 Amazon P5 인스턴스 이상을 요청하는 사례가 일반적입니다.
하지만 현실적으로 H100/H200 GPU는 전 세계적인 수요 급증으로 인해 확보가 쉽지 않으며, 온프레미스에서도 마찬가지입니다. 그렇다면 이 모델들을 서빙하려면 반드시 고가의 대형 GPU가 필요할까요?
본 글에서는 Tensor Parallelism(TP) 기법을 활용하면, GPU 메모리가 상대적으로 작은 Amazon EC2 G5/G6 인스턴스(NVIDIA A10G/L4 GPU, GPU 당 24GB 메모리)에서도 여러 장의 GPU에 모델을 분산 배치하여 파라미터 수가 큰LLM을 충분히 서빙할 수 있음을 실측 데이터와 함께 보여드립니다. 나아가, 동시 사용자가 늘어나는 환경에서 다중 GPU 병렬 처리가 전체 처리량(Throughput)을 크게 높일 수 있다는 점도 함께 검증합니다.
1. 왜 G5/G6에서 Tensor Parallelism인가
현재 상황: 대형 LLM과 GPU 확보의 어려움
오픈소스 LLM 생태계가 빠르게 성장하면서, 기업들이 배포하려는 모델의 크기도 커지고 있습니다. BF16(Brain Floating Point 16)은 16비트 부동소수점 데이터 형식으로, 모델 가중치 하나를 2바이트로 표현합니다. FP32(32비트, 4바이트) 대비 메모리를 절반만 사용하면서도 학습/추론 정확도를 거의 유지하는 것이 특징입니다. BF16 정밀도 기준으로 주요 모델의 GPU 메모리 요구량을 살펴보면:
| 모델 | 파라미터 | BF16 메모리 | BF16 메모리 산정 근거 | 단일 GPU 요구사양 |
| Llama 3.1 8B | 8B | ~16GB | 8B × 2 bytes = 16GB | A10G (24GB) 1장 가능 |
| Qwen 2.5 32B | 32B | ~64GB | 32B × 2 bytes = 64GB | A10G (24GB) 1장 불가, H100 (80G) 필요 |
| Llama 3.1 70B | 70B | ~140GB | 70B × 2 bytes = 140GB | H100 (80G) 1장으로도 불가, 2장 필요 |
| EXAONE 3.5 32B | 32B | ~64GB | 32B × 2 bytes = 64GB | A10G (24GB) 1장 불가, H100 (80G)필요 |
32B 이상의 모델은 단일 A10G/L4(24GB)에 올릴 수 없어, 고객들은 자연스럽게 H100(80GB)이 탑재된 P5 이상의 인스턴스를 요청하게 됩니다. 하지만 H100/H200은 글로벌 공급 부족 상황이 지속되고 있습니다.
Tensor Parallelism: 작은 GPU 여러 장으로 큰 모델 서빙하기
Tensor Parallelism(TP)은 모델의 Transformer Tensor 연산을 여러 GPU에 걸쳐 분할하는 기법입니다. 각 GPU는 모델 파라미터의 일부만 보유하고, 레이어마다 All-Reduce 통신으로 중간 결과를 동기화하는 방식으로 진행됩니다.
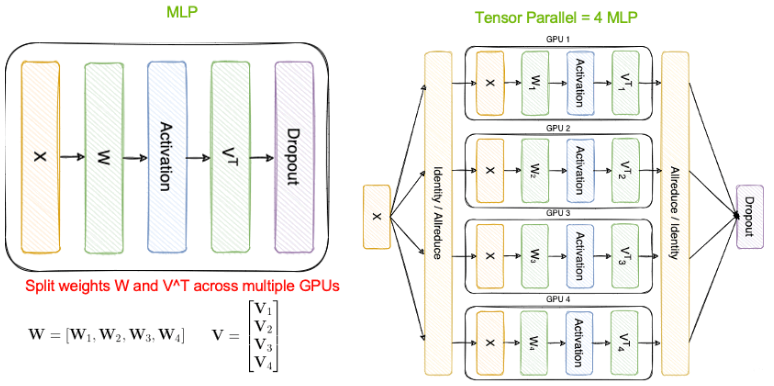
[그림1] Tensor Parallelism개념
Tensor Parallelism은 위의 그림에서 처럼, 하나의 GPU에서 했던 MLP(Multi-Layer Perceptron, 다층 퍼셉트론) Operation을, W와 VT 벡터의 내용을 더 작은 벡터로 쪼갠 다음에 각각의 벡터에 대한 Tensor Operation을 여러개의 GPU에서 병렬로 처리하는 방식입니다.
