AWS 기술 블로그
현대오토에버의 Amazon Bedrock으로 구축한 빅데이터 클러스터 장애 대응 자동화 에이전트 구축기
이 글은 현대오토에버의 GenAI Sandbox 활용 생산성 향상 해커톤 시리즈의 세번째 글이며, 현대오토에버의 오명우, 정세종님과 함께 작성하였습니다. 첫 번째 글에서는 현대오토에버와 AWS가 GenAI Sandbox를 활용해 어떻게 생산성 향상 해커톤을 기획하고 운영했는지, 그리고 14개 팀 150여 명이 참여한 이 행사의 전반적인 성과를 소개 했습니다. 두 번째 글에서는 Amazon Bedrock과 LangGraph를 활용해 어떻게 다중 AI 에이전트 기반 장애 대응 시스템을 구축했는지 소개하였습니다. 이번 글에서는 해커톤 수상 팀 중 하나인 데이터플랫폼기술팀의 빅데이터 클러스터 장애 대응 자동화 에이전트 구축기를 소개합니다.
장애 대응 생명 주기와 도전 과제
장애 대응은 단일 작업이 아니라, 다섯 단계로 이루어진 생명 주기입니다. 1) Detection 단계에서 알림을 감지하고 심각도를 판단한 뒤, 2) Investigation 단계에서 컨텍스트를 수집하고 가설을 검증하여 근본 원인을 식별합니다. 이어서 3) Recovery 단계에서 추가 장애 리스크를 고려하며 서비스를 복구하고, 4) Post-Incident Review 단계에서 RCA를 문서화하고 개선 기회를 식별합니다. 마지막으로 5) Improve 단계에서 축적된 경험을 바탕으로 관측성·인프라·배포 파이프라인을 개선합니다.
그러나 이 생명 주기에 걸쳐 시간 확보, 균등한 품질, 원인 추적의 정확성 등 여러 도전 과제가 존재합니다. 현대오토에버 데이터플랫폼기술팀은 이러한 문제들을 근본적으로 해결하고자 엔지니어가 더 빠르고 정확하게 판단할 수 있도록 돕는 AI 에이전트 구축을 목표로 하였습니다. 이 글에서는 LangGraph를 활용해 장애 대응 Workflow를 상태 기반 그래프로 설계하고, Amazon Opensearch로 로그를 구조적으로 탐색하며, Amazon Bedrock의 파운데이션 모델을 역할별 멀티 에이전트로 구성해 장애 대응을 자동화한 경험을 공유합니다.
참가팀 소개
현대오토에버 데이터플랫폼기술팀은 Hadoop 기반 대규모 빅데이터 클러스터를 24시간 365일 운영하고 있습니다. 장애가 발생하면 상태 확인, 로그 수집, 근본 원인 분석(RCA), 복구 계획 수립, 승인 기반 실행, 사후 보고까지 일련의 Incident 대응 프로세스 수행은 핵심 미션의 하나입니다.
배경: 기존 장애 대응 프로세스의 한계
기존 빅데이터 클러스터 장애 대응 프로세스는 알림 하나에도 여러 단계의 수작업이 필요하고, 담당 엔지니어의 숙련도에 따라 품질이 달라지는 구조적 한계를 안고 있었습니다. 구체적으로, 알림 뒤에는 다음과 같은 확인 작업이 연쇄적으로 이어집니다.
- Ambari 상태 확인: Service·Host 상태 및 CRITICAL/WARNING 알림 파악
- 노드별 SSH 진단: 컴포넌트가 구성된 여러 노드에 접속해 프로세스, 리소스 상태를 점검
- 로그 탐색: OpenSearch에서 장애 전후 로그를 Component, Level, 시간 구간으로 좁혀 확인
- 근본 원인 분석: 흩어져있는 진단들을 조합해 장애 가설을 세우고 복구 시나리오를 비교, 분석
- 승인 기반 복구: 운영 정책에 따른 복구 승인 절차 진행
이러한 문제를 해결하기 위해 다음 세 가지 핵심 목표를 설정했습니다.
- MTTA* 단축: 초기 진단·상태 보고 자동화로 1차 응답 시간 단축 (*)MTTA: Mean Time To Acknowledge
- 품질 표준화: 야간이나 휴일에도 특정 엔지니어의 경험에 의존하지 않고 일관된 진단과 보고서 제공
- 지식 자산화: 모든 Incident의 상태 스냅샷, 타임라인, 명령 트레이스를 DB에 축적해 조직의 내부 지식으로 전환
기술 스택 선택
Workflow Orchestration : LangGraph
장애 대응 워크플로우는 단순한 직선형 파이프라인이 아닙니다. 상황에 따라 분기하고, 충분한 증거가 확보될 때까지 반복하며, 여러 분석을 병렬로 수행해야 합니다. LangGraph는 이러한 요구사항을 StateGraph 기반으로 자연스럽게 표현할 수 있었습니다.
- 분기·Loop·병렬 실행 지원으로 복잡한 워크플로우 구현 가능
- Reducer 기반 필드별 Merge 규칙으로 병렬 실행 결과를 안전하게 합산
- PostgresSaver 기반 Checkpointing으로 중단 후 재개 가능
로그 검색·집계: Amazon OpenSearch Service
로그는 장애 대응의 핵심 증거입니다. Amazon OpenSearch Service는 시간 범위, Level, Component 조건으로 원천 로그를 빠르게 검색하고, Aggregation으로 어떤 Component를 먼저 살펴야 하는지 즉시 판단할 수 있게 해줍니다. Query DSL 기반으로 복잡한 조건과 집계를 유연하게 구성할 수 있다는 점도 선택의 이유였습니다.
