AWS 기술 블로그
완전 관리형 AI 서비스를 활용하여 서버리스로 책 읽어주는 서비스 이용하기
카메라로 사진을 찍으면 번역해주거나 카메라로 찍은 이미지를 읽어주는 앱은 기계 학습(Machine Learning) 기술을 활용하고 있습니다. 이런 기계 학습 모델을 직접 개발하는 것은 상당한 기술적 노하우를 요구합니다. AWS에서는 Amazon SageMaker와 같이 기계 학습 모델을 개발하는 서비스 이외에도 다양한 완전 관리형(Managed) AI 서비스를 제공하고 있어서 기계 학습에 숙련된 인력이 없더라도 기계 학습 기반의 서비스를 쉽게 개발할 수 있습니다. 본 게시글에서는 AWS의 완전 관리형 AI 서비스인 Amazon Rekognition와 Amazon Polly를 이용하여, 사진에서 문장을 추출해서 읽어주는 서비스인 Story Time을 구현하고자 합니다. 이를 통해 기계 학습을 활용하여 이미지에서 텍스트를 추출하고 텍스트를 음성으로 변환하는 방법을 이해할 수 있습니다.
AWS에서 제공하는 완전 관리형 AI 서비스를 이용하여 기계 학습 문제를 해결하더라도 Story Time과 같은 서비스를 만들기 위해서는, 사용자의 입력을 받아 Amazon Simple Storage Service (Amazon S3)에 파일을 저장하고, Amazon Rekognition에 텍스트 추출 요청을 하고, 추출된 텍스트를 받아서 Amazon Polly에서 음성 파일을 생성한 다음에 이를 이메일과 같은 방법으로 사용자에게 결과를 전달하는 것과 같이 연속적인 순서(Sequence)로 데이터를 처리할 수 있어야 합니다. 또한 각종 서비스들을 쉽게 배포하고, 변화하는 트래픽에 대해서도 안정적으로 운영하고, 유지보수가 용이하여야 합니다. 여기에서는 이벤트 기반(event driven) 형태의 서버리스 아키텍처를 이용하여 연속적인 순서로 데이터를 쉽게 처리하고, 자동 확장(auto scaling)을 통해 시스템을 안정적으로 운영하며, 유지보수를 최소화합니다. 또한 AWS Cloud Development Kit (AWS CDK)를 활용하여 각종 인프라 서비스들을 쉽게 배포할 방법을 소개합니다.
Story Time의 아키텍처
전체적인 아키텍처는 다음과 같습니다. Amazon Rekognition을 이용하여 이미지에서 텍스트를 추출하고 Amazon Polly를 이용하여 텍스트를 음성으로 변환합니다. 두 완전 관리형 AI 서비스를 이벤트 기반 형태로 구현하기 위하여 AWS Lambda와 Amazon Simple Queue Service (Amazon SQS)를 사용합니다. 여기서 제안하는 아키텍처는 Amazon API Gateway를 엔드포인트(Endpoint)로 하는 API 서비스로도 활용할 수 있지만 일반적인 사용자의 사용성을 고려하여 Amazon CloudFront를 이용해 UI까지 제공하는 웹서비스 방식으로 구현하였습니다.

주요 사용 시나리오는 아래와 같습니다.
- 사용자가 웹브라우저를 이용하여 CloudFront의 도메인으로 접속합니다.
- CloudFront와 연결된 S3 버킷에서 HTML 파일을 로드합니다.
- 사용자는 음성으로 듣고자 하는 이미지 파일을 선택하여 업로드를 시작합니다.
- 파일 업로드 요청은 API Gateway의 “/upload” 리소스로 POST 메서드(Method) 방식으로 전달하여 RESTful하게 구현합니다.
- API Gateway와 연결된 Lambda 함수는 HTTPS POST의 body에 있는 바이너리 이미지(binary image)를 로드하여 base64로 디코딩한 후에 S3 버킷에 저장합니다. 이후 저장된 파일의 버킷(Bucket), 키(key)와 Request ID를 SQS에 전송합니다.