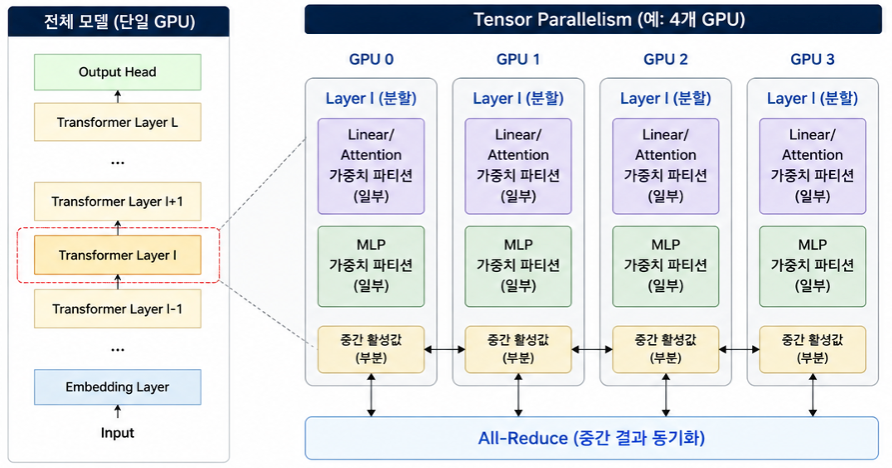
[그림2] Multi-Transformer Layer 환경의에서 Tensor Parallelism 적용 개념
그리고 이 방식은 Transformer 여러 개가 존재하는 레이어에서도 일관되게 적용할 수 있습니다.
vLLM은 PagedAttention과 Continuous Batching 기술을 활용해 대규모 언어모델(LLM)을 고속·고효율로 서빙할 수 있도록 만든 오픈소스 추론 엔진입니다. vLLM은 GPU 아키텍처를 네이티브로 인지하기 때문에, vLLM을 이용해서 GPU 장비에 LLM을 설치해서 적용할 경우에는, vLLM의 Tensor Parallelism을 통해서 이 기능을 사용할 수 있습니다.
예를 들어, 64GB 크기의 32B 모델을 TP=4로 구성하면:
- GPU당 약 16GB (=64GB/4) 의 모델 파라미터 (Parameter Memory)만 적재 (24GB GPU에 충분히 수용)
- 나머지 ~8GB/GPU (=24GB-16GB) 를 KV Cache와 활성화 메모리 (Activation Memory)에 활용
- vLLM이 자동으로 weight를 분산하므로 별도 코드 수정 불필요
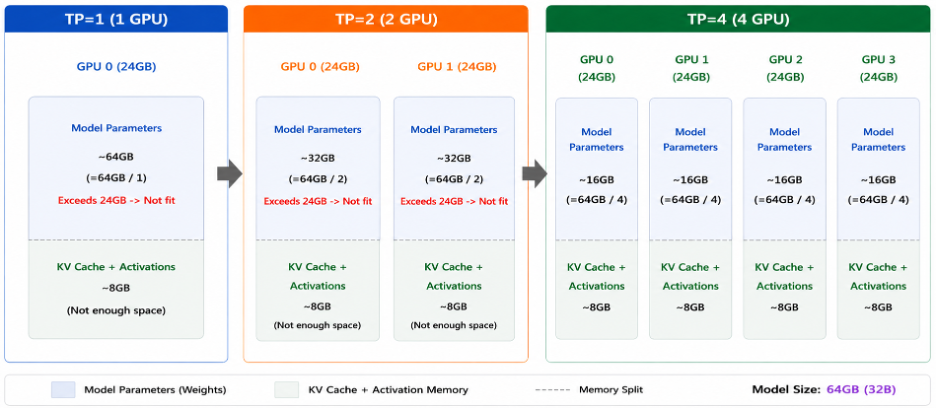
[그림3] TP=1, TP=2, TP=4 구성별 모델 분산 개념도
이 접근법의 추가적인 장점은 응답 속도 향상입니다. 모델이 단일 GPU에 들어가는 8B급 모델이라 하더라도, Tensor Parallelism을 적용해서 여러장의 GPU를 병렬로 사용하게 되며 연산을 분산하여 개별 토큰 생성 속도가 빨라집니다. 즉, TP는 “큰 모델을 올리기 위한 수단”일 뿐 아니라 “빠른 서빙을 위한 최적화 기법”이기도 합니다.
2. 테스트 환경 구성
본 테스트에서는 G5 인스턴스에 탑재된 NVIDIA A10G GPU(24GB) 4장을 사용하여, Qwen3-8B 모델을 TP=1(1 GPU), TP=2(2 GPU), TP=4(4 GPU) 구성으로 서빙하고 성능을 비교 측정하였습니다. 8B 모델을 선택한 이유는 TP=1에서도 동작하여 단일 GPU 대비 다중 GPU의 성능 차이를 직접 비교할 수 있기 때문입니다.
인프라
| Hardware | |
| Instance | Amazon EC2 G5.12xlarge (4x GPU) |
| GPU | NVIDIA A10G x 4 (24GB GDDR6X each) |
| Interconnect | PCIe Gen4 x16 |
| CPU | AMD EPYC 7R32 (48 vCPU) |
| Memory | 186GB DDR4 |
| Software | |
| OS | Ubuntu 24.04 LTS |
| NVIDIA Driver | 595.58.03 |
| CUDA | 13.2 |
| PyTorch | 2.11.0 |
| vLLM | 20.0 |
테스트 모델
| 항목 | 내용 |
| 모델 | Qwen/Qwen3-8B |
| 파라미터 | 약 80억 (8B) |
| 아키텍처 | Qwen3ForCausalLM (Transformer, GQA: 32 heads / 8 KV heads) |
| Precision | BF16 (양자화 미적용) |
| 크기 | ~16.4GB |
| Max Output | 512 tokens |
테스트 매트릭스
Q3가지 TP 구성(TP=1,2,4) x 4가지 동시성 수준(C=1,4,8,16) = 총 12가지 조합을 테스트했습니다. 이를 통해 GPU 수와 동시 사용자 수에 따른 성능 변화를 다차원으로 분석합니다.