LLM 런타임: Amazon Bedrock
단일 LLM으로는 모든 역할을 최적으로 수행하기 어렵습니다. Amazon Bedrock은 Anthropic, Meta, Amazon 등 다양한 파운데이션 모델을 단일 API로 호출할 수 있어, 노드 특성에 맞춰 경량 모델과 고성능 모델을 유연하게 분기할 수 있었습니다.
전체 아키텍처
아키텍처는 크게 VDI Agent와 Main Agent Server 두 영역으로 나뉩니다.
| VDI Agent | |
| Outlook Monitor | 장애 알림 메일을 필터링하여 서버에 incident payload를 전송 |
| Teams Agent | 주요 시점에 진행 상황을 알리고, 사후 질의응답 인터페이스를 제공 |
| SSH Runner | 서버 요청에 따라 read-only 진단 명령을 실행하고 결과를 반환 |
| Main Agent Server | |
| FastAPI REST Gateway | /incidents, /approve, /ask 엔드포인트 및 WebSocket 브릿지(/ws) |
| LangGraph Orchestrator | Incident별 StateGraph 실행 및 PostgresSaver Checkpointing |
| PostgreSQL | Checkpoint와 Incident 상태(ops), 클러스터·노드 Metadata(meta), 실행 트레이스와 Audit Log(trace) |
| Amazon OpenSearch Service | 로그 검색 및 집계 |
| Amazon Bedrock | 멀티 에이전트용 파운데이션 모델 호출 |
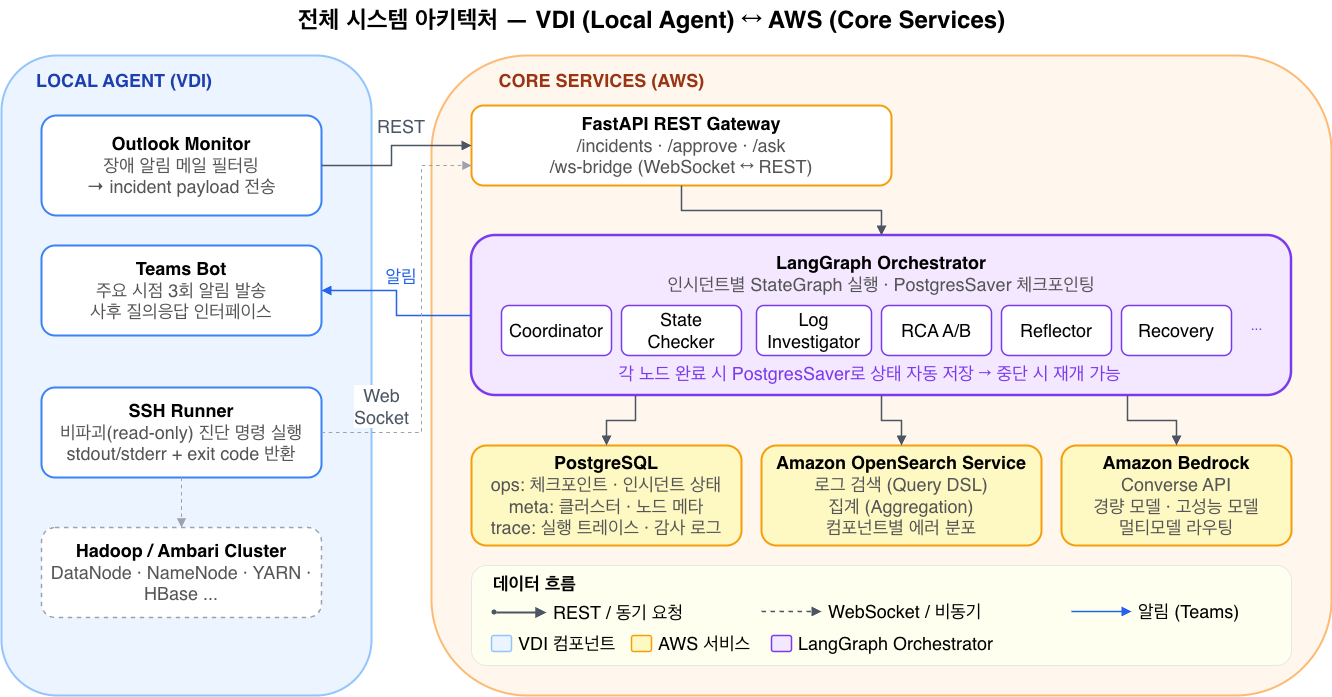
그림 1. 전체 시스템 아키텍처
VDI 측의 Outlook Monitor가 장애 알림을 감지하면 REST API를 통해 FastAPI Gateway로 전달합니다.
LangGraph Orchestrator가 PostgreSQL, OpenSearch, Bedrock을 활용해 에이전트 그래프를 실행합니다. SSH 진단은 WebSocket 브릿지를 통해 VDI의 SSH Runner가 수행하며, 운영자에게는 Teams Agent을 통해 알림과 Q&A를 제공합니다.
LangGraph Workflow 설계
전체 Workflow는 14개 에이전트(노드)로 설계했습니다. 현재 운영 환경에서는 분류·진단부터 분석까지 9개 노드를 활성화하고, 복구·승인·사후 보고 노드는 단계적으로 확장해 나가고 있습니다.