- 단계 5에서 SQS 대기열에 전달한 이벤트가 Lambda 함수를 트리거하면 Amazon Rekognition에 이미지 정보를 전달하여 텍스트를 추출합니다. 이후 추출된 텍스트와 Request ID를 포함한 정보를 SQS 대기열에 전달합니다.
- 단계 6에서 SQS 대기열에 전달한 이벤트가 Lambda 함수를 트리거하면 Amazon Polly에 텍스트를 전달하여 MP3 음성파일을 생성합니다. 생성된 음성파일의 위치인 버킷, 키값과 CloudFront의 도메인을 이용하여 음성파일을 다운로드할 수 있는 URL 정보를 만들어서, Amazon Simple Notification Service (Amazon SNS)를 이용하여 사용자에게 이메일로 전달합니다.
- Amazon Polly는 생성한 음성파일을 지정된 S3 버킷에 저장합니다.
- SNS는 구독된 이메일 주소로 음성 파일의 URL 정보를 전달합니다.
- 사용자는 이메일의 링크를 선택하여 음성파일을 들을 수 있습니다.
시스템 동작은 Sequence Diagram을 참고합니다.
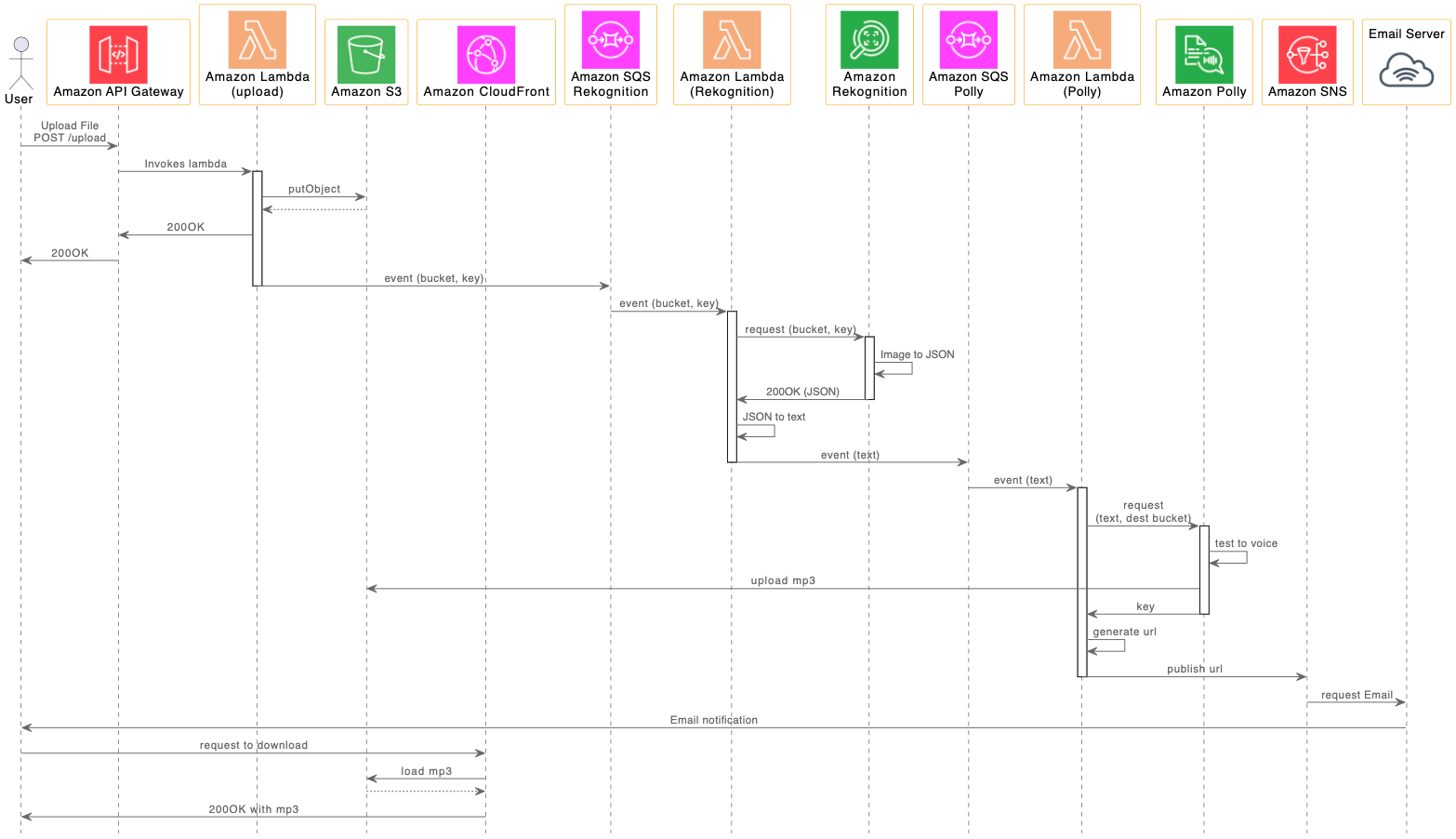{kind=link}

상세 시스템 구성
파일을 업로드하는 Lambda 함수의 구현
파일을 업로드하는 Lambda 함수는 API Gateway로 인입된 이미지 데이터를 base64로 디코딩한 후에 S3 버킷에 저장합니다. 이후 이미지의 버킷, 키값을 JSON 형태로 만들어서 SQS 대기열에 전송합니다. 전체 코드는 여기(index.js)에서 확인할 수 있습니다.
API Gateway가 Lambda 함수로 전달한 이벤트에는 바이너리 이미지 파일, Contents-Type, 파일 이름과 같은 정보가 있습니다. 이를 아래와 같이 추출합니다. 또한, uuid를 생성하여 이벤트를 구분하기 위한 ID로 활용하고, 사용자의 요청에 파일이름이 없는 경우에는 uuid를 파일 이름으로 사용합니다.
const body = Buffer.from(event["body"], "base64");
const header = event['multiValueHeaders'];