| C=1 (단일 사용자) | C=4 (소규모 팀) | C=8 (중규모) | C=16 (대규모) | |
| TP=1 (1 GPU) | O | O | O | O |
| TP=2 (2 GPU) | O | O | O | O |
| TP=4 (4 GPU) | O | O | O | O |
3. 테스트 방법론
벤치마크 아키텍처
vLLM 추론 엔진으로 OpenAI API 호환 서버를 구성하고, Python의 비동기 프로그래밍 프레임워크인 asyncio와 비동기 HTTP 통신 라이브러리인 aiohttp를 활용하여 대량의 동시 요청(concurrent requests)을 효율적으로 생성합니다. 응답은 SSE(Server-Sent Events) 기반 스트리밍 방식으로 실시간 수신하며, 각 토큰의 생성 시점과 전송 지연 시간을 토큰 단위로 정밀 측정합니다.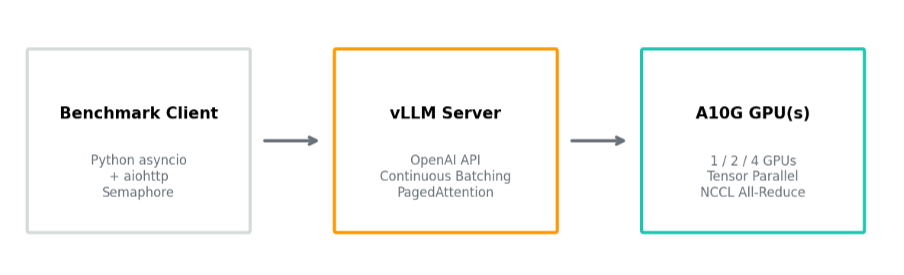
[그림4] 벤치마크 아키텍처: Client → vLLM Server → A10G GPU(s)
실행 절차
전체 벤치마크는 쉘 스크립트로 자동화됩니다. 각 TP 구성에 대해 다음 절차를 순차 실행합니다.

[그림5] 벤치마크 실행 절차 플로우
각 동시성 수준에서:
- Warmup 3회 – GPU 캐시 및 CUDA 커널 워밍업
- 벤치마크 15건 – 5종 프롬프트(한/영) x 3회 반복, 각 512 토큰 생성
- 결과 수집 – 요청별 상세 메트릭을 JSON으로 저장
테스트 워크로드
실제 사용 패턴을 반영한 5종의 프롬프트를 설계하였습니다. 한/영 구성은 실제 한국어 LLM 서빙 환경에서 자주 관찰되는 혼합 워크로드를 의도적으로 재현한 것입니다. 한국어 프롬프트(ko_*)는 자국어 추론·서술·코드 생성과 같이 길고 가변적인 출력이 발생하는 시나리오를, 영어 프롬프트(en_*)는 기술 문서·논문·레퍼런스 인용처럼 비교적 정형화된 입력이 주어지는 시나리오를 대표하도록 배치하였습니다. 두 언어는 토크나이저 경로와 토큰 길이 분포가 다르기 때문에, 동일 모델·동일 인스턴스에서도 처리량(TPS)·지연(latency) 특성에 차이가 나타날 수 있어 G5/P5 비교를 보다 입체적으로 평가할 수 있습니다.
| ID | 언어 | 유형 | 내용 |
| ko_explain | 한국어 | 기술 설명 | LLM Self-Attention 메커니즘 상세 설명 |
| ko_compare | 한국어 | 비교 분석 | GPU 인스턴스 학습 vs 추론 비교 |
| ko_code | 한국어 | 코드 생성 | Python 비동기 웹 크롤러 구현 |
| en_technical | 영어 | 기술 비교 | Tensor vs Pipeline Parallelism |
| en_summary | 영어 | 요약 | vLLM 아키텍처 및 PagedAttention |
측정 지표
| 지표 | 정의 | 의미 |
| TTFT | Time to First Token | 요청 전송 → 첫 토큰까지 시간. 체감 응답 시작 시간 |
| TPOT | Time Per Output Token | 첫 토큰 이후 각 토큰의 생성 시간. 텍스트 출력 속도 |
| Aggregate Throughput | 전체 처리량 | 시스템이 단위 시간당 생성하는 총 토큰 수 (tokens/s) |
| Per-Request Throughput | 요청당 처리량 | 개별 사용자가 체감하는 토큰 생성 속도 (tokens/s) |
| Total Time | 전체 소요 시간 | 요청 전송 → 마지막 토큰 수신까지 소요 시간 |
vLLM 서버 구동 예시
vLLM 명령을 통해서 아래와 같이 4장의 GPU를 이용해서 분산 서빙하는 것을 구성할 수 있습니다.
--tensor-parallel-size 옵션 하나만 변경하면 TP 구성을 전환할 수 있습니다. vLLM이 자동으로 모델 weight를 GPU에 분산하고 NCCL(NVIDIA Collective Communications Library) 통신 그룹을 초기화합니다.
vLLM 환경 구성을 위한 고려사항
이러한 테스트를 위하여 환경을 구성할 경우에는 고려해야 될 부분들이 있습니다. AMI(Amazon Machine Image)와 EC2인스턴스 등과 같은 사항들에 대해서 제대로 된 환경이 구성될 수 있도록, 아래와 같은 사항들이 고려되어야 합니다.