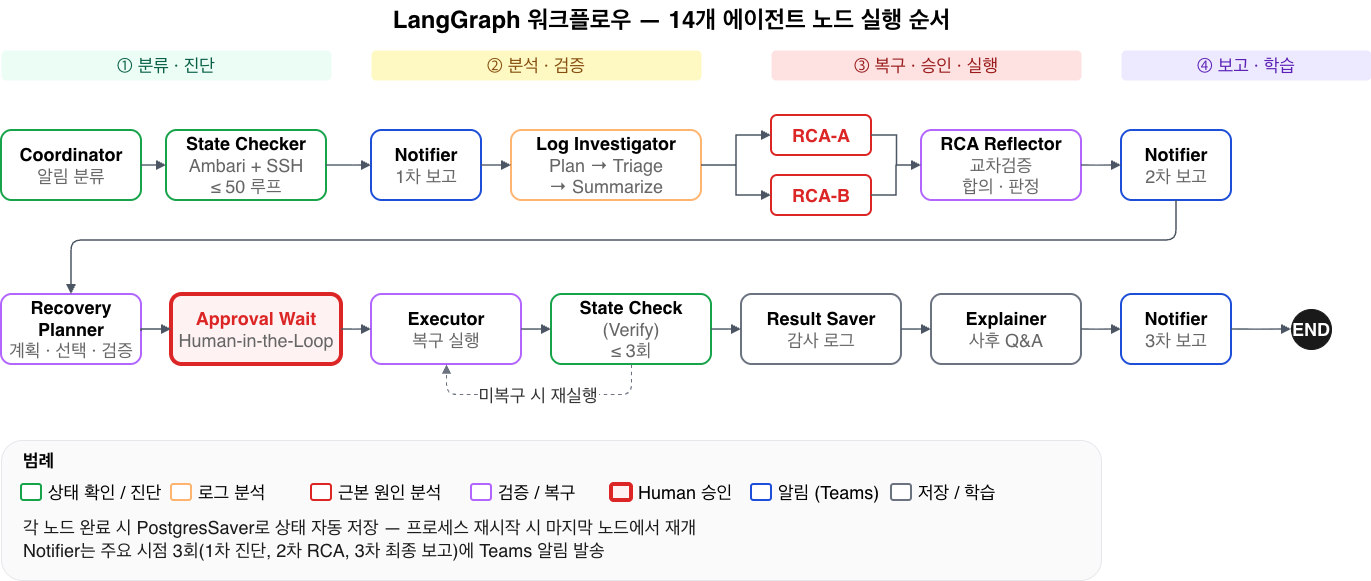
그림 2. LangGraph Workflow
분류·진단, 분석·검증, 복구·승인·실행, 보고·학습의 4단계로 구성됩니다. 현재 활성화된 9개 노드 (Coordinator → State Checker → Notifier(1차) → Log Investigator → RCA A/B 병렬 → RCA Join → Reflector → Notifier(2차))가 알림 수신부터 RCA 완료까지를 자동 수행합니다. 각 노드 완료 시 PostgresSaver로 상태가 자동 저장되어 중단 후 재개가 가능합니다.
핵심 구현 포인트
이번 글에서는 1. 상태 스키마와 Merge 방식, 2. Coordinator, 3.State Checker, 4. Log Investigator, 5. RCA 병렬+반증+Reflector를 핵심 구현 포인트로 다룹니다.
핵심 구현 1. 상태 스키마 설계: 델타 반환과 Reducer Merge
LangGraph에서 병렬 실행 환경에서의 상태 충돌을 방지하기 위해, 전체 상태를 덮어쓰는 대신 노드가 만든 변경분(delta)만 반환합니다. Reducer가 자동으로 Merge하여 병렬 노드의 출력이 충돌 없이 합쳐집니다. 여기서 핵심은 TypedDict와 Annotated Reducer의 조합입니다.
이 구조를 사용하면 rca_a노드가 {“analysis”: {“rca_a”: {…}}}를, rca_b노드가 {“analysis”: {“rca_b”: {…}}}를 반환해도 _merge_dict Reducer가 analysis 아래에 충돌 없이 합쳐집니다.
Checkpointing을 위해 PostgresSaver를 사용하면, 노드 실행 단위로 상태가 저장됩니다. 장애 대응 도중 프로세스가 재시작되더라도 마지막 Checkpoint에서 재개할 수 있기 때문에 운영 환경에서의 내결함성이 확보됩니다. LangGraph의 Checkpointing과 PostgresSaver 사용법은 공식 문서에서 확인할 수 있습니다.
핵심 구현 2. Coordinator: 알림 분류와 메타 검증
Coordinator는 수신된 알림을 자동화 Workflow로 처리할지 결정하는 Gate 노드입니다.
● 입력: Outlook 알림 메일(subject/body), tenant/cluster_id
● 처리 흐름:
- Bedrock 경량 모델로 어떤 Service/Component 에서 장애가 발생했는지 추출, 분류
- PostgreSQL Meta DB에서 cluster_id의 존재 여부와 해당 클러스터가 담당 클러스터인지 확인
accept && cluster_exists일 때만 다음 단계로 진행하고, 그렇지 않으면 Workflow를 종료
● 출력: analysis.alert_classification, analysis.should_proceed timeline
*운영 포인트: LLM 분류는 참고 신호로만 활용하고, 최종 클러스터 매칭은 Meta DB로 판단합니다. LLM의 오탐이나 Hallucination을 데이터베이스 검증으로 보완하는 설계입니다.
핵심 구현 3. State Checker: Ambari + SSH 반복 탐색(최대 50회)
State Checker는 원인을 단정하지 않고, 현재 운영 상태를 객관적으로 기술하는 역할을 맡습니다. 원인 분석은 이후 RCA 단계에서 수행합니다.