let contentType;
if(header['Content-Type']) {
contentType = String(header['Content-Type']);
}
let contentDisposition="";
if(header['Content-Disposition']) {
contentDisposition = String(header['Content-Disposition']);
}
let filename = "";
const uuid = uuidv4();
if(contentDisposition) {
filename = cd.parse(contentDisposition).parameters.filename;
}
else {
filename = uuid+'.jpeg';
}
S3 putObject를 이용하여 아래와 같이 파일을 업로드합니다.
const destparams = {
Bucket: bucketName,
Key: filename,
Body: body,
ContentType: contentType
};
await s3.putObject(destparams).promise();업로드된 파일의 정보를 SQS 대기열로 전송합니다. 이때 파일의 정보는 uuid로 만든 유일한 ID와 이미지 파일에 대한 버킷 이름 및 파일 이름입니다.
const fileInfo = {
Id: uuid,
Bucket: bucketName,
Key: filename,
};
let params = {
DelaySeconds: 10,
MessageAttributes: {},
MessageBody: JSON.stringify(fileInfo),
QueueUrl: sqsRekognitionUrl
};
await sqs.sendMessage(params).promise();Amazon Rekognition에 텍스트 추출을 요청하는 Lambda 함수의 구현
Lambda 함수를 이용하여 Amazon Rekognition에 텍스트의 추출을 요청하고, SQS 대기열에 음성 파일로 변환해야 할 텍스트 정보를 전달합니다. 전체 코드는 여기(index.js)에서 확인할 수 있습니다.
