AWS 기술 블로그
포스코DX의 엔지니어링 암묵지를 AI가 활용할 수 있는 지식 자산으로 전환하기
들어가며
“이 밸브 유형에는 향후 사양 변경에 대비해 예비 접점을 반드시 확보합니다.”
20년 차 시니어 엔지니어는 이 규칙을 당연하게 적용합니다. 하지만 이 판단 기준은 어떤 매뉴얼에도 적혀 있지 않고, 어떤 교과서에도 나오지 않으며, 인터넷 어디에서도 검색할 수 없습니다. 오직 수십 년의 현장 경험을 통해, 사람에서 사람으로 전승되어 온 지식입니다.
이 문제는 한 조직만의 이야기가 아닙니다. Panopto와 YouGov의 직장 내 지식 생산성 조사(2018)에 따르면, 직무 지식의 42%는 해당 개인에게만 존재하는 고유 지식이며, 그 직원이 퇴직하면 동료가 해당 직무의 42%를 수행할 수 없게 됩니다. 응답자의 81%는 “경험으로 얻은 지식이 가장 대체하기 어렵다”고 답했습니다. 제조업처럼 현장 경험 의존도가 높은 산업에서는 이 문제가 더욱 심각합니다.
포스코DX 자동화사업실은 철강 플랜트의 EIC(Electric, Instrumentation & Control) 전반을 총괄하며, 핵심 업무로서 PLC(Programmable Logic Controller) 제어 설계를 수행합니다. 이 조직의 설계 노하우 — 슬롯 균등 분배 기준, 모듈카드 배치 순서 원칙, 공정별 I/O 분리 규칙 등 — 는 수십 년간 현장에서 검증된 핵심 자산이지만, 그 대부분이 시니어 엔지니어 개인의 경험 속에만 존재합니다.
2025년부터 AI 기반 설계 자동화(Engineering Automation)를 추진하면서, 한 가지 근본적인 질문에 부딪혔습니다.
“범용 AI 모델에게 ‘우리 규칙대로 설계해 달라‘고 하면, AI는 ‘우리 규칙‘을 어떻게 알 수 있을까?”
답은 명확했습니다. 알 수 없습니다. AI의 사전 학습 데이터에 포스코DX 고유의 설계 판단 기준은 포함되어 있지 않기 때문입니다. 이 문제를 해결하지 않으면, AI의 출력은 “일반적으로는 맞지만 우리 현장에서는 틀린” 결과에 머물 수밖에 없습니다.
이 글에서는 이 문제를 어떻게 정의했는지, 그리고 Amazon Bedrock과 Graphiti 기반 지식 그래프를 활용하여 해결 방안을 PoC로 검증한 전 과정을 공유합니다.
│ 참고: 이 글에 등장하는 설계 규칙의 구체적 수치, 규칙 번호, 임계값 등은 비즈니스 기밀 보호를 위해 일반화된 예시로 대체되었습니다. 솔루션의 구조와 방법론은 실제 구현을 충실히 반영합니다.
문제 정의: UDK(Untrained Domain Knowledge)
“AI가 모르는 것”을 식별하다
설계 자동화 프로젝트에서 PLC 제어 설계 규칙을 코드로 구현하는 과정에서, 총 35개의 설계 규칙을 식별했습니다. 프로젝트 초기에는 “최신 LLM이라면 엔지니어링 지식 대부분을 이미 알고 있을 것”이라는 기대가 있었습니다.
그러나 실제 검증 결과는 달랐습니다. 각 설계 규칙을 범용 LLM에게 제시하고 “이 내용을 사전에 학습한 것인지” 확인한 결과, 35개 규칙 중 28개(약 80%)를 AI가 학습하지 못한 것으로 확인되었습니다.
│ 질문: “솔레노이드 밸브 설계 시 접점 수는?”
│ AI의 답변: “현재 사양 기준으로 최소 필요 접점만 확보하면 됩니다.”
│ 현장 엔지니어의 답변: “향후 사양 변경에 대비하여 예비 접점을 추가로 확보합니다.”
AI는 교과서적 정답을 제시했지만, 현장 엔지니어는 미래의 사양 변경 가능성까지 고려한 판단을 내립니다. 이 차이, “기술적 정답”과 “현장 최적해” 사이의 간극에 해당하는 지식을 UDK(Untrained Domain Knowledge) — AI가 사전 학습하지 못한 도메인 지식 — 라 정의했습니다.
3축 분류 체계
식별된 35개 규칙을 체계적으로 분류하기 위해 3가지 축을 설정했습니다.
- AI 학습 여부: 범용 LLM의 사전 학습 데이터에 포함되어 있는가?
- 지식의 성격: 문서화된 형식지(explicit)인가, 경험으로만 전승되는 암묵지(tacit)인가?
- 지식의 범위: 우리 조직 고유인가, 산업 일반적인가?