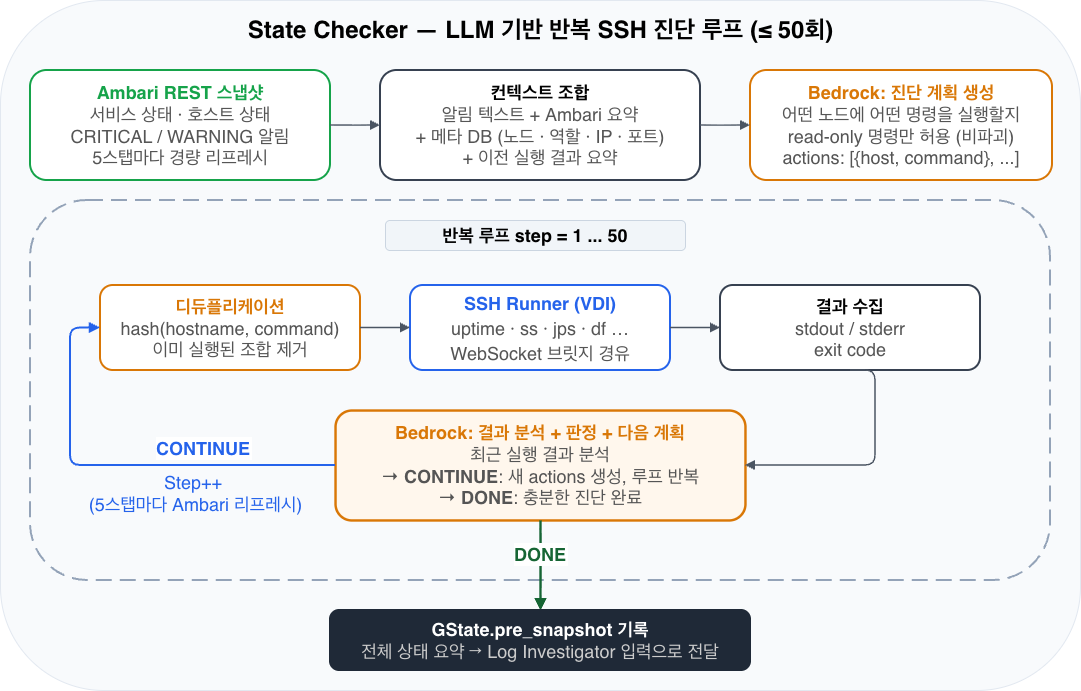
그림 3. State Checker의 반복 진단 Loop
Ambari REST API로 초기 스냅샷을 수집한 뒤, LLM이 이전 결과를 분석해 다음 진단 계획을 생성합니다. (hostname, command) 해시 기반 Deduplication으로 중복 실행을 방지하며, 5스텝마다 Alert 상태를 Refresh합니다.
진단 흐름 :
1 단계 : Ambari REST API로 초기 스냅샷 수집
클러스터 Service 상태, Host 상태, CRITICAL/WARNING 알림 요약을 수집합니다. 이어서 현재 Alert의 상세 정보도 조회합니다.
2 단계 : 알림 텍스트/Ambari 스냅샷 요약/Meta DB기반 노드 목록 바탕으로 LLM에서 노드에 대한 SSH 진단 계획 생성
3 단계 : 반복 Loop (최대 50회)로 탐색 확장
- 최근 실행 결과를 LLM에 제공 → 다음 SSH 명령 생성
- 이미 실행한 (hostname, command) 조합은 SHA-256 해시 기반 Deduplication으로 중복 실행 방지
- VDI의 SSH Runner가 WebSocket을 통해 명령 실행
- 5 스텝마다 Alert 상태 Refresh로 실시간 상태 변화를 반영
이 구조를 통해 처음에는 범용 진단(uptime, ss, jps)을 수행하고, 필요에 따라 범위를 좁혀 추가 진단(service status, df, logs tail)으로 확장할 수 있습니다. 모든 SSH 명령은 read-only로 제한하여 시스템에 영향을 주지 않습니다. 또한 최대 50회까지 반복할 수 있지만, 매 Step마다 Agent가 수집된 진단 결과의 충분성을 자율적으로 평가합니다. 현재 상태를 기술하기에 충분한 증거가 확보되었다고 판단하면 Loop를 조기 종료하고 다음 단계(Log Investigator)로 즉시 전환합니다. 이를 통해 불필요한 SSH 호출을 줄이면서도, 복잡한 장애 상황에서는 필요한 만큼 깊이 탐색 할 수 있는 유연성을 확보합니다.
핵심 구현 4. Log Investigator: OpenSearch 기반 3단계 로그 분석
Log Investigator는 탐색 계획 수립, 1차 분류, 심층 요약을 하나의 노드 안에서 수행합니다. 불필요한 LLM 호출을 줄이고, 로그 분석 결과를 RCA가 바로 소비할 수 있는 EvidencePack 형태로 일관되게 제공하는 것을 설계 목표로 합니다.