- AMI: AWS Deep Learning AMI GPU PyTorch (Ubuntu 22.04 이상 권고) — CUDA·NVIDIA 드라이버·Python 환경이 사전 구성되어 별도 설치 부담이 적습니다.
- 인스턴스: g5.12xlarge 이상 (A10G x 4) 또는 g6.12xlarge (L4 x 4). TP=4 구성을 위해 GPU가 4장인 인스턴스를 권장합니다.
- CUDA / 드라이버: CUDA 12.x, NVIDIA 드라이버 535 이상 권고(vLLM 최신 버전 호환 기준).
- vLLM 설치: 가상 환경 생성 후 `pip install vllm` 한 줄로 설치 가능. 모델 가중치는 Hugging Face Hub 또는 S3에서 사전 다운로드해 두면 첫 기동 시간을 단축할 수 있습니다.
- 참고 문서:
- AWS Deep Learning AMI 공식 문서: https://docs.aws.amazon.com/dlami/
- vLLM 공식 문서: https://docs.vllm.ai/en/latest/
- AWS ML 블로그: https://aws.amazon.com/blogs/machine-learning/
4. 성능 테스트 결과
4.1 vLLM 서버 Startup Time
TP 적용 시 weight 분산과 NCCL 초기화로 시작 시간이 증가하지만, 서버 최초 기동 시 1회성 비용입니다.
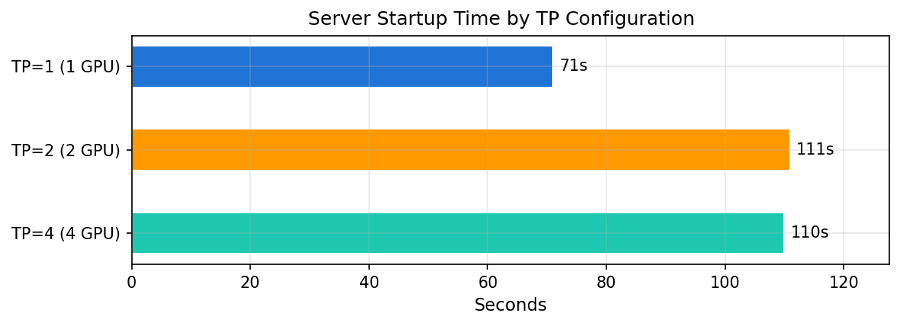
[그림6] TP 구성별 서버 Startup Time
| 구성 | GPU 수 | Startup Time | TP=1 대비 |
| TP=1 | 1장 | 71초 | – |
| TP=2 | 2장 | 111초 | +56.3% |
| TP=4 | 장 | 110초 | +54.9% |
4.2 토큰 생성 속도 (TPOT) – 사용자 체감 속도
TPOT(Time Per Output Token)는 Decode 단계에서 각 토큰이 생성되는 시간으로, 사용자가 텍스트가 나타나는 속도를 직접 체감하는 지표입니다. GPU를 추가할수록 연산이 분산되어 토큰 생성이 빨라집니다.
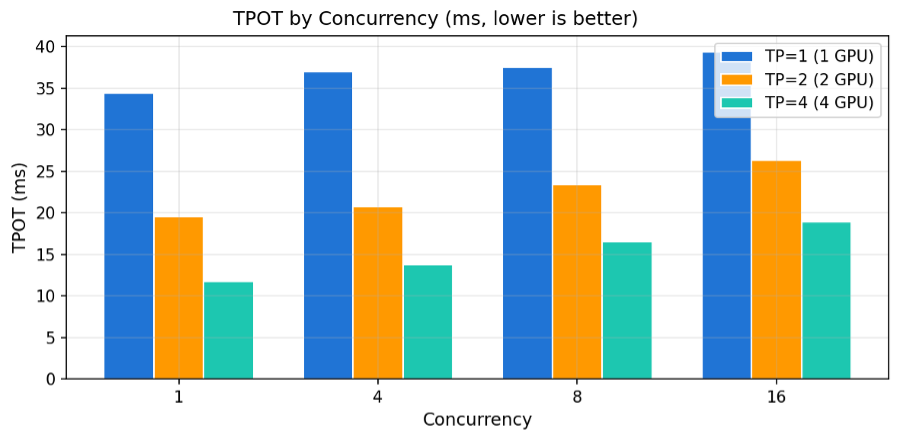
[그림7] 동시 사용자 수별 TPOT 비교 (ms, 낮을수록 좋음)
| 동시 사용자 | TP=1 (1 GPU) | TP=2 (2 GPU) | TP=4 (4 GPU) | TP=1 대비 TP=4 개선율 |
| 1명 | 34.4 ms | 19.6 ms | 11.8 ms | -65.7% |
| 4명 | 37.0 ms | 20.8 ms | 13.8 ms | -62.7% |
| 8명 | 37.6 ms | 23.4 ms | 16.5 ms | -56.1% |
| 16명 | 39.4 ms | 26.4 ms | 18.9 ms | -52.0% |
4.3 전체 처리량 (Aggregate Throughput) – 시스템 서빙 능력
Aggregate Throughput는 시스템 전체가 단위 시간당 생성하는 토큰 수로, 서비스 운영 관점에서 얼마나 많은 사용자를 동시에 서빙할 수 있는가를 나타내는 핵심 지표입니다.