세 축을 동시에 펼치면 조합이 많아지지만, 실제로는 첫 축인 ‘AI 학습 여부’가 갈림길 역할을 합니다. 이미 학습된 지식은 별도로 자산화할 필요가 없으므로 유형 5(일반 지식) 하나로 묶이고, 학습되지 않은 지식만 다시 ‘성격(형식지/암묵지)’과 ‘범위(자사/그룹/산업)’에 따라 유형 1~4로 세분화됩니다. 그 결과 이론적으로 가능한 모든 조합이 아니라, 35개 규칙에서 실제로 관찰된 다섯 가지 유형으로 정리됩니다. 아래 표의 비율은 전체 35개 규칙 중 각 유형이 차지하는 비중입니다.
| 유형 | 분류 | 예시 | 비율 |
| 1 | AI 미학습 + 암묵지 + 자사 고유 | 장비별 예비 접점 확보 기준, 슬롯 분배 임계값, 모듈 배치 순서 | ~60% |
| 2 | AI 미학습 + 암묵지 + 그룹 특화 | 특정 공정에 특화된 접점 구성 패턴 | ~5% |
| 3 | AI 미학습 + 형식지 + 자사 고유 | 내부 코드 매핑 체계, 표기 규칙, 넘버링 규약 | ~10% |
| 4 | AI 미학습 + 엔지니어링 일반 | 장비 사양 기반 배치 규칙, 물리적 연결 제약 | ~5% |
| 5 | AI 학습 완료 + 일반 지식 | 국제 표준(IEC 61131-3) 기반 주소 체계 | ~20% |
결과적으로, 35개 규칙 중 약 80%(유형 1~4)가 AI에게 별도로 제공해야 하는 UDK였습니다. 그 중에서도 가장 큰 비중(60%)을 차지하는 유형 1은 문서화조차 되어 있지 않은 조직 고유의 암묵지입니다. 이 지식은 시니어 엔지니어가 퇴직하거나 이동하는 순간 영구적으로 유실됩니다. 단순한 IT 과제가 아니라, 조직의 핵심 경쟁력을 어떻게 보존할 것인가의 문제입니다.
LLM 학습 여부 판별 프로세스
“이 규칙을 AI가 아는지 모르는지”를 어떻게 체계적으로 판별했을까요? 각 설계 규칙의 핵심 내용을 범용 LLM(Claude)에게 제시하고, “이 내용을 사전 학습 데이터를 통해 알고 있는 지식인가”를 직접 확인하는 방식을 사용했습니다. LLM이 해당 규칙의 존재와 판단 근거를 설명할 수 있으면 “학습 완료”, 그렇지 않으면 “미학습”으로 분류합니다.
이 방식의 핵심은 단순히 결론의 일치 여부가 아니라, LLM이 “왜 그렇게 하는가(판단 근거)”까지 정확히 설명할 수 있는지를 기준으로 삼는다는 점입니다. 설령 결론이 우연히 같더라도, 판단 근거를 모르면 “미학습”으로 분류합니다. 이유 없는 정답은 신뢰할 수 없기 때문입니다.
왜 지식 그래프인가
UDK를 식별했다면, 다음 단계는 두 가지입니다. 첫째, 이 지식을 AI가 활용할 수 있는 형태로 구조화하는 것. 둘째, 구조화된 지식을 필요한 시점에 정확하게 검색하여 AI에게 전달(RAG)하는 것. 이 둘은 분리된 문제가 아닙니다 — 지식을 어떤 형태로 저장하느냐가 곧 검색의 품질을 결정합니다.
단순 문서화의 한계
설계 규칙을 Word 파일이나 위키에 정리하는 것은 가장 먼저 떠오르는 방법이지만, 세 가지 근본적 한계가 있습니다.
첫째, 맥락 기반 검색이 불가능합니다. “이 장비에 적용되는 모든 설계 규칙은?”이라는 질문에 키워드 매칭만으로는 답할 수 없습니다. 규칙이 장비를 직접 언급하지 않더라도, 해당 장비가 속한 공정이나 모듈 유형을 통해 간접적으로 적용되는 규칙까지 찾아야 합니다.
둘째, 변경 영향도를 파악할 수 없습니다. “분배 규칙을 변경하면 어디에 영향이 가는가?” — 이 질문에 답하려면 규칙 간의 의존(depends_on), 충돌(conflicts_with), 전제 조건(has_precondition) 관계를 명시적으로 알아야 합니다. 비정형 문서에서는 이런 관계가 암시적으로만 존재합니다.
셋째, AI 컨텍스트로 주입하기 어렵습니다. AI에게 “우리 규칙대로 설계해 줘”라고 하려면, 해당 맥락에 관련된 규칙만 선별하여 구조화된 형태로 제공해야 합니다. 수백 페이지의 비정형 문서를 통째로 프롬프트에 넣는 것은 컨텍스트 길이, 비용, 정확도 모든 측면에서 비현실적입니다.