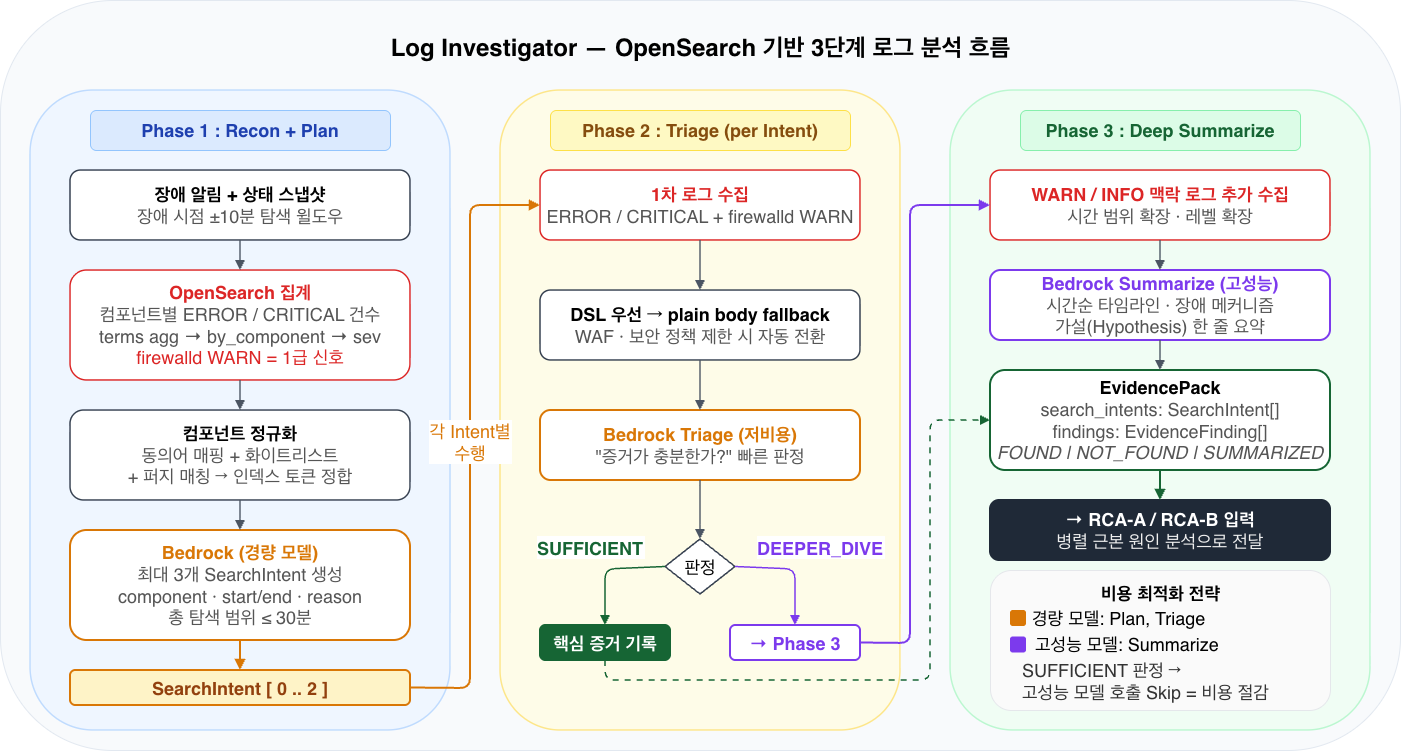
그림 4. Log Investigator의 3단계 흐름
Phase 1에서 OpenSearch 집계로 Component별 에러 건수를 파악하고, Phase 2에서 LLM이 최대 3개의 탐색 의도(SearchIntent)를 생성합니다. Phase 3에서는 각 의도별로 저비용 모델의 Triage 판정을 거치며, DEEPER_DIVE 판정 시에만 고성능 모델이 호출되어 비용을 최적화합니다.
Phase 1: Recon Component별 에러 집계로 우선순위 결정
Component별 에러 집계로 어떤 Component를 먼저 살펴야 할지 빠르게 판단합니다. 장애 시점 전후 10분을 기본 탐색 Window로 설정하고, OpenSearch 집계(aggregation)로 Component별 ERROR/CRITICAL 건수를 집계합니다.
운영 특성을 반영해 firewalld의 WARN 로그를 중요 신호로 취급하였습니다. 방화벽 정책 변화가 Service 단절로 직결되는 경우가 빈번했기 때문입니다.
Phase 2: Plan 최대 3개의 SearchIntent 생성
집계 결과, 알림, 현재 상태 요약을 Bedrock 경량 모델에 전달하고, 구조화된 탐색 의도를 생성합니다.
탐색 범위는 고정이 아니라 Agent가 증거의 충분성을 판단하며 점진적으로 확장 합니다. 초기에는 장애 시점 전후 10분 범위에서 CRITICAL/ERROR Level 로그만 탐색하고, 증거가 부족하다고 판단되면 20분, 최대 30분까지 Time Window를 확장합니다. 동시에 탐색 대상 Log Level 역시 CRITICAL → WARN → INFO 순으로 단계적으로 확장하여, 더 넓은 맥락에서 단서를 포착합니다. 충분한 증거가 확보되었다고 Agent가 판단하는 시점에 탐색을 즉시 중단함으로써, 비용과 지연을 최소화하면서도 필요한 깊이의 분석을 보장합니다.
Component 정규화
LLM은 “firewall”, “OS”, “Hue Server” 처럼 실제 인덱스 토큰과 다른 표현을 생성할 수 있습니다. 이를 그대로 OpenSearch 쿼리에 사용하면 검색 실패와 비용 증가로 이어집니다. 이를 해결하기 위해 세 가지 방식을 결합합니다.
| 정규화 방식 | 설명 | 예시 |
|---|---|---|
| 동의어 매핑 | 미리 정의된 동의어 테이블로 변환 | “firewall” → “firewalld” |
| Whitelist | 해당 시간 구간에 실제 존재하는 Component 목록으로 필터링 | “Hue Server” → “hue” |
| 퍼지 매칭 | 위 두 방식으로 매칭되지 않을 때 가장 근접한 토큰 선택 | “hdfs_nameode” → “hdfs_namenode” |
Phase 3: Triage → Summarize 비용 최적화된 2단계 LLM 패턴
각 SearchIntent마다 다음을 수행합니다.
- Triage (저비용 모델): 수집된 증거가 충분한지 빠르게 판정
SUFFICIENT: 핵심 증거만 기록하고 종료. (고성능 모델 호출을 건너뛰어 비용 절감)DEEPER_DIVE: 다음 단계로 진행
- 심층 요약 (고성능 모델): WARN/INFO 맥락 로그를 추가 수집한 뒤, 시간순 타임라인과 장애 메커니즘을 요약
최종 산출물은 RCA가 바로 소비할 수 있도록 EvidencePack으로 패키징합니다.