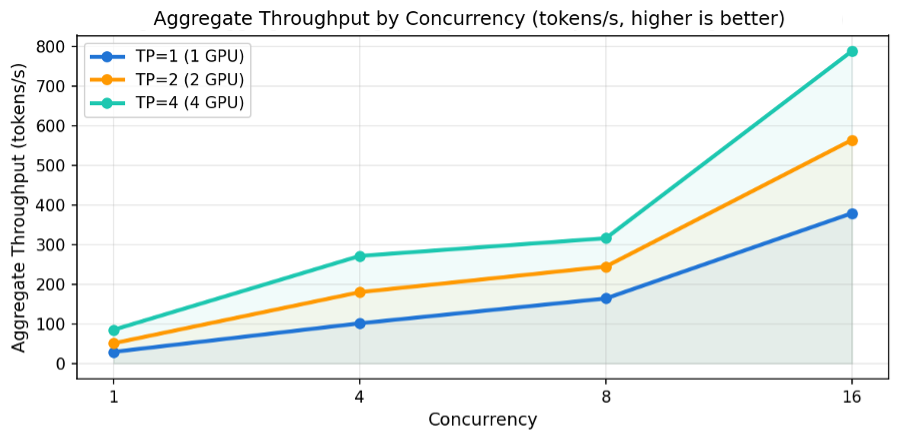
[그림8] 동시 사용자 수별 Aggregate Throughput (tokens/s, 높을수록 좋음)
| 동시 사용자 | TP=1 (1 GPU) | TP=2 (2 GPU) | TP=4 (4 GPU) | TP=4 vs TP=1 |
| 1명 | 29.0 t/s | 50.8 t/s | 84.7 t/s | +192% |
| 4명 | 101.0 t/s | 179.7 t/s | 271.1 t/s | +168% |
| 8명 | 163.7 t/s | 244.3 t/s | 315.7 t/s | +93% |
| 16명 | 378.8 t/s | 563.7 t/s | 787.9 t/s | +108% |
4.4 전체 응답 시간 – 사용자 대기 시간
512 토큰 응답을 받기까지 사용자가 기다리는 시간입니다.
GPU갯수가 많을수록 요청처리가 분산되어서, TP=4일 경우에 512토큰 응답이 더 빨라지고 있습니다.
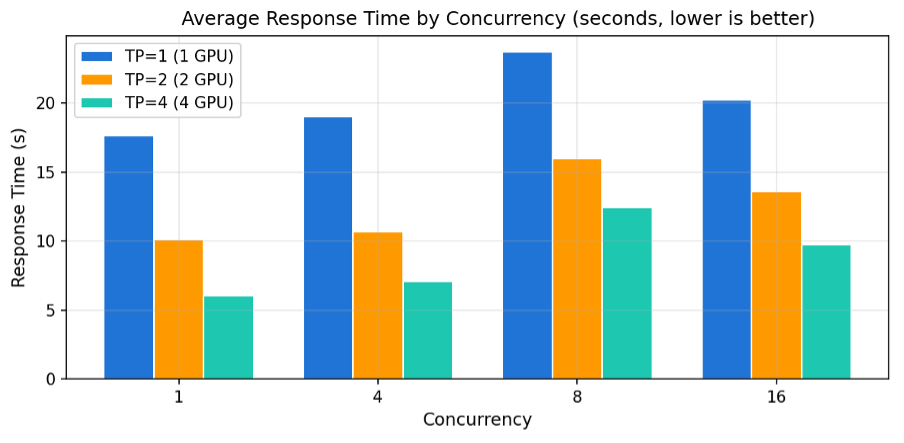
[그림9] 동시 사용자 수별 평균 응답 시간 (초, 낮을수록 좋음)
| 동시 사용자 | TP=1 | TP=2 | TP=4 | TP=1 대비 TP=4 단축 |
| 1명 | 17.6초 | 10.1초 | 6.0초 | 66% |
| 4명 | 19.0초 | 10.7초 | 7.1초 | -63% |
| 8명 | 23.7초 | 16.0초 | 12.4초 | -48% |
| 16명 | 20.2초 | 13.6초 | 9.7초 | -52% |
4.5 요청당 처리량 (Per-Request Throughput) – 개인 체감 속도
개별 사용자가 체감하는 토큰 생성 속도입니다. 동시 사용자가 늘어도 TP=4는 가장 빠른 개인 체감 속도를 유지합니다.
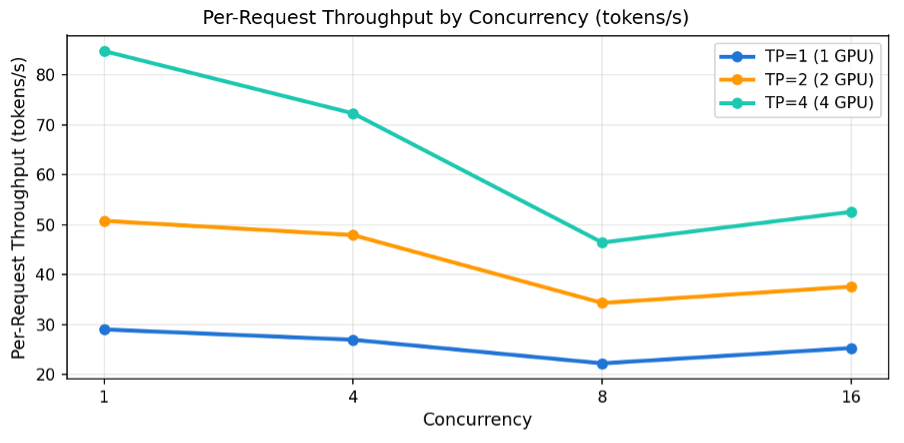
[그림10] 동시 사용자 수별 Per-Request Throughput (tokens/s)
| 동시 사용자 | TP=1 | TP=2 | TP=4 |
| 1명 | 29.0 t/s | 50.8 t/s | 84.7 t/s |
| 4명 | 27.0 t/s | 47.9 t/s | 72.3 t/s |
| 8명 | 22.2 t/s | 34.3 t/s | 46.4 t/s |
| 16명 | 25.3 t/s | 37.6 t/s | 52.6 t/s |
5. 심층 분석: 동시 사용자 증가 시 다중 GPU의 이점
단일 사용자 환경에서 TP의 이점은 “빠른 응답”입니다. 하지만 진정한 가치는 동시 사용자가 증가할 때 나타납니다. 다중 GPU가 동시 서빙에서 어떤 이점을 제공하는지 심층적으로 분석합니다.