벡터 DB(일반 RAG)와의 비교
벡터 DB 기반 RAG는 최근 가장 널리 사용되는 지식 활용 방식이지만, 설계 규칙 도메인에서는 구조적 한계가 있습니다.
| 비교 항목 | 벡터 DB (일반 RAG) | 지식 그래프 (이번 접근) |
| 검색 방식 | 의미적 유사도 기반 | 의미 + 키워드 + 관계 순회 |
| 관계 표현 | 불가능 (문서 조각이 독립적) | depends_on, conflicts_with 등 명시적 |
| 영향도 분석 | 불가능 | 규칙 변경 시 영향받는 규칙 자동 추적 |
| 시간축 관리 | 스냅샷 기반 | 규칙별 유효 기간(valid_from/valid_to) |
| 중복 엔티티 | 다른 표현이 별개로 저장 | Entity Resolution으로 자동 병합 |
| 추론 | 검색된 조각 내에서만 | 그래프 순회를 통한 multi-hop 추론 |
핵심 차이는 “관계“를 일급 시민(first-class citizen)으로 다루는가 여부입니다. 설계 규칙 간의 의존, 충돌, 대체 관계 자체가 중요한 지식이므로, 이를 명시적으로 표현하고 순회할 수 있는 지식 그래프가 적합합니다.
물론, 벡터 검색의 장점 — 의미적 유사도 기반의 유연한 탐색 — 을 포기할 이유는 없습니다. 이번 솔루션에서는 지식 그래프 위에 벡터 검색을 결합한 하이브리드 방식을 채택했습니다.
솔루션 아키텍처: End-to-End 파이프라인
전체 흐름
AWS와 함께 설계한 파이프라인은 9개 단계로 구성됩니다.
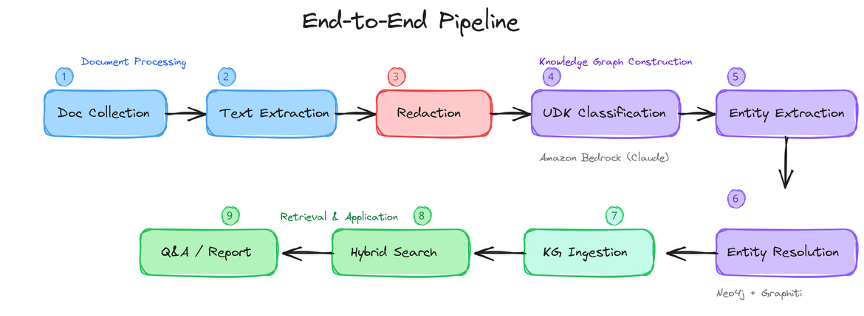
각 단계는 독립적으로 실행 가능하며, 실패 시 해당 단계만 재실행하도록 설계했습니다. 문서 수집부터 Q&A가 가능해지기까지의 소요 시간은 약 60초입니다.
1~3단계는 문서 처리(Document Processing) 영역입니다. 14종 포맷(docx, pdf, pptx, xlsx, mp4 등)의 문서를 수집하고, VLM 기반 OCR로 이미지나 스캔 문서까지 텍스트를 추출합니다. 이어서 Bedrock Claude의 문맥 이해 능력을 활용해 민감정보(내부 프로젝트명, 협력사명, 구체적 수치 등)를 탐지하고 제거합니다.
4~5단계는 지식 그래프 구축의 전반부입니다. 정제된 텍스트에서 각 규칙을 5가지 UDK 유형으로 자동 분류하고, 엔티티(설계 규칙, 장비, 공정)와 관계(depends_on, conflicts_with 등)를 구조화된 JSON으로 추출합니다. 두 단계 모두 Bedrock Claude의 Zero-shot 추론을 활용합니다.
6~7단계는 지식 그래프 구축의 후반부입니다. Graphiti의 Entity Resolution이 동일 개념의 다른 표현을 자동 식별하여 단일 노드로 병합하고, 시간축(valid_from/valid_to)과 함께 Neo4j 그래프에 적재합니다.
8~9단계는 검색과 활용(Retrieval & Application) 영역입니다. 사용자 질의에 대해 벡터 검색(Titan Embeddings), BM25 키워드 검색, 그래프 순회를 병렬로 수행하고 RRF(Reciprocal Rank Fusion)로 융합한 뒤, Bedrock Claude가 출처 인용이 포함된 답변을 생성합니다.