핵심 구현 5: Bedrock 기반 병렬 RCA + 자체 반증(Falsification)
단일 LLM이 RCA를 수행하면 확증 편향(첫 가설에 끌려가는 현상)과 환각 위험이 커지므로, 이를 완화하기 위해 다음을 목표로 설계했습니다.
- 병렬 실행 : Amazon Bedrock에서 제공하는 서로 다른 최고 수준의 추론 모델을 RCA-A와 RCA-B에 각각 할당하여 동일한 증거를 서로 다른 모델의 관점에서 독립적으로 분석함으로써, 단일 모델의 편향을 구조적으로 상쇄합니다.
- 자체 반증 : 각 RCA가 자기 결론을 스스로 공격하는 반증(Falsification) 단계를 수행
- 교차 검증 : Reflector가 두 결과를 비교, 합의, 판정
이 구조로 속도(병렬)와 신뢰성(검증)을 동시에 확보합니다.
Reflect 패턴의 이점
Reflector는 단순히 두 결과를 비교하는 것이 아니라, 독립적으로 도출된 두 분석의 논증 구조를 교차 검증 합니다. RCA-A와 RCA-B가 서로 다른 모델로 동일한 결론에 도달했다면 해당 분석의 신뢰도는 크게 높아지고, 결론이 불일치하다면 각각의 증거 강도와 반증 견고성을 기준으로 우세를 판정합니다. 이를 통해 단일 Agent가 빠지기 쉬운 확증 편향을 구조적으로 방지하면서, 최종 보고서의 근거를 투명하게 추적할 수 있습니다.
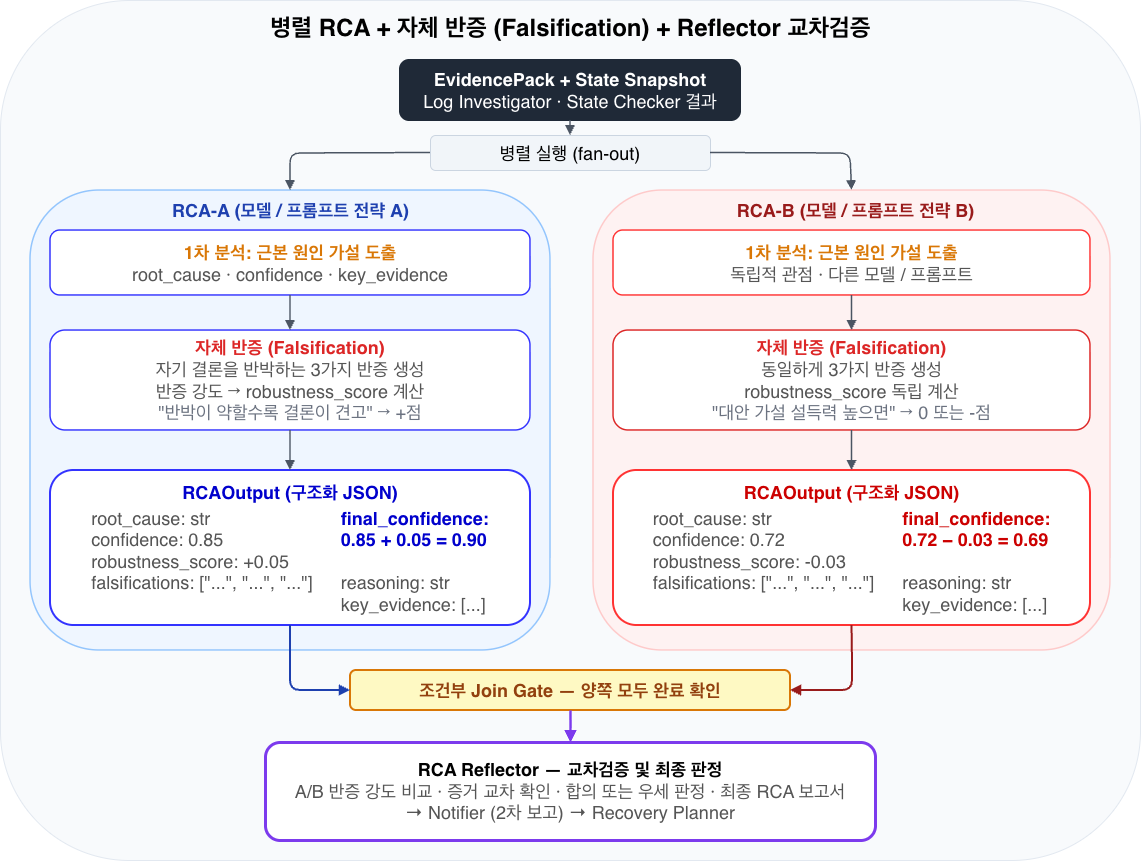
그림 5. 병렬 RCA + 자체 반증 + Reflector 교차검증
RCA-A와 RCA-B가 동일한 EvidencePack을 입력받아 독립적으로 근본 원인을 분석합니다. 각 RCA는 자기 결론에 대한 3가지 반증을 생성하고, 반증 강도에 따라 robustness_score를 계산합니다. Join Gate가 양쪽 완료를 확인한 뒤, Reflector가 두 분석을 교차검증하여 최종 판정합니다.
RCA 노드 출력 스키마
반증 기반 Robustness Score
- 반증이 짧고 빈약할수록(반박하기 어려울수록) 결론이 견고하다고 판단하여 Robustness Score 가 +점
- 대안 가설이 설득력 있게 나오면 0 또는 -점
- 최종 신뢰도를 confidence+robustness_score 로 산출
LangGraph 병렬 fan-in: Join Gate
LangGraph에서 두 병렬 노드의 출력을 하나의 후속 노드로 합류될 때, 양쪽이 모두 준비됐을 때만 Reflector를 실행하는 Gate 함수가 필요합니다. 실제 구현에서는 Pass-through Join 노드와 조건부 라우터를 조합하여 이를 처리합니다.