SQS 대기열로부터 Lambda 함수로 전달된 이벤트에서 버킷 이름과 키를 추출하여 아래처럼 Amazon Rekognition에 테스트 추출을 요청합니다.
const body = JSON.parse(event['Records'][0]['body']);
const bucket = body.Bucket;
const key = body.Key;
const rekognition = new aws.Rekognition();
const rekognitionParams = {
Image: {
S3Object: {
Bucket: bucket,
Name: key
},
},
}
let data = await rekognition.detectText(rekognitionParams).promise();Amazon Rekognition이 전달한 텍스트 정보는 위치 정보를 포함하고 있습니다. 이를 읽어 주기 위해서는 아래와 같이 하나의 문장으로 변환하여야 합니다. 여기에서는 Amazon Rekognition이 LINE 타입으로 분류한 텍스트를 모아서 문장을 생성합니다.
let text = "";
for (let i = 0; i < data.TextDetections.length; i++) {
if(data.TextDetections[i].Type == 'LINE') {
text += data.TextDetections[i].DetectedText;
}
}Amazon Rekognition을 통해 추출한 문장과 이미지 파일에 대한 버킷 이름 및 키 등을 아래와 같이 SQS 대기열에 전송합니다.
let sqsParams = {
DelaySeconds: 10,
MessageAttributes: {},
MessageBody: JSON.stringify({
Id: id,
Bucket: bucket,
Key: key,
Name: name,
Text: text
}),
QueueUrl: sqsPollyUrl
};
await sqs.sendMessage(sqsParams).promise();Amazon Polly에 텍스트를 음성으로 변환을 요청하는 Lambda 함수의 구현
Lambda 함수를 이용하여 이미지에서 추출한 문장을 Amazon Polly에 음성 파일로 변환을 요청하고, 결과를 사용자에게 보내기 위해서 SNS 주제로 전송합니다. 전체 코드는 여기(index.js)에서 확인할 수 있습니다.
아래 코드는 SQS 대기열로부터 얻은 이벤트에서 텍스트와 버킷 이름을 추출하여 Amazon Polly을 사용하여 음성으로 변환하는 것을 보여줍니다.
const body = JSON.parse(event['Records'][0]['body'])
const bucket = body.Bucket;
const text = body.Text;
let pollyParams = {
OutputFormat: "mp3",
OutputS3BucketName: bucket,
Text: text,
TextType: "text",
VoiceId: "Ivy", // child girl
Engine: 'neural',
};
pollyResult = await polly.startSpeechSynthesisTask(pollyParams).promise();
const pollyUrl = pollyResult.SynthesisTask.OutputUri;
const fileInfo = path.parse(pollyUrl);
key = fileInfo.name + fileInfo.ext;추출된 음성파일 결과를 사용자에게 URL로 전달하기 위해서 CloudFront의 도메인 정보를 이용하여 URL을 생성합니다. 또한 메시지에는 추출된 텍스트 결과도 아래와 같이 SNS의 주제(Topic)에 메시지를 게시(publish)합니다.
const CDN = process.env.CDN;
const topicArn = process.env.topicArn;
let url = CDN+key;
let snsParams = {
Subject: 'Get your voice book generated from '+name,
Message: '('+id+') Link: '+url+'\n'+text,
TopicArn: topicArn
};
await sns.publish(snsParams).promise();웹브라우저에서 파일 업로드 구현
JavaScript에서는 바이너리 타입으로 이미지 파일을 업로드하기 위하여 Blob을 사용하여 아래처럼 구현합니다.
const uri = "https://d1kpgkk8y8p43t.cloudfront.net/upload";
const xhr = new XMLHttpRequest();
xhr.open("POST", uri, true);
var blob = new Blob([file], {type: 'image/jpeg'});
xhr.send(blob);AWS CDK로 리소스 생성 코드 준비
AWS 리소스를 효과적으로 배포하기 위하여 Infrastructure as Code(IaC) 도구인 CDK를 이용해 배포하고자 합니다. 여기에서는 TypeScript를 이용하여 CDK 코드를 구현합니다. 전체 코드는 여기(cdk-storytime-stack.ts)에서 확인할 수 있습니다.