인프라 구성
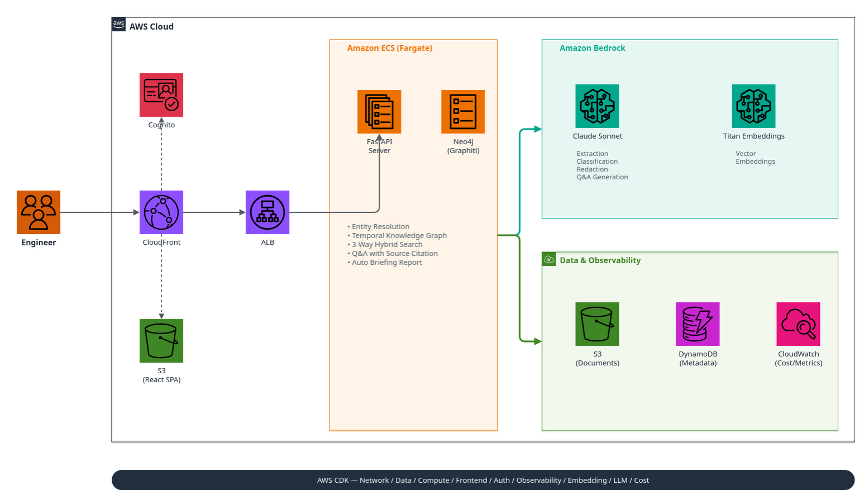
파이프라인은 Amazon Bedrock을 관리형으로 사용하여 모델 운영 부담을 제거했습니다. Claude Sonnet이 추출, 분류, Q&A를, Titan Embeddings가 벡터 검색을 담당합니다. 애플리케이션 서버(FastAPI)와 Neo4j는 Amazon ECS(Fargate) 위에서 서버리스로 호스팅되며, 문서 저장과 상태 추적에는 Amazon S3와 Amazon DynamoDB를, 사용자 인증과 프론트엔드 배포에는 Amazon CloudFront + Amazon Cognito를 활용합니다. LLM 토큰 사용량과 비용은 Amazon CloudWatch로 실시간 추적합니다.
전체 인프라는 AWS CDK로 코드화되어 있으며, Network, Data, Compute, Frontend, Auth, Observability, Embedding, LLM, Cost 등 9개 스택으로 구성됩니다. 환경별 파라미터만 변경하면 동일한 인프라를 재현할 수 있습니다.
Graphiti + Neo4j: 시간적 지식 그래프
왜 Graphiti인가
Graphiti는 시간적 지식 그래프(Temporal Knowledge Graph)를 구축하기 위한 오픈소스 프레임워크입니다. Neo4j를 스토리지 백엔드로 사용하며, 일반적인 그래프 DB 위에 세 가지 핵심 기능을 추가합니다.
첫째, Entity Resolution입니다. 동일 개념의 다른 표현을 자동으로 인식하고 병합합니다. 둘째, Temporal Fact Management로, 모든 관계에 시간축(유효 기간)을 부여합니다. 셋째, Episode 기반 Provenance를 통해 각 지식의 출처를 원본 문서 단위로 추적합니다.
실제 코드에서는 add_episode() API 하나로 추출부터 적재까지 전체 흐름이 실행됩니다.
Entity Resolution: 같은 규칙, 다른 이름
현장에서는 동일한 설계 규칙이 여러 이름으로 불립니다. 예를 들어, 하나의 규칙이 관리 번호(“RULE-001”), 공식 명칭(“예비 접점 확보 규칙”), 현장 표현(“Spare 처리 규칙”), 맥락적 언급(“밸브 접점을 여유 있게 잡는 원칙”) 등으로 참조됩니다.
Graphiti는 LLM 기반 의미적 비교를 통해 이 표현들이 모두 같은 규칙을 가리킨다는 것을 자동으로 인식하고 단일 노드로 병합합니다. “Spare 처리”와 “예비 접점 확보”가 같은 개념임을 판단하려면 PLC 설계 도메인에 대한 이해가 필요한데, 이것을 LLM이 수행합니다.
Temporal Fact Management: 규칙은 변한다
설계 규칙은 고정되어 있지 않습니다. 새로운 장비 도입, 공정 개선, 안전 사고 교훈 반영 등으로 업데이트됩니다. Graphiti는 모든 관계에 유효 기간(valid_from, valid_to)을 부여하여, “2025년 1분기에 적용되던 규칙”과 “현재 적용 중인 규칙”을 명확히 구분합니다. 규칙이 업데이트되면 이전 버전을 무효화하고 새 버전을 생성하는 방식이므로, 과거 설계 근거를 추적하거나 규칙 변경 이력을 감사(audit)할 때 필수적인 기능입니다.
그래프 구조
PoC에서 구축된 지식 그래프는 53개 엔티티(설계 규칙, 장비, 공정, 표준, UDK 분류)와 91개 관계(depends_on, conflicts_with, supersedes, applies_to 등 20종)로 구성됩니다. 여기서 주목할 점은, 20종의 관계 타입을 사전에 정의한 것이 아니라 LLM이 텍스트에서 자동으로 식별했다는 것입니다.
