AWS 기술 블로그
현대오토에버의 Amazon Bedrock으로 구축한 다중 AI 에이전트: 장애 대응 시간 5분으로 단축하기
이 글은 현대오토에버의 GenAI Sandbox 활용 생산성 향상 해커톤 시리즈의 두 번째 글이며, 현대오토에버의 김만철, 최라윤님과 함께 작성하였습니다. 첫 번째 글에서는 현대오토에버와 AWS가 GenAI Sandbox를 활용해 어떻게 생산성 향상 해커톤을 기획하고 운영했는지, 그리고 14개 팀 150여 명이 참여한 이 행사의 전반적인 성과를 소개했습니다. 이번 글에서는 해커톤 수상 팀 중 하나인 ErrorWatcher 팀이 AWS에서 LangGraph와 Claude를 활용해 어떻게 다중 AI 에이전트 기반 장애 대응 시스템을 구축했는지 소개합니다.
배경: 반복되는 장애 대응에 AI 활용하자!
현대오토에버의 차량제어서비스개발팀은 디지털키, 차량보안 등 스마트폰과 차량 간 통신 기반의 커넥티드 서비스를 개발하고 운영하고 있습니다. 국내외 글로벌 환경에서 24시간 운영되는 서비스 특성상, 장애 발생 시 신속한 원인 분석과 대응이 필수적입니다. 우리 팀은 Microsoft Teams를 통해 서비스 장애 알람을 실시간으로 수신하고 있으며, 다양한 시스템 커스텀 알람을 활용하여 장애 발생 시 신속하게 대응하고 있습니다. 하지만 Application, 데이터베이스(DB), Kubernetes, 로드 밸런서(Load Balancer, LB) 등 여러 레이어에 걸쳐 발생하는 장애의 근본 원인을 분석하고 대응하는 데는 여전히 수 시간이 소요되었습니다.
2025년 9월 26일, 현대오토에버와 AWS 협력하여 개최된 GenAI Sandbox 활용 생산성 향상 해커톤에서 ErrorWatcher 팀은 이 문제를 생성형 AI(Generative AI)를 활용하여 해결하고자 했습니다. 시니어 엔지니어가 가진 노하우를 AI가 보조하고, 장애 각 단계에서 발생하는 불필요한 시간을 줄이는 것을 프로젝트의 핵심 목표로 삼았습니다. 그 결과, 장애 대응 시간을 수 시간에서 5분으로 단축하는 성과를 입증하며 해커톤 Spotlight Award를 수상했습니다.

솔루션 개요: ErrorWatcher
ErrorWatcher는 LangGraph 기반의 다중 에이전트(Multi-Agent) 오케스트레이션 시스템으로, 단순한 알림 전달을 넘어 생성형 AI 에이전트가 능동적으로 장애를 분석하고 대응 방안을 제시하는 지능형 장애 대응 자동화를 목표로 합니다. 이 시스템에서는 ‘이상징후 분석(Monitor)’, ‘근본원인 분석(Detective)’, ‘솔루션 아키텍트(Solver)’, ‘보고서 작성(Reporter)’라는 네 가지 역할을 가진 에이전트들이 오케스트레이터의 지휘 아래 유기적으로 협력하여, 24시간 장애 감지부터 원인 분석, 해결책 제시, 상세한 보고서 생성까지의 전 과정을 자동화합니다.
이 시스템은 단순한 알림 전달을 넘어, 생성형 AI 에이전트가 능동적으로 장애를 분석하고 대응 방안을 제시하는 지능형 장애 대응 자동화를 목표로 합니다. 이 시스템은 ‘이상징후 분석(Monitor)’, ‘근본원인 분석(Detective)’, ‘솔루션 아키텍트(Solver)’, ‘보고서 작성(Reporter)’라는 네 가지 역할을 가진 에이전트들이 오케스트레이터의 지휘 아래 유기적으로 협력하여 문제를 해결합니다.