S3 버킷을 생성하고 CloudFront와 연결합니다.
const s3Bucket = new s3.Bucket(this, "storage",{
// bucketName: bucketName,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL,
removalPolicy: cdk.RemovalPolicy.DESTROY,
autoDeleteObjects: true,
publicReadAccess: false,
versioned: false,
});
const distribution = new cloudFront.Distribution(this, 'cloudfront', {
defaultBehavior: {
origin: new origins.S3Origin(s3Bucket),
allowedMethods: cloudFront.AllowedMethods.ALLOW_ALL,
cachePolicy: cloudFront.CachePolicy.CACHING_DISABLED,
viewerProtocolPolicy: cloudFront.ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
},
priceClass: cloudFront.PriceClass.PRICE_CLASS_200,
});결과를 사용자에게 전달하기 위하여 SNS 주제를 생성합니다.
const topic = new sns.Topic(this, 'SNS', {
topicName: 'sns'
});
topic.addSubscription(new subscriptions.EmailSubscription(email));Amazon Rekognition과 Amazon Polly를 위한 SQS 대기열을 정의합니다.
const queueRekognition = new sqs.Queue(this, 'QueueRekognition', {
queueName: "queue-rekognition",
});
const queuePolly = new sqs.Queue(this, 'QueuePolly', {
queueName: "queue-polly",
});파일 업로드를 처리하는 Lambda 함수를 생성하고 SQS 대기열과 S3 버킷에 대한 퍼미션을 부여합니다.
const lambdaUpload = new lambda.Function(this, "LambdaUpload", {
runtime: lambda.Runtime.NODEJS_16_X,
functionName: "lambda-for-upload",
code: lambda.Code.fromAsset("../lambda-upload"),
handler: "index.handler",
timeout: cdk.Duration.seconds(10),
environment: {
sqsRekognitionUrl: queueRekognition.queueUrl,
bucketName: s3Bucket.bucketName
}
});
queueRekognition.grantSendMessages(lambdaUpload);
s3Bucket.grantReadWrite(lambdaUpload);Amazon Rekognition에 텍스트 추출을 의뢰하는 Lambda 함수를 정의합니다. Upload Lambda 함수가 SQS 대기열에 저장한 이벤트를 받기 위하여 SQS 대기열을 이벤트 소스(Event Source)로 등록하고, SQS 전송, S3 읽기, Amazon Rekognition에 대한 퍼미션을 부여합니다.
const lambdaRekognition = new lambda.Function(this, "LambdaRekognition", {
runtime: lambda.Runtime.NODEJS_16_X,
functionName: "lambda-for-rekognition",
code: lambda.Code.fromAsset("../lambda-rekognition"),
handler: "index.handler",
timeout: cdk.Duration.seconds(10),
environment: {
sqsRekognitionUrl: queueRekognition.queueUrl,
sqsPollyUrl: queuePolly.queueUrl,
}
});
lambdaRekognition.addEventSource(new SqsEventSource(queueRekognition));
queuePolly.grantSendMessages(lambdaRekognition);
s3Bucket.grantRead(lambdaRekognition);
const RekognitionPolicy = new iam.PolicyStatement({ // rekognition policy
actions: ['rekognition:*'],
resources: ['*'],
});
lambdaRekognition.role?.attachInlinePolicy(
new iam.Policy(this, 'rekognition-policy', {
statements: [RekognitionPolicy],
}),
);텍스트를 음성파일로 변환하도록 Amazon Polly에 요청하는 Lambda 함수를 생성합니다. 이때 Lambda함수는 Amazon Rekognition의 결과가 전달되는 SQS 대기열을 이벤트 소스(Event Souce)로 등록하고 SNS 주제(topic)에 대한 게시(Publish), S3에 대한 쓰기, 그리고 Amazon Polly를 사용할 수 있도록 퍼미션을 추가합니다.