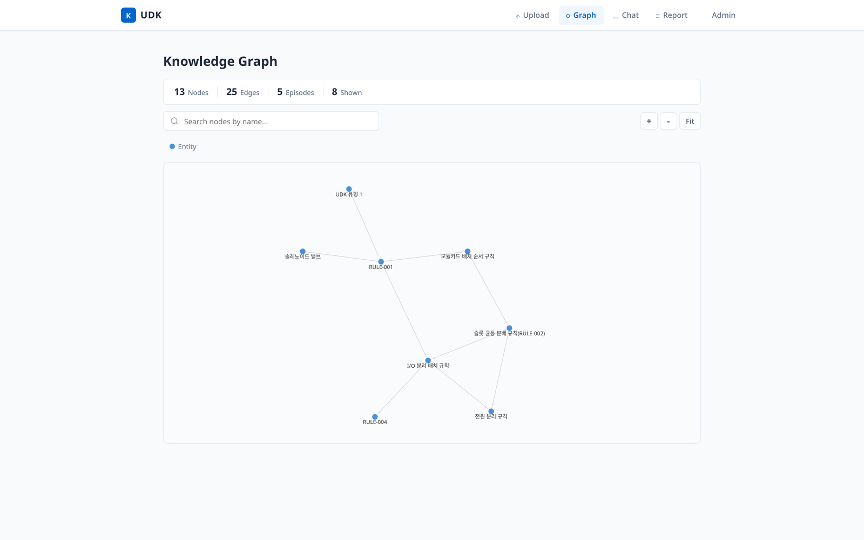
그림. 설계 규칙 간의 의존(depends_on)·참조(references) 관계가 네트워크로 시각화됩니다. 규칙·명칭·수치는 일반화된 예시입니다.
3-Way 하이브리드 검색
왜 단일 검색으로는 부족한가
현장 엔지니어의 질문은 형태가 다양합니다. “사양 변경에 대비하는 방법은?”처럼 개념적인 질문에는 벡터 검색(의미 유사도)이 강합니다. “예비 접점 규칙”처럼 정확한 용어를 찾을 때는 BM25 키워드 검색이 적합합니다. “이 규칙에 의존하는 다른 규칙은?”이나 “분배 규칙 변경의 파급 효과는?”처럼 관계를 추적하는 질문에는 그래프 순회(Neo4j Cypher)가 필요합니다.
한 가지 검색 방식만으로는 이 모든 유형에 대응할 수 없기 때문에, 세 가지를 병렬로 수행하고 결과를 융합하는 방식을 채택했습니다.
RRF(Reciprocal Rank Fusion) 융합
세 가지 검색을 병렬로 수행한 뒤, 각 결과의 순위(rank)를 기준으로 융합합니다. 절대 점수가 아닌 순위 기반이므로, 서로 다른 스케일의 점수를 정규화할 필요가 없다는 것이 RRF의 핵심 장점입니다.
async def hybrid_search(query: str, top_k: int = 10) -> List[SearchResult]:
vector_results, bm25_results, graph_results = await asyncio.gather(
vector_search(query, top_k=20),
bm25_search(query, top_k=20),
graph_traverse(query, max_depth=2),
)
fused_scores = {}
k = 60 # RRF 상수
for source in [vector_results, bm25_results, graph_results]:
for rank, result in enumerate(source):
fused_scores[result.id] = fused_scores.get(result.id, 0) + 1/(k + rank + 1)
sorted_results = sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
return [get_result_by_id(rid) for rid, _ in sorted_results[:top_k]]
예를 들어, “밸브 접점 설계 시 고려사항”이라는 질문에 대해 벡터 검색과 BM25 검색 모두 “예비 접점 확보 규칙”을 1위로 반환하고, 그래프 순회는 이 규칙에서 depends_on 관계를 따라 “분배 규칙”까지 함께 가져옵니다. 세 검색 모두에서 상위에 등장한 규칙이 최종 1위로 확정되고, 그래프 순회를 통해 의존 관계에 있는 규칙도 컨텍스트에 자동 포함됩니다.
데이터 보안
설계 데이터는 기업의 핵심 경쟁력에 해당하는 민감 정보입니다. 이 시스템에서는 다층 방어(Defense-in-Depth) 전략을 적용했습니다.
가장 근본적인 원칙은 아키텍처 수준의 격리입니다. 원본 데이터는 고객 환경을 절대 벗어나지 않으며, 수집 에이전트는 고객 환경 내에서만 동작합니다. 지식 그래프 서버로 전송되는 것은 정제된 지식(엔티티, 관계, 메타데이터)뿐입니다.
민감정보 제거는 2-Pass로 수행합니다. 문서 수집 시점에 LLM 기반 문맥 인식 Redaction을 1차로 수행하고, Export 시점에 패턴 기반 필터와 LLM 이중 검증으로 2차 필터링합니다. 민감정보 탐지에서는 재현율(recall)이 정밀도보다 중요하므로, 판단이 모호한 경우에는 제거하는 보수적 전략을 기본으로 합니다.
정제된 지식의 저장에는 AES-256-GCM 암호화를, 전송에는 TLS 1.3을 적용하여 데이터가 어떤 경로에서든 보호되도록 했습니다.