_merge_dict Reducer 덕분에 analysis.rca_a와 analysis.rca_b는 자동으로 Merge되며, 라우터 함수가 양쪽 결과의 존재를 확인한 뒤에만 Reflector로 진행합니다.
Amazon Bedrock 멀티모델 운영 전략
Amazon Bedrock은 다양한 모델을 단일 API로 호출할 수 있기 때문에, 노드 특성에 따라 모델을 분기하는 전략이 효과적입니다. 노드별 LLM 구성은 LLMRegistry를 통해 중앙에서 관리하며, 환경 변수로 런타임에 교체할 수 있습니다.
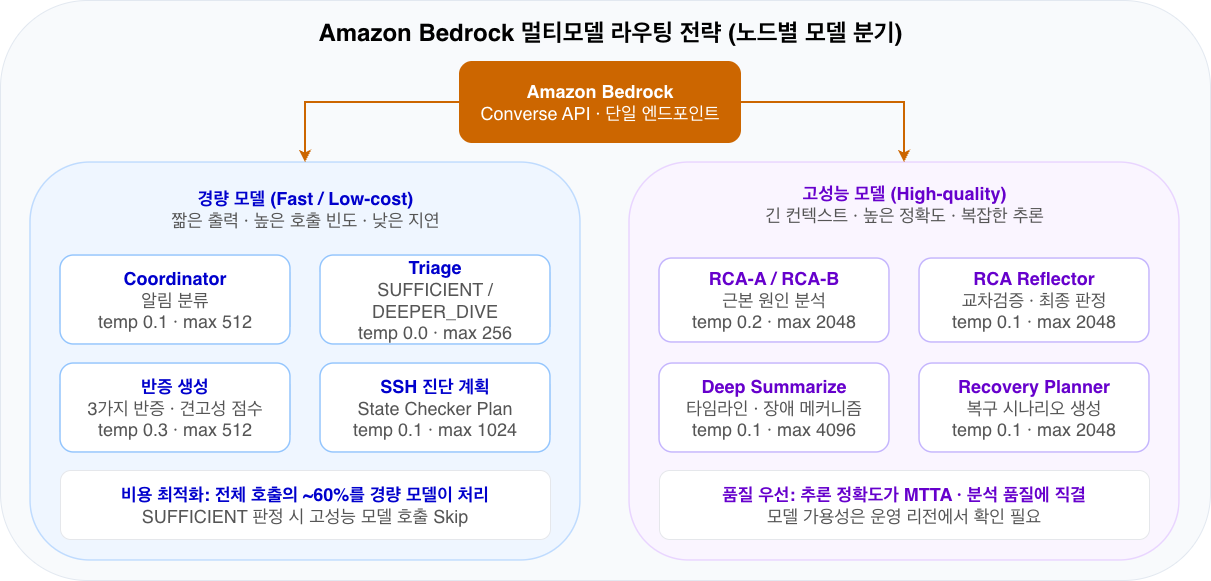
그림 6. Amazon Bedrock 멀티모델 라우팅 전략
전체 호출의 약 60%를 차지하는 경량 모델(Coordinator, Triage, 반증 생성, SSH 진단 계획)과 추론 품질이 핵심인 고성능 모델(RCA, Reflector, Deep Summarize)로 분기합니다. Triage에서 SUFFICIENT 판정 시 고성능 모델 호출을 건너뛰어 비용을 절감합니다.
| 역할 | 노드 | 모델 특성 | temperature | maxTokens |
|---|---|---|---|---|
| 경량 | Coordinator | 빠르고 저렴 | 0.1 | 512 |
| 경량 | Triage | 빠르고 저렴 | 0 | 256 |
| 경량 | 반증 생성 | 빠르고 저렴 | 0.3 | 512 |
| 경량 | SSH 진단 계획 | 빠르고 저렴 | 0.1 | 1024 |
| 고성능 | RCA-A / RCA-B | 추론 품질 우선 | 0.1 | 2048 |
| 고성능 | RCA Reflector | 추론 품질 우선 | 0.1 | 2048 |
| 고성능 | Deep Summarize | 추론 품질 우선 | 0.1 | 4096 |
| 고성능 | Recovery Planner | 추론 품질 우선 | 0.1 | 2048 |
운영 안정성과 보안 설계
자동화가 실질적인 가치를 발휘하려면, 운영 환경에서 신뢰할 수 있어야 합니다. 이를 위해 세 가지 원칙을 적용했습니다.
1) Human-in-the-Loop: 복구 실행 분리
자동화의 범위를 신중하게 설정했습니다. 진단은 자동화하되, 복구 명령 실행은 운영자 승인 후 수행합니다. Approval Wait 노드에서 Workflow를 일시 중단하고, Teams를 통해 운영자에게 복구 계획을 제시합니다. 승인이 이루어지면 Executor가 실행을 진행하고, State Checker(Verify)가 최대 3회까지 복구 상태를 검증합니다. 이는 자동화의 이점을 가져가면서도 오탐이나 실수의 리스크를 제어할 수 있는 가장 현실적인 방식입니다.
2) 비파괴적 명령만 자동 실행
State Checker 단계의 SSH는 uptime, ss -lntp, jps -l, systemctl status, df -h 등 read-only 명령만 허용합니다. 복구 단계는 별도의 Whitelist와 Guardrail 정책으로 제한합니다.