5.1 Throughput Scaling: 동시 사용자 증가에 따른 처리량 변화
각 TP 구성에서 C=1 대비 처리량이 몇 배로 증가하는지를 보여줍니다. 점선은 이상적인 Linear Scaling(동시성 N배 → 처리량 N배)을 나타냅니다.
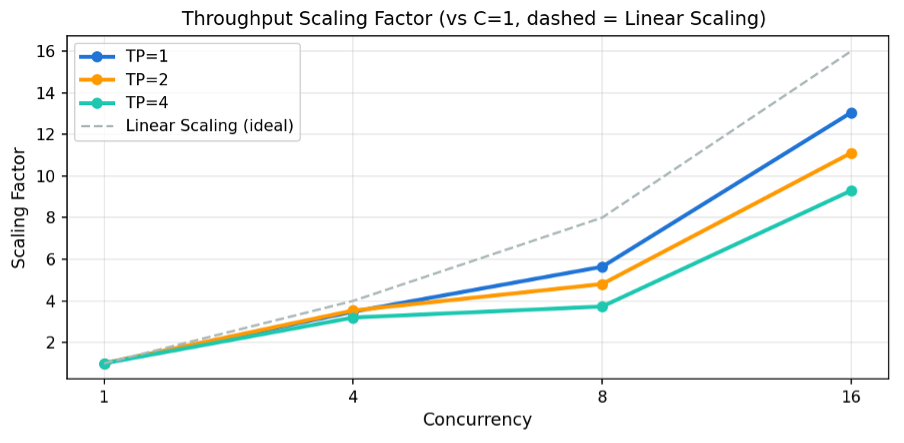
[그림11] Throughput Scaling Factor (C=1 대비 배수, 점선 = Linear Scaling)
| 동시 사용자 | 이상적 | TP=1 | TP=2 | TP=4 |
| 1 | 1x | 1.00x | 1.00x | 1.00x |
| 4 | 4x | 3.48x | 3.54x | 3.20x |
| 8 | 8x | 5.64x | 4.81x | 3.73x |
| 16 | 16x | 13.05x | 11.11x | 9.30x |
5.2 16명 동시 사용: GPU 1장 vs 4장 직접 비교
| A10G 1장으로 16명 서빙 (TP=1) | A10G 4장으로 16명 서빙 (TP=4) |
| 378.8 t/s | 787.9 t/s |
| 요청당 25.3 t/s | 응답 20.2초 | 요청당 52.6 t/s | 응답 9.7초 |
전체 처리량: 2.1배 향상 (787.9 vs 378.8 tokens/s)
응답 시간: 52% 단축 (9.7초 vs 20.2초)
개인 체감 속도: 2.1배 빠름 (52.6 vs 25.3 tokens/s)
5.3 GPU당 처리량 효율
GPU 투자 대비 효율을 분석합니다. GPU당 Throughput = 전체 Throughput / GPU 수.
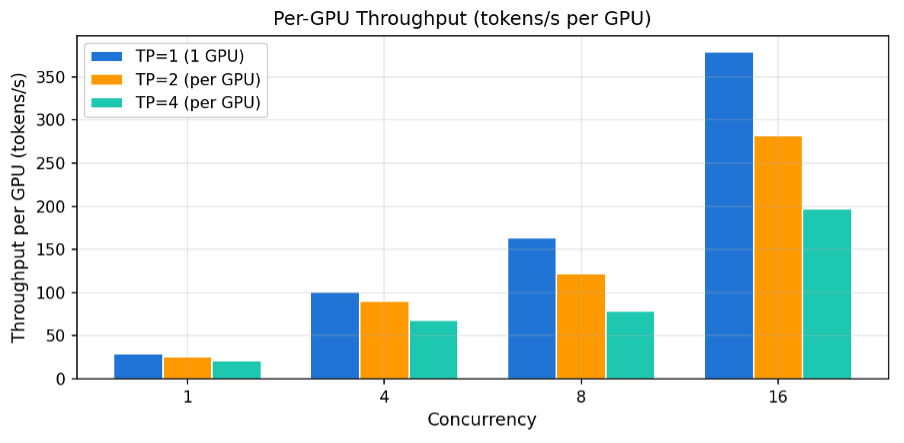
[그림12] GPU당 Throughput (tokens/s per GPU)
| 동시 사용자 | TP=1 (1 GPU) | TP=2 (GPU당) | TP=4 (GPU당) |
| 1 | 29.0 t/s | 25.4 t/s | 21.2 t/s |
| 4 | 101.0 t/s | 89.8 t/s | 67.8 t/s |
| 8 | 163.7 t/s | 122.2 t/s | 78.9 t/s |
| 16 | 378.8 t/s | 281.9 t/s | 197.0 t/s |
이 결과에서 알 수 있듯이, GPU당 효율은 사용하는 GPU 갯수가 작을수록 좋습니다. 다수의 GPU를 사용할수록 GPU당 효율은 명백하게 떨어지고 있습니다. 이러한 GPU당 효율 감소는 PCIe 환경의 All-Reduce 통신 오버헤드 때문입니다. NVLink 환경(P4d/P5의 A100/H100)에서는 GPU 간 대역폭이 수십 배 높아 이 효율 감소가 크게 줄어듭니다. 그럼에도 PCIe 환경에서 절대 처리량과 응답 속도 측면에서는 다중 GPU가 명확히 유리합니다.