구축 과정의 현실: Lessons Learned
AI는 “엔지니어처럼” 보지 않는다
초기에 AI가 추출한 엔티티는 일반적인 NLP 관점에 머물렀습니다. “특정 모듈의 앞쪽 N개 채널은 센싱 전용으로 사용한다”라는 문장에서, AI는 “모듈명”과 “센싱”을 엔티티로 추출했습니다. 그러나 현장 엔지니어가 진정으로 중요하게 보는 것은 “N개라는 임계값“과 “앞/뒤 구분이라는 배치 원칙“이었습니다. AI는 명사구를 추출하는 데 익숙하지만, 현장의 핵심은 숫자로 표현된 판단 기준과 위치 관계로 표현된 설계 원칙이었습니다.
이를 해결하기 위해 시스템 프롬프트에 도메인 컨텍스트를 주입했습니다. 설계 용어 사전, 엔티티 유형 가이드, 그리고 올바른 추출 결과의 few-shot 예시를 제공하여 추출 품질을 개선했습니다.
Entity Resolution 튜닝
Graphiti의 Entity Resolution은 강력하지만, 도메인 특수성으로 인해 기본 설정만으로는 정확도가 불충분했습니다. 예를 들어, “RULE-001″과 “예비 접점 확보 규칙”은 같은 엔티티인데 threshold가 높으면 별개로 유지되고, “A 공정 분배 규칙”과 “B 공정 분배 규칙”은 다른 엔티티인데 threshold가 낮으면 오병합되었습니다. 엔티티 유형별로 다른 threshold를 적용하고, “이런 경우는 같은 엔티티가 아닙니다”라는 negative example을 보강하여 해결했습니다.
관계 타입 자동 식별
20종의 관계 타입 중 일부는 예상하지 못했던 유용한 발견이었습니다. IS_ABBREVIATION_FOR(약어와 풀네임 자동 매핑)는 검색 시 동의어 확장에 즉시 활용되었고, HAS_PRECONDITION(규칙 적용의 전제 조건)은 규칙 적용 순서를 결정하는 데 활용되었습니다. CONFLICTS_WITH(상충 규칙 쌍)는 설계 검증 시 충돌 경고에 활용됩니다. 반면, RELATED_TO 같은 지나치게 일반적인 관계 타입은 실용 가치가 낮아서, 프롬프트에서 사용을 제한하는 가이드를 추가했습니다.
비용 최적화
지식 그래프 구축은 LLM 호출이 빈번합니다. 문서 하나당 추출 1회, 분류가 규칙당 1회, Entity Resolution이 엔티티당 1~5회 발생하므로 비용 관리가 필수입니다. Prompt Caching을 적용하여 반복되는 시스템 프롬프트의 입력 토큰 비용을 절감하고, 복잡한 추론이 필요한 작업(엔티티 추출, UDK 분류)에는 Claude Sonnet을, 단순한 임베딩 작업에는 Titan Embeddings를 사용하는 모델 분리 전략을 적용했습니다. 일별/월별 토큰 사용량 상한을 설정하여 예상치 못한 비용 초과를 방지합니다.
결과
정량적 성과
PoC 결과, 35개 설계 규칙에서 53개 엔티티와 91개 관계(20종 관계 타입)가 자동 추출되었습니다. 문서 업로드부터 Q&A가 가능해지기까지 약 60초가 소요되며, 14종의 문서 포맷을 지원합니다. 인프라는 CDK 9개 스택, REST API 25개 엔드포인트로 구성됩니다.
Q&A 시나리오
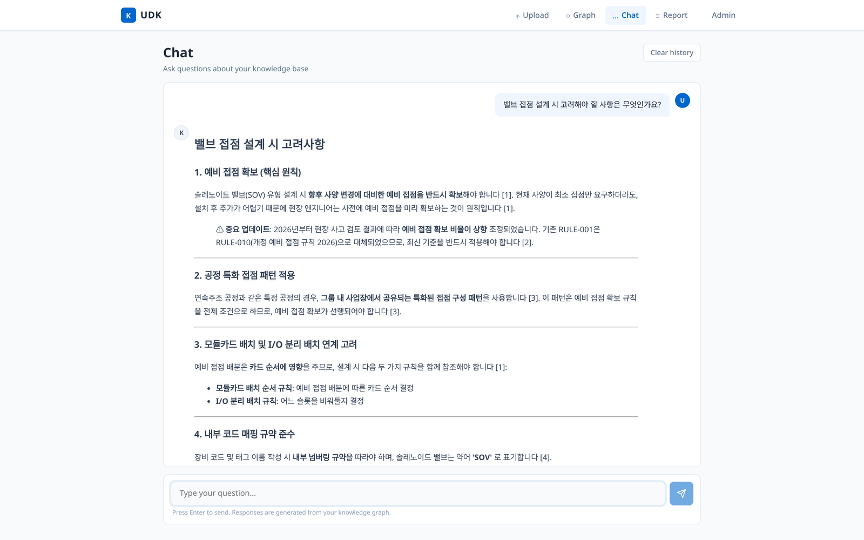
그림. 현장 질문에 대해 판단 근거와 출처 인용([1][2]…)이 포함된 답변을 생성합니다.