3) Checkpoint 기반 내결함성
PostgresSaver를 통해 각 노드 완료 시 상태가 자동 저장됩니다. 프로세스 재시작 시 마지막 Checkpoint에서 재개할 수 있어, 장시간 실행되는 Incident Workflow에서도 안정성을 확보했습니다.자세한 내용은 LangGraph의 PostgresSaver 구성 문서 를 참고하세요.
도입 효과
앞서 설정한 세 가지 핵심 목표—MTTA 단축, 품질 표준화, 지식 자산화—에 대해 도입 전후 변화를 정리하면 다음과 같습니다.
| 항목 | 도입 전 | 도입 후 |
|---|---|---|
| 1차 상태 보고 | 엔지니어가 수동 수집, 평균 3시간 이상 소요 | 알림 수신 후 수 분 내 자동 생성 |
| 분석 품질 | 담당자 경험에 의존, 야간·휴일에 편차 발생 | 병렬 RCA + 반증으로 일관성 확보 |
| 지식 축적 | 개인 노트나 구두 전달에 의존 | 모든 Incident의 스냅샷, 타임라인, 트레이스가 DB에 축적 |
향후 고도화 방향
장애 대응 자동화를 넘어, 장애를 사전에 예방하고 에이전트 스스로 학습·진화하는 시스템으로 발전시키기 위해 다음과 같은 고도화를 계획하고 있습니다.
1. 유사 Incident 검색 (RAG)
현재 모든 Incident의 상태 스냅샷, 타임라인, 명령 트레이스가 PostgreSQL에 축적되고 있습니다. 다음 단계는 이 데이터를 벡터화하여 유사 케이스를 자동으로 검색하고, RCA 노드의 입력 컨텍스트로 제공하는 것입니다. Amazon OpenSearch Service의 k-NN 벡터 검색이나 PostgreSQL의 pgvector 확장을 검토하고 있습니다. 나아가 베테랑 엔지니어의 암묵지를 구조화된 Knowledge Base로 전환하고, 운영자의 RCA 피드백을 유사 검색 가중치에 반영하는 순환 구조를 통해 에이전트의 분석 품질이 운영 경험과 함께 지속적으로 개선되는 것을 목표로 합니다.
2. 인시던트 상관분석
빅데이터 클러스터에서는 하나의 근본 원인이 여러 컴포넌트에 걸쳐 연쇄 알림을 유발하는 경우가 빈번합니다.
현재는 각 알림이 독립적인 Incident Workflow를 트리거하지만, 향후에는 시간 윈도우와 영향 범위를 기준으로 동시 다발 알림을 자동으로 그룹핑하여 하나의 상관 Incident로 묶는 것이 가능할 것입니다. 이를 통해 중복 조사를 방지하고, RCA 단계에서 더 넓은 맥락(여러 컴포넌트에 걸친 증거)을 한 번에 분석할 수 있어 근본 원인 식별의 정확도를 높일 수 있습니다.
3. 예방적 개선 (Proactive Prevention)
도입부에서 언급한 것처럼, 장애 대응의 궁극적 목표는 반복적인 소방 대응에서 벗어나 근본적 개선에 집중하는 것입니다. 축적된 Incident 데이터에서 동일 컴포넌트, 동일 원인으로 반복되는 장애 패턴을 탐지하고, 이를 바탕으로 관측성 강화, 인프라 개선, 운영 절차 개선 등 카테고리별 개선 권고를 자동 생성하는 단계로 나아갈 계획입니다. 개선 조치 적용 후 재발 여부를 추적하여 효과를 데이터로 검증하는 것까지가 목표입니다.
4. Amazon Bedrock 모델 라우팅 자동화
현재는 LLMRegistry를 통해 노드별 모델을 중앙에서 관리하고 환경 변수로 교체하고 있습니다. 향후에는 각 노드의 실행 이력에서 비용, 지연 시간, RCA 정확도(운영자 피드백 기반) 지표를 수집하고, 이를 기반으로 노드별 최적 모델을 동적으로 라우팅하는 방안을 준비하고 있습니다.
5. Amazon Bedrock AgentCore를 활용한 고도화 검토
Amazon Bedrock AgentCore는 LangGraph를 포함한 오픈소스 프레임워크와 호환되는 완전 관리형 에이전트 플랫폼입니다. 현재 시스템의 3축 — LangGraph 기반 워크플로우 오케스트레이션, Amazon OpenSearch Service 기반 로그 분석, Amazon Bedrock 기반 멀티모델 운영 — 구조를 유지하면서, 인프라 운영 부담을 줄이고 안정성을 높이기 위한 다음 단계로 검토하고 있습니다. 특히 에이전트 실행 환경의 스케일링, 모니터링, 보안 관리를 매니지드 서비스로 위임함으로써 팀이 에이전트의 도메인 로직과 품질 개선에 더 집중할 수 있을 것으로 기대합니다.
결론
현대오토에버 데이터플랫폼기술팀은 LangGraph로 장애 대응 workflow를 상태 기반 그래프로 구성하고, Amazon OpenSearch Service로 로그 탐색을 구조화하며, Amazon Bedrock의 멀티모델을 역할 분리된 에이전트로 운영해 Incident 대응을 자동화했습니다. 이 프로젝트에서 가장 중요하게 생각한 것은 자동화 그 자체가 아니라, 운영자가 더 빠르고 정확하게 판단할 수 있도록 돕는 것이었습니다. 두 개의 독립적인 RCA와 반증으로 결론의 신뢰도를 높이고, 승인 기반 실행으로 운영 리스크를 통제하는 Human-in-the-Loop 설계가 그 철학을 반영합니다.
빅데이터 클러스터 운영 자동화를 포함한 장애 대응 자동화 적용을 고민하시는 분들께 이 경험이 실질적인 참고가 되길 바랍니다.