시스템 흐름
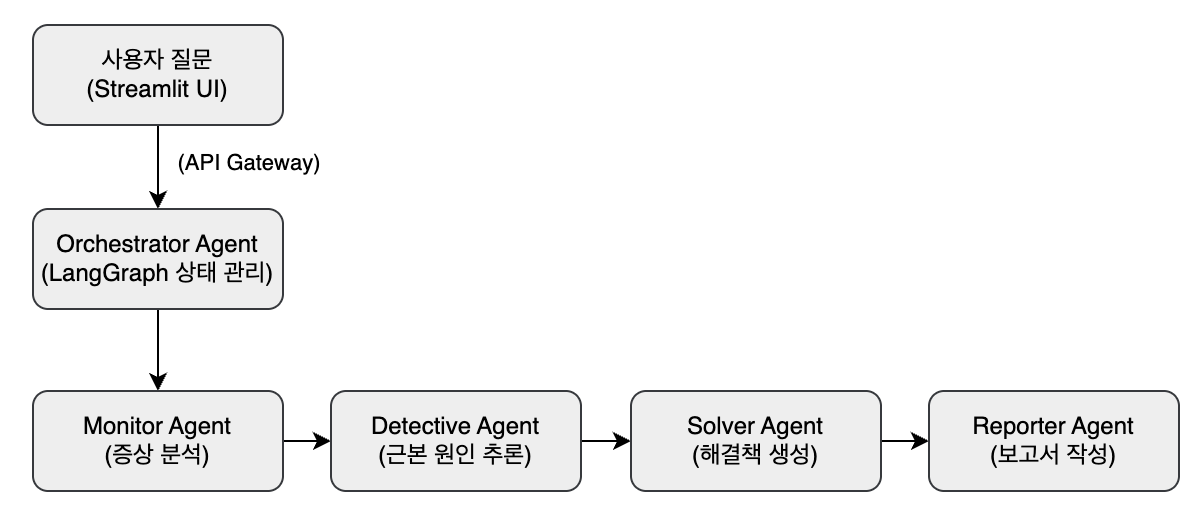
[그림 1] ErrorWatcher 흐름도
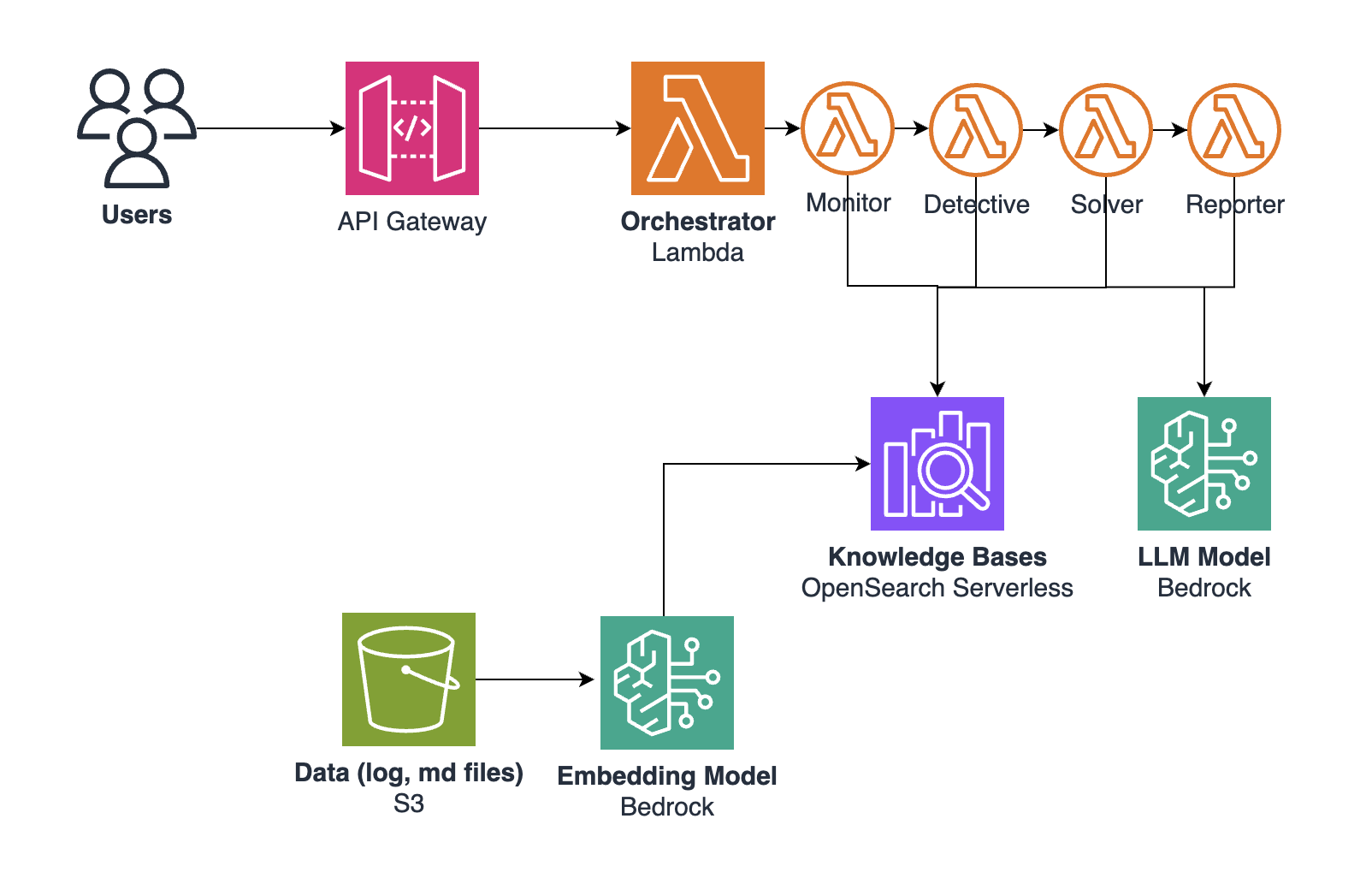
[그림 2] ErrorWatcher 아키텍처 구성도
기술 스택 및 아키텍처
ErrorWatcher는 다음과 같은 AWS 서비스 및 오픈소스 프레임워크를 조합하여 구축하였습니다.
| 구분 | 기술 | 선택 이유 |
|---|---|---|
| LLM | Claude Sonnet (Amazon Bedrock) | 뛰어난 추론 능력, AWS 네이티브 통합 |
| Orchestration | LangGraph on AWS Lambda | 유연한 에이전트 흐름 제어 (*주1) |
| RAG | Amazon Bedrock Knowledge Base | OpenSearch Serverless 기반 의미 검색 |
| Storage | Amazon S3 | 로그 및 지식 베이스파일 저장 |
| UI | Streamlit | 빠른 PoC 및 데모 구현 |
(*주1) Amazon Bedrock Agents는 완전 관리형 에이전트 오케스트레이션 서비스로, 별도의 인프라 구성 없이 빠르게 AI 에이전트를 배포할 수 있다는 강점이 있습니다. 반면, ErrorWatcher 팀은 Monitor → Detective → Solver → Reporter로 이어지는 순차적 분석 파이프라인에서 에이전트 간 상태 전달과 실행 흐름을 Python 코드 수준에서 세밀하게 제어해야 했기 때문에, LangGraph의 StateGraph를 활용한 커스텀 오케스트레이션 방식을 채택했습니다.