5.4 다중 GPU가 동시 사용에 유리한 이유
다중 GPU 환경에서는 아래와 같은 요인들에 의해서 장점들이 있습니다.
- KV Cache 메모리 분산: Tensor Parallelism(TP)을 사용하면 모델 가중치와 함께 KV Cache도 여러 GPU 메모리에 분산 저장할 수 있습니다. 이를 통해 단일 GPU 메모리 한계를 넘어 더 긴 Context Length와 더 많은 동시 요청(concurrent requests)을 수용할 수 있습니다.
- 연산 병렬화: Batch 내 여러 요청을 처리할 때, 각 GPU가 모델의 일부만 담당하므로 토큰당 연산이 빨라집니다. 동시 요청이 늘어 Batch 크기가 커질수록 이 분산 연산의 이점이 더 크게 작용합니다.
- Continuous Batching 효율: vLLM의 Continuous Batching은 완료된 요청 슬롯에 즉시 새 요청을 투입합니다. TP를 통해 토큰 생성 속도가 빨라지면 요청 처리 사이클이 더 짧아지고, 결과적으로 대기열의 요청이 더 빠르게 처리 파이프라인에 진입하여 전체 처리량(throughput)이 향상됩니다.
6. G5/G6 인스턴스 활용 전략
6.1 모델 크기별 G5/G6 서빙 가이드
A10G 24GB GPU를 기준으로, 모델 크기에 따른 TP 구성을 안내합니다. BF16 기준에서 GPU 메모리의 약 70%를 모델에, 나머지를 KV Cache에 할당한다고 가정합니다.
| 모델 크기 | BF16 메모리 | 최소 TP | GPU 수 (A10G) | 인스턴스 예시 |
| 8B | ~16GB | TP=1 | 1장 | g5.xlarge |
| 8B (고성능) | ~16GB | TP=2~4 | 2~4장 | g5.12xlarge |
| 14B | ~28GB | TP=2 | 2장 | g5.12xlarge |
| 32B | ~64GB | TP=4 | 4장 | g5.12xlarge |
| 70B (INT8) | ~70GB | TP=4 | 4장 | g5.12xlarge |
| 70B (BF16) | ~140GB | TP=8 | 8장 | g5.48xlarge |
6.2 TP vs 수평 확장(Horizontal Scaling)
GPU 4장을 TP=4로 사용하는 대신, 각 GPU에 독립 vLLM 인스턴스를 배포하고 Load Balancer로 분산하는 수평 확장 방법도 있습니다. 워크로드 특성에 따라 적합한 전략이 다릅니다.
| 특성 | Tensor Parallelism (TP=4) | 수평 확장 (TP=1 x 4) |
| 대형 모델 서빙 | 24GB GPU로 70B+ 모델 서빙 가능 | 단일 GPU에 모델이 들어가야 함 |
| 개별 응답 속도 | 빠름 (TPOT 65.7% 개선) | TP=1과 동일 |
| 전체 처리량 | 787.9 t/s (C=16 기준) | 378.8 x 4 = ~1,515 t/s (이론치) |
| 적합한 서비스 | 대화형 AI, 실시간 보조
(응답 속도 중요) |
배치 처리, API 서비스
(총 처리량 중요) |
| 아키텍처 복잡도 | 단일 서버, 간단한 구성 | Load Balancer, 복수 서버 관리 |
6.3 비용 관점
P5(H100) 대비 G5(A10G)는 시간당 비용이 크게 낮습니다. H100 GPU 확보를 기다리는 동안 프로젝트가 지연되는 기회비용까지 고려하면, 즉시 확보 가능한 G5/G6로 서비스를 시작하고 필요 시 P5로 마이그레이션하는 전략이 합리적입니다.
| 비교 항목 | G5.12xlarge (A10G x 4) | P5.4xlarge (H100 x 1) 상당 |
| GPU 메모리 | 24GB x 4 = 96GB (합산) | 80GB (단일) |
| 확보 난이도 | 용이 | 제한적 |
| 적합 모델 | 32B BF16, 70B INT8 | 70B BF16 |
| GPU 인터커넥트 | PCIe Gen4 | NVLink (고대역폭) |
| 시간당 비용(주) | 약 $5.672 / hour | 약 $6.880 / hour |
* (주) 이 블로그를 작성시점 기준에는 P5.4xlarge가 서울리전에 없어서, 해당 EC2가 모두 제공되는 us-east-1 리전 기준으로 작성하였습니다.