const lambdaPolly = new lambda.Function(this, "LambdaPolly", {
runtime: lambda.Runtime.NODEJS_16_X,
functionName: "lambda-for-poly",
code: lambda.Code.fromAsset("../lambda-polly"),
handler: "index.handler",
timeout: cdk.Duration.seconds(10),
environment: {
CDN: 'https://'+distribution.domainName+'/',
sqsPollyUrl: queuePolly.queueUrl,
topicArn: topic.topicArn,
bucketName: s3Bucket.bucketName
}
});
lambdaPolly.addEventSource(new SqsEventSource(queuePolly));
topic.grantPublish(lambdaPolly);
s3Bucket.grantWrite(lambdaPolly);
const PollyPolicy = new iam.PolicyStatement({ // polloy policy
actions: ['polly:*'],
resources: ['*'],
});
lambdaPolly.role?.attachInlinePolicy(
new iam.Policy(this, 'polly-policy', {
statements: [PollyPolicy],
}),
);API Gateway를 통해 외부에서 요청을 받습니다. 이때 요청의 body에 있는 이미지 파일을 API Gateway에서 받기 위하여 아래처럼 binaryMediaTypes를 설정하고 프록시 모드로 동작합니다.
const stage = "dev";
const api = new apiGateway.RestApi(this, 'api-storytime', {
description: 'API Gateway',
endpointTypes: [apiGateway.EndpointType.REGIONAL],
binaryMediaTypes: ['*/*'],
deployOptions: {
stageName: stage,
},
});
// POST method
const resourceName = "upload";
const upload = api.root.addResource(resourceName);
upload.addMethod('POST', new apiGateway.LambdaIntegration(lambdaUpload, {
passthroughBehavior: apiGateway.PassthroughBehavior.WHEN_NO_TEMPLATES,
credentialsRole: role,
integrationResponses: [{
statusCode: '200',
}],
proxy:true,
}), {
methodResponses: [{ // API Gateway sends to the client that called a method.
statusCode: '200',
responseModels: {
'application/json': apiGateway.Model.EMPTY_MODEL,
},
}]
}); CORS 회피를 위해 API Gateway로 구현한 Upload API는 CloudFront를 이용해 URL Routing을 수행합니다. 파일 업로드는 POST 메서드를 사용하므로 allowedMethods를 cloudFront.AllowedMethods.ALLOW_ALL로 설정하여 POST 메서드를 허용합니다.
distribution.addBehavior("/upload", new origins.RestApiOrigin(api), {
cachePolicy: cloudFront.CachePolicy.CACHING_DISABLED,
allowedMethods: cloudFront.AllowedMethods.ALLOW_ALL,
viewerProtocolPolicy: cloudFront.ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
});직접 실습해 보기
사전 준비 사항
이 솔루션을 사용하기 위해서는 사전에 아래와 같은 준비가 되어야 합니다.
AWS Cloud9 환경 생성
AWS Cloud9을 활용하면 브라우저만으로 코드를 작성, 실행 및 디버깅을 쉽게 할 수 있으며, 배포를 위한 편리한 환경을 생성할 수 있습니다. 여기서는 편의상 서울 리전을 사용하여 AWS Cloud9 으로 인프라를 생성합니다.
AWS Cloud9 관리 콘솔로 진입하여 [Create environment]를 선택한 후에 아래처럼 Name을 입력합니다. 여기서는 “Storytime”이라고 입력하였습니다. 이후 나머지는 기본값을 유지하고 [Create]를 선택합니다.

AWS Cloud9환경이 생성되면 [Open]후 아래처럼 Terminal을 준비합니다.

CDK로 솔루션 배포하기
아래와 같이 소스를 다운로드합니다.
curl https://aws-korea-tech-blog-public.s3.ap-northeast-2.amazonaws.com/serverless-storytime-using-managed-ai-service/simple-serverless-storytime.zip -o simple-serverless-storytime.zip
이후 압축을 풉니다.
unzip simple-serverless-storytime.zip
아래와 같이 “simple-serverless-storytime/cdk-storytime/lib/cdk-storytime-stack.ts”을 열어서, 이메일 주소를 업데이트합니다.