ErrorWatcher 의 Agents
| Agent 역할 | Agent명 | 주요 데이터 소스 | 데이터 수집/접근 방식 | 역할 |
|---|---|---|---|---|
| 총괄 에이전트 | orchestrator |
LangGraph 상태 관리 | – | • 전체 분석 프로세스 계획 및 각 Agent에 작업 할당
• Agent 간 상태 전파 및 순차 실행 관리 |
| 이상징후 분석 에이전트 | monitor-agent |
S3 (로그, 메트릭) | Lambda → S3 직접 접근 | • Mock 데이터
• 로그, 메트릭(log, JSON)에서 에러 내역, 장애 발생 패턴 탐색 • LLM 기반 증상 분석 |
| 근본원인 분석 에이전트 | detective-agent |
Bedrock Knowledge Base | RAG + 원인분석가 전문가 프롬프트 | • 과거 유사 장애 이력 + 시스템 아키텍처 문서 참조
• 신뢰도 계산 및 LLM 기반 최종 원인 분석 |
| 솔루션 아키텍트 에이전트 | solver-agent |
Bedrock Knowledge Base | RAG + 도메인별 전문가 프롬프트 (해결책 중심) | • 실행 가능한 해결책 설계
• 신뢰도 계산 • 단기/장기 구분 + 구체적 명령어 포함 |
| 보고서 작성 에이전트 | reporter-agent |
Bedrock Knowledge Base | RAG + S3 저장 | • 경영진 + 기술진 모두 이해 가능한 보고서 작성
• 자동 학습 시스템 (신뢰도가 높은 보고서를 KB 추가) |
핵심 구현 내용
LangGraph 기반 에이전트 상태 관리
ErrorWatcher는 LangGraph의 StateGraph를 활용하여 에이전트 간 상태를 공유하고 순차적 워크플로우를 실행합니다. 각 에이전트는 TypedDict로 정의된 State를 통해 데이터를 주고받으며, 이를 통해 전체 분석 과정을 하나의 명확한 파이프라인으로 관리합니다.
메타데이터 필터링
ErrorWatcher는 Knowledge Base 검색 시 메타데이터 필터링을 적용하여 각 에이전트에게 필요한 문서만 제공합니다.
- Detective Agent:
past-incidents/,architecture/폴더만 검색 - Solver Agent:
runbooks/폴더만 검색 (해결책 중심) - Reporter Agent:
templates/폴더에서 보고서 양식 검색
이를 통해 검색 정확도를 높이고 불필요한 토큰 소비를 방지합니다.
신뢰도 기반 자동 학습 시스템
Solver Agent는 근본 원인의 도메인(DB, Infrastructure, Network 등)에 따라 다른 전문가 페르소나를 적용하여 더욱 정확하고 실행 가능한 해결책을 제시합니다. 모든 분석 결과에 신뢰도 점수(HIGH/MEDIUM/LOW)를 부여합니다. 지속적 학습(Continuous Learning)을 위해 신뢰도가 HIGH인 보고서는 learned-cases/ 폴더에 자동 저장되어, 향후 유사 장애 분석 시 참고 자료로 활용됩니다. 다음은 EKS Pod CrashLoopBackOff가 발생한 상황을 가정하여, 각 에이전트의 데이터 흐름을 살펴본 예시입니다.
도메인별 4개의 전문가 프롬프트
Solver Agent는 근본 원인의 도메인(DB, Infrastructure, Network 등)에 따라 다른 전문가 페르소나를 적용하여 더욱 정확하고 실행 가능한 해결책을 제시합니다. 실제 예시를 통해 데이터 흐름을 살펴 보겠습니다. EKS Pod CrashLoopBackOff가 발생한 상황이라고 가정해보겠습니다.
1단계: Monitor Agent – 증상 수집
Monitor Agent는 Amazon S3에 저장된 로그와 메트릭 정보를 읽어 장애 증상을 분석합니다. 이 데이터는 Fluentbit, CloudWatch, Grafana에서 수집된 것으로 가정하며, S3에 날짜별로 저장되어 있습니다. Monitor Agent는 로그를 LLM 개입 없이 직접 분석하고, 메트릭은 LLM을 활용하여 분석합니다. 최종적으로 LLM이 두 분석 결과를 종합하여 증상 요약을 생성합니다. 아래는 Monitor Agent의 출력 데이터 구조입니다.