│ Q: “밸브 접점 설계 시 고려해야 할 사항은?”
│ A: “해당 솔레노이드 밸브는 현재 사양 기준으로는 최소 접점만 필요하지만, 향후 사양 변경 가능성에 대비하여 예비 접점을 추가로 확보하는 것이 사내 설계 표준입니다.”
│ 출처: 설계 규칙 — 예비 접점 확보 (유형 1: AI 미학습 + 암묵지 + 자사 고유)
일반 RAG 시스템이었다면 “현재 사양 기준으로 최소한만 확보하면 됩니다”라는 교과서적 답변에 그쳤을 것입니다. 지식 그래프에 UDK가 구조화되어 있기 때문에, 판단 근거까지 포함한 현장 수준의 답변이 가능합니다.
영향도 분석 시나리오
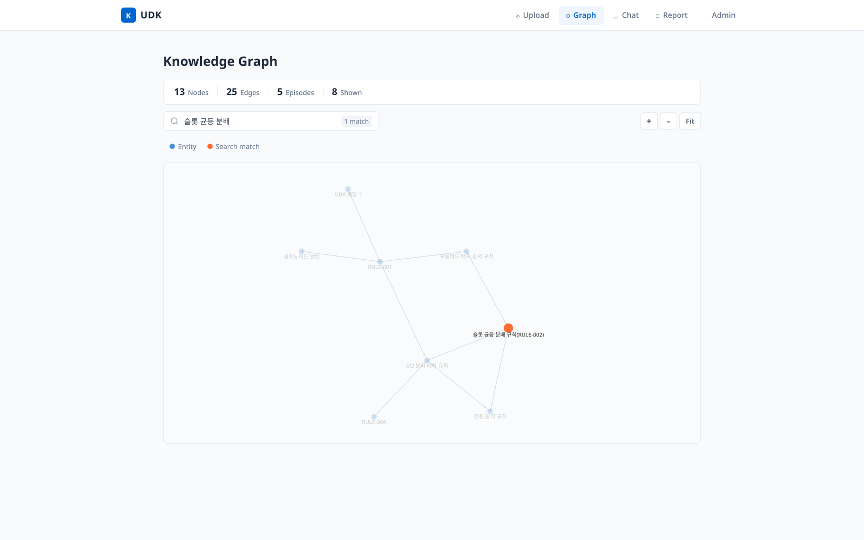
그림. 특정 규칙(슬롯 균등 분배 규칙)을 선택하면 그래프 순회로 연관 규칙이 강조되어, 변경 시 검토 범위를 빠르게 파악할 수 있습니다.
│ Q: “Rack 슬롯 수가 4에서 8로 변경됐는데, I/O List에서 어느 부분을 수정해야 하나?”
│ A (그래프 순회 결과):
│ – I/O 분리 배치 규칙 (depends_on) — 슬롯 수 변경에 따라 배치 기준 재적용 필요
│ – 모듈카드 배치 순서 규칙 (references) — 슬롯 확장 시 배치 순서 재검토
│ – Spare 처리 규칙 (references) — 예비 슬롯 할당 기준 변경
│ – 전원 분리 규칙 (depends_on → depends_on) — 2-hop 간접 의존
이처럼 실무에서 발생하는 구체적인 변경 사항에 대해, 그래프 순회를 통해 영향받는 규칙과 수정이 필요한 영역을 사전에 파악할 수 있습니다. 문서 검색이나 벡터 검색만으로는 불가능한 기능입니다.
자동 분석 리포트
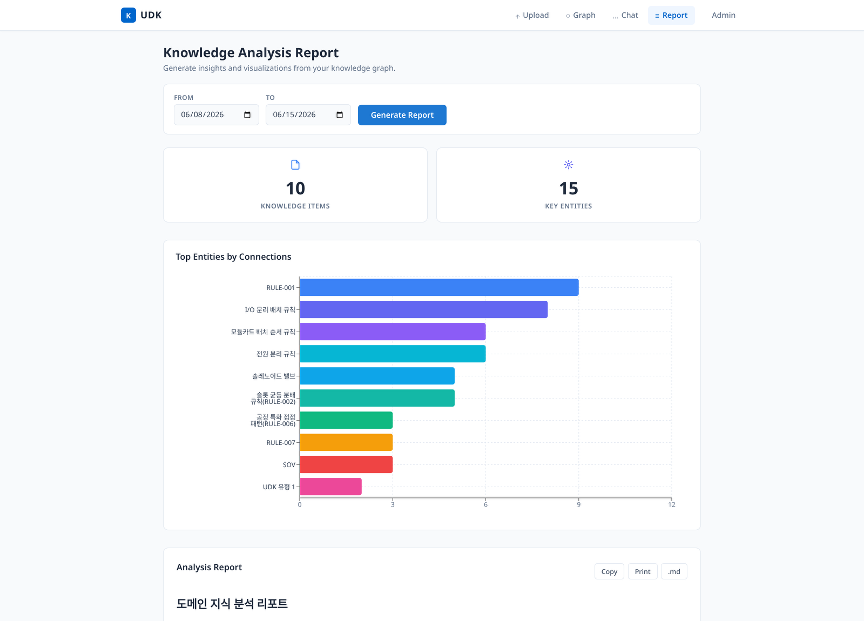
그림. 축적된 지식을 바탕으로 규칙 현황과 가장 많은 규칙이 의존하는 핵심 규칙(hub node)을 자동 분석합니다.