7. 실전 적용 가이드
시나리오별 권장 구성
| 시나리오 | 권장 구성 | 근거 |
| 개발/테스트, PoC | G5 + TP=1 | 최소 비용, 단일 사용자에 충분한 성능 |
| 8B 모델, 중규모 서비스 | G5 + TP=2 | TPOT 43% 개선, PCIe 환경에서 비용 대비 최적 |
| 8B 모델, 대규모 동시 접속 | G5 + TP=4 | 최대 처리량, 응답 52% 단축, 사용자 경험 최우선 |
| 32B 모델 서빙 | G5 + TP=4 (필수) | BF16 기준 ~64GB, A10G 4장에 분산 적재 |
| 70B 모델 서빙 | G5 + TP=4 + INT8 (양자화)
또는 G5 + TP=8 |
양자화로 메모리 절감, 또는 8-GPU 인스턴스 활용 |
구현 시 고려사항
실제 운영 워크로드에 구성할 때는 아래와 같은 사항들에 대해서도 실제 워크로드를 감안해서 고려하는 것이 필요합니다.
- Startup Time 증가: TP 적용 시 서버 시작이 약 40초 증가합니다(71초 → 110초). Auto Scaling 환경에서는 이 점을 고려하여 Warm Pool이나 사전 프로비저닝을 활용하세요.
- TP 크기 = 2의 거듭제곱: Tensor Parallelism은 TP=1, 2, 4, 8 등 2의 거듭제곱 값에서 가장 효율적입니다. 모델의 attention head 수가 TP 크기로 나누어지는지 확인하세요.
- PCIe 환경의 한계 인지: G5/G6는 PCIe 연결이므로, TP=8 이상에서는 통신 오버헤드가 클 수 있습니다. 대형 모델에서 높은 TP가 필요한 경우 NVLink 인스턴스(P4d/P5)를 고려하세요.
- 양자화 적극 활용: vLLM이 AWQ, GPTQ를 네이티브 지원하므로, 양자화를 적용하면 필요한 GPU 수를 줄일 수 있습니다. 품질 저하가 허용 가능한 수준인지는 사전 평가가 필요합니다.
- 벤치마크 필수: 본 글의 결과는 특정 환경(Qwen3-8B, A10G, vLLM 0.20.0)에서의 실측치입니다. 실제 서비스에 적용하기 전에 자체 모델과 워크로드로 벤치마크를 수행하시기 바랍니다.
8. 결론
H100/H200 GPU 확보가 어려운 현실에서, Tensor Parallelism은 강력한 대안입니다. Amazon EC2 G5/G6 인스턴스의 A10G/L4 GPU 여러 장에 모델을 분산 배치하면, 단일 대형 GPU 없이도 40~80GB급 LLM을 서빙할 수 있습니다. 본 테스트를 통해 몇 가지 중요한 인사이트를 확인할 수 있었습니다. 먼저, A10G(24GB) GPU 4장을 TP=4로 구성하면 총 96GB의 메모리를 활용할 수 있어, 32B 모델(BF16)이나 70B 모델(INT8)과 같은 대형 모델도 충분히 서빙이 가능하다는 점입니다. 또한 동일한 모델이라도 TP=4로 분산했을 때 토큰 생성 속도(TPOT)가 약 65.7% 개선되어, 사용자 입장에서 체감하는 응답 속도가 눈에 띄게 빨라졌습니다. 특히 동시 사용자가 증가하는 상황에서 이러한 이점은 더욱 두드러집니다. 16명의 동시 요청 환경에서는 TP=4 구성이 TP=1 대비 약 2.1배 높은 처리량을 보였고, 응답 시간 역시 52%가량 단축되었습니다. 이는 실제 서비스 환경처럼 트래픽이 증가할수록 다중 GPU 기반 아키텍처의 가치가 더욱 커진다는 점을 잘 보여줍니다. 마지막으로, 초기 도입 관점에서도 의미 있는 시사점을 얻을 수 있습니다. 비교적 수급이 용이한 G5/G6 인스턴스를 활용해 LLM 서비스를 빠르게 시작하고, 이후 필요에 따라 NVLink를 지원하는 P4d나 P5와 같은 고성능 인스턴스로 확장하는 단계적 접근이 충분히 현실적인 전략이 될 수 있습니다. 결과적으로, Tensor Parallelism 기반의 다중 GPU 구성은 단순한 성능 향상을 넘어, 확장성과 비용 효율성까지 함께 고려할 수 있는 실용적인 선택지임을 확인할 수 있었습니다. GPU 확보 문제로 LLM 프로젝트를 지연시키고 계신다면, Tensor Parallelism과 G5/G6 인스턴스의 조합을 검토해 보시기 바랍니다. vLLM의 --tensor-parallel-size 옵션 하나로 즉시 적용할 수 있습니다.
본 블로그에 포함된 테스트 결과는 특정 환경에서의 실측치이며, 실제 성능은 워크로드, 모델, 인스턴스 유형에 따라 달라질 수 있습니다.
관련 리소스
- vLLM GitHub – 고성능 LLM 추론 엔진
- Amazon EC2 Documentation – GPU 인스턴스 유형별 사양
- vLLM Documentation – Tensor Parallelism 구성 가이드
- Amazon EC2 G5 Instances – NVIDIA A10G 기반 GPU 인스턴스