2단계: Detective Agent – 근본 원인 분석
Detective Agent는 Monitor Agent가 전달한 증상 데이터와 Knowledge Base 검색 결과를 프롬프트에 결합하여 에러의 근본 원인을 분석합니다. 이때 Knowledge Base 검색 결과의 관련성을 평가하여 HIGH/MEDIUM/LOW로 신뢰도 점수를 부여합니다. 또한 메타데이터 필터링을 통해 past-incidents/, architecture/ 폴더의 문서만 검색하여 분석 정확도를 높입니다. 아래는 Detective Agent의 출력 데이터 구조입니다.
3단계: Solver Agent – 해결책 제시
Solver Agent는 Detective Agent가 전달한 근본 원인 데이터를 기반으로 Knowledge Base를 검색하여 실행 가능한 해결책을 도출합니다. Detective Agent와 마찬가지로 Knowledge Base 검색 결과의 관련성을 평가하여 HIGH/MEDIUM/LOW로 신뢰도 점수를 부여하며, 메타데이터 필터링을 통해 runbooks/ 폴더의 문서만 검색하여 해결책 중심의 정보를 확보합니다. Solver Agent는 이 결과를 종합하여 즉시 실행 가능한 해결책과 단기/장기적인 개선책을 함께 제시합니다. 아래는 Solver Agent의 출력 데이터 구조입니다.
4단계: Reporter Agent – 보고서 생성 및 지속 학습
Reporter Agent는 앞선 에이전트들이 분석한 에러 로그, 근본 원인, 해결책을 종합하고, Knowledge Base에서 보고서 양식을 검색하여 최종 보고서를 생성합니다. 생성된 보고서는 Amazon S3에 저장되며, 신뢰도가 HIGH인 보고서는 learned-case/ 폴더에 자동 추가되어 향후 에이전트가 RAG 수행 시 참고 자료로 활용됩니다. 아래는 Reporter Agent의 최종 보고서 양식입니다.
프로젝트 효과 및 향후 계획
ErrorWatcher 도입 효과
ErrorWatcher는 장애 감지부터 원인 분석, 해결책 제시, 보고서 생성까지 전 과정을 자동화하여 MTTR을 수 시간에서 5분으로 단축했습니다. 또한 운영자의 경험 수준과 무관하게 일관된 분석 품질을 보장하며, 팀의 장애 대응 노하우를 조직 전체의 지식 자산으로 전환했습니다.
- MTTR 획기적 단축: ErrorWatcher는 장애 분석 시간을 수 분 단위로 단축했습니다. 숙련된 엔지니어가 부재한 야간이나 주말에도 동일한 수준의 신속한 대응이 가능합니다.
- 일관된 품질 보장: 운영자의 경험 수준과 무관하게 동일한 수준의 분석 품질을 보장합니다. 신입 엔지니어도 베테랑과 같은 수준의 근본 원인 분석과 해결책을 얻을 수 있습니다.
- 무제한 확장성: 현재 EKS, ALB, DB 도메인을 대상으로 구축되었지만, 분석 데이터 수집 형식만 맞추면 어떤 도메인이든 확장 가능합니다. 새로운 장애 유형도 기존 패턴을 기반으로 자동 분류 및 분석됩니다.
- 지식 자산화: 개인의 경험과 노하우가 구조화된 문서로 저장되어 팀 전체의 자산으로 전환됩니다. 한 명의 엔지니어가 해결한 장애 사례가 시스템에 학습되면, 모든 팀원이 동일한 수준의 전문성을 공유하게 됩니다.