시스템은 축적된 지식을 바탕으로 자동 분석 리포트도 생성합니다. 카테고리별 규칙 현황, 가장 많은 규칙이 의존하는 핵심 규칙(hub node) 식별, 그리고 아직 규칙이 식별되지 않은 공백 영역(gap) 파악 등을 통해 지식 자산화의 현재 수준과 보완이 필요한 영역을 시각적으로 확인할 수 있습니다.
기대 효과 & 향후 제언
이번 PoC를 통해 기대하는 비즈니스 효과는 크게 다섯 가지입니다.
첫째, 시니어 엔지니어의 판단 기준을 구조화하여 인력 퇴직으로 인한 핵심 지식 유실을 방지합니다. 둘째, 구조화된 UDK를 AI 컨텍스트로 주입하여 설계 자동화의 정확도를 “일반 수준”에서 “현장 수준“으로 끌어올립니다. 셋째, 규칙 변경 시 그래프 순회로 영향받을 수 있는 규칙을 함께 제시하여, 엔지니어가 검토할 범위를 빠르게 좁히도록 돕습니다. 넷째, 구조화된 Q&A를 통해 신규 인력의 온보딩 기간을 단축합니다. 마지막으로, 동일한 규칙이 모든 설계자에게 일관되게 적용되어 설계 품질 편차를 줄입니다.
이번 PoC는 EIC 계장 설계의 35개 규칙을 대상으로 검증을 완료했습니다. 향후에는 전기, 기계 등 타 공종으로의 확장과, 축적된 지식 그래프를 설계 자동화 시스템의 컨텍스트로 직접 활용하는 방향을 검토하고 있습니다.
마치며
모든 산업에는 “AI가 모르는 도메인 지식”이 존재합니다. 교과서에 나오지 않고, 인터넷에 공개되지 않은, 오직 현장 경험으로만 축적되는 지식입니다.
AI가 아무리 발전해도, 이 지식을 명시적으로 제공하지 않으면 출력은 항상 “일반적으로 맞지만 우리 현장에서는 틀린” 결과에 머물게 됩니다. AI의 능력을 현장 수준으로 끌어올리는 열쇠는, 우리만의 지식을 AI가 이해할 수 있는 형태로 구조화하는 것입니다.
포스코DX는 이번 PoC를 통해 세 가지를 확인했습니다. “AI가 모르는 지식”을 체계적으로 분류할 수 있다는 것, 지식 그래프로 구조화하면 단순 검색을 넘어 영향도 분석과 multi-hop 추론이 가능하다는 것, 그리고 Amazon Bedrock과 Graphiti의 조합으로 문서 수집부터 Q&A까지 약 60초 만에 End-to-End 자동화할 수 있다는 것입니다.
“우리 조직의 노하우를 어떻게 AI에게 전달할 수 있을까?” — 이 고민은 AI 도입을 추진하는 모든 제조/엔지니어링 조직이 결국 마주하게 될 질문입니다. 비슷한 과제를 시작하려는 조직에게 한 가지 제안을 드리자면, 작게 시작하세요. 가장 빈번하게 질문받는 핵심 규칙 10개를 선별하고, LLM에게 같은 질문을 던져 현장 답변과 비교하는 것만으로도 “자산화 대상이 무엇인지”가 명확해집니다.
이 글이 그 첫 걸음에 참고가 되길 바랍니다.
다음 단계로
- Amazon Bedrock 시작하기: Amazon Bedrock 사용 설명서에서 Claude·Titan 등 기반 모델을 콘솔에서 바로 호출해 볼 수 있습니다. 별도 인프라 없이 API 한 번으로 시작합니다.
- 지식 베이스(RAG) 직접 구성: 문서 기반 RAG를 관리형으로 빠르게 구축하려면 Amazon Bedrock Knowledge Bases부터 시도해 보세요. 본문의 지식 그래프 접근과 비교하며 우리 도메인에 맞는 방식을 선택할 수 있습니다.
- 핸즈온 워크숍: Amazon Bedrock 워크숍에서 RAG·임베딩에이전트 실습을 단계별로 따라 할 수 있습니다.
- 시간적 지식 그래프 프레임워크는 Graphiti에서 오픈소스로 제공되며, pip install graphiti-core로 로컬에서 바로 실험해 볼 수 있습니다.
[참여 고객]
*고객의 요청으로 프로필 노출을 하지 않았습니다.
- 최영식(Youngsik Choi) — 포스코DX AX융합연구소 OT기술개발그룹