터미널로 돌아가서, CDK 폴더로 이동한 후에 필요한 라이브러리를 설치합니다.
cd simple-serverless-storytime/cdk-storytime && npm install
CDK를 처음 사용하는 경우에는 아래와 같이 bootstrap을 실행하여야 합니다. 여기서 account-id는 12자리의 계정 번호를 의미합니다. AWS 콘솔 화면에서 확인하거나, “aws sts get-caller-identity –query Account –output text” 명령어로 확인할 수 있습니다.
cdk bootstrap aws://account-id/ap-northeast-2
이제 CDK로 전체 인프라를 생성합니다.
cdk deploy
정상적으로 인프라가 설치되면 아래와 같은 화면이 노출됩니다. 여기서 Output의 “UploadUrl”로 부터 접속하는 웹페이지의 정보가 “https://d1kpgkk8y8p43t.cloudfront.net/upload.html”임을 알 수 있습니다.

인프라를 설치하고 나면, CDK 라이브러리에 등록한 이메일 주소로 Confirmation 메시지가 전달됩니다. 이메일을 열어서 아래와 같이 [Confirm subscription]을 선택합니다.

정상적으로 진행되면 아래와 같은 결과를 얻습니다.

실행하기
로컬 PC에서 sample.jpeg을 다운로드합니다. 이후, 웹 브라우저를 이용하여 Output에 있는 “UploadUrl”로 접속합니다. 여기서는 “https://d1kpgkk8y8p43t.cloudfront.net/upload.html”로 접속하는데, “d1kpgkk8y8p43t.cloudfront.net”은 CloudFront의 도메인입니다. 크롬 브라우저를 이용하여 웹페이지로 접속하면 아래와 같이 [Choose File]과 [Send] 버튼이 보입니다. 웹 브라우저마다 보이는 화면은 조금 다를 수 있습니다. 웹페이지에서 [Choose File] 버튼을 선택하여 “sample.jpeg”을 선택합니다. 이후, [Send] 버튼을 선택하면 파일이 업로드됩니다. 업로드된 그림에서 아래의 텍스트 영역을 음성으로 변환하고자 합니다.
{kind=link}

실행결과
파일을 업로드 한 후에 수십 초가 지나면 아래와 같이 등록한 이메일로 결과가 전달됩니다. 링크에는 MP3 파일의 URL 경로가 있어서 사용자가 선택하면 재생할 수 있습니다. 또한 링크 아래에 추출된 텍스트 정보가 전달됩니다.

“sample.jpeg”로 부터 텍스트를 추출하여 생성한 음성은 sample-result.mp3에서 확인할 수 있습니다.
리소스 정리하기
인프라를 사용하지 않는 경우에 아래처럼 모든 리소스를 삭제할 수 있습니다.
cd /home/ec2-user/environment/simple-serverless-storytime/cdk-storytime && cdk destroy
결론
AWS의 완전 관리형 AI 서비스인 Amazon Rekognition과 Amazon Polly를 이용하여 이미지에서 텍스트를 추출하고 음성으로 변환하는 이벤트 기반(Event driven) 아키텍처를 AWS CDK를 이용하여 구현하였습니다. 이를 통해 사용자는 직접 기계 학습 모델을 개발하지 않더라도 편리하게 필요한 앱을 개발할 수 있습니다. 완전 관리형 AI 서비스를 활용하여 서버리스 아키텍처를 구성하면 확장가능(Scalable)한 시스템을 안정적으로 구축하고 유지보수 비용을 최소화하여 운용할 수 있습니다.
실습 코드 및 도움이 되는 참조 블로그
아래의 링크에서 실습 소스 파일 및 기계 학습(ML)과 관련된 자료를 확인하실 수 있습니다.