향후 발전 방향
1. 예방적 장애 대응 (Proactive Monitoring)
ErrorWatcher가 핵심 지표를 24시간 감시하여 장애가 발생하기 전에 사전 경고를 제공하고, 미리 대응할 수 있는 체계를 구축할 예정입니다.
2. 자동화된 사내 장애 시스템 연계 (Human-in-the-Loop)
AI의 신속성과 인간의 판단력을 결합한 Human-in-the-Loop 방식을 구현할 예정입니다. ErrorWatcher가 장애를 분석하고 해결책을 제시하면, 운영자는 Teams 알람을 통해 즉시 통보받습니다. 운영자가 해결책을 검토하고 승인 버튼을 클릭하면 해당 조치가 자동으로 실행되며, ErrorWatcher는 시스템이 정상 상태로 복구된 것을 확인한 후 사내 시스템에 장애 보고서를 자동으로 생성하고 제출합니다. 이 방식은 위험도가 낮은 작업(예: 로그 수집, 메트릭 확인)은 완전 자동화하고, 위험도가 높은 작업(예: DB 설정 변경, Pod 재시작)은 사람의 승인을 필수로 설정하여 안전성과 효율성을 동시에 확보합니다.
3. 사용자 접근성 강화
Teams Webhook을 연동하여 운영자가 채팅 기반으로 장애 분석을 요청할 수 있도록 할 계획입니다. 이를 통해 운영자들은 언제 어디서나 모바일이나 PC를 통해 즉시 ErrorWatcher의 도움을 받을 수 있습니다.
결론
ErrorWatcher는 단순한 PoC를 넘어 실제 운영 환경에 적용 가능한 자동 장애 분석 시스템입니다. 이번 GenAI 해커톤을 통해 ErrorWatcher 팀은 AI 멀티 에이전트 협업 시스템을 실제로 구현하며, 기술적 가능성과 실용적 가치를 동시에 검증했습니다. 해당 시스템의 핵심 가치는 세 가지입니다. 첫째, LangGraph 기반의 정밀한 워크플로우 제어로 에이전트 실행 순서와 상태 전달을 명확하게 관리합니다. 둘째, 메타데이터 필터링을 통한 효율적인 RAG로 각 에이전트가 필요한 정보만 정확하게 검색합니다. 셋째, 신뢰도 기반 자동 학습 시스템을 통해 지속적으로 학습하며 진화합니다. 특히 Teams 알람만 받던 상황에서 “왜 발생했고, 어떻게 해결할 것인가”에 대한 명확한 답변을 수 분 내에 받을 수 있다는 점은 운영 팀에게 혁신적인 변화입니다. 앞으로 ErrorWatcher는 사후 대응을 넘어 예방적 모니터링, ITSM 자동 연계, Teams 채팅 기반 접근성 강화 등을 통해 완전 자율 운영 시스템으로 발전할 것입니다. ErrorWatcher가 AI 기반 자동화 운영의 새로운 표준이 되기를 기대합니다.
다음 연재 예고
이번 해커톤을 통해 현대오토에버 차량제어서비스개발팀은 AWS GenAI Sandbox 환경에서 단 2~3주의 스프린트 만에 실제 운영 문제를 해결하는 AI 솔루션을 구현해냈습니다. LangGraph의 유연한 에이전트 오케스트레이션과 Amazon Bedrock의 Claude 모델, 그리고 Amazon Bedrock Knowledge Base의 RAG 기능이 결합되어 강력한 AIOps 솔루션이 탄생했습니다. GenAI Sandbox는 단순한 실험 환경을 넘어, 실제 비즈니스 문제를 해결하는 혁신의 발판이 되고 있습니다. 다음 시리즈에서는 해커톤의 또 다른 수상 팀인 현대오토에버의 Amazon Bedrock 기반 빅데이터 클러스터 장애 대응 자동화 에이전트 구축기 사례를 소개할 예정